Illustrated Transformer笔记
Attention Is All You Need
编码器端
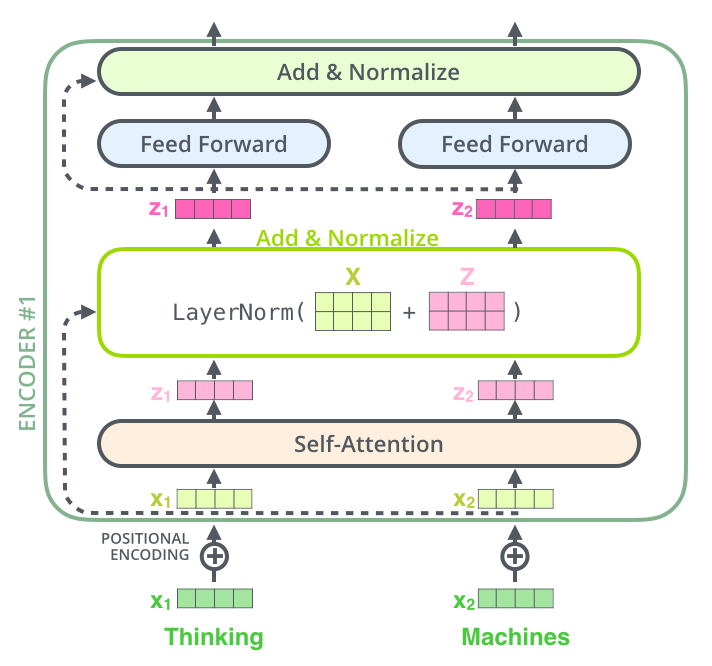
Self-attention层
用处:将对其他相关单词的“理解”融入我们当前正在处理的单词的方法,类似于RNN通过保持隐藏状态让 RNN 将其已处理的先前单词/向量的表示与当前正在处理的单词/向量结合起来
将单词输入转化为Embedding之后,将Embedding和Q K V三个矩阵相乘,便可以获得一个查询向量\(q_i\)、一个键向量\(k_i\)和一个值向量\(v_i\)
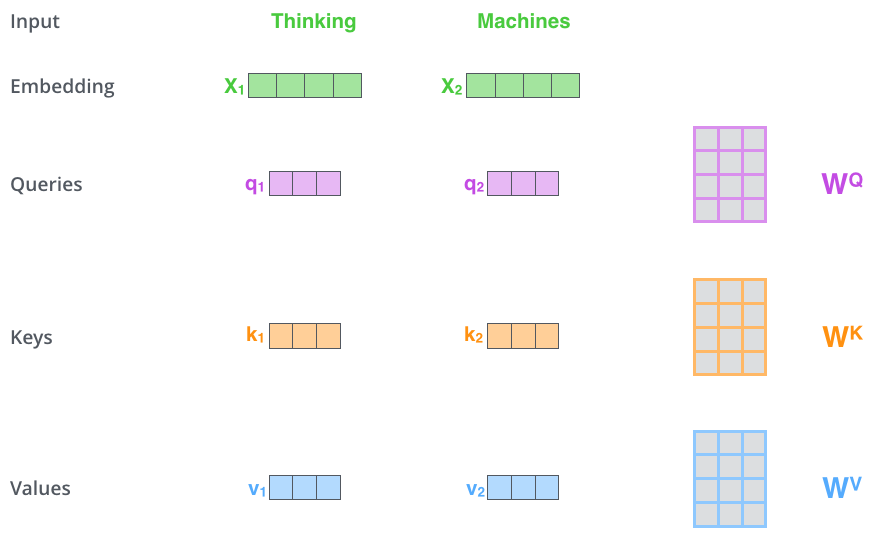
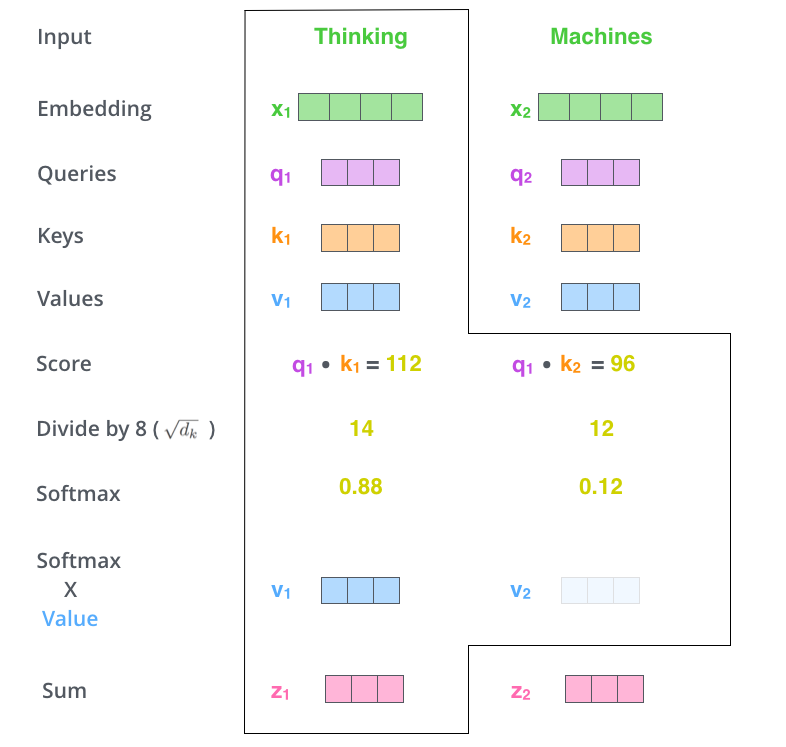
有了\(q_i\)和\(k_i\),我们就可以根据这个词对输入句子的每个单词进行评分。分数决定了我们在某个位置编码单词时对输入句子其他部分的关注程度。通过计算\(q_i \cdot k_i\),获得这个分数。
之后,我们将这些分数除以 8(论文中使用的关键向量维度64的平方根 - 8。这会导致更稳定的梯度。这里可能还有其他可能的值,但这是默认值),然后将结果传递给 softmax 运算,最终再乘以\(v_i\)向量
使用矩阵表示上面的流程
Z矩阵就是self-attention的输出
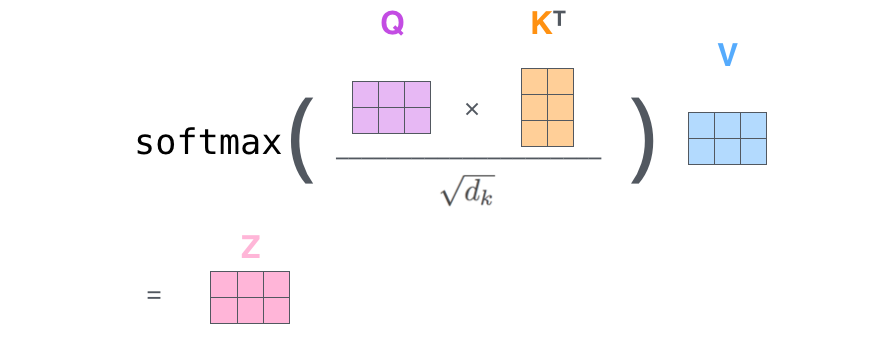
多头注意力本质:多个独立的Q K V矩阵
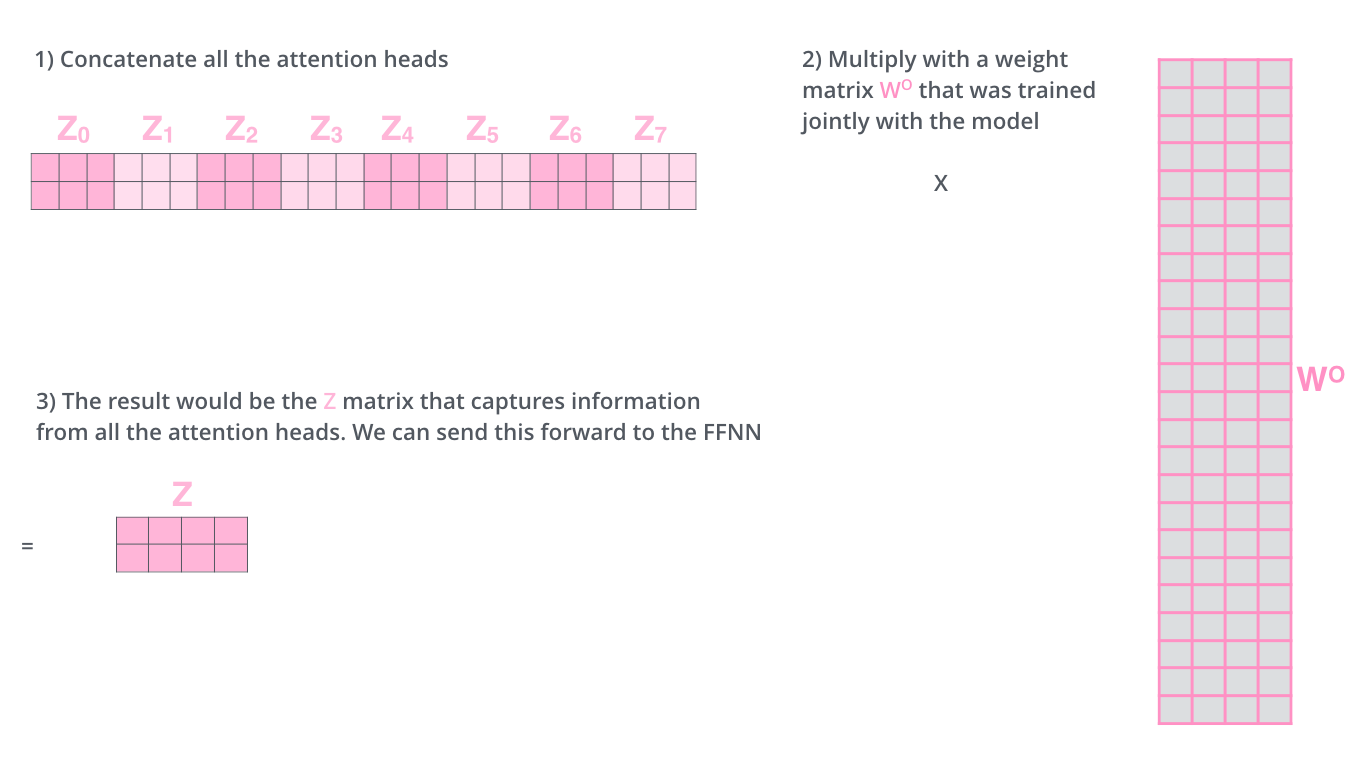
但是前馈层并不期望八个(多头的默认数目)矩阵——它期望一个矩阵(每个单词一个向量)。所以我们需要一种方法将这八个矩阵压缩成一个矩阵。我们该怎么做呢?我们将矩阵连接起来,然后将它们乘以附加权重矩阵 \(W^O\)。
使用位置编码表示序列的顺序
到目前为止,我们所描述的模型缺少一件事,那就是解释输入序列中单词顺序的方法。
为了解决这个问题,Transformer 为每个输入嵌入添加了一个向量。这些向量遵循模型学习到的特定模式,这有助于确定每个单词的位置,或序列中不同单词之间的距离。这里的直觉是,将这些值添加到嵌入中后,一旦嵌入向量被投影到 \(Q/K/V\) 向量中并在点积注意期间,它们之间就会提供有意义的距离。
解码器端
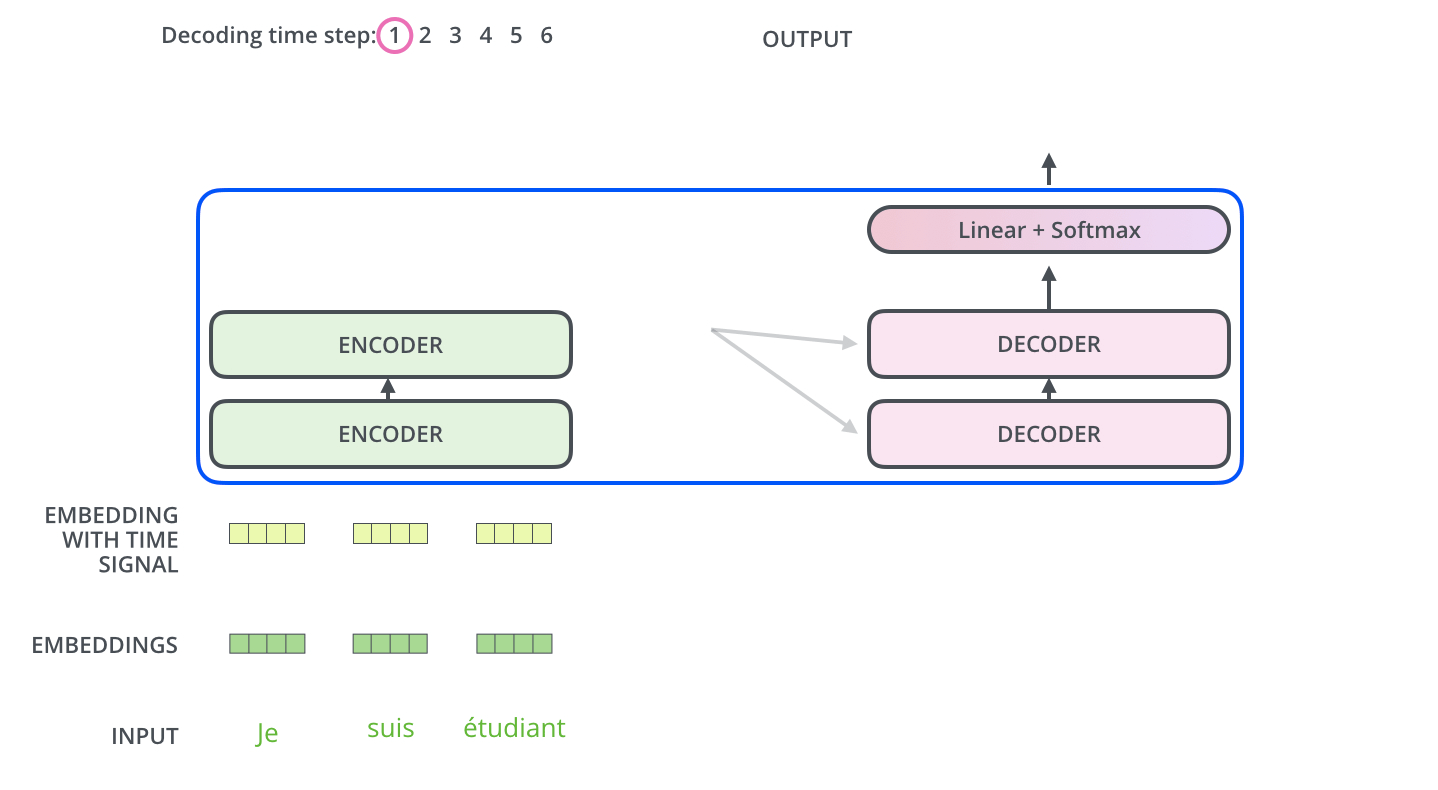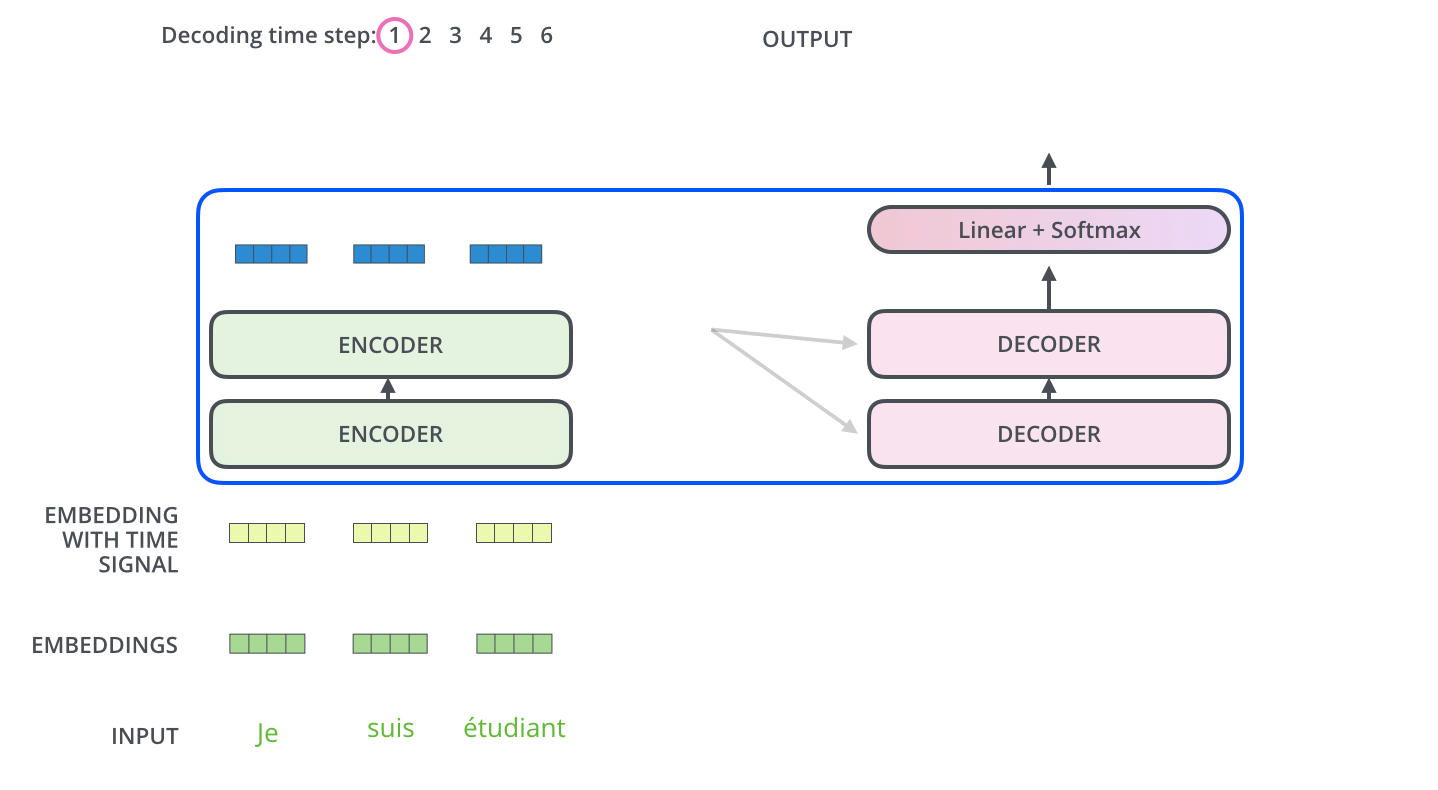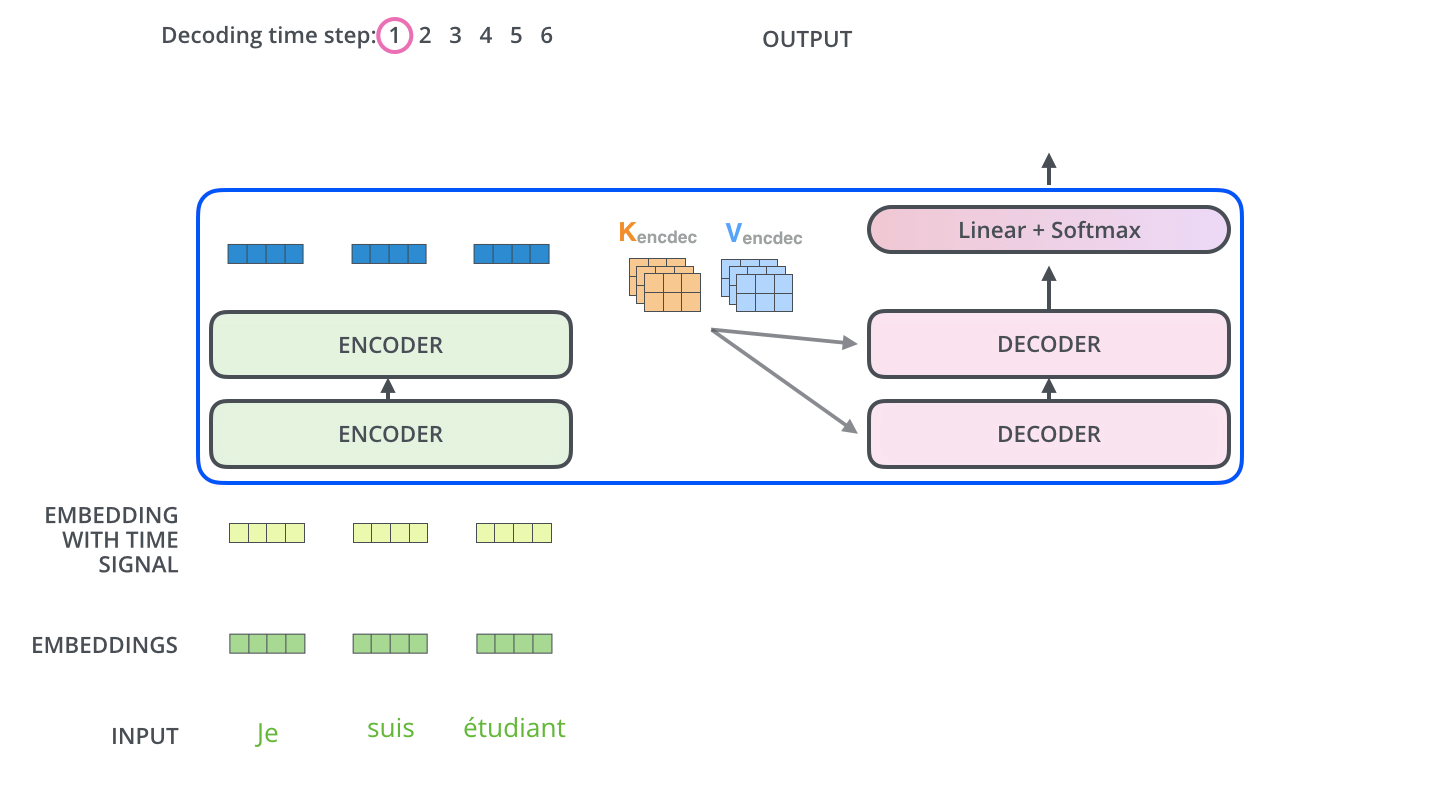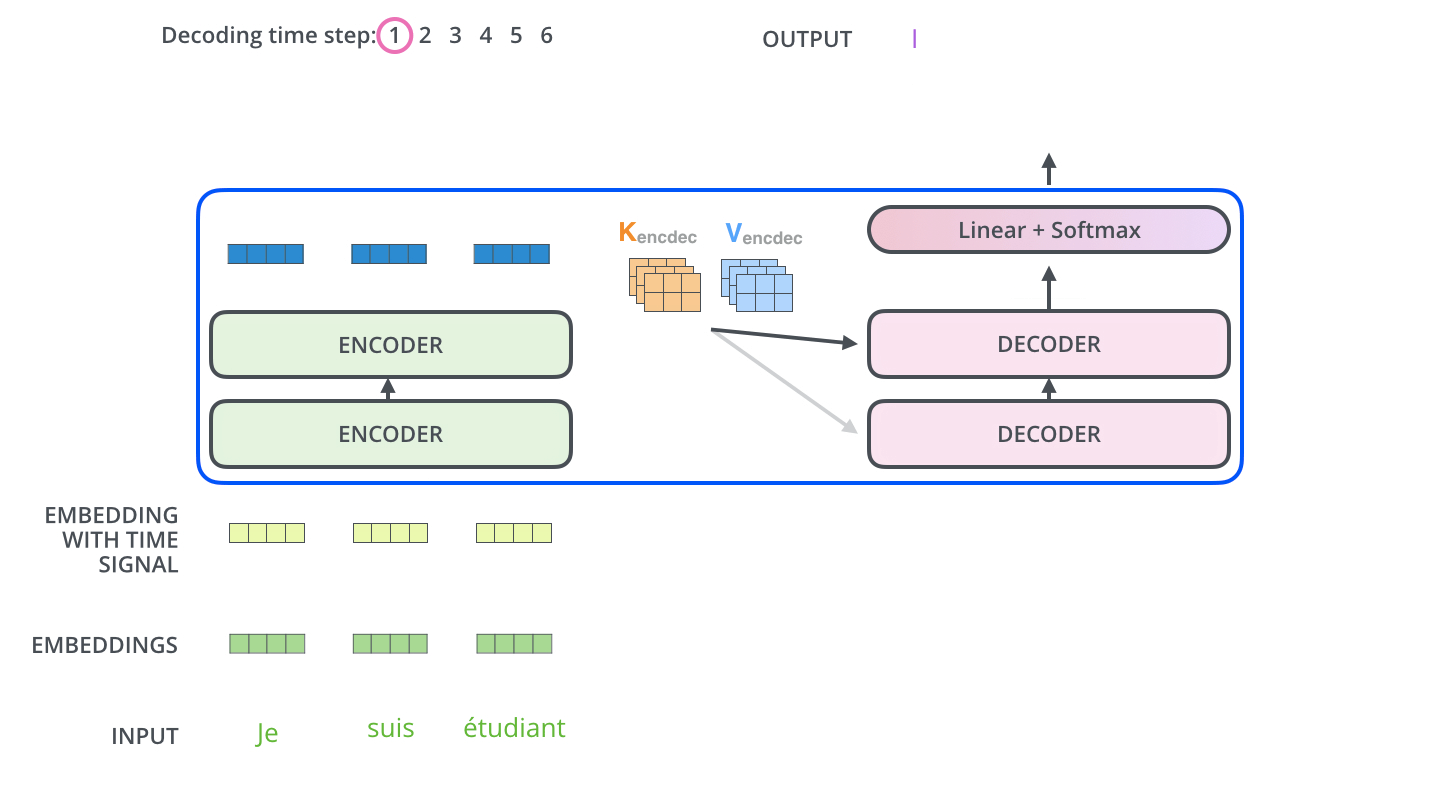
Encoder-Decoder Attention层
在上述公式中,\(d_k\) 表示的是矩阵的维度,而不是向量的维度。
具体来说,\(d_k\) 是注意力机制中查询(query)和键(key)的维度大小。在自注意力机制(self-attention)中,输入向量会被分成多个注意力头,每个头都会有自己的查询、键和值。\(d_k\) 用来表示每个注意力头中查询和键的维度大小,以便在计算注意力权重时进行归一化。
在公式中,\(Q\), \(K\) 和 \(V\) 都是矩阵形式的输入,而 \(d_k\) 表示了查询和键矩阵的维度大小。该维度大小通常与输入矩阵的特征维度相对应,以保持一致性和有效性。
为什么采用self-attention
1、每层的计算量减少
2、在训练时,可以并行计算
3、网络中长范围的相关性,当两个位置的输入输出之前的路径更短时,更容易学习到两者之间的相关性。感觉有点吸取了CNN和RNN中梯度消失和梯度爆炸的教训
4、self-attention可以得到更具有解释性的模型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号