字符编码简介
ASCII
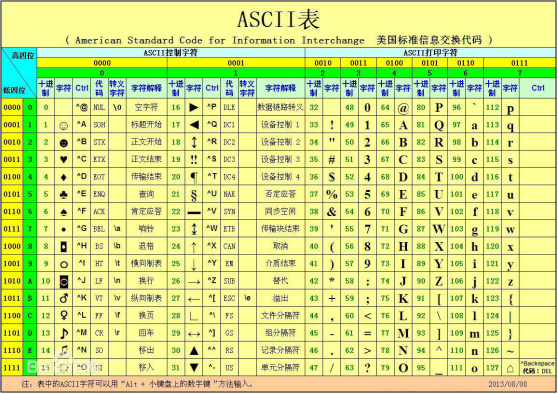
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码),是一种单字节编码。计算机起源于美国,早期计算机中使用的只有英文,没有其他的语言,而单字节可以表示2**8 -1即255个字符,可以表示所有的英文字符及许多控制符号。而且只用了一半。
GB2312
GB2312是一种双字节编码,由中国国家标准总局1980年发布,1981年5月1日开始使用。适用于汉字处理,汉子通信等系统之间的信息交换,收入汉字6763个和非汉字符682个。
GB2312规定对收录的每个字符采用两个字节表示,第一个字节为“高字节”,对应94个区;第二个字节为“低字节”,对应94个位。所以它的区位码范围是:0101-9494。区号和位号分别加上0xA0就是GB2312编码。例如最后一个码位是9494,区号和位号分别转换成十六进制是5E5E,0x5E+0xA0=0xFE,所以该码位的GB2312编码是FEFE。
部分手机以及MP3支持的是GB2312编码格式。
GBK
GBK是一种双字节编码,1995年制定并正式发布。GBK向下与GB2312编码兼容,其编码范围从8140至FEFE(剔除xx7F),共23940个码位,共收录了21003个汉字。
Unicode
Unicode(统一码、万国码、单一码),用两个字节表示一个字符,1994年正式公布。原有的英文编码从单字节变成双字节,只需要把高字节全部填为0就可以。Unicode把所有语言都统一到一套编码里,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。因为Python的诞生比Unicode标准发布的时间还要早,所以最早的Python只支持ASCII编码,普通的字符串'ABC'在Python内部都是ASCII编码的。现在Python支持Unicode编码了
UTF-8
UTF-8是一种针对Unicode的可变长度字符编码,又称万国码,由Ken Thompson于1992年创建。UTF-8用1到6个字节编码Unicode字符。ASCII字符在utf-8编码格式中占用一个字节,汉子则占用三个字节。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号