

MYSQL中的一些小问题
char和varchar区别:
在MyISAM存储引擎的下面:
1.char是固定长度,varchar长度可变:
存储时,前者不管实际存储数据的长度,直接规定CHAR规定的长度分配存储空间;而后者会根据实际存储的数据分配最终的存储空间。通常情况下,varchar能够节约磁盘空间,为此往往认为其能够提升数据库的性能。但必须注意的是,在提升性能的同时也会有些副作用。如在更改前其字符长度为10,此时系统为其分配10个存储单元,更改后长度变为20,原先存储的位置无法满足其存储的需求,就需要一些额外的操作,根据存储引擎的不同,有的会采用拆分机制,有的采用分页机制。
eg.定义char(10)和varchar(10),存入"test",char所占存储长度为10,除了字符"test"外后面跟着6个空格,而varchar直接存4个长度;读取数据时,char用trim()去掉多余的空格,varchar直接读出数据。
2.char的存储方式是:英文字符占1个字节,汉字占用2个字节;varchar的存储方式是:英文和汉字都占用2个字节,两者的存储数据都非unicode的字符数据。
项目建议:
实际项目中要使用varchar还是char需要根据具体情况考量:
1.根据字符长度判断:在实际项目中,如果字段长度较短一般采用char
2.根据字符间长度是否相近:如果字符间长度相近甚至是相同的长度,会采用char字符类型
*小问题:char(1)和varchar(1)的区别?两个都只能保存单个字符,但是varchar要多占一个或两个存储位置用来记录存储长度信息。
3.从碎片角度进行考虑:char固定长度,存储空间一次性分配,没有碎片的困扰;但是varchar在更改前后难免会有长度不一致导致存储碎片的情况,因此需要管理员时不时对碎片的处理。
MySQL的复制原理以及流程(主从复制)
2、Slave通过I/O线程读取Master中的binary log events并写入到它的中继日志(relay log)
3、Slave重做中继日志中的事件,把中继日志中的事件信息一条一条的在本地执行一次,完成数据在本地的存储,从而实现将改变反映到它自己的数据(数据重放)
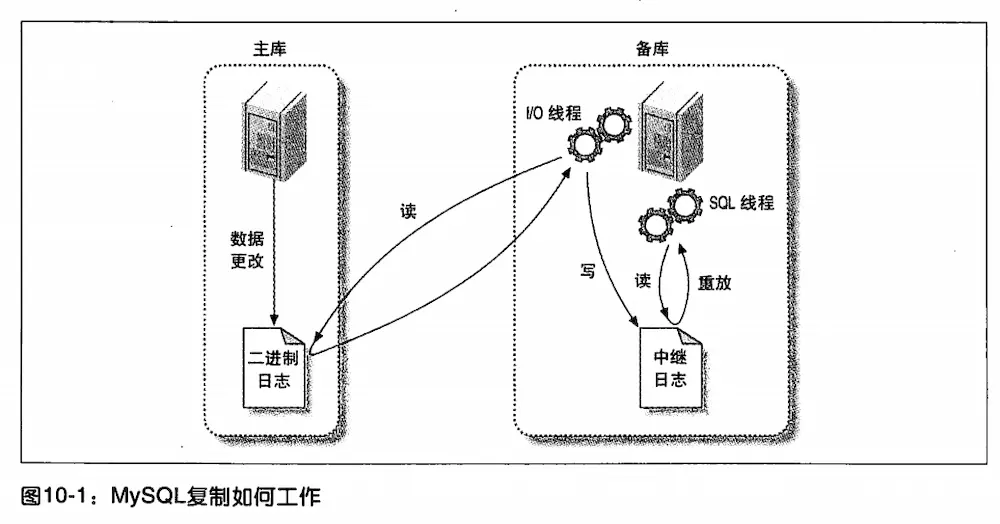
参考:https://www.jianshu.com/p/63c1a1babfd1
如何从mysqldump产生的全库备份中只恢复某一个库、某一张表?
通过正则表达式grep命令等
参考:https://blog.51cto.com/suifu/1830651
一个6亿的表a,一个3亿的表b,通过外间tid关联,你如何最快的查询出满足条件的第50000到第50200中的这200条数据记录。
1、如果A表TID是自增长,并且是连续的,B表的ID为索引
select * from a,b where a.tid = b.id and a.tid>500000 limit 200;
2、如果A表的TID不是连续的,那么就需要使用覆盖索引.TID要么是主键,要么是辅助索引,B表ID也需要有索引。
select * from b , (select tid from a limit 50000,200) a where b.id = a .tid;
MYSQL数据库CPU占用突然特别高
1.多实例的服务器,先top查看是那一个进程占用CPU多;
2.show full processeslist 查看线程是否有锁住;关于这个命令https://xu3352.github.io/mysql/2017/07/08/msyql-show-full-processlist
3.查看慢查询,找出执行时间长的sql;explain分析sql是否走索引,sql优化;
4.再查看是否缓存失效引起,需要查看buffer命中率;
常见的一些问题:
一些问题会导致连锁反应,而且不太好定位,有时候以为是慢查询,很可能是大多时间是在等在CPU、内存资源的释放,所以有时候同一个查询消耗的时间有时候差异很大
总结了一些常见问题:
- CPU报警:很可能是 SQL 里面有较多的计算导致的
- 连接数超高:很可能是有慢查询,然后导致很多的查询在排队,排查问题的时候可以看到”事发现场“类似的 SQL 语句一大片,那么有可能是没有索引或者索引不好使,可以用:
explain分析一下 SQL 语句
MYSQL 5.6关于索引的优化:
索引条件下推(ICP:index condition pushdown):
科普时间—— Index Condition Pushdown(索引下推) MySQL 5.6引入了索引下推优化,默认开启,使用SET optimizer_switch = ‘index_condition_pushdown=off’;可以将其关闭。官方文档中给的例子和解释如下: people表中(zipcode,lastname,firstname)构成一个索引
SELECT * FROM people WHERE zipcode=‘95054’ AND lastname LIKE ‘%etrunia%’ AND address LIKE ‘%Main Street%’;
如果没有使用索引下推技术,则MySQL会通过zipcode='95054’从存储引擎中查询对应的数据,返回到MySQL服务端,然后MySQL服务端基于lastname LIKE '%etrunia%'和address LIKE '%Main Street%'来判断数据是否符合条件。 如果使用了索引下推技术,则MYSQL首先会返回符合zipcode='95054’的索引,然后根据lastname LIKE '%etrunia%'和address LIKE '%Main Street%'来判断索引是否符合条件。如果符合条件,则根据该索引来定位对应的数据,如果不符合,则直接reject掉。 有了索引下推优化,可以在有like条件查询的情况下,减少回表次数。
外键的作用:
外键用于保持数据一致性,完整性(减少数据库的冗余)
主要目的是控制存储在外键表中的数据
删除时属性:
RESTRICT(默认属性)
当在父表(即外键的来源表)中删除对应记录时,首先检查该记录是否有对应外键,如果有则不允许删除。
No ACTION
当在父表(即外键的来源表)中删除对应记录时,首先检查该记录是否有对应外键,如果有则不允许删除。
CASCADE
当在父表(即外键的来源表)中删除对应记录时,首先检查该记录是否有对应外键,如果有则也删除外键在子表(即包含外键的表)中的记录。
SET NULL
当在父表(即外键的来源表)中删除对应记录时,首先检查该记录是否有对应外键,如果有则设置子表中该外键值为null(不过这就要求该外键允许取null)。
更新时属性
RESTRICT(默认属性)
则当在父表(即外键的来源表)中更新对应记录时,首先检查该记录是否有对应外键,如果有则不允许更新。
No ACTION
则当在父表(即外键的来源表)中更新对应记录时,首先检查该记录是否有对应外键,如果有则不允许更新。
CASCADE
当在父表(即外键的来源表)中更新对应记录时,首先检查该记录是否有对应外键,如果有则也更新外键在子表(即包含外键的表)中的记录。
SET NULL
当在父表(即外键的来源表)中更新对应记录时,首先检查该记录是否有对应外键,如果有则设置子表中该外键值为null(不过这就要求该外键允许取null)。
总结
外键的使用对于减少数据库冗余性,以及保证数据完整性和一致性有很大作用。
另外注意,如果两张表之间存在外键关系,则MySQL不能直接删除表(Drop Table),而应该先删除外键,之后才可以删除。所以一般默认就好(RESTRICT)。
本文来自博客园,作者:LeeJuly,转载请注明原文链接:https://www.cnblogs.com/peterleee/p/10609035.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号