

hystrix-go熔断框架源码分析理解(一)
简介:
hystrix 由 Netflix 开源的一个集流量控制、熔断、容错、重试及服务降级于一身的 Java 库。hystrix-go 则为 go 语言版
简单使用:通过回调传入正常的处理逻辑和出现错误的兜底逻辑,异步调用使用Go方法,同步调用使用Do方法
msg := "success" _ = hystrix.Go("test", func() error { _, err := http.Get("https://www.baidu.com") if err != nil { fmt.Printf("请求失败:%v", err) return err } return nil }, func(err error) error { fmt.Printf("handle error:%v\n", err) msg = fmt.Sprintf("%v",err) return err })
源码分析:
Go函数底层调用Goc
func Go(name string, run runFunc, fallback fallbackFunc) chan error { runC := func(ctx context.Context) error { return run() } var fallbackC fallbackFuncC if fallback != nil { fallbackC = func(ctx context.Context, err error) error { return fallback(err) } } return GoC(context.Background(), name, runC, fallbackC) }
Goc传入上下文对象和两段处理逻辑,是hystric-go的核心处理逻辑
func GoC(ctx context.Context, name string, run runFuncC, fallback fallbackFuncC) chan error { #1.可以简单理解为这次请求
cmd := &command{ run: run, fallback: fallback, start: time.Now(), errChan: make(chan error, 1), finished: make(chan bool, 1), } #2.获取熔断器 circuit, _, err := GetCircuit(name) if err != nil { cmd.errChan <- err return cmd.errChan } cmd.circuit = circuit ticketCond := sync.NewCond(cmd) ticketChecked := false #3.令牌返回逻辑
returnTicket := func() { cmd.Lock() for !ticketChecked { ticketCond.Wait() } cmd.circuit.executorPool.Return(cmd.ticket) cmd.Unlock() } returnOnce := &sync.Once{} #4.上报此次请求处理结果逻辑
reportAllEvent := func() { err := cmd.circuit.ReportEvent(cmd.events, cmd.start, cmd.runDuration) if err != nil { log.Printf(err.Error()) } } go func() {
#5.此次请求结束的标志 defer func() { cmd.finished <- true }()
#6.不允许请求,熔断器开启,直接走兜底处理逻辑
if !cmd.circuit.AllowRequest() { cmd.Lock() // It's safe for another goroutine to go ahead releasing a nil ticket. ticketChecked = true ticketCond.Signal() cmd.Unlock() returnOnce.Do(func() { returnTicket() cmd.errorWithFallback(ctx, ErrCircuitOpen) reportAllEvent() }) return }
#可以请求, cmd.Lock() select {
#7.可以获取到令牌,走正常处理逻辑 case cmd.ticket = <-circuit.executorPool.Tickets: ticketChecked = true ticketCond.Signal() cmd.Unlock() default:
#8.获取不到令牌,走兜底逻辑 ticketChecked = true ticketCond.Signal() cmd.Unlock() returnOnce.Do(func() { returnTicket() cmd.errorWithFallback(ctx, ErrMaxConcurrency) reportAllEvent() }) return } runStart := time.Now() runErr := run(ctx) returnOnce.Do(func() { defer reportAllEvent() cmd.runDuration = time.Since(runStart) returnTicket() if runErr != nil { cmd.errorWithFallback(ctx, runErr) return } cmd.reportEvent("success") }) }() #9.专门开的协程对超时情况进行兜底处理 go func() { timer := time.NewTimer(getSettings(name).Timeout) defer timer.Stop() select { case <-cmd.finished: // returnOnce has been executed in another goroutine case <-ctx.Done(): returnOnce.Do(func() { returnTicket() cmd.errorWithFallback(ctx, ctx.Err()) reportAllEvent() }) return case <-timer.C: returnOnce.Do(func() { returnTicket() cmd.errorWithFallback(ctx, ErrTimeout) reportAllEvent() }) return } }() return cmd.errChan }
这段代码可以总结为这样一个流程图:
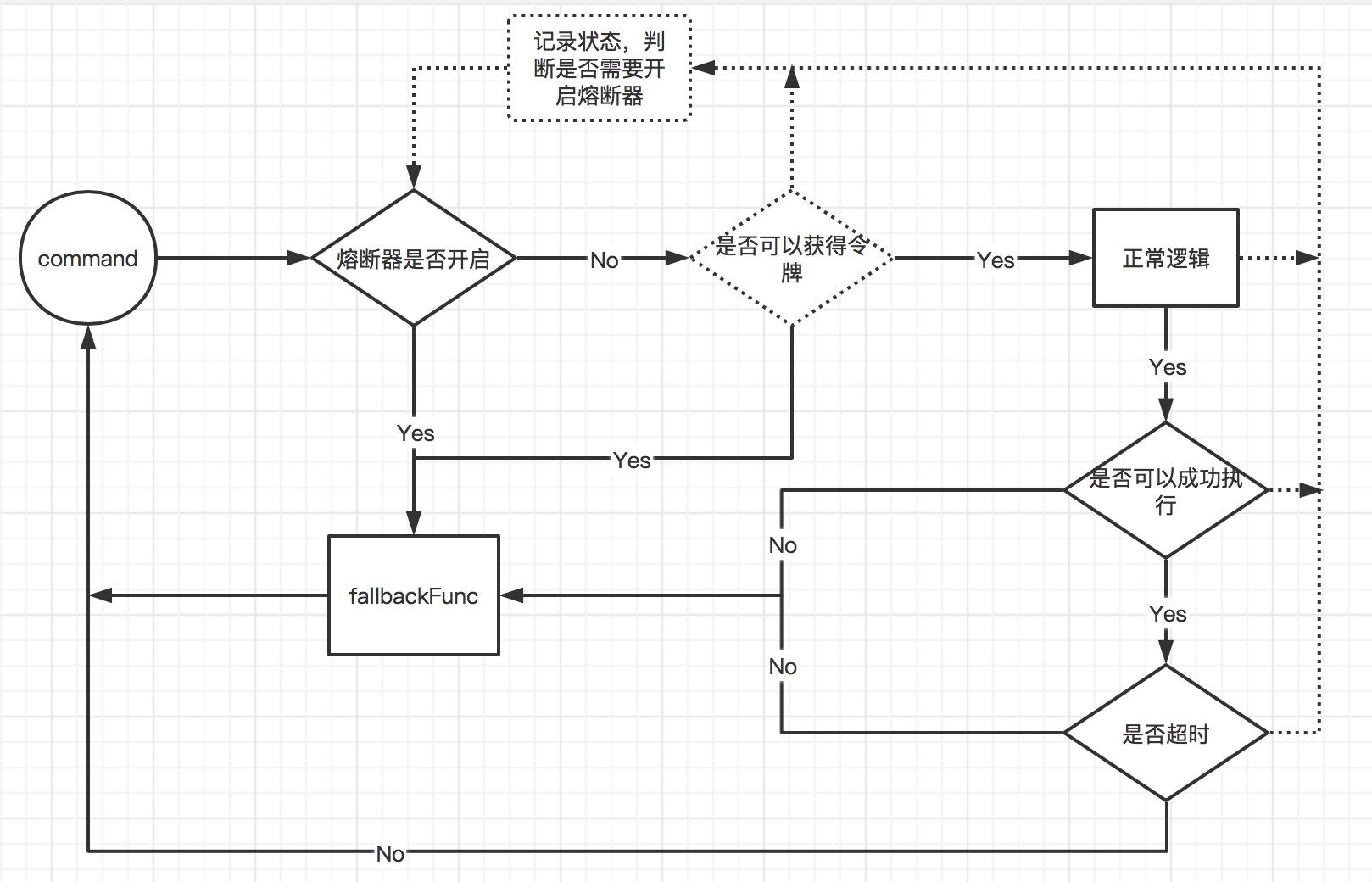
在看这段逻辑会有这样几个问题:
1.熔断器何时开启,如何开启?
2.熔断器何时关闭?
3.如何去上报这些事件,包括成功的失败的?
4.如何对这些上报事件进行处理
5.令牌的逻辑是什么?
首先在使用go-hystrix时会有一个默认配置过程:
hystrix.ConfigureCommand("test", hystrix.CommandConfig{ Timeout: 1000, MaxConcurrentRequests: 10, SleepWindow: 5000, RequestVolumeThreshold: 20, ErrorPercentThreshold: 10, })
- Timeout: 执行command的超时时间。
默认时间是1000毫秒 - MaxConcurrentRequests:command的最大并发量
默认值是10 - SleepWindow:当熔断器被打开后,SleepWindow的时间就是控制过多久后去尝试服务是否可用了。
默认值是5000毫秒 - RequestVolumeThreshold: 一个统计窗口10秒内请求数量。达到这个请求数量后才去判断是否要开启熔断。
默认值是20 - ErrorPercentThreshold:错误百分比,请求数量大于等于
RequestVolumeThreshold并且错误率到达这个百分比后就会启动熔断默认值是50
每一个请求都会持有一个熔断器cmd.circuit = circuit
熔断器结构:
type CircuitBreaker struct { Name string open bool forceOpen bool mutex *sync.RWMutex openedOrLastTestedTime int64 executorPool *executorPool metrics *metricExchange }
metrics就是去处理这些上报事件的,metricExchange结构和初始化过程:
type metricExchange struct { Name string Updates chan *commandExecution Mutex *sync.RWMutex metricCollectors []metricCollector.MetricCollector } func newMetricExchange(name string) *metricExchange { m := &metricExchange{} m.Name = name m.Updates = make(chan *commandExecution, 2000) m.Mutex = &sync.RWMutex{} m.metricCollectors = metricCollector.Registry.InitializeMetricCollectors(name) m.Reset() go m.Monitor() return m }
go m.Monitor()就是开启一个单独协程不断进行处理updates,updates就是记录的每一个上报事件,Monitor中间会不断调用IncrementMetrics
func (m *metricExchange) Monitor() { for update := range m.Updates { // we only grab a read lock to make sure Reset() isn't changing the numbers. m.Mutex.RLock() totalDuration := time.Since(update.Start) wg := &sync.WaitGroup{} for _, collector := range m.metricCollectors { wg.Add(1) go m.IncrementMetrics(wg, collector, update, totalDuration) } wg.Wait() m.Mutex.RUnlock() } } func (m *metricExchange) IncrementMetrics(wg *sync.WaitGroup, collector metricCollector.MetricCollector, update *commandExecution, totalDuration time.Duration) { // granular metrics r := metricCollector.MetricResult{ Attempts: 1, TotalDuration: totalDuration, RunDuration: update.RunDuration, ConcurrencyInUse: update.ConcurrencyInUse, } switch update.Types[0] { case "success": r.Successes = 1 case "failure": r.Failures = 1 r.Errors = 1 case "rejected": r.Rejects = 1 r.Errors = 1 case "short-circuit": r.ShortCircuits = 1 r.Errors = 1 case "timeout": r.Timeouts = 1 r.Errors = 1 case "context_canceled": r.ContextCanceled = 1 case "context_deadline_exceeded": r.ContextDeadlineExceeded = 1 } if len(update.Types) > 1 { // fallback metrics if update.Types[1] == "fallback-success" { r.FallbackSuccesses = 1 } if update.Types[1] == "fallback-failure" { r.FallbackFailures = 1 } } collector.Update(r) wg.Done() }
其中collector.Update(r)其实就是默认收集器的处理方式,可以看到每个metrixExchange都是可以单独持有collector的,metricCollectors []metricCollector.MetricCollector,在实际生产环境中,是可以单独对collector进行定制化处理,针对需要处理指标来实现相应的方法,默认收集器其实已经涵盖大部分场景了
type DefaultMetricCollector struct {
mutex *sync.RWMutex
numRequests *rolling.Number
errors *rolling.Number
successes *rolling.Number
failures *rolling.Number
rejects *rolling.Number
shortCircuits *rolling.Number
timeouts *rolling.Number
contextCanceled *rolling.Number
contextDeadlineExceeded *rolling.Number
fallbackSuccesses *rolling.Number
fallbackFailures *rolling.Number
totalDuration *rolling.Timing
runDuration *rolling.Timing
}
func (d *DefaultMetricCollector) Update(r MetricResult) { d.mutex.RLock() defer d.mutex.RUnlock() d.numRequests.Increment(r.Attempts) d.errors.Increment(r.Errors) d.successes.Increment(r.Successes) d.failures.Increment(r.Failures) d.rejects.Increment(r.Rejects) d.shortCircuits.Increment(r.ShortCircuits) d.timeouts.Increment(r.Timeouts) d.fallbackSuccesses.Increment(r.FallbackSuccesses) d.fallbackFailures.Increment(r.FallbackFailures) d.contextCanceled.Increment(r.ContextCanceled) d.contextDeadlineExceeded.Increment(r.ContextDeadlineExceeded) d.totalDuration.Add(r.TotalDuration) d.runDuration.Add(r.RunDuration) } // Reset resets all metrics in this collector to 0. func (d *DefaultMetricCollector) Reset() { d.mutex.Lock() defer d.mutex.Unlock() d.numRequests = rolling.NewNumber() d.errors = rolling.NewNumber() d.successes = rolling.NewNumber() d.rejects = rolling.NewNumber() d.shortCircuits = rolling.NewNumber() d.failures = rolling.NewNumber() d.timeouts = rolling.NewNumber() d.fallbackSuccesses = rolling.NewNumber() d.fallbackFailures = rolling.NewNumber() d.contextCanceled = rolling.NewNumber() d.contextDeadlineExceeded = rolling.NewNumber() d.totalDuration = rolling.NewTiming() d.runDuration = rolling.NewTiming() }
因此问题4就解决了,其中就是熔断器开启的时候就开启了单独的协程在不断对update进行处理,并把这些数据记录挂载到了collector上面
在此可以补充一下记录事件的存储细节,*rolling.Number结构:
type Number struct { Buckets map[int64]*numberBucket Mutex *sync.RWMutex } type numberBucket struct { Value float64 } func (r *Number) getCurrentBucket() *numberBucket { now := time.Now().Unix() var bucket *numberBucket var ok bool if bucket, ok = r.Buckets[now]; !ok { bucket = &numberBucket{} r.Buckets[now] = bucket } return bucket } func (r *Number) removeOldBuckets() { now := time.Now().Unix() - 10 for timestamp := range r.Buckets { // TODO: configurable rolling window if timestamp <= now { delete(r.Buckets, timestamp) } } }
Buckets是把每个时间戳(秒级)作为key的,记录每一秒的各种事件次数,这种实现方式内存占用是否过高
本文来自博客园,作者:LeeJuly,转载请注明原文链接:https://www.cnblogs.com/peterleee/p/15957267.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号