【第一章】好的推荐系统
推荐系统的实验方法
- 离线实验
- 用户调查
- 在线实验
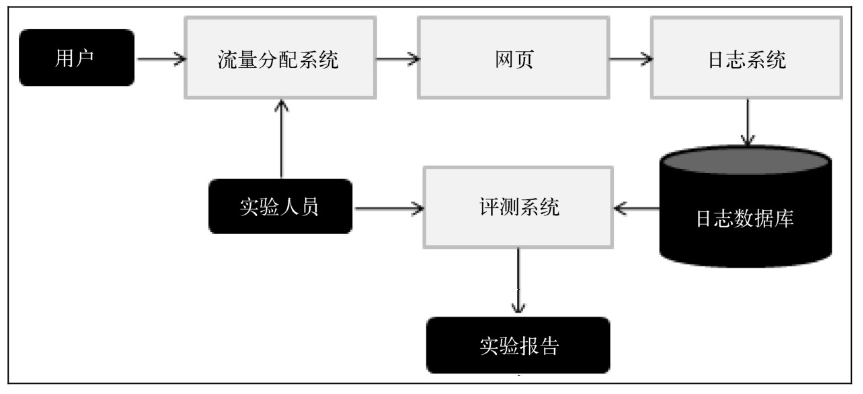
AB测试: 通过一定的规则将用户随机分成几组,并对不同组的用户采用不同的算法,然后通过统计不同组用户的各种不同的评测指标比较不同算法
- 优点:可以公平获得不同算法实际在线时的性能指标,包括商业上关注的指标
- 缺点:周期比较长,必须进行长期的实验才能得到可靠的结果。其次,不同团队同时进行的AB测试可能会互相影响
推荐系统评测的指标:
1. 用户满意度
2. 预测准确度
- 评分预测:评分预测的预测准确度一般通过均方根误差(RMSE)和平均绝对误差(MAE)计算
关于RMSE和MAE这两个指标的优缺点,Netflix认为RMSE加大了对预测不准的用户物品评分的惩罚(平方项的惩罚),因而对系统的评测更加苛刻。研究表明,如果评分系统是基于整数建立的(即用户给的评分都是整数),那么对预测结果取整会降低MAE的误差。 - TOP-N推荐(比评分预测更有现实意义):TopN推荐的预测准确率一般通过准确率(precision)/召回率(recall)度量。
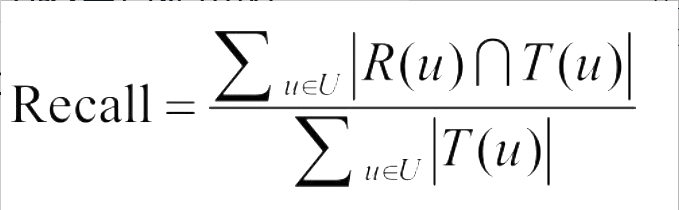
3. 覆盖率
-
覆盖率(coverage)描述一个推荐系统对物品长尾的发掘能力。一个好的推荐系统不仅需要有比较高的用户满意度,也要有较高的覆盖率。覆盖率为100%的系统可以有无数的物品流行度分布。为了更细致地描述推荐系统发掘长尾的能力,需要统计推荐列表中不同物品出现次数的分布。如果所有的物品都出现在推荐列表中,且出现的次数差不多,那么推荐系统发掘长尾的能力就很好。因此,可以通过研究物品在推荐列表中出现次数的分布描述推荐系统挖掘长尾的能力。如果这个分布比较平,那么说明推荐系统的覆盖率较高,而如果这个分布较陡峭,说明推荐系统的覆盖率较低。
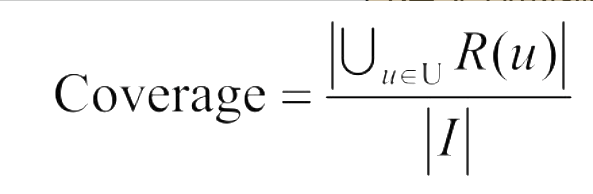
-
定义方法:信息熵和Gini Index
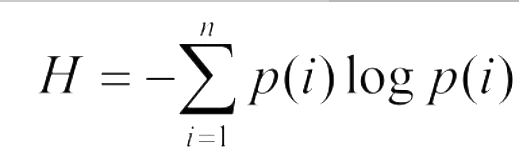
4. 多样性
- 用户兴趣是变化的,广泛覆盖用户的兴趣点有助于让用户在更多的时间内都被推荐符合兴趣的内容
- 假设s(i,j)∈[0,1]定义了物品i和j之间的相似度,那么用户u的推荐列表R(u)的多样性定义如下:

- 推荐系统的整体多样性可以定义为所有用户推荐列表多样性的平均值:
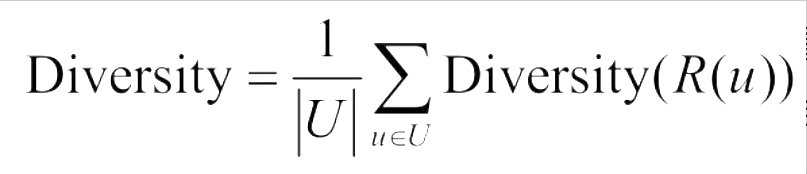
- 推荐系统的整体多样性可以定义为所有用户推荐列表多样性的平均值:
5. 新颖性
- 新颖的推荐是指给用户推荐那些他们以前没有听说过的物品。在一个网站中实现新颖性的最简单办法是,把那些用户之前在网站中对其有过行为的物品从推荐列表中过滤掉。
- 惊喜度(serendipity):之前不知道用户喜欢这个类别,但是一经推送,用户反馈很好,说明惊喜度高
- 信任度 用户信任推荐系统有利于促进用户的反馈和交互。可以通过推荐过程透明化和增强基于好友喜欢过的东西推荐来提升
6. 时效性
- 第一点,推荐系统需要实时地更新推荐列表来满足用户新的行为变化。比如,当一个用户购买了iPhone,如果推荐系统能够立即给他推荐相关配件,那么肯定比第二天再给用户推荐相关配件更有价值。
- 第二点,实时性的第二个方面是推荐系统需要能够将新加入系统的物品推荐给用户。这主要考验了推荐系统处理物品冷启动的能力
7. 健壮性
任何一个能带来利益的算法系统都会被人攻击,这方面最典型的例子就是搜索引擎。搜索引擎的作弊和反作弊斗争异常激烈,这是因为如果能让自己的商品成为热门搜索词的第一个搜索结果,会带来极大的商业利益。
获取指标的方式:

评测维度
测系统中还需要考虑评测维度,比如一个推荐算法,虽然整体性能不好,但可能在某种情况下性能比较好,而增加评测维度的目的就是知道一个算法在什么情况下性能最好。这样可以为融合不同推荐算法取得最好的整体性能带来参考。一般来说,评测维度分为如下3种。
- 用户维度 主要包括用户的人口统计学信息、活跃度以及是不是新用户等。
- 物品维度 包括物品的属性信息、流行度、平均分以及是不是新加入的物品等。
- 时间维度 包括季节,是工作日还是周末,是白天还是晚上等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号