
BUAA 软工 Week_4 结对作业_最长英语单词链
| 内容 | |
|---|---|
| 这个作业属于哪个课程 | |
| 这个作业的要求在哪里 | |
| 我在这个课程的目标是 | 学习软件工程 |
| 这个作业在哪个具体方面帮助我实现目标 | 学会与队友合作,了解结对编程,学习接口相关知识 |
1. 项目说明
-
教学班级:周五班
2. 计划
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) |
|---|---|---|
| Planning | 计划 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 30 |
| Development | 开发 | 900 |
| · Analysis | · 需求分析 (包括学习新技术) | 90 |
| · Design Spec | · 生成设计文档 | 60 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 |
| · Design | · 具体设计 | 50 |
| · Coding | · 具体编码 | 240 |
| · Code Review | · 代码复审 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 180 |
| Reporting | 报告 | 120 |
| · Test Report | · 测试报告 | 60 |
| · Size Measurement | · 计算工作量 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 |
| 合计 | 1050 |
3. 教材阅读
看教科书和其它资料中关于 Information Hiding,Interface Design,Loose Coupling 的章节,说明你们在结对编程中是如何利用这些方法对接口进行设计的。
Information Hiding
要求提供一个稳定的接口,限制使用者调用的方法和范围,保护程序的其余部分不受实现的影响,同时也保护这个接口内的内容不被访问。在这次任务中,通过类core对各个函数和功能模块的封装组合,既保证了接口的统一,调用的便捷,也能够实现对这些模块使用的保护,可以提前对输入的参数进行测评、处理,再用核心计算单元进行计算。其中,在stage1中,我们在main函数中直接用inputProcess里的函数实现了对输入参数的分析、处理,再根据参数寻找word计算模块中对应的算法要求。在stage2中,通过使用core的封装,能够做到调用要求的四个函数,并在core中自动调用inputProcess参数处理,并根据分析自动调用word计算模块,或者报告异常情况。
Interface Design
要给调用者一个直接使用的接口,如此次作业中的GUI,命令行界面,通过图形化界面选择参数或者在命令行中输入参数进行接口调用,可以极大的方便调用者,同时,尽量减少接口的输入要求,在方便用户的设计思维下,需要被调用方更加全面的实现各种调用情况的应对,我们对可能存在的各种输入组合以及对应的措施如异常提示,各类功能的调用与结果输出进行了分析和实现。
如:
参数冲突表
表中记录了参数是否可以复合使用。(x 表示两个参数不能同时出现)
| 参数2 \ 参数1 | n | w | m | c | h | t | r |
|---|---|---|---|---|---|---|---|
| n | x | x | x | x | x | x | x |
| w | x | x | x | x | |||
| m | x | x | x | x | x | x | x |
| c | x | x | x | x | |||
| h | x | x | x | ||||
| t | x | x | x | ||||
| r | x | x | x |
异常处理
参数
-
存在非法参数
-
未定义参数
-
不只一个字母
-
非字母或无字母
-
-
-
参数非法使用
-
具体参数的非法使用(见具体需求)
-
冲突
-
重复
-
缺失
-
无参数
-
只有 -r, -h, -t 但没有功能指令
-
-
文件
-
文件不存在
-
没有给出文件名
-
文件非法(不以
.txt结尾) -
存在不只一个文件名
具体需求
-n
-
功能
统计该单词文本中共有多少条单词链,包含嵌套单词链。
-
输入
文件的绝对或相对路径(以
.txt结尾)。 -
输出
命令行输出
一个数字 n ,代表单词链总数。
之后的 n 行输出单词链(不同单词用空格分隔)。
-
异常处理
单词构成环路
-
特殊情况
没有单词链
Loose Coupling
减少各个模块之间的耦合性,能够使得可以几乎将所有的模块独立,并且能够在对模块的实现方法了解很少的基础上实现调用、组合,也可以方便模块正确性测试。
在这次作业中,分为inputProcess,word,core,exception四大板块,其中inputProcess实现了两组输入处理模式,一个是针对阶段一中命令行的输入需求对参数输入进行处理,另一组是针对GUI中能够传入的参数进行处理;word则是计算关键,分为N,M,W_noR,W_R,C_noR,C_R几大功能。异常包包含了各种异常错误类型,core则实现对外统一封装。
附加题小组交换core
本组与周子颖(19373132)、王宇欣(19373349)交换了 dll 模块,并分别进行了测试,测试方式为:
-
本组单元测试模块 + 对方组的 dll
-
本组的 GUI + 对方组的 dll
-
本组的 dll + 对方组测试模块
-
(由于在互换时对方组没有设计 GUI,故无法实现本组的 dll + 对方组 GUI)
在这次的结对编程中,我们保证了core的接口定义,此外要求输入的result是一个提前开了20000个指针类型空间的指针,严格要求inputLen和input所包含的字符串数量相同。
与别组交换core进行测试的时候,也同样要遵循该组对输入参数的规定。例如在此次交换的小组,除了课程组中参数类型规定,该组的契约要求了输入的result要是一个提前开了20000个指针类型空间的指针,输入的char** input只能包含无重复输入的全小写英文单词,输入参数head,tail只能输入小写英文字母。这样就要求我们在调用时,提前将所有的单词串做去重处理,并将不符合要求的字符单词处理了,以及在输入head和tail时保证该参数的正确性。
除了以上的参数要求,互相在交换调用的时候不在关注其实现的过程,并且也只在测试程序中调用接口函数即可,如果出现问题,则可以将该模块单独拎出去进行测试。
在交换模块中,发现对方小组:
-
对于无链的情况("ab", "cbc", "dcd", "ede", "faf", "gfg", "hgh")处理出现错误(图一,左图为我们dll,右图为对方dll)
-
对于五点全向图测试样例瞬间卡退崩溃
-
出现异常情况时,dll没有提示异常信息,也没有处理异常,而是将异常抛出,需要外面调用者自己catch处理(个人认为是一个设计缺陷)(图二)

4. 模块接口设计与实现
-n
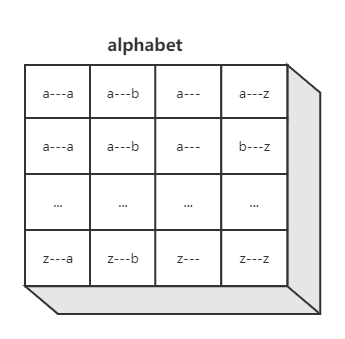
算法设计:采用 DFS 的方式实现,每次求出以某一特定字母开头的全部可能单词链。
无环路
数据结构alphatet中每一格存首尾相同的单词list组
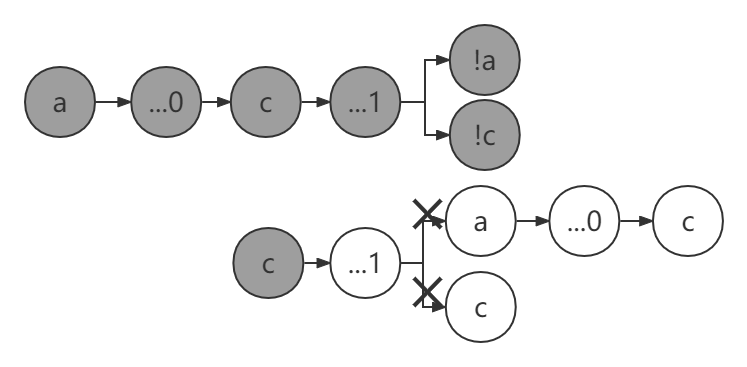
判断环路
算法设计
采用深度搜索,将首尾相同的单词都视作同一个边,用CycleFind记录每轮递归找到的点,同时找到的点都放入AllFind中,如下如分析,如果在单词深度搜索中没有找到导致环路的点,那么这一轮所有出现过的点都不用再分析了,因为假设再用它为开头找环,如果能够找到环,则在它之前的那一轮循环中也能找到环,这样就出现矛盾,因此用AllFind排除一些重复的点,并且将未知单词个数简化到最多26个点。
-w
算法设计
和环路算法数据结构相同,同样视首尾相同的单词为同一条线,换成迪杰斯特拉算法找所有源的最大长度路径,由于无环,首先排除入度不为0的字母,循环遍历只出不进的字母,每一轮找到离该源点最大路径的点,经过一次松弛,记录前项点,其中避开a---a格式的点,保证除了初始点,前项点始终与自己不同,循环所有点后,再进行下一个单源点寻找。在计算最长路径的时候,需要通过前项点寻找路径,同时,假设找到的点为a,如果alphabet中存在a---a格式的点,则需要将路径再添加一次权重,如果长度超过现有最大值则更新。
只有-t时,反转alphabet[colomn][row]的colomn\row去寻找
权重为1
-c
算法设计
上述算法中权重为单词长度
-m
算法设计
上述算法中寻找路径时跳过对a---a格式的点的判断
有环路
-w & -c
算法设计
在有环路的情况下,统一采用 DFS 的方式进行检索,每在单词链中添加一个单词即将其标记为 dirty,选取最长的单词链保存。
性能改进
由于 -c 要求选出字符长度最长的单词链,因此在输入时可根据单词长度对其排序,每次从最长单词开始遍历,可以减少对于单词图的遍历次数,获得一定的性能提升。
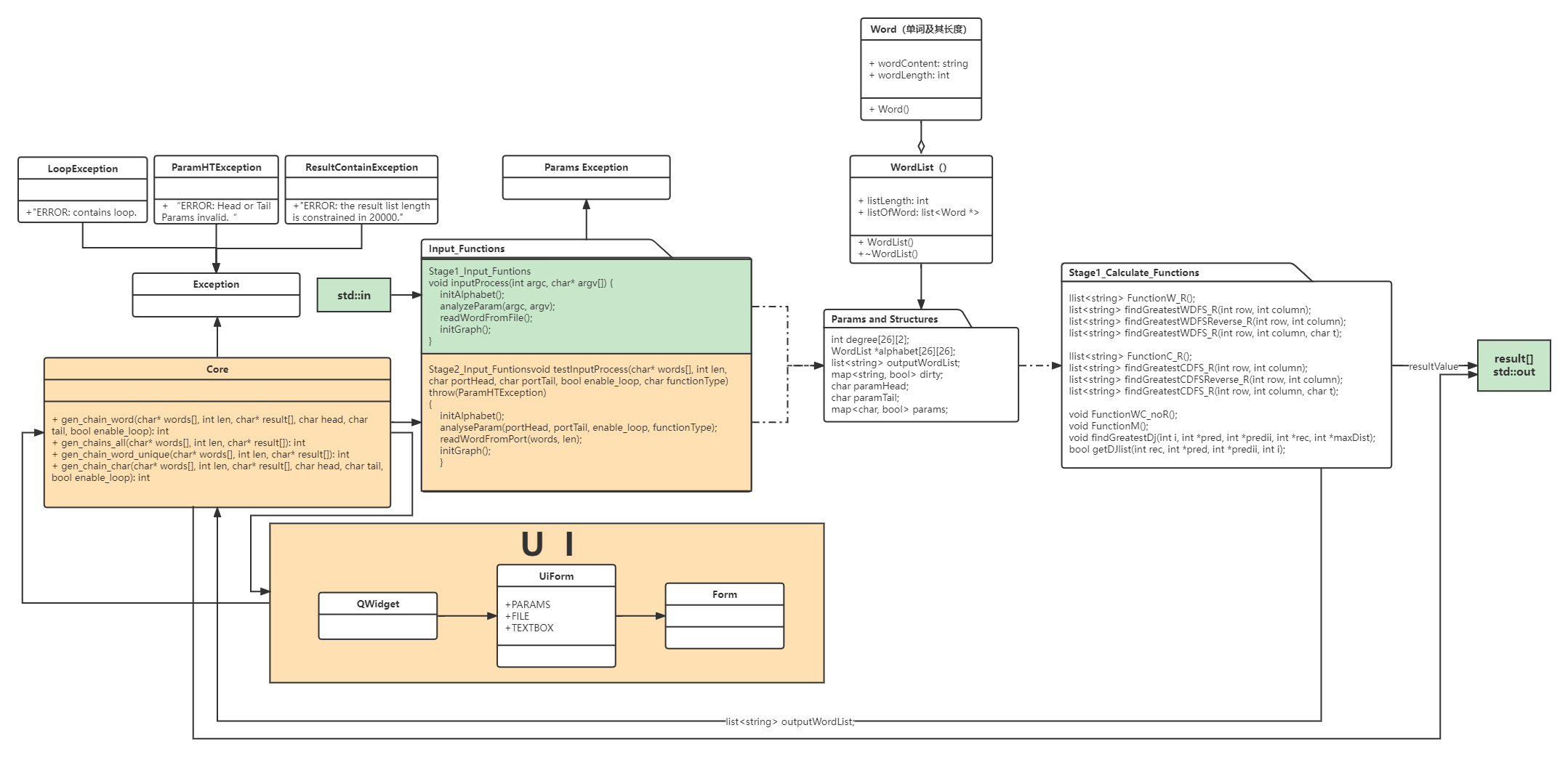
5. UML 图
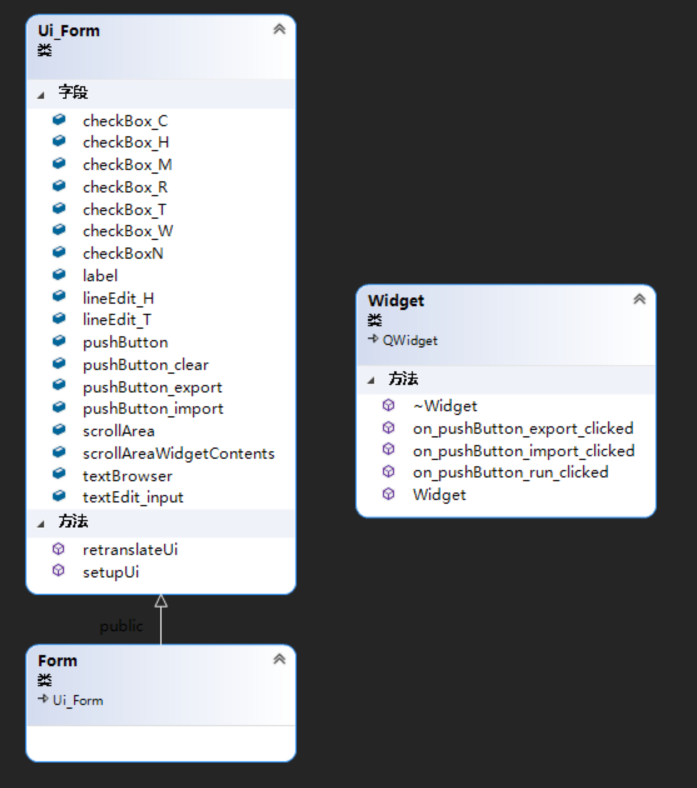
UML、函数流程混杂图(其中绿色为stage1,红色为stage2)
6. 模块接口部分性能改进
在测试中-w和-c测试量相同,其中性能测试样例包含四点全向图,多链,固定首尾。分析函数性能,Core::gen_chain_word 和 Core::gen_chain_char 所封装的 FunctionC_R 和 FunctionC_R 占据了极大的比例。其中 FunctionC_R 更多,是因为该函数需要获取单词的长度作为权重,在查单词长度时导致了这一消耗。
-
改进思路1:通过加入对点的判断,减少不必要的点的函数递归调用
-
改进思路2:有参数
-c时先对单词长度进行排序,再执行算法 -
改进思路3:引入编译优化
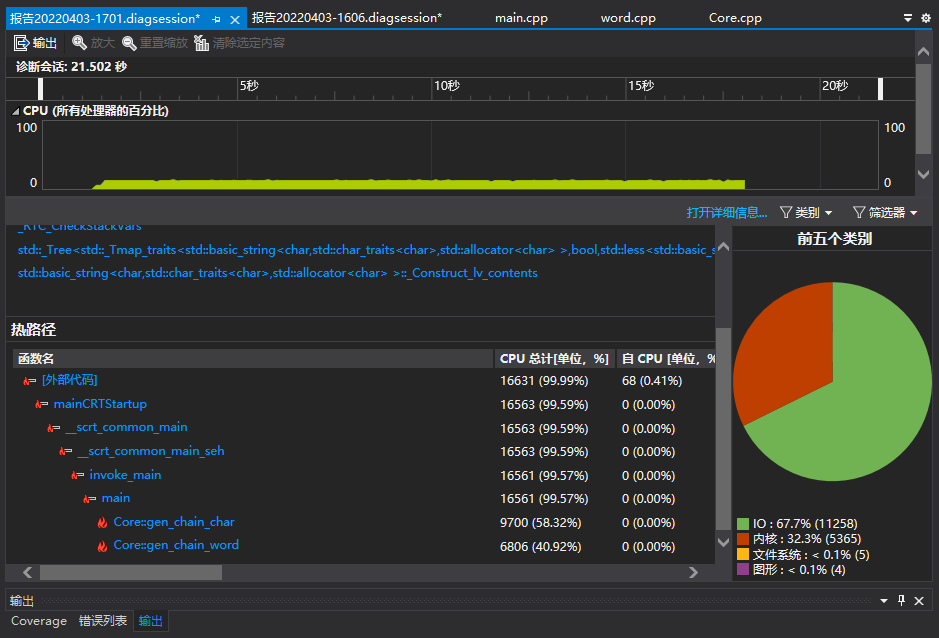
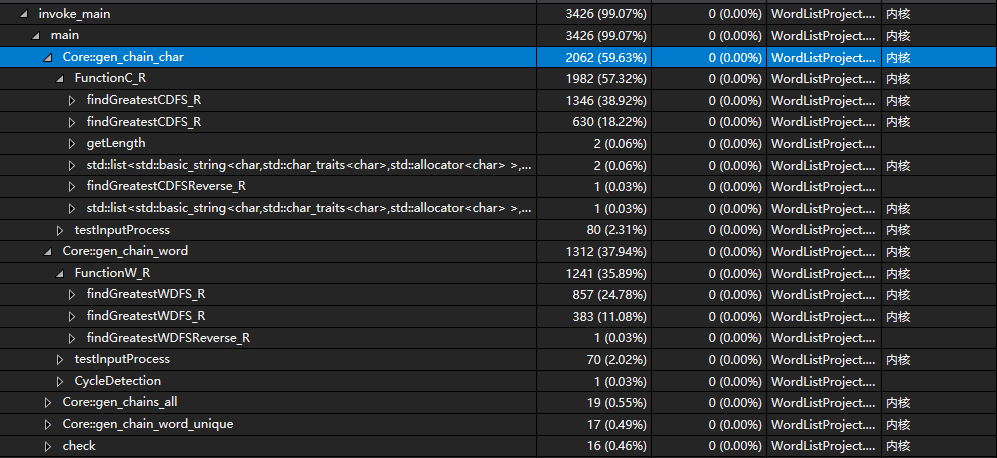
对于-noR,可以通过不再读入两个以上的同样首尾的单词(a---a格式可以读入两个)来降低其读入的时间开销。
7. Design by Contract, Code Contract
契约式编程是一种设计方法,为传统的抽象数据类型增加了先验条件、后验条件和不变式。通过增加contract实现对函数、方法、接口调用的参数规范,从语法、语义上对调用接口进行了封装保护。比如.NET的代码协议中,contract可以在运行时提供自动测试工具,过滤掉不满足先决条件的测试参数,或在不运行程序时自动检查隐式契约如空指针或越界等情况,或调用程序员的显式契约。
契约式编程对程序语言要求很高,需要有机制来验证契约的成立,可以使用断言机制但是仍有语言不包含这些机制,而且契约的机制并没有统一标准,因此存在语言与语言之间、项目之间契约模块的不同。
契约的思想要求调用者一方根据接口的要求来调用,被调用者则需满足测试要求条件之内的正确性。这保证了双方地位的平等,与以往被调用者需要考虑全所有的情况并给出相应的应对来保证准确性更加安全,可靠,同时也能够使得程序测试或者调用时更加高效,有序。
在这次的结对编程中,我们保证了core的接口定义,参数要求范围内程序运行的正确性,生成了dll模块。我们要求了输入的result要是一个提前开了20000个指针类型空间的指针,严格要求inputLen和input所包含的字符串数量相同。
与别组交换core进行测试的时候,也同样要遵循该组对输入参数的规定。例如在此次交换的小组,除了课程组中原本的参数类型规定,该组的契约要求了输入的result要是一个提前开了20000个指针类型空间的指针,输入的char** input只能包含无重复输入的全小写英文单词,输入参数head,tail只能输入小写英文字母。这样就要求我们在调用时,提前将所有的单词串做去重处理,并将不符合要求的字符单词处理了,以及在输入head和tail时保证该参数的正确性。
8. 单元测试
单元测试覆盖率如下:
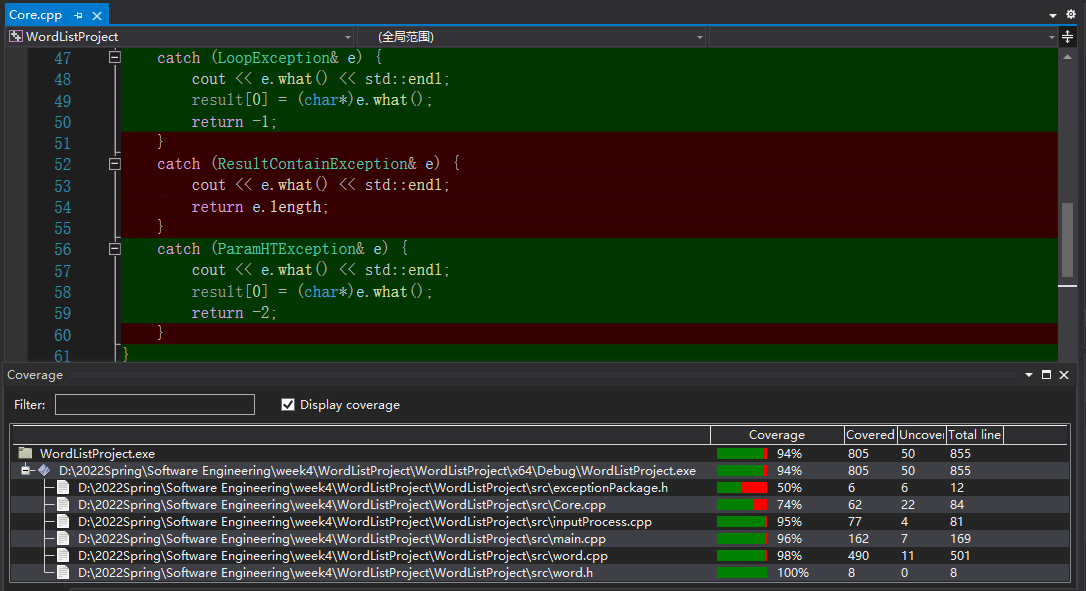
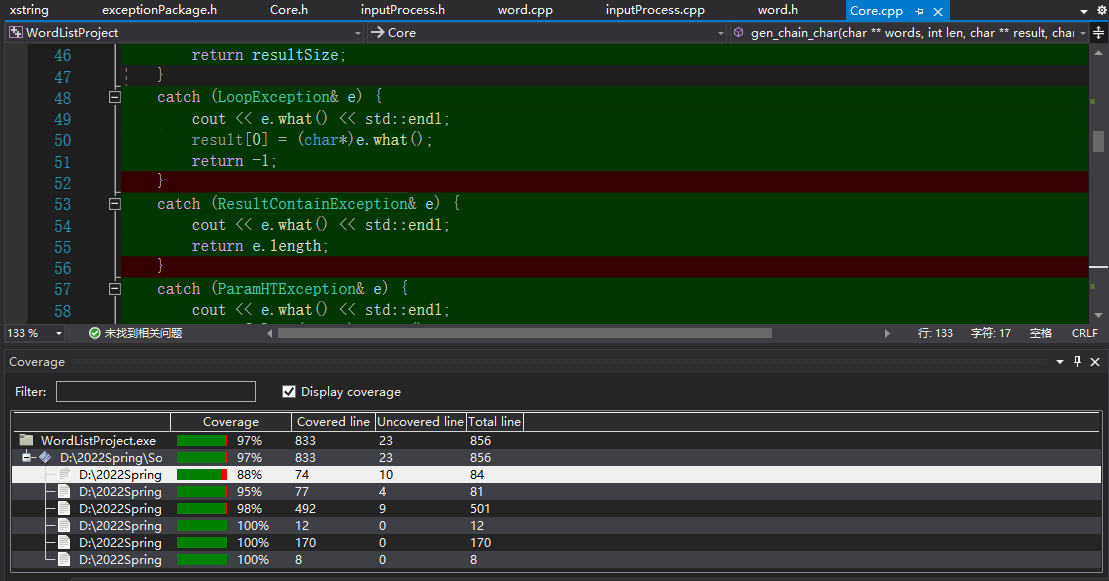
8.1 测试函数说明
init(char** inputw,int inLenw):将测试用例导入;
void check(int refLen,char *refAns[]):将参考结果导入,如果refLen是-1,则默认跳过assert核对环节;
void init(char** inputw,int inLenw) {
input = inputw;
inLen = inLenw;
}
void check(int refLen,char *refAns[]) {
cout << len << endl;
if (true) {
for (int i = 0; i < len; i++) {
const char* tmpRes = result[i];
cout << tmpRes << endl;
}
}
else {
assert(refLen == len);
for (int i = 0; i < len && i < refLen; i++) {
const char* tmpRef = refAns[i];
const char* tmpRes = result[i];
assert(strcmp(tmpRef, tmpRes) == 0);
cout << tmpRes << endl;
}
}
cout << "--------times " << times << " end ----" << endl;
times++;
len = 0;
}
8.2 正确性测试
构造思路
对于所有
-
单词样例
-
传入的单词大小写
-
传入重复单词
-
-
无链
-
传入的 input 数列是否为空
-
只有一个单词成立是否会被识别为链输出
-
-
有链
-
单链
-
是否有形如
axxxxa ax的词组
-
-
多链
-
是否有会被重复使用到的单词如
"ab"之于da ca
-
-
-
有环
W/C
-
-r 带环
-
-h 有参数,以该单词为首,是否存在链
-
-t 有参数,以该单词为首,是否存在链
-
样例中存在一个以 word 为标准的最长链和一个以 char 为标准的最长链
/*-------M/N-------*/
const int inLenN00 = 0;
const char* inputN00 = NULL;
init((char**)inputN00, inLenN00);
len = Core::gen_chains_all(input, inLen, result);
check(-1,NULL);
const int inLenN0 = 4;
const char* inputN0[inLenN0] = { "aend", "OF", "the", "World" };
const int refLenN0 = 1;
const char* refAnsN0[refLenN0] = { "thea aend" };
init((char** )inputN0, inLenN0);
len = Core::gen_chains_all(input, inLen, result);
check(refLenN0, (char**)refAnsN0);
const int inLenN1 = 10;
const char* inputN1[inLenN1] = { "ab", "bc", "cd", "de", "af", "fg", "gh", "aa", "kk", "lmopq" };
init((char**)inputN2, inLenN2);
len = Core::gen_chains_all(input, inLen, result);
check(-1,NULL);
len = Core::gen_chain_word_unique(input, inLen, result);
check(-1,NULL);
const int inLenM0 = 10;
const char* inputM0[inLenM0] = { "ab", "bc", "cd", "de", "af", "fg", "gh", "aa", "kk", "lmopq" };
const int refLenM0 = 4;
const char* refAnsM0[refLenM0] = {"ab","bc","cd","de"};
init((char**)inputM0, inLenM0);
len = Core::gen_chain_word_unique(input, inLen, result);
check(refLenM0, (char**)refAnsM0);
/*----------W/C_NoR-------*/
const int inLenW1 = 10;
const char* inputW1[inLenW1] = { "AB", "bc", "cd", "de", "af", "fg", "gh", "aa", "kk", "kxxxxxxxxxxxxlmopq" };
const int refLenW11 = 4;
const char* refAnsW11[refLenW11] = { "aa","ab", "bc", "cd" };
len = W(input, inLen, result,