Makefile学习
Makefile 文件描述了 Linux 系统下 C/C++ 工程的编译规则,它用来自动化编译 C/C++ 项目。一旦写编写好 Makefile 文件,只需要一个 make 命令,整个工程就开始自动编译,不再需要手动执行 GCC 命令。
一个中大型 C/C++ 工程的源文件有成百上千个,它们按照功能、模块、类型分别放在不同的目录中,Makefile 文件定义了一系列规则,指明了源文件的编译顺序、依赖关系、是否需要重新编译等。
参考:Makefile教程
1. Makefile文件是什么?
Windows环境:如果你是在 Windows 下作开发的话不需要去考虑这个问题,因为 Windows 下的集成开发环境(IDE)已经内置了 Makefile,或者说会自动生成 Makefile,我们不用去手动编写。
Linux环境:Linux 中却不能这样,需要我们去手动的完成这项工作。不懂 Makefile,就操作不了多文件编程,就完成不了相对于大的工程项目的操作。
Makefile 可以简单的认为是一个工程文件的编译规则,描述了整个工程的编译和链接等规则。其中包含了那些文件需要编译,那些文件不需要编译,那些文件需要先编译,那些文件需要后编译,那些文件需要重建等等。编译整个工程需要涉及到的,在 Makefile 中都可以进行描述。换句话说,Makefile 可以使得我们的项目工程的编译变得自动化,不需要每次都手动输入一堆源文件和参数。
以 Linux 下的C语言开发为例来具体说明一下,多文件编译生成一个文件,编译的命令如下所示:
gcc -o outfile name1.c name2.c ...
outfile 要生成的可执行程序的名字,nameN.c 是源文件的名字。
这是我们在 Linux 下使用 gcc 编译器编译 C 文件的例子。如果我们遇到的源文件的数量不是很多的话,可以选择这样的编译方式。如果源文件非常的多的话,就会遇到下面的这些问题:
1) 编译的时候需要链接库的的问题。
2) 编译大的工程会花费很长的时间。
对于这样的问题我们 Makefile 可以解决,Makefile 支持多线程并发操作,会极大的缩短我们的编译时间,并且当我们修改了源文件之后,编译整个工程的时候,make 命令只会编译我们修改过的文件,没有修改的文件不用重新编译,也极大的解决了我们耗费时间的问题。
2. Makefile文件中包含哪些规则?
Makefile 描述的是文件编译的相关规则,它的规则主要是两个部分组成,分别是依赖的关系和执行的命令,其结构如下所示:
targets : prerequisites
command
相关说明如下:
- targets:规则的目标,可以是 Object File(一般称它为中间文件),也可以是可执行文件,还可以是一个标签;
- prerequisites:是我们的依赖文件,要生成 targets 需要的文件或者是目标。可以是多个,也可以是没有;
- command:make 需要执行的命令(任意的 shell 命令)。可以有多条命令,每一条命令占一行。Makefile 中的任何命令都要以
tab键开始。
举例:
test:test.c
gcc -o test test.c
上述代码实现的功能就是编译 test.c 文件,通过这个实例可以详细的说明 Makefile 的具体的使用。
其中 test 是的目标文件,也是我们的最终生成的可执行文件。依赖文件就是 test.c 源文件,重建目标文件需要执行的操作是gcc -o test test.c。这就是 Makefile 的基本的语法规则的使用。
简单的概括一下Makefile 中的内容,它主要包含有五个部分,分别是:
1) 显式规则
显式规则说明了,如何生成一个或多的的目标文件。这是由 Makefile 的书写者明显指出,要生成的文件,文件的依赖文件,生成的命令。
2) 隐晦规则
由于我们的 make 命名有自动推导的功能,所以隐晦的规则可以让我们比较粗糙地简略地书写 Makefile,这是由 make 命令所支持的。
3) 变量的定义
在 Makefile 中我们要定义一系列的变量,变量一般都是字符串,这个有点像C语言中的宏,当 Makefile 被执行时,其中的变量都会被扩展到相应的引用位置上。
4) 文件指示
其包括了三个部分,一个是在一个 Makefile 中引用另一个 Makefile,就像C语言中的 include 一样;另一个是指根据某些情况指定 Makefile 中的有效部分,就像C语言中的预编译 #if 一样;还有就是定义一个多行的命令。有关这一部分的内容,我会在后续的部分中讲述。
5) 注释
Makefile 中只有行注释,和 UNIX 的 Shell 脚本一样,其注释是用“#”字符,这个就像 C/C++ 中的“//”一样。如果你要在你的 Makefile 中使用“#”字符,可以用反斜框进行转义,如:“\#”。
3. Makefile的工作流程
当我们在执行 make 这条命令的时候,make 就会去当前文件下找要执行的编译规则,也就是 Makefile 文件。我们编写 Makefile 的时候可以使用的文件的名称 :"GNUmakefile" 、"makefile" 、"Makefile" ,make 执行时会去寻找 Makefile 文件,找文件的顺序也是这样的。
工作流程
清除工作目录中的过程文件
我们在使用的时候会产生中间文件会让整个文件看起来很乱,所以在编写 Makefile 文件的时候会在末尾加上这样的规则语句:
.PHONY:clean
clean:
rm -rf *.o test
其中 "*.o" 是执行过程中产生的中间文件,"test" 是最终生成的执行文件。我们可以看到 clean 是独立的,它只是一个伪目标(在《Makefile伪目标》的章节中详细介绍),不是具体的文件。不会与第一个目标文件相关联,所以我们在执行 make 的时候也不会执行下面的命令。在shell 中执行 "make clean" 命令,编译时的中间文件和生成的最终目标文件都会被清除,方便我们下次的使用。
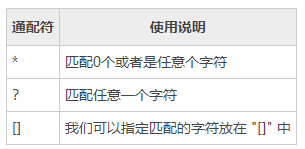
4. Makefile通配符的使用
Makefile 是可以使用 shell 命令的,所以 shell 支持的通配符在 Makefile 中也是同样适用的。 shell 中使用的通配符有:"*","?","[...]"。具体看一下这些通配符的表示含义和具体的使用方法。
5. Makefile变量的定义和使用
Makefile 文件中定义变量的基本语法如下:
变量的名称=值列表
它并没有像其它语言那样定义变量的时候需要使用数据类型。变量的名称可以由大小写字母、阿拉伯数字和下划线构成。等号左右的空白符没有明确的要求,因为在执行 make 的时候多余的空白符会被自动的删除。至于值列表,既可以是零项,又可以是一项或者是多项。如: VALUE_LIST = one two three
调用变量的时候可以用 "$(VALUE_LIST)" 或者是 "${VALUE_LIST}" 来替换,这就是变量的引用。
举例:
OBJ=main.o test.o test1.o test2.o
test:$(OBJ)
gcc -o test $(OBJ)
变量的基本赋值
知道了如何定义,下面我们来说一下 Makefile 的变量的四种基本赋值方式:
- 简单赋值 ( := ) 编程语言中常规理解的赋值方式,只对当前语句的变量有效。
- 递归赋值 ( = ) 赋值语句可能影响多个变量,所有目标变量相关的其他变量都受影响。
- 条件赋值 ( ?= ) 如果变量未定义,则使用符号中的值定义变量。如果该变量已经赋值,则该赋值语句无效。
- 追加赋值 ( += ) 原变量用空格隔开的方式追加一个新值。
6. Makefile自动化变量
自动化变量可以理解为由 Makefile 自动产生的变量。
在模式规则中,规则的目标和依赖的文件名代表了一类的文件。规则的命令是对所有这一类文件的描述。我们在 Makefile 中描述规则时,依赖文件和目标文件是变动的,显然在命令中不能出现具体的文件名称,否则模式规则将失去意义。
那么模式规则命令中该如何表示文件呢?就需要使用“自动化变量”,自动化变量的取值根据执行的规则来决定,取决于执行规则的目标文件和依赖文件。下面是对所有的自动化变量进行的说明:

我们在执行 make 的时候,make 会自动识别命令中的自动化变量,并自动实现自动化变量中的值的替换,这个类似于编译C语言文件的时候的预处理的作用。
7. Makefile目标文件搜索(VPATH和vpath)
如果所有的源文件都是存放在与 Makefile 相同的目录下,只要依赖的文件存在,并且依赖规则没有问题,执行 make命令整个工程就会按照对我们编写规则去编译,最终会重建目标文件。
如果需要的文件是存在于不同的路径下,在编译的时候要去怎么办呢(不改变工程的结构)?这就用到了 Makefile 中为我们提供的目录搜索文件的功能。
常见的搜索的方法的主要有两种:一般搜索VPATH和选择搜索vpath。乍一看只是大小写的区别,其实两者在本质上也是不同的。
VPATH 和 vpath 的区别:
- VPATH 是变量,更具体的说是环境变量,Makefile 中的一种特殊变量,使用时需要指定文件的路径;
- vpath 是关键字,按照模式搜索,也可以说成是选择搜索。搜索的时候不仅需要加上文件的路径,还需要加上相应限制的条件。
VPATH的使用
在 Makefile 中可以这样写:
VPATH := src
我们可以这样理解,把 src 的值赋值给变量 VPATH,所以在执行 make 的时候会从 src 目录下找我们需要的文件。
当存在多个路径的时候我们可以这样写:VPATH := src car
或者是 VPATH := src:car
多个路径之间要使用空格或者是冒号隔开,表示在多个路径下搜索文件。搜索的顺序为我们书写时的顺序,拿上面的例子来说,我们应该先搜索 src 目录下的文件,再搜索 car 目录下的文件。
vpath的使用
VPATH 是搜索路径下所有的文件,而 vpath 更像是添加了限制条件,会过滤出一部分再去寻找。
具体用法:
1) vpath PATTERN DIRECTORIES
2) vpath PATTERN
3) vpath
( PATTERN:可以理解为要寻找的条件,DIRECTORIES:寻找的路径 )
首先是用法一,命令格式如下:
vpath test.c src
可以这样理解,在 src 路径下搜索文件 test.c。
使用什么样的搜索方法,主要是基于编译器的执行效率。
使用 VPATH 的情况是路径下的文件较少,或者是搜索的文件不能使用通配符表示,这些情况下使用VPATH最好。
如果存在某个路径的文件特别的多或者是可以使用通配符表示的时候,就不建议使用 VPATH 这种方法,为什么呢?因为 VPATH 在去搜索文件的时没有限制条件,所以它会去检索这个目录下的所有文件,每一个文件都会进行对比,搜索和我们目录名相同的文件,不仅速度会很慢,而且效率会很低。我们在这种情况下就可以使用 vpath 搜索,它包含搜索条件的限制,搜索的时候只会从我们规定的条件中搜索目标,过滤掉不符合条件的文件,当然查找的时候也会比较的快。
8. Makefile路径搜索使用案例
9. Makefile隐含规则
所谓的隐含规则就是需要我们做出具体的操作,系统自动完成。编写 Makefile 的时候,可以使用隐含规则来简化Makefile 文件编写。
test:test.o
gcc -o test test.o
test.o:test.c
我们可以在 Makefile 中这样写来编译 test.c 源文件,相比较之前少写了重建 test.o 的命令。但是执行 make,发现依然重建了 test 和 test.o 文件,运行结果却没有改变。这其实就是隐含规则的作用。
因为完整的文件是:
test:test.o
gcc -o test test.o
test.o:test.c
gcc -o test.o test.c
在某些时候其实不需要给出重建目标文件的命令,有的甚至可以不需要给出规则。实例:
test:test.o
gcc -o test test.o
运行的结果是相同的。
注意:隐含条件只能省略中间目标文件重建的命令和规则,但是最终目标的命令和规则不能省略。
隐含规则的具体的工作流程:
make 执行过程中找到的隐含规则,提供了此目标的基本依赖关系。确定目标的依赖文件和重建目标需要使用的命令行。隐含规则所提供的依赖文件只是一个基本的(在C语言中,通常他们之间的对应关系是:test.o 对应的是 test.c 文件)。当需要增加这个文件的依赖文件的时候要在 Makefile 中使用没有命令行的规则给出。
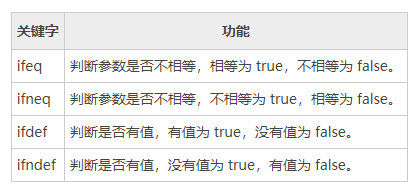
10. Makefile ifeq、ifneq、ifdef和ifndef(条件判断)
需要解决的问题:要根据判断,分条件执行语句。
条件语句的作用:条件语句可以根据一个变量的值来控制 make 执行或者时忽略 Makefile 的特定部分,条件语句可以是两个不同的变量或者是常量和变量之间的比较。
条件语句使用优点:Makefile 中使用条件控制可以做到处理的灵活性和高效性。
ifeq (ARG1, ARG2)
else
endif
11. Makefile伪目标
所谓的伪目标可以这样来理解,它并不会创建目标文件,只是想去执行这个目标下面的命令。伪目标的存在可以帮助我们找到命令并执行。
使用伪目标有两点原因:
- 避免我们的 Makefile 中定义的只执行的命令的目标和工作目录下的实际文件出现名字冲突。
- 提高执行 make 时的效率,特别是对于一个大型的工程来说,提高编译的效率也是我们所必需的。
我们先来看一下第一种情况的使用。如果需要书写这样一个规则,规则所定义的命令不是去创建文件,而是通过 make 命令明确指定它来执行一些特定的命令。实例:
clean:
rm -rf *.o test
规则中 rm 命令不是创建文件 clean 的命令,而是执行删除任务,删除当前目录下的所有的 .o 结尾和文件名为 test 的文件。当工作目录下不存在以 clean 命令的文件时,在 shell 中输入 make clean 命令,命令 rm -rf *.o test 总会被执行 ,这也是我们期望的结果。
如果当前目录下存在文件名为 clean 的文件时情况就会不一样了,当我们在 shell 中执行命令 make clean,由于这个规则没有依赖文件,所以目标被认为是最新的而不去执行规则所定义的命令。因此命令 rm 将不会被执行。
为了解决这个问题,删除 clean 文件或者是在 Makefile 中将目标 clean 声明为伪目标。
将一个目标声明称伪目标的方法是将它作为特殊的目标.PHONY的依赖,如下:
.PHONY:clean
这样 clean 就被声明成一个伪目标,无论当前目录下是否存在 clean 这个文件,当我们执行 make clean 后 rm 都会被执行。而且当一个目标被声明为伪目标之后,make 在执行此规则时不会去试图去查找隐含的关系去创建它。这样同样提高了 make 的执行效率,同时也不用担心目标和文件名重名而使我们的编译失败。
在书写伪目标的时候,需要声明目标是一个伪目标,之后才是伪目标的规则定义。目标 "clean" 的完整书写格式如下:
.PHONY:clean
clean:
rm -rf *.o test
12. Makefile常用字符串处理函数
函数的调用和变量的调用很像。引用变量的格式为$(变量名),函数调用的格式如下:
$(<function> <arguments>) 或者是 ${<function> <arguments>}
其中,function 是函数名,arguments 是函数的参数,参数之间要用逗号分隔开。而参数和函数名之间使用空格分开。调用函数的时候要使用字符“$”,后面可以跟小括号也可以使用花括号。这个其实我们并不陌生,我们之前使用过许多的函数,比如说展开通配符的函数 wildcard,以及字符串替换的函数 patsubst ,Makefile 中函数并不是很多。
字符串处理函数,这些都是我们经常使用到的函数,下面是对函数详细的介绍。
1. 模式字符串替换函数,函数使用格式如下:
$(patsubst <pattern>,<replacement>,<text>)
函数说明:函数功能是查找 text 中的单词是否符合模式 pattern,如果匹配的话,则用 replacement 替换。返回值为替换后的新字符串。实例:
OBJ=$(patsubst %.c,%.o,1.c 2.c 3.c)
all:
@echo $(OBJ)
执行 make 命令,我们可以得到的值是 "1.o 2.o 3.o",这些都是替换后的值。
注:all通常也是一个.PHONY目标【伪目标】
2. 字符串替换函数,函数使用格式如下:
$(subst <from>,<to>,<text>)
函数说明:函数的功能是把字符串中的 form 替换成 to,返回值为替换后的新字符串。
3. 去空格函数,函数使用格式如下:
$(strip <string>)
函数说明:函数的功能是去掉字符串的开头和结尾的字符串,并且将其中的多个连续的空格合并成为一个空格。返回值为去掉空格后的字符串。
4. 查找字符串函数,函数使用格式如下:
$(findstring <find>,<in>)
函数说明:函数的功能是查找 in 中的 find ,如果我们查找的目标字符串存在。返回值为目标字符串,如果不存在就返回空。
5. 过滤函数,函数使用格式如下:
$(filter <pattern>,<text>)
函数说明:函数的功能是过滤出 text 中符合模式 pattern 的字符串,可以有多个 pattern 。返回值为过滤后的字符串。
6. 反过滤函数,函数使用格式如下:
$(filter-out <pattern>,<text>)
函数说明:函数的功能是功能和 filter 函数正好相反,但是用法相同。去除符合模式 pattern 的字符串,保留符合的字符串。返回值是保留的字符串。
7. 排序函数,函数使用格式如下:
$(sort <list>)
函数说明:函数的功能是将 <list>中的单词排序(升序)。返回值为排列后的字符串。注意:sort会去除重复的字符串。
8. 取单词函数,函数使用格式如下:
$(word <n>,<text>)
函数说明:函数的功能是取出函数<text>中的第n个单词。返回值为我们取出的第 n 个单词。
13. Makefile常用文件名操作函数
在编写 Makefile 的时候,很多情况下需要对文件名进行操作。例如获取文件的路径,去除文件的路径,取出文件前缀或后缀等等。
当遇到这样的问题的时手动修改是不太可能的,因为文件可能会很多,而且 Makefile 中操作文件名可能不止一次。所以 Makefile 给我们提供了相应的函数去实现文件名的操作。
注意:下面的每个函数的参数字符串都会被当作或是一个系列【多个】的文件名来看待。
1. 取目录函数,函数使用格式如下:
$(dir <names>)
函数说明:函数的功能是从文件名序列 names 中取出目录部分。如果 names 中有 "/" ,取出的值为 最后一个反斜杠之前的部分。如果没有反斜杠将返回“./”。实例:
OBJ=$(dir src/foo.c hacks)
all:
@echo $(OBJ)
执行 make 命令,我们可以得到的值是“src/ ./”。提取文件 foo.c 的路径是 "/src" 和文件 hacks 的路径 "./"。
2. 取文件函数,函数使用格式如下:
$(notdir <names>)
函数说明:函数的功能是从文件名序列 names 中取出非目录的部分【文件名】。非目录的部分是最后一个反斜杠之后的部分。返回值为文件非目录的部分。
3. 取后缀名函数,函数使用格式如下:
$(suffix <names>)
函数说明:函数的功能是从文件名序列中 names 中取出各个文件的后缀名。返回值为文件名序列 names 中的后缀序列,如果文件没有后缀名,则返回空字符串。
4. 取前缀函数,函数使用格式如下:
$(basename <names>)
函数说明:函数的功能是从文件名序列 names 中取出各个文件名的前缀部分【除了后缀的其他所有字符】。返回值为被取出来的文件的前缀名,如果文件没有前缀名则返回空的字符串。
5. 添加后缀名函数,函数使用格式如下:
$(addsuffix <suffix>,<names>)
函数说明:函数的功能是把后缀 suffix 加到 names 中的每个单词后面。返回值为添加上后缀的文件名序列。
6. 添加前缀名函数,函数使用格式如下:
$(addperfix <prefix>,<names>)
函数说明:函数的功能是把前缀 prefix 加到 names 中的每个单词的前面。返回值为添加上前缀的文件名序列。 我们可以使用这个函数给我们的文件添加路径。
7. 链接函数,函数使用格式如下:
$(join <list1>,<list2>)
函数说明:函数功能是把 list2 中的单词对应的拼接到 list1 的后面。如果 list1 的单词要比 list2的多,那么,list1 中多出来的单词将保持原样,如果 list1 中的单词要比 list2 中的单词少,那么 list2 中多出来的单词将保持原样。返回值为拼接好的字符串。
8. 获取匹配模式文件名函数,命令使用格式如下:
$(wildcard PATTERN)
函数说明:函数的功能是列出当前目录下所有符合模式的 PATTERN 格式的文件名。返回值为空格分隔并且存在当前目录下的所有符合模式 PATTERN 的文件名。
14. Makefile中的其它常用函数
1、$(foreach <var>,<list>,<text>)
函数的功能是:把参数<list>中的单词逐一取出放到参数<var>所指定的变量中,然后再执行<text>所包含的表达式。
每一次<text>会返回一个字符串,循环过程中,<text>所返回的每个字符串会以空格分割,最后当整个循环结束的时候,<text>所返回的每个字符串所组成的整个字符串(以空格分隔)将会是 foreach 函数的返回值。
所以<var>最好是一个变量名,<list>可以是一个表达式,而<text>中一般会只用<var>这个参数来一次枚举<list>中的单词。
2、$(if <condition>,<then-part>)或(if<condition>,<then-part>,<else-part>)
3、$(call <expression>,<parm1>,<parm2>,<parm3>,...)
call 函数是唯一一个可以用来创建新的参数化的函数。我们可以用来写一个非常复杂的表达式,这个表达式中,我们可以定义很多的参数,然后你可以用 call 函数来向这个表达式传递参数。
4、$(origin <variable>)
origin 函数不像其他的函数,它并不操作变量的值,它只是告诉你这个变量是哪里来的。
15. Makefile命令的编写
命令回显
通常 make 在执行命令行之前 会把要执行的命令输出到标准输出设备,我们称之为 "回显",就好像我们在 shell 环境下输入命令执行时一样。
OBJ=test main list
all:
echo $(OBJ)
执行make 或者make all,输出:

如果规则的命令行以字符“@”开始,则 make 在执行的时候就不会显示这个将要被执行的命令。典型的用法是在使用echo命令输出一些信息时。
OBJ=test main list
all:
@echo $(OBJ)
执行时将会得到test main list这条输出信息。
命令的执行
当规则中的目标需要被重建的时候,此规则所定义的命令将会被执行,如果是多行的命令,那么每一行命令将是在一个独立的子 shell 进程中被执行。因此,多命令行之间的执行命令时是相互独立的,相互之间不存在依赖。
在 Makefile 中书写在同一行中的多个命令属于一个完整的 shell 命令行,书写在独立行的一条命令是一个独立的 shell 命令行。
因此:
在一个规则的命令中命令行 “cd”改变目录不会对其后面的命令的执行产生影响。就是说之后的命令执行的工作目录不会是之前使用“cd”进入的那个目录。
如果达到这个目的,就不能把“cd”和其后面的命令放在两行来书写。而应该把这两个命令放在一行上用分号隔开。这样才是一个完整的 shell 命令行。
foo:bar/lose
cd bar;gobble lose >../foo
如果想把一个完整的shell命令行书写在多行上,需要使用反斜杠 (\)来对处于多行的命令进行连接,表示他们是一个完整的shell命令行。
16. Makefile include文件包含
包含其他文件使用的关键字是 "include",和 C 语言包含头文件的方式相同。
当 make 读取到 "include" 关键字的时候,会暂停读取当前的 Makefile,而是去读 "include" 包含的文件,读取结束后再继读取当前的 Makefile 文件。"include" 使用的具体方式如下:
include <filenames>
filenames 是 shell 支持的文件名(可以使用通配符表示的文件)。
include 通常使用在以下的场合:
- 在一个工程文件中,每一个模块都有一个独立的 Makefile 来描述它的重建规则。它们需要定义一组通用的变量定义或者是模式规则。通用的做法是将这些共同使用的变量或者模式规则定义在一个文件中,需要的时候用 "include" 包含这个文件。
- 当根据源文件自动产生依赖文件时,我们可以将自动产生的依赖关系保存在另一个文件中。然后在 Makefile 中包含这个文件。
17. Makefile嵌套执行make
在一个大的工程文件中,不同的文件按照功能被划分到不同的模块中,也就说很多的源文件被放置在了不同的目录下。每个模块可能都会有自己的编译顺序和规则,如果在一个 Makefile 文件中描述所有模块的编译规则,就会很乱,执行时也会不方便,所以就需要在不同的模块中分别对它们的规则进行描述,也就是每一个模块都编写一个 Makefile 文件,这样不仅方便管理,而且可以迅速发现模块中的问题。这样我们只需要控制其他模块中的 Makefile 就可以实现总体的控制,这就是 make 的嵌套执行。
如何来使用呢?举例说明如下:
subsystem:
cd subdir && $(MAKE)
这个例子可以这样来理解,在当前目录下有一个目录文件 subdir 和一个 Makefile 文件,子目录 subdir 文件下还有一个 Makefile 文件,这个文件是用来描述这个子目录文件的编译规则。使用时只需要在最外层的目录中执行 make 命令,当命令执行到上述的规则时,程序会进入到子目录中执行 make。这就是嵌套执行 make,我们把最外层的 Makefile 称为是总控 Makefile。
export的使用
使用 make 嵌套执行的时候,变量是否传递也是我们需要注意的。如果需要变量的传递,那么可以这样来使用:
export <variable>
如果不需要那么可以这样来写:
unexport <variable>
<variable>是变量的名字,不需要使用 "$" 这个字符。如果所有的变量都需要传递,那么只需要使用 "export" 就可以,不需要添加变量的名字。
18. 嵌套执行make的案例
19. make命令参数和选项大汇总
20. Makefile目标类型大汇总
规则中的目标形式是多种多样的,它可以是一个或多个的文件、可以是一个伪目标,这是我们之前讲到过的,也是经常使用的。其实规则目标还可以是其他的类型,下面是对这些类型的详细的说明。
强制目标
空目标文件
特殊的目标
多规则目标
21. Makefile变量的高级用法
高级使用方法有两种:一种是变量的替换引用,一种是变量的嵌套引用。
1、变量的替换引用
我们定义变量的目的是为了简化我们的书写格式,代替我们在代码中频繁出现且冗杂的部分。它可以出现在我们规则的目标中,也可以是我们规则的依赖中。
我们使用的时候会经常的对它的值(表示的字符串)进行操作。遇到这样的问题我们可能会想到我们的字符串操作函数,比如 "patsubst" 就是我们经常使用的。
但是我们使用变量同样可以解决这样的问题,我们通过下面的例子来具体的分析一下。
实例:
foo:=a.c b.c d.c
obj:=$(foo:%.c=%.o)
All:
@echo $(obj)
这段代码实现的功能是字符串的后缀名的替换,把变量 foo 中所有的以 .c 结尾的字符串全部替换成 .o 结尾的字符串。我们在 Makefile 中这样写,然后再 shell 命令行执行 make 命令,就可以看到打印出来的是 "a.o b.o d.o" ,实现了文件名后缀的替换。
表达式中使用了 "%" 这个字符,这个字符的含义就是自动匹配一个或多个字符。在开发的过程中,我们通常会使用这种方式来进行变量替换引用的操作。
2、变量的嵌套使用
变量的嵌套引用的具体含义是这样的,我们可以在一个变量的赋值中引用其他的变量,并且引用变量的数量和和次数是不限制的。下面我们通过实例来说明一下。
实例:
foo:=test
var:=$(foo)
All:
@echo $(var)
这种用法是最常见的使用方法,打印出 var 的值就是 test。我们可以认为是一层的嵌套引用。
22. Makefile控制函数error和warning
Makefile 中提供了两个控制 make 运行方式的函数。其作用是当 make 执行过程中检测到某些错误时为用户提供消息,并且可以控制 make 执行过程是否继续。这两个函数是 "error" 和 "warning",我们来详细的介绍一下这两个函数。
$(error TEXT...)
函数说明如下:
- 函数功能:产生致命错误,并提示 "TEXT..." 信息给用户,并退出 make 的执行。需要说明的是:"error" 函数是在函数展开时(函数被调用时)才提示信息并结束 make 进程。因此如果函数出现在命令中或者一个递归的变量定义时,读取 Makefile 时不会出现错误。而只有包含 "error" 函数引用的命令被执行,或者定义中引用此函数的递归变量被展开时,才会提示知名信息 "TEXT..." 同时退出 make。
- 返回值:空
- 函数说明:"error" 函数一般不出现在直接展开式的变量定义中,否则在 make 读取 Makefile 时将会提示致命错误。
实例:
ERROR1=1234
all:
ifdef ERROR1
$(error error is $(ERROR1))
endif
make 读取解析 Makefile 时,如果所起的变量名是已经定义好的"ERROR1",make 将会提示致命错误信息 "error is 1234" 并保存退出。
$(warning TEXT...)
函数说明如下:
- 函数功能:函数 "warning" 类似于函数 "error" ,区别在于它不会导致致命错误(make不退出),而只是提示 "TEXT...",make 的执行过程继续。
- 返回值:空
- 函数说明:用法和 "error" 类似,展开过程相同。
23. Makefile中常见的错误信息
make 执行过程中所产生错误并不都是致命的,特别是在命令行之前存在 "-"、或者 make 使用 "-k" 选项执行时。
make 执行过程的致命错误都带有前缀字符串 "***"。错误信息都有前缀,一种是执行程序名作为错误前缀(通常是 "make");另外一种是当 Makefile 本身存在语法错误无法被 make 解析并执行时,前缀包含了 Makefile 文件名和出现错误的行号。
Make
代码变成可执行文件,叫做编译(compile);先编译这个,还是先编译那个(即编译的安排),叫做构建(build)。
Make是最常用的构建工具,诞生于1977年,主要用于C语言的项目。但是实际上 ,任何只要某个文件有变化,就要重新构建的项目,都可以用Make构建。
make只是一个根据指定的Shell命令进行构建的工具。它的规则很简单,你规定要构建哪个文件、它依赖哪些源文件,当那些文件有变动时,如何重新构建它。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号