机械臂抓取---(1)概述
Pipeline and Key Technologies
智能机器人的重要特性是能够感知环境并与之交互。 在机器人的众多功能力中,抓取是机器人的最基础也是最重要的功能。在工业生产中,机器人每天要完成大量繁重的抓取放置任务,为老年人和残疾人提供便利的家用机器人,也是以日常抓取任务为主。因此,赋予机器人感知能力并通过感知信息更好的完成抓取一直是机器人和机器视觉领域的重要研究内容之一。
机器人抓取系统主要由 抓取检测系统、抓取规划系统和抓取控制系统 组成。其中, 抓取检测系统为后面两个子系统的规划和控制提供了目标和机器人的相对位置信息,是抓取任务顺利进行的前提。抓取规划系统和控制系统与运动学和自动化控制学科关系密切,本文只讨论与机器人视觉相关的抓取检测系统子系统的实现。
抓取检测系统的实现根据实际的应用场景有所不同。目前常见的抓取场景可分为两大类:2D平面抓取 和 6 Dof空间抓取 。
2D平面抓取
该场景下,机械臂竖直向下,从单个角度去抓目标物体,如工业场景中流水线上的分拣和码垛。二维平面抓取,目标物体位于平面工作空间上,抓取受到一个方向的约束(支撑平面约束)。 在这种情况下,夹持器的高度是固定的,夹持器的方向垂直于一个平面。 因此,基本信息从 6D 简化为 3D,即 2D 平面内位置和 1D 旋转角度。
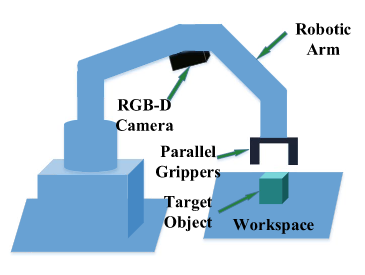
图1 2D平面抓取
6Dof空间抓取
该场景下,机械臂可以从任意角度抓取目标物体。如图2,黄色物体表示平行抓手,它可以从不同的角度来抓取目标物体。
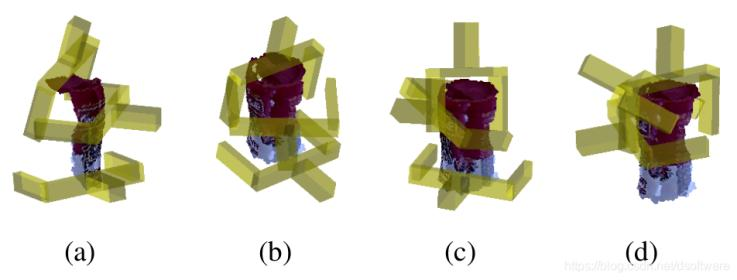
图2 6Dof空间抓取
无论是2D平面抓取还是6Dof空间抓取,抓取检查系统都需要完成的三个任务:目标定位、目标位姿估计和抓取位置估计。或者说 物体定位、位姿估计到抓取位姿估计。
本文尽力实现抓取检测系统实现的技术全貌,了解如何在给定原始视觉数据的情况下检测目标进行位姿估计,并根据目标物体的位姿,计算得到机器人抓取时夹爪的位姿。
目标定位
大多数机器人抓取方法首先需要目标对象在输入数据中的位置。 这涉及三种不同的情况:无分类的对象定位、对象检测和对象实例分割。 无分类的对象定位只输出目标对象的潜在区域,而不知道它们的类别。 对象检测提供目标对象及其类别的边界框。 对象实例分割进一步提供了目标对象像素级或点级区域及其类别。
无分类的对象定位
- 基于2D图像

图3 基于2D图像的定位方法
如果物体的外部轮廓已知,可以采用拟合形状基元法。先提取出图像所有封闭的轮廓,其次再用拟合方法得到潜在可能是目标的物体,如果存在多个候选,可以使用模板匹配去除干扰。如果物体轮廓未知的,可以采用显著性检测方法,显著性区域可以是任意形状。2D显著性区域检测的目的是定位和分割出给定图像中最符合视觉显著性的区域,可以依据一些经验例如颜色对比、形状先验来得到显著性区域。
- 基于3D点云

图4 基于3D点云的定位方法
基于3D点云的定位方法,与2D类似,只是维度上升到了三维。针对有形状的物体(如球体、圆柱体、长方体等),将这些基本的形状作为3维基元,通过各种方法进行拟合来定位。而基于3D显著性区域检测方法,需要从完整的物体点云中提取显著性图谱作为特征。
目标检测
物体检测任务是检测某一类物体的实例,可以将其视为定位任务加分类任务。 通常,目标物体的形状是未知的,并且很难获得准确的显着区域。 因此,规则边界框用于一般对象定位和分类任务,对象检测的输出是带有类标签的边界框。
- 基于2D图像

图5 基于2D图像的目标检测
有两种主流的算法,第一种是基于区域候选的方法,通过使用滑动窗口策略获得候选矩阵框,然后针对每个矩形框进行分类识别。为了在不同观测距离处检测不同的目标,一般会使用多个不同大小和宽高比的窗口。而矩形框中的特征,常使用的SIFT,FAST,SURF和ORB等。另一种,就是使用回归的方法,采用端到端的深度学习,进行神经网络训练,直接一次预测出边界框和类别分数,如我们熟知的YOLO算法。
- 基于3D点云
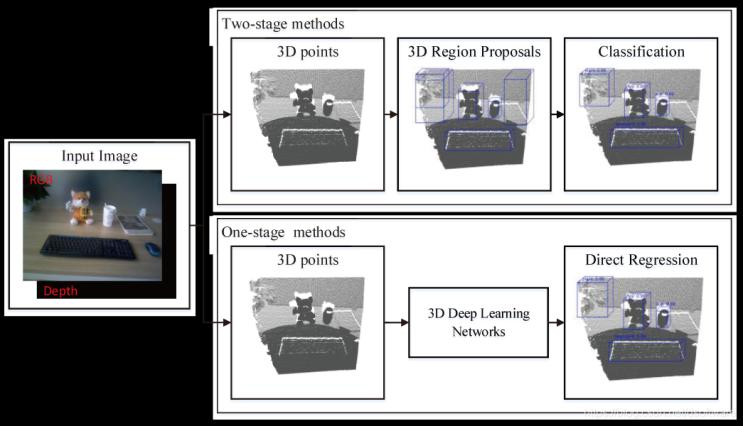
图6 基于3D点云的目标检测
3D物体检测的目的是找到目标物体的包围盒,也就是找到一个立方体刚好能够容纳目标物体。基于区域候选的方法,使用3D区域候选,通过人工设计的3D特征,例如Spin Images, 3D Shape Context, FPFH, CVFH, SHOT等,训练诸如SVM之类的分类器完成3D检测任务,代表方法为Sliding Shapes。随着深度学习的发展,可以直接通过网络预测物体的3D包围盒及其类别概率,其中比较有代表性的是VoxeNet。VoxelNet将输入点云划分成3D voxels,并且将每个voxel内的点云用统一特征表示,再用卷积层和候选生成层得到最终的3D包围盒。
物体分割
物体实例分割是指检测某一类的像素级或点级实例对象,与对象检测和语义分割任务密切相关。 存在两种方法,即两阶段方法和一阶段方法。 两阶段方法是指基于区域候选的方法,一阶段方法是指基于回归的深度学习方法。
- 基于2D图像
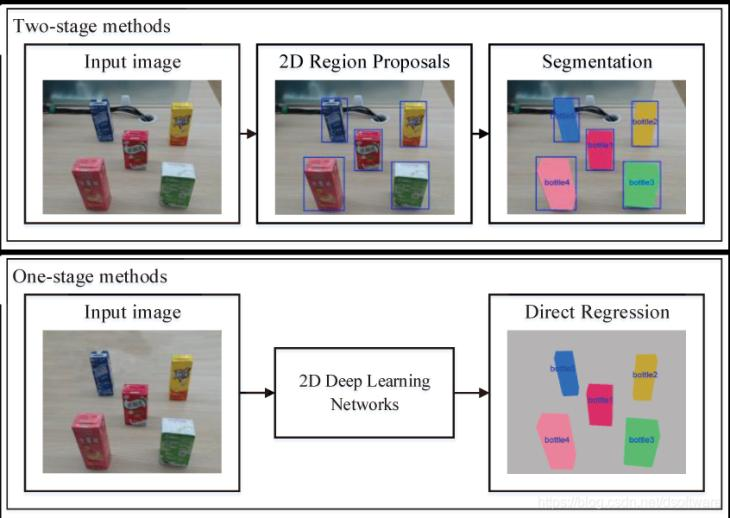
图7基于2D图片的目标分割
区域候选法借助上一节目标检测的结果生成的包围盒或候选区域,在其内部计算物体的mask区域,然后使用CNN来进行候选区域的特征提取与识别分类。另一种直接使用端到端的深度学习方法进行分割,预测分割的mask和存在物体的得分。其中比较有代表性的算法有DeepMask,TensorMask,YOLACT等。
- 基于3D点云
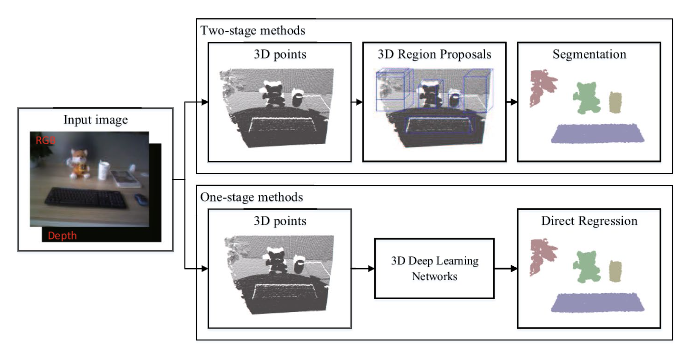
图8基于3D点云的目标分割
基于点云数据的区域候选法,在点云目标检测的基础上,对包围盒区域进行前后景分割来得到目标物体的点云。比较经典的算法有GSPN和3D-SIS,GSPN通过在生成3D候选区域后,通过PointNet进行3D物体的实例分割。3D-SIS使用二维和三维融合特征进行物体高位盒检测盒语义实例分割。
目标6D位姿估计
在一些 2D 平面抓取中,目标对象被约束在 2D 工作空间中并且没有堆积,对象6D位姿可以表示为 2D 位置和平面内旋转角度。 这种情况相对简单,基于匹配 2D 特征点或 2D 轮廓曲线可以很好地解决。 在其他 2D 平面抓取和 6DoF 抓取场景中,需要得到 6D 物体姿态信息,这有助于机器人了解目标物体的位置和朝向。6D物体位姿估计分为基于对应、基于模板和基于投票的三种方法,如下表。

基于对应关系
基于对应关系的目标6D 位姿估计涉及在观察到的输入数据和现有完整 3D 对象模型之间寻找对应关系的方法。 当我们想基于2D RGB图像解决这个问题时,需要找到现有3D模型的2D像素和3D点之间的对应关系。然后通过 Perspective-n-Point (PnP) 算法计算出位姿信息。 当要从深度图像中提取的 3D 点云来进行位姿估计时,要找到观察到的局部视图点云和完整 3D 模型之间的 3D 点的对应关系,此时可以通过最小二乘法预测对象6D姿态。
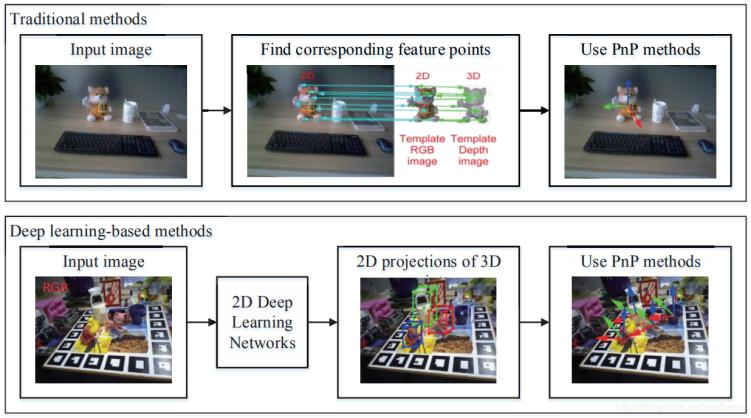
图9 2D图片基于对应关系的位姿估计
基于对应关系的方法主要针对纹理丰富的目标物体,首先将需要计算位姿的目标物体的3D模型投影到N个角度,得到N张2D模板图像,记录这些模板图上2D像素和真实3D点的对应关系。当单视角相机采集到RGB图像后,通过特征提取(SIFT,FAST,ORB等),寻找特征点与模板图片之间的对应关系。通过这种方式,可以得到当前相机采集图像的2D像素点与3D点的对应关系。最后使用PnP算法即可恢复当前视角下图像的位姿。除了使用显示特征的传统算法外,也出现了许多基于深度学习来隐式预测3D点在2D图像上投影,进而使用PnP算法计算位姿的方法。

图10 3D点云基于对应关系的位姿估计
基于3D点云的方法与2D图像类似,只是使用了三维的特征来进行两片点云之间的对应。在特征选择方面也分为传统特征提取(如Spin Images,3D Shape Context等)和深度学习特征提取(3D Match,3D Feat-Net等)的方法。
基于模板的方法
基于模板的对象6D姿态估计是从已有的对象6D姿态模板库中找到最相似模板的方法。 在 2D 情况下,模板可以是来自已知 3D 模型的投影 2D 图像,模板内的对象在相机坐标中具有相应的对象6D姿态。 因此,6D 物体姿态估计问题转化为图像检索问题。 在 3D 情况下,模板可以是目标对象的完整点云。 我们需要找到将局部点云与模板对齐的最佳 6D 姿态,因此对象6D姿态估计成为一个部分到整体的粗配准问题。
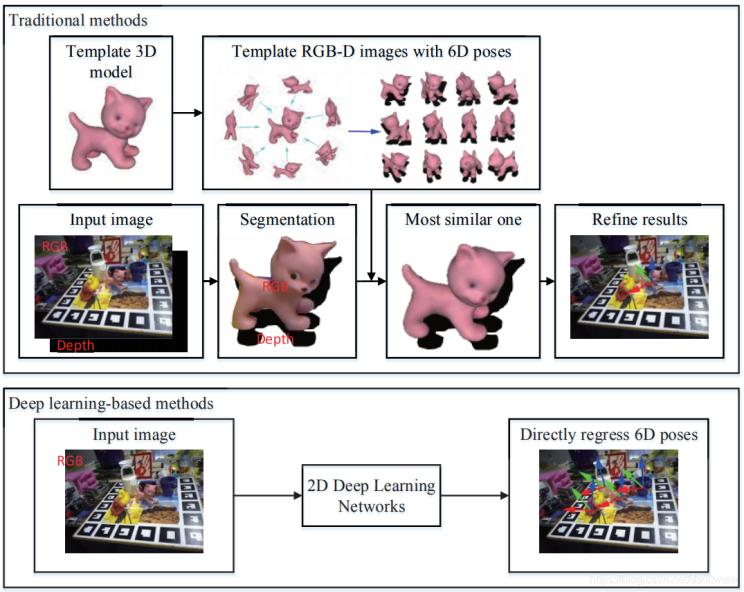
图11 2D图片基于模板匹配的位姿估计
LineMode方法是基于2D图像的代表,通过比较观测RGB图像和模板RGB图像的梯度信息,寻找到最相似模板图像,以该模板对应的位姿作为观测图像对应的位姿,该方法还可以结合深度图的法向量来提高精度。而在模板匹配的过程中了,除了显式寻找最相似的模板图像外,也有方法隐式地寻找最近似的模板,代表性方法是AAE。该方法将模板图像编码形成码书,输入图像转换为一个编码和码书进行比较寻找到最近似的模板。当然,也可以通过深度学习方法,直接从图像中预测目标物体的位姿信息。该方法可看作是从带有标签的模板图像中寻找和当前输入图像最接近的图像并且输出其对应的6D位姿标签的过程。

图12 2D图片基于模板匹配的位姿估计
当以3D点云为输入数据时,传统的点云部分配准方法将采集到的部分点云与完整点云模板进行对齐匹配,在噪声较大的情况下具有很好的鲁棒性,但是算法计算过程耗时较长。在这方面,一些基于深度学习的方法也可以有效地完成部分配准任务。这些方法使用一对点云,从 3D 深度学习网络中提取具有代表性和判别性的特征,通过回归的方式确定对点云之间的 6D 变换,进而来计算目标物体的6D位姿。
基于投票的方法
基于投票的方法意味着每个像素或 3D 点通过提供一票或多票对对象6D姿态估计做出贡献。 按照投票方式可分为两种,一种是间接投票方式,一种是直接投票方式。 间接投票方法意味着每个像素或 3D 点对某些特征点进行投票,从而提供 2D-3D 对应关系或 3D-3D 对应关系。 直接投票方法是指每个像素或 3D 点对某个 6D 对象坐标或姿势进行投票。
- 间接投票
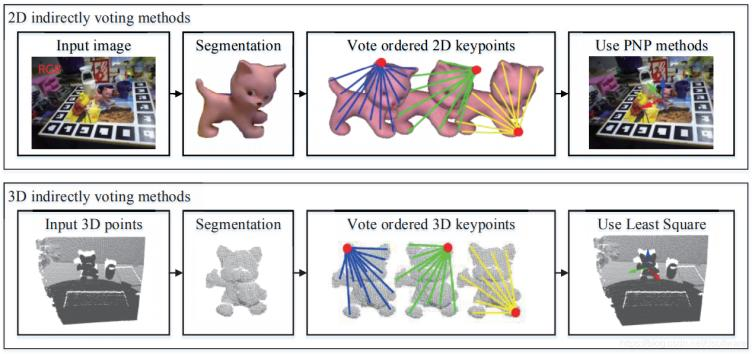
图13 基于间接投票的位姿估计
间接投票可以看作是基于对应的投票。 在 2D 情况下,对 2D 特征点进行投票,可以实现 2D-3D 对应。 在 3D 情况下,对 3D 特征点进行投票,可以实现观察到的局部点云和规范的完整点云之间的 3D-3D 对应关系。此类方法大多使用深度学习,因为它具有强大的特征表示能力,可以预测出更好的投票结果。
- 直接投票
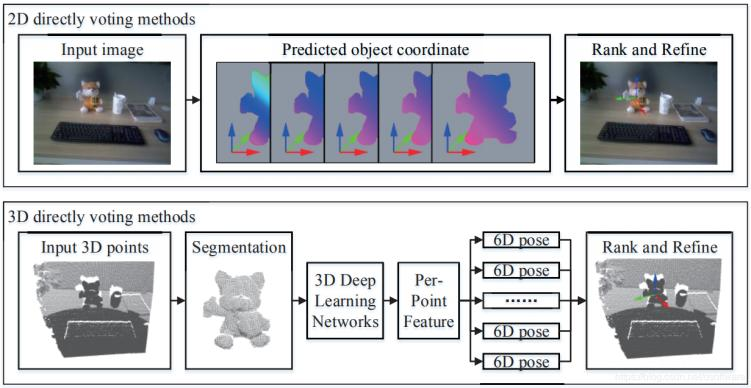
图14 基于直接投票的位姿估计
直接投票方法,通过生成大量位姿预测,再进行选择和优化,可以得到最终的位姿。在二维情况下,这种方法主要用于计算有遮挡物体的姿态。对于这些对象,图像中的局部证据限制6D位姿的可能性,因此可通过局部区域中每个像素投票方式预测位姿。2D输入的代表性方法有[2014-Learning 6d object pose]和[2014-Latent-class],3D输入的代表性方法有PPF[2012-3d object detection],[2018-6d pose estimation]。
抓取估计
抓取估计是指估计相机坐标中的夹具6D位姿。如前所述,抓取可分为二维平面抓取和 6 DoF 抓取。 对于 2D 平面抓取,受到一个方向的约束,6D 抓手姿势可以简化为 3D 表示,其中包括 2D 平面内位置和 1D 旋转角度,因为高度和沿其他轴的旋转是固定的 . 对于 6DoF 抓取,抓手可以从各个角度抓取物体,因而抓手6d位姿对于抓取至关重要。
2D平面抓取估计
二维平面抓取估计常用的方法是估计抓取接触点。 在 2D 平面抓取中,抓取接触点可以唯一定义抓手的抓取姿势,这在 6DoF 抓取中是不存在的。这种方法首先对候选抓取接触点进行采样,然后使用分析方法或基于深度学习的方法来评估抓取成功的可能性。这种方法属于分类的方法,机器人抓取的经验是基于某些先验知识(例如对象几何学、物理模型或力分析)已知的前提下执行的。抓取数据库通常涵盖的对象数量有限,经验在处理未知对象时会遇到困难。
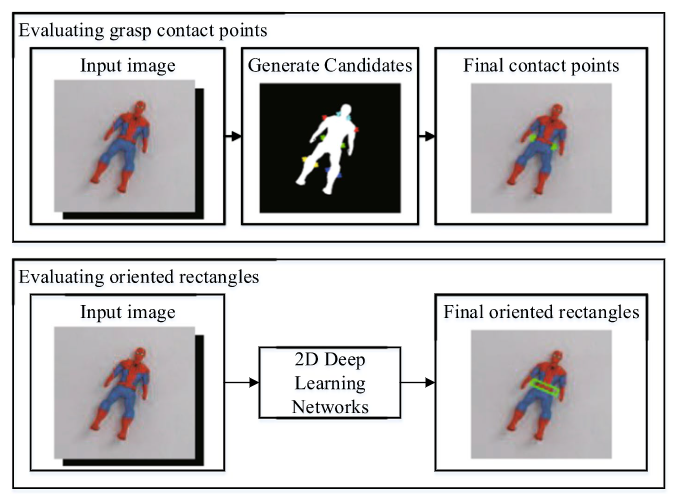
图15 2D平面抓取抓取接触点估计
6 Dof抓取估计
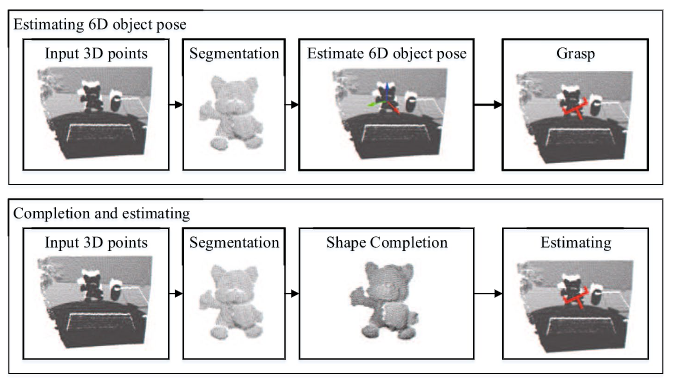
图11 6 Dof抓取估计
如果目标物体已知,则可以从RGB-D数据中准确地估计出6D物体姿态,并且可以通过离线预计算或在线生成来获得6DOF抓取位姿,这是抓取系统最常用的方法。如果数据库中存在6DoF抓取姿势,则可以从知识库中检索当前的6DoF抓取姿势,或者通过与现有抓取进行比较来对其进行采样和排序,从而获得当前的6DoF抓取姿势。如果数据库中不存在6DoF抓取姿势,则利用解析方法计算抓取姿势。这类方法适合任意角度的抓取,然而该类方法的弊端是,尽管能成候选抓取位置,但是单个角度下获得的数据毕竟有限,而如果能够对物体进行补全,则使用传统方法生成候选抓取位置也能够得到很好的结果。
总结
目前机器人抓取系统都与给定的场景深度绑定,不存在一种抓取系统能够一劳永逸适用于多场景下的抓取任务。因此,针对机器人抓取系统的研究一定是在某个给定场景下,针对给定场景构建基于视觉的物体定位、位姿估计和抓取估计算法。
物体定位方面,定位但不识别算法要求物体在结构化场景中或者与背景具有显著差异,因此限制了其应用场景,而实例级的目标检测算法,需要大量目标物体训练集,且算法只对训练集上的物体具良好的检测精度,对与新的识别目标,需要重新进行训练,比较耗时。
位姿估计方面,当目标物体具有丰富的纹理和几何细节时,基于对应关系的方法是一个很好选择。当目标对象具有弱纹理或几何细节时,可以使用基于模板的方法。当对象被遮挡且仅部分表面可见时,可以选择投票的方法进行位姿估计。
抓取估计方面,在有精确的3D模型的情况下,可以精确的估计目标物体的6D姿态。然而,当现有的3D模型与目标模型不同时,估计的6D姿态会产生较大的偏差,从而导致抓取失败。在这种情况下,需要通过对部分视点云进行补全,以获得完整的形状。在重建的完整3D形状上生成抓取点。
虽然目前基于视觉端到端的抓取检测系统研究很多,但是依然存在很多没有解决的问题。如在日常化的抓取场景中,不是每个抓取的物体都能实现在系统中存有3D模型。同时,基于深度学习的方法大多都是在开放抓取数据集上进行性能测试,而我们日常生活中的对象远不是这些数据集所能表征的。另外,目前的抓取系统对于透明物体“无可奈何”,因为深度传感器很难获取它们的三维信息。因此,要将学术研究领域的抓取系统直接应用于日常的抓取场景还有很长的路要走。
参考文献:
[1] Du, Guoguang, et al. "Vision-based robotic grasping from object localization, object pose estimation to grasp estimation for parallel grippers: a review." Artificial Intelligence Review 54.3 (2021): 1677-1734.
[2]《杜国光博士,基于视觉的机器人抓取--物体定位,位姿估计到抓取估计讲座笔记》 https://blog.csdn.net/dbdxnuliba/article/details/109544312

 浙公网安备 33010602011771号
浙公网安备 33010602011771号