
正确理解Golang string 及底层结构
1.Go语言string最底层是byte数组
具体由一个结构体包装而成,其中包括了指向字节数组的指针和字节数组的长度
type StringHeader struct { Data uintptr Len int }
底层如何将string转换为[]byte
func str2bytes(s string) []byte { p := make([]byte, len(s)) for i := 0; i < len(s); i++ { c := s[i] p[i] = c } return p }
如何将string不通过拷贝的方式转为byte数组?
func main() { a :="test" ssh := *(*reflect.StringHeader)(unsafe.Pointer(&a)) b := *(*[]byte)(unsafe.Pointer(&ssh)) fmt.Printf("%v",b) }
unsafe.Pointer(&a)方法可以得到变量a的地址。
(*reflect.StringHeader)(unsafe.Pointer(&a)) 可以把字符串a转成底层结构的形式。
(*[]byte)(unsafe.Pointer(&ssh)) 可以把ssh底层结构体转成byte的切片的指针。
再通过 *转为指针指向的实际内容。
底层将[]byte转换为string
func bytes2str(s []byte) (p string) { data := make([]byte, len(s)) for i, c := range s { data[i] = c } hdr := (*reflect.StringHeader)(unsafe.Pointer(&p))#unsafe.Pointer()获取地址的函数 hdr.Data = uintptr(unsafe.Pointer(&data[0])) hdr.Len = len(s) return p }
在结构体中存储的值在内存中是连续的,顺便了解下unsafe.Pointer这个函数吧
type Num struct { i string j int64 k string } func main() { n := Num{i: "EDDYCJY", j: 1, k: "dddd"} nPointer := unsafe.Pointer(&n) niPointer := (*string)(nPointer) *niPointer = "haha" // 这里反向加是因为内存是栈的原因 njPointer := (*int64)(unsafe.Pointer(uintptr(nPointer) + unsafe.Offsetof(n.j))) *njPointer = 3 nkPointer := (*string)(unsafe.Pointer(uintptr(nPointer) + unsafe.Offsetof(n.k))) *nkPointer = "hehe" fmt.Println(n.i, n.j, n.k) } #haha hehe 3
2.在Golang底层byte又是怎样的结构
byte和uint8是一样的,不能和int8进行转换
直接对一个字符串用len(str),计算的是byte数组的大小,如果有其他字符,比如中文字符(占用3个字节)其实是不准的,需要将string转换成runes数组,[]rune(str),rune底层采用unicode编码(而底层又是通过utf-8来实现的)
utf-8底层是变长字节,比如一个英文字符底层就一个字节,中文就三个字节,其他字符可能又不相同
utf-8底层又是如何分辨一个英文字符还是中文字符的呢,主要是通过字节的首位数组(比如字节第一个bit是0,往后读一个字节,110读两个字节)
utf-8更像底层的存储,实际读到内存中计算还是需要转为unicode(任意一个字符都与一个unicode有映射关系)
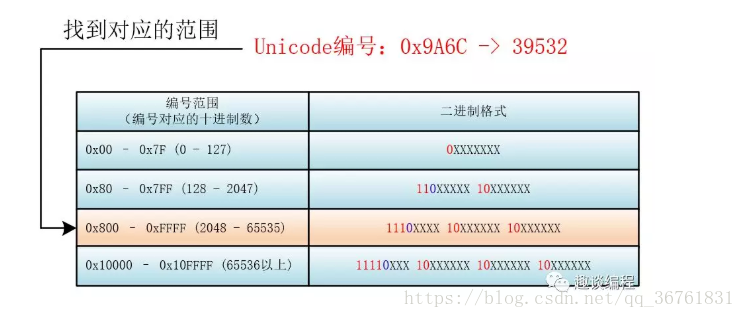
以一个实际的例子看一下
func main() { var s string = "人生" for i := range s { fmt.Println(i) fmt.Println(s[i]) } } 输出 0 228 3 231
底层实际把string转为rune了(所以只输出两次,但rune底层其实又是byte数组),然后又是作为byte数组进行遍历,0和3按byte数组下标确定,s[i]实际合并前几个byte
3.补充string和int之间的转换问题
string转成int: int, err := strconv.Atoi(string) string转成int64: int64, err := strconv.ParseInt(string, 10, 64) string到float64 float,err := strconv.ParseFloat(string,64) string到float32 float,err := strconv.ParseFloat(string,32) int转成string: string := strconv.Itoa(int) int64转成string: string := strconv.FormatInt(int64,10) float到string string := strconv.FormatFloat(float32,'E',-1,32) string := strconv.FormatFloat(float64,'E',-1,64) 同类型的就用强转符 int64_ := int64(1234)
额外比较两个字符串大小
strings.Compare(a, b) a>b return 1 ; a=b return 0; a<b return -1
4.strings常见函数
package main import ( "fmt" "strings" ) func main() { str := "hello world" fmt.Println(strings.Contains(str, "hello")) //true,是否包含子串 fmt.Println(strings.ContainsAny(str, "def")) //true,是否包含子串中任意一个字符 fmt.Println(strings.Count(str, "e")) //子串出现的次数,没有就返回0 fmt.Println(strings.EqualFold(str, "helloworlD")) //判断串是否相同,不区分大小写 for _, v := range strings.Fields(str) { //将子串以空格为分隔符拆分成若干个字符串,若成功则返回分割后的字符串切片 fmt.Println(v) } fmt.Println(strings.HasPrefix(str, "he")) //判断是否以子串开头 fmt.Println(strings.HasSuffix("str ", "orld")) //判断是否以子串结尾 fmt.Println(strings.Index(str, "e")) //判断子串第一次出现的位置,没有的话返回-1,LastIndex(s, sep string) int 返回最后出现的位置 fmt.Println(strings.IndexAny(str, "abc")) //返回子串任意一个字符出现的位置 s := []string{"foo", "baa", "bae"} fmt.Println(strings.Join(s, ", ")) //将string数组连接起来 fmt.Println(strings.Repeat(str, 3)) //将子串重复n次连接 str = "heLLo worLd Abc" fmt.Println(strings.ToUpper(str)) // "HELLO WORLD ABC" fmt.Println(strings.ToLower(str)) // "hello world abc" fmt.Println(strings.ToTitle(str)) // "HELLO WORLD ABC" fmt.Println(strings.Trim(str, "heob")) //删除父串中所有子串(父和子串都连续)中出现的字符 输出:LLo worLd Abc fmt.Println(strings.TrimSpace(" \t\n hello world \n\t\r\n")) //去除首尾部空格换行字符 fmt.Println(strings.Replace("ABAACEDF", "A", "a", 2)) //替换字符,n为从头到位找到的个数替换,-1表示全部替换 }
本文来自博客园,作者:LeeJuly,转载请注明原文链接:https://www.cnblogs.com/peterleee/p/13688725.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号