

理解操作系统内存管理
前沿:
如果存在一个程序,所需内存空间超过了计算机可以提供的实际内存,那么由于该程序无法装入内存所以也就无法运行。单纯的增加物理内存只能解决一部分问题,但是仍然会出现无法装入单个或者无法同时装入多个程序的问题。但是可以从逻辑的角度扩充内存容量,即可解决上述两种问题。基于局部性原理,在程序装入时,可以将程序的一部分装入内存,而将其余部分留在外存,就可以启动程序执行。在程序执行过程中,当所访问的信息不在内存时,由操作系统将所需要的部分调入内存,然后继续执行程序。另一方面,操作系统将内存中暂时不使用的内容换出到外存上,从而腾出空间存放将要调入内存的信息.
wiki:虚拟内存是计算机系统内存管理的一种技术。它使得应用程序认为它拥有连续可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。与没有使用虚拟内存技术的系统相比,使用这种技术的系统使得大型程序的编写变得更容易,对真正的物理内存(例如RAM)的使用也更有效率。(这里的虚拟内存其实应该指虚拟地址空间)
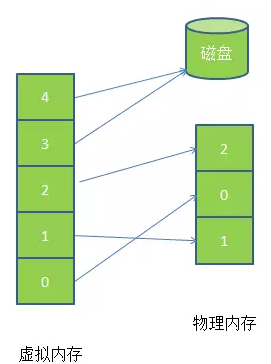
虚拟地址空间到物理地址的映射具体步骤:
虚拟内存实际上可以比物理内存大。当访问虚拟内存时,会通过MMU(内存管理单元)去匹配对应的物理地址,而如果虚拟内存的页并不存在于物理内存中,会产生缺页中断(物理内存页不存在,1.相关页被加载到内存,但没有向MMU注册 2.相关的页没有被加入到内存),从磁盘中取得缺的页放入内存,如果内存已满,还会根据某种算法将磁盘中的页换出。
而虚拟内存和物理内存的匹配是通过页表实现,页表存在MMU中,页表中每个项通常为32位,既4byte,除了存储虚拟地址和页框地址之外,还会存储一些标志位,比如是否缺页,是否修改过,写保护等。可以把MMU想象成一个接收虚拟地址项返回物理地址的方法。
虚拟地址空间到物理地址的映射具体步骤:
虚拟地址到物理地址和硬盘通过MMU建立一种一对一的关系, MMU 中包含了一个关于页表的缓存,称为翻译后备缓冲器(Translation Lookaside Buffer,TLB)。简而言之,TLB 的作用就是加速 MMU 的地址转换。
具体步骤:
1.CPU 产生一个虚拟地址
2.MMU 从 TLB 中获取页表,翻译成物理地址
3.MMU 把物理地址发送给主存
4.主存将地址对应的数据返回给 CPU
映射关系如下:
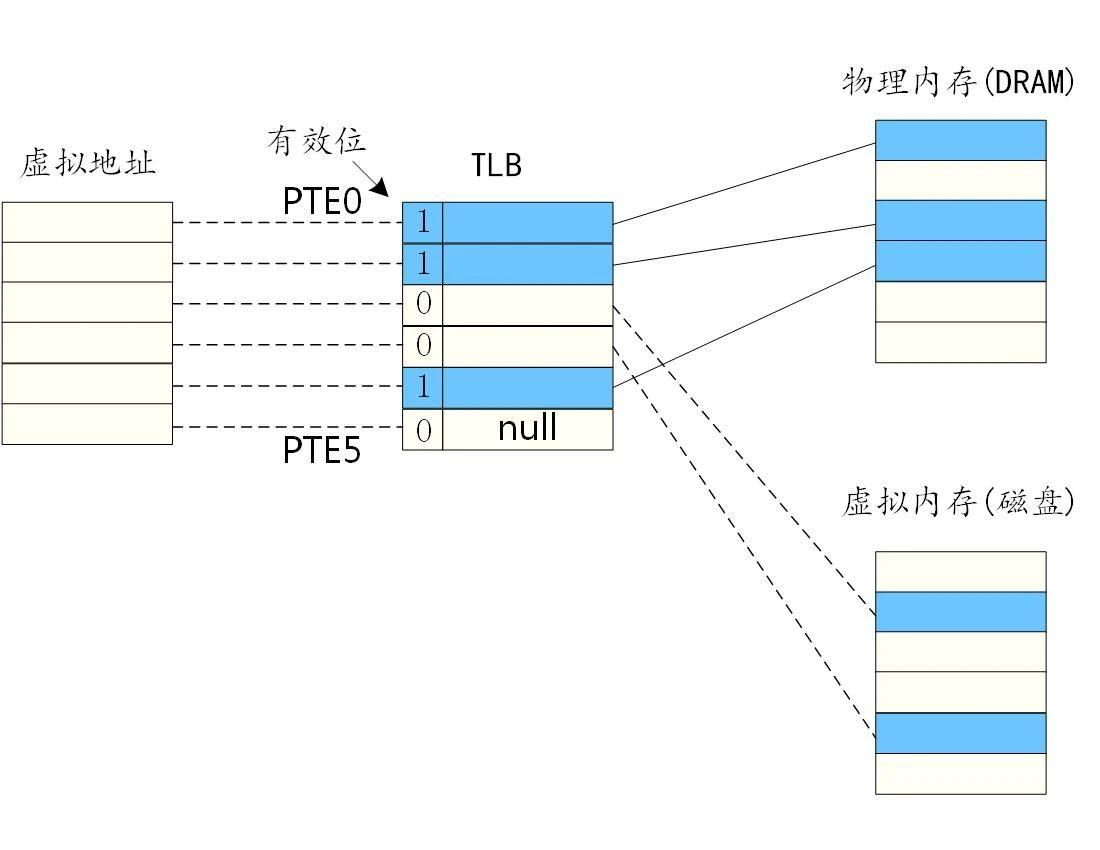
上图中的虚拟内存容易有误解,实际虚拟内存应该指虚拟地址的这段空间,磁盘只是虚拟内存技术为了解决物理内存空间不足而扩充物理空间的一个方案。
每条 PTE 都由一个有效位和一个 n 位地址组成。如果 PTE 的有效位为 1,则 n 位地址表示相应物理页的起始位置,即虚拟地址能够在物理内存中找到相应的物理页。如果 PTE 的有效位为 0,且后面跟着的地址为空,那么表示该虚拟地址指向的虚拟页还没有被分配。如果 PTE 的有效位为 0,且后面跟着指向虚拟页的地址,表示该虚拟地址在物理内存中没有相对应的物理地址,指向该虚拟页在磁盘上的起始位置,我们通常把这种情况称为缺页,缺页中断就通过页面置换算法把硬盘的页面置换过来。
为何引入虚拟内存?如果直接操作物理内存有哪些危害
1:进程地址空间不隔离。由于程序都是直接访问物理内存,所以恶意程序可以随意修改别的进程的内存数据,以达到破坏的目的。有些非恶意的,但是有bug的程序也可能不小心修改了其它程序的内存数据,就会导致其它程序的运行出现异常。这种情况对用户来说是无法容忍的,因为用户希望使用计算机的时候,其中一个任务失败了,至少不能影响其它的任务。
2:内存使用效率低。在A和B都运行的情况下,如果用户又运行了程序C,而程序C需要20M大小的内存才能运行,而此时系统只剩下8M的空间可供使用,所以此时系统必须在已运行的程序中选择一个将该程序的数据暂时拷贝到硬盘上,释放出部分空间来供程序C使用,然后再将程序C的数据全部装入内存中运行。可以想象得到,在这个过程中,有大量的数据在装入装出,导致效率十分低下。
3:程序运行的地址不确定。当内存中的剩余空间可以满足程序C的要求后,操作系统会在剩余空间中随机分配一段连续的20M大小的空间给程序C使用,因为是随机分配的,所以程序运行的地址是不确定的
内存分配中的分页、分段区别?
页是信息的物理单位,又系统决定,为了管理内存而划分,分页是为实现离散分配方式,提高内存利用率,对用户是透明的。
段是信息的逻辑单位,它是根据用户的需要划分的,因此段对用户是可见的,其大小不固定,由它所完成的功能决定,由用户编写的程序决定的,段向用户提供二维地址空间(在标识一个地址时,既需要给出段名,又需要给出段内地址)
内存管理中的缓冲区溢出?有什么危害?其原因是什么?
缓冲区溢出是指当计算机向缓冲区填充数据时超出了缓冲区本身的容量,溢出的数据覆盖在合法数据上。1.引起程序崩溃,导致拒绝额服务 2.导致源代码跳转并且执行一段恶意代码,造成缓冲区溢出的主要原因是程序中没有仔细检查用户输入。
访问虚拟地址时出现缺页中断,那么中断和异常(陷入)区别:
中断(Interruption),也称外中断,指来自CPU执行指令以外的事件的发生,如设备发出的I/O结束中断,表示设备输入/输出处理已经完成,希望处理机能够向设备发下一个输入 / 输出请求,同时让完成输入/输出后的程序继续运行。时钟中断,表示一个固定的时间片已到,让处理机处理计时、启动定时运行的任务等。这一类中断通常是与当前程序运行无关的事件,即它们与当前处理机运行的程序无关。
异常(Exception),也称内中断、例外或陷入(Trap),指源自CPU执行指令内部的事件,如程序的非法操作码、 地址越界、算术溢出、虚存系统的缺页以及专门的陷入指令等引起的事件。对异常的处理一般要依赖于当前程序的运行现场,而且异常不能被屏蔽,一旦出现应立即处理。
解决物理内存不足的其他方案
覆盖技术(应用程序手动把需要的指令和数据保存在内存中)
目标:在较小的可用内存中运行较大的程序
方法:依据程序逻辑结构,将程序划分为若干功能相对独立的模块;将不会同时执行的模块共享同一块内存区域
(1)必要部分(常用功能)的代码和数据常驻内存
(2)可选部分(不常用功能)放在其他程序模块中,只在需要用到时装入内存
(3)不存在调用关系的模块可相互覆盖,共用同一块内存区域
交换技术:Linux下的swap分区及作用(操作系统自动把暂时不能执行的程序保存到外存磁盘中)
swap 分区是Linux系统的交换分区,当内存不够用的时候,我们使用 swap 分区存放内存中暂时不用的数据。也就是说,当内存不够用时,我们使用 swap 分区来临时顶替。
free 命令主要是用来査看内存和 swap 分区的使用情况的,其中:
- total:是指总数;
- used:是指已经使用的;
- free:是指空闲的;
- shared:是指共享的;
- buffers:是指缓冲内存数;
- cached:是指缓存内存数,单位是KB;
我们需要解释一下 buffers(缓冲)和 cached(缓存)的区别。简单来讲,cached 是给读取数据时加速的,buffers 是给写入数据加速的。cached 是指把读取出来的数据保存在内存中,当再次读取时,不用读取硬盘而直接从内存中读取,加速了数据的读取过程;buffers 是指在写入数据时,先把分散的写入操作保存到内存中,当达到一定程度后再集中写入硬盘,减少了磁盘碎片和硬盘的反复寻道,加速了数据的写入过程。
页面置换算法:
1.最佳置换算法(OPT)
最佳(Optimal, OPT)置换算法所选择的被淘汰页面将是以后永不使用的,或者是在最长时间内不再被访问的页面,这样可以保证获得最低的缺页率。但由于人们目前无法预知进程在内存下的若千页面中哪个是未来最长时间内不再被访问的,因而该算法无法实现。
2.先进先出(FIFO)页面置换算法
优先淘汰最早进入内存的页面,亦即在内存中驻留时间最久的页面。该算法实现简单,只需把调入内存的页面根据先后次序链接成队列,设置一个指针总指向最早的页面。但该算法与进程实际运行时的规律不适应,因为在进程中,有的页面经常被访问。
3.LFU页面置换算法(最少使用页面排序算法)
根据最近一段时间访问的次数进行淘汰,优先置换最近使用次数少的
4. 最近最久未使用(LRU)置换算法
选择最近最长时间未访问过的页面予以淘汰,它认为过去一段时间内未访问过的页面,在最近的将来可能也不会被访问。该算法为每个页面设置一个访问字段,来记录页面自上次被访问以来所经历的时间,淘汰页面时选择现有页面中值最大的予以淘汰。
5. 时钟(CLOCK)置换算法
LRU算法的性能接近于OPT,但是实现起来比较困难,且开销大;FIFO算法实现简单,但性能差。所以操作系统的设计者尝试了很多算法,试图用比较小的开销接近LRU的性能,这类算法都是CLOCK算法的变体。
简单的CLOCK算法是给每一帧关联一个附加位,称为使用位。当某一页首次装入主存时,该帧的使用位(u)设置为1;当该页随后再被访问到时,它的使用位也被置为1。对于页替换算法,用于替换的候选帧集合看做一个循环缓冲区,并且有一个指针与之相关联。当某一页被替换时,该指针被设置成指向缓冲区中的下一帧。当需要替换一页时,操作系统扫描缓冲区,以查找使用位被置为0的一帧。每当遇到一个使用位为1的帧时,操作系统就将该位重新置为0;如果在这个过程开始时,缓冲区中所有帧的使用位均为0,则选择遇到的第一个帧替换;如果所有帧的使用位均为1,则指针在缓冲区中完整地循环一周,把所有使用位都置为0,并且停留在最初的位置上,替换该帧中的页。由于该算法循环地检查各页面的情况,故称为CLOCK算法,又称为最近未用(Not Recently Used, NRU)算法。
CLOCK算法的性能比较接近LRU,而通过增加使用的位数目,可以使得CLOCK算法更加高效。在使用位的基础上再增加一个修改位,则得到改进型的CLOCK置换算法。这样,每一帧都处于以下四种情况之一:
- 最近未被访问,也未被修改(u=0, m=0)。
- 最近被访问,但未被修改(u=1, m=0)。
- 最近未被访问,但被修改(u=0, m=1)。
- 最近被访问,被修改(u=1, m=1)。
参考:https://cloud.tencent.com/developer/news/682507
本文来自博客园,作者:LeeJuly,转载请注明原文链接:https://www.cnblogs.com/peterleee/p/11242114.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号