Node.js学习
官方站点:Node.js
介绍
Node.js 是一个 Javascript 运行环境(runtime)。
实际上它是对 Google V8 引擎进行了封装,V8 引擎执行JavaScript 的速度非常快,性能非常好;而 Node.js 对一些特殊用例进行了优化,提供了替代的 API,使得 V8 在非浏览器环境下运行得更好,用于方便地搭建响应速度快、易于扩展的网络应用。
Node.js 使用事件驱动,非阻塞 I/O 模型而得以轻量和高效,非常适合在分布式设备上运行数据密集型的实时应用。
node.js是前端or后端?
- node.js本身不属于前端,但是属于前端的技术栈。
- node.js是前端工具链的重要成员,它参与前端开发,属于前端技术栈里的前端工具。类似于GWT,或者编辑器,它本身并不是属于前端。
- node.js是js的运行环境,即可以服务于前端,也可以服务于后端。
特点
对性能的苛求是 Node 的一个关键因素,JavaScript 是一个事件驱动语言,Node 利用了这个优点,编写出可扩展性高的服务器。
作为一个新兴的后台语言,Node.js 有很多吸引人的地方:
- RESTful API
- 单线程:Node.js 可以在不新增额外线程的情况下,依然可以对任务进行并行处理 —— Node.js 是单线程的;它通过事件轮询(event loop)来实现并行操作,对此,我们应该要充分利用这一点 —— 尽可能的避免阻塞操作,取而代之,多使用非阻塞操作。
- 非阻塞 I/O
- V8 虚拟机
- 事件驱动
模块
Node.js 使用 Module(模块)去划分不同的功能,以简化应用的开发。
模块有点像 C++ 语言中的类库,每一个 Node.js 的类库都包含了十分丰富的各类函数,比如 http 模块就包含了和 http 功能相关的很多函数,可以帮助开发者很容易地对比如 http、tcp/udp 等进行操作,还可以很容易的创建 http 和 tcp/udp 的服务器。
要在程序中使用模块是十分方便的,一般是如下步骤:
首先安装模块,比如通过 NPM 或者 yarn 这类包管理工具来找到并安装对应模块,当然这里举例的 http 模块是 Node.js 内建的,所以无需单独安装;不过如果是非内建模块,这样安装:
npm install <Module name>接着,在安装了模块之后,我们就需要在开发项目当中引入该模块了。这个时候,Node.js 会在我们应用中搜索是否存在 node_modules 的目录,并且搜索这个目录中是否存在模块;如果找不到这个目录,则会到全局模块缓存中去寻找,同时用户可以通过相对或者绝对路径,指定模块的位置,比如:
const myModule = require('./myModule.js');示例程序
在我们创建 Node.js 第一个 "Hello, World!" 应用前,让我们先了解下 Node.js 应用是由哪几部分组成的:
- 引入 required 模块:我们可以使用 require 指令来载入 Node.js 模块。
- 创建服务器:服务器可以监听客户端的请求,类似于 Apache 、Nginx 等 HTTP 服务器。
- 接收请求与响应请求 服务器很容易创建,客户端可以使用浏览器或终端发送 HTTP 请求,服务器接收请求后返回响应数据。
在项目的根目录下创建一个叫 server.js 的文件,并写入以下代码:
const http=require('http')
http.createServer(function(request,response){
// 发送 HTTP 头部
// HTTP 状态值: 200 : OK
// 内容类型: text/plain
response.writeHead(200,{'Content-Type':'text/plain'});
// 发送响应数据 "Hello World"
response.end('Hello World\n');
}).listen(8888);
// 终端打印如下信息
console.log('Server running at http://127.0.0.1:8888/');
运行: node server.js
接下来,打开浏览器访问 http://127.0.0.1:8888/,就会看到一个写着“Hello World”的网页。
简要分析一下:
- 这里引入了 ef="http://nodejs.cn/api/http.html">HTTP 模块:使用该模块来创建 HTTP 服务器
- 服务器被设置为在指定的 8888端口上进行监听, 当服务器就绪时,则 listen 回调函数会被调用【这里没有设置】。
- createServer传入的回调函数会在每次接收到请求时被执行, 每当接收到新的请求时,"http://nodejs.cn/api/http.html#http_event_request">request 事件会被调用,并提供两个对象:一个请求(http.IncomingMessage 对象)和一个响应(http.ServerResponse 对象)
- request 提供了请求的详细信息, 通过它可以访问请求头和请求的数据,response 用于构造要返回给客户端的数据;在此示例中:设置 statusCode 属性为 200,以表明响应成功;还设置了 Content-Type 响应头;最后结束并关闭响应,将内容作为参数添加到 end():
包管理器
除了 Node.js 自带的 NPM 包管理器,还有一些比较常用的第三方包管理器,比如 yarn(来自 Facebook)或者 bower 等等。
NPM 是随同 Node.js 一起安装的包管理工具,能解决其代码部署上的很多问题,常见的使用场景有以下几种:
- 允许用户从 NPM 服务器下载别人编写的第三方包到本地使用。
- 允许用户从 NPM 服务器下载并安装别人编写的命令行程序到本地使用。
- 允许用户将自己编写的包或命令行程序上传到 NPM 服务器供别人使用。
npm -v 查看版本
npm install npm -g 升级npm
1、安装模块
npm install <Module Name> 安装模块,
eg:npm install express
安装完后包就放在当前工程目录下的 node_modules 目录中,因此在代码中只需要通过 require('express') 的方式就好,无需指定第三方包路径:const express = require('express');
2、全局安装(global)与本地安装(local)
- npm install express # 本地安装
- npm install express -g # 全局安装
如果出现以下错误:npm err! Error: connect ECONNREFUSED 127.0.0.1:8087
解决办法为:npm config set proxy null
本地安装
- 将安装包放在 ./node_modules 下(运行 npm 命令时所在的目录),如果没有 node_modules 目录,会在当前执行 npm 命令的目录下生成 node_modules 目录。
- 可以通过 require() 来引入本地安装的包。
全局安装
- 将安装包放在 /usr/local 下或者你 node 的安装目录【win环境中其实应该是 C:\Users\xxx\AppData\Roaming\npm\node_modules】。
- 可以直接在命令行里使用。
如果你希望具备两者功能,则需要在两个地方安装它或使用 npm link。
接下来我们使用全局方式安装 express:npm install express -g
可以使用自定义的路径去存储模块,参考 Node.js安装及环境配置之Windows篇~之环境变量配置
然后就可以直接引用全局模块了,eg:全局安装模块axios后,const axios = require('axios');。
3、查看安装信息
使用以下命令来查看所有全局安装的模块:npm list -g
如果要查看某个模块的版本号:npm list <module name>
4、使用package.json
package.json 位于模块的目录下,用于定义包的属性。
Package.json 属性说明
- name:包名
- version:包的版本号
- description:包的描述
- homepage:包的官网 url
- author:包的作者姓名
- contributors:包的其他贡献者姓名
- dependencies:依赖包列表;如果依赖包没有安装,NPM 会自动将依赖包安装在 node_module 目录下
- repository:包代码存放的地方的类型,可以是 git 或 svn,git 可在 Github 上
- main:main 字段指定了程序的主入口文件,require('moduleName') 就会加载这个文件;这个字段的默认值是模块根目录下面的 index.js
- keywords - 关键字
5、其他命令
卸载模块:npm uninstall module_name
更新模块:npm update module_name
搜索模块:npm search module_name
创建模块:npm init 生成package.json文件 (需要填写包的信息,注册用户,发布模块).......
查看所有命令:npm help
某条命令的帮助:npm help command_name
6、运行
两种方式
1、直接终端运行 node xxx.js
2、添加start启动项
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"start":"node service.js"
}
再执行npm start
7、版本号
NPM 使用语义版本号来管理代码,这里简单介绍一下。
语义版本号分为 X.Y.Z 三位,分别代表主版本号、次版本号和补丁版本号,当代码变更时,版本号按以下原则更新:
- 如果只是修复 bug,需要更新 Z 位。
- 如果是新增了功能,但是向下兼容,需要更新 Y 位。
- 如果有大变动,向下不兼容,需要更新 X 位。
版本号有了这个保证后,在申明第三方包依赖时,除了可依赖于一个固定版本号外,还可依赖于某个范围的版本号,例如 "argv": "0.0.x" 表示依赖于 0.0.x 系列的最新版 argv。
8、使用淘宝NPM镜像
大家都知道国内直接使用 npm 的官方镜像是非常慢的,在不涉及到“墙”的情况下,我们可以考虑使用淘宝 NPM 镜像。
淘宝 NPM 镜像(https://cnpmjs.org/)是一个完整 http://npmjs.org 镜像,可以用此代替官方版本(只读),同步频率目前为 10分钟一次以保证尽量与官方服务同步。
我个人比较喜欢使用淘宝定制的 cnpm(gzip 压缩支持)命令行工具代替默认的 npm:
npm install -g cnpm --registry=https://registry.npm.taobao.org
这样就可以使用 cnpm 命令来安装模块了:
cnpm install [name]
更多信息可以查阅:国内优秀npm镜像推荐及使用
REPL
REPL是Read Eval Print Loop 的缩写,中文译名是交互式解释器;其实说白了就是命令行的开发工具,这个也是 Node.js 的基础功能之一,使得我们可以不必借助浏览器环境,直接开发和运行一些无需 GUI 的程序,也就从很多方面上看起来更接近传统的开发语言环境。
它表示一个电脑的环境,类似 Window 系统的终端或 Unix/Linux shell,我们可以在终端中输入命令,并接收系统的响应。
Node 自带了交互式解释器,可以执行以下任务:
- 读取 - 读取用户输入,解析输入了 JavaScript 数据结构并存储在内存中
- 执行 - 执行输入的数据结构
- 打印 - 输出结果
- 循环 - 循环操作以上步骤直到用户两次按下 ctrl-c 按钮退出
Node 的交互式解释器可以很好的调试 JavaScript 代码。
我们可以输入 node 命令来启动 Node 的终端。
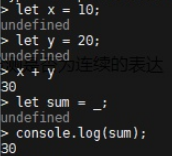
表达式计算:1+2
使用变量:变量声明用var、let、const,使用 console.log() 来输出。

下划线变量: 可以使用下划线 _ 获取上一个表达式的运算结果:
包运行器~NPX
NPX 就是一个可以直接执行 NPM 当中发布的模块的命令,而无需提前下载安装;或者也可以直接调用项目内的模块,或者说本地模块;甚至可以运行完全不同版本的 Node,这些都是它的强大之处。
- 用NPM需要先下载模块,再使用;
- 用NPX则直接使用,npx 会自动进行下载,执行该命令后再删除,比较适合需要一次性执行的任务。
事件循环
事件循环(Event Loop)是了解 Node.js 最重要的方面之一;它阐明了 Node.js 如何做到异步且具有非阻塞的 I/O,也就是 Node.js 的“杀手级应用”,正是这一点使它成功了。
和原生 JavaScript 一样,Node 的代码也是运行在单线程上的, 每次只处理一件事。
这个限制实际上非常有用,因为它大大简化了编程方式,而不必担心并发问题,只需要注意如何编写代码,并避免任何可能阻塞线程的事情,例如同步的网络调用或无限的循环。
通常,在大多数浏览器中,每个浏览器选项卡都有一个事件循环,以使每个进程都隔离开,并避免使用无限的循环或繁重的处理来阻止整个浏览器的网页。
Node 环境同理,它管理多个并发的事件循环,例如处理 API 调用、 Web 工作进程也运行在自己的事件循环中,我们所要关注的重心,就在于如何确保自己的应用工作在单线程当中,而不会阻塞事件循环。
阻塞事件循环
任何花费太长时间才能将控制权返回给事件循环的 JavaScript 代码,都会阻塞页面中任何 JavaScript 代码的执行,甚至阻塞 UI 线程,并且用户无法单击浏览、滚动页面等。
JavaScript 中几乎所有的 I/O 基元都是非阻塞的: 网络请求、文件系统操作等; 被阻塞是个异常,这就是 JavaScript 如此之多基于回调(当然打从 ES 6 发布之后,越来越多基于 promise 和 async/await)的原因。
调用堆栈
调用堆栈是一个 LIFO 队列(后进先出):事件循环不断地检查调用堆栈,以查看是否需要运行任何函数,当执行时,它会将找到的所有函数调用添加到调用堆栈中,并按顺序执行每个函数。
让一个函数执行插队
setTimeout(() => {}, 0) 就是个典型的在代码中其他函数执行之后,再调用一个函数的用法。
消息队列
当调用 setTimeout() 时,浏览器或 Node.js 会启动定时器, 当定时器到期时(在此示例中会立即到期,因为将超时值设为 0),则回调函数会被放入“消息队列”中。
在消息队列中,用户触发的事件(如单击或键盘事件、或获取响应)也会在此排队,然后代码才有机会对其作出反应;类似 onLoad 这样的 DOM 事件也如此。
事件循环会赋予调用堆栈优先级,它首先处理在调用堆栈中找到的所有东西,一旦其中没有任何东西,便开始处理消息队列中的东西。
我们不必等待诸如 setTimeout、fetch 或其他的函数来完成它们自身的工作,因为它们是由浏览器提供的,并且位于它们自身的线程中。
process.nextTick()
每当事件循环进行一次完整的行程时,我们都将其称为一个滴答。
当将一个函数传给 process.nextTick() 时,则指示引擎在当前操作结束(在下一个事件循环滴答开始之前)时调用此函数:
process.nextTick(() => {
//做些事情
});
事件循环正在忙于处理当前的函数代码,当该操作结束时,JS 引擎会运行在该操作期间传给 nextTick 调用的所有函数;这是可以告诉 JS 引擎异步地(在当前函数之后)处理函数的方式,但是尽快执行而不是将其排入队列。
调用 setTimeout(() => {}, 0) 会在下一个滴答结束时执行该函数,比使用 nextTick()(其会优先执行该调用并在下一个滴答开始之前执行该函数)晚得多。
当要确保在下一个事件循环迭代中代码已被执行,则需要使用 nextTick()。
setImmediate()
当要异步地(但要尽可能快)执行某些代码时,其中一个选择是使用 Node.js 提供的 setImmediate() 函数:
setImmediate(() => {
//运行一些东西
});
作为 setImmediate() 参数传入的任何函数都是在事件循环的下一个迭代中执行的回调。
setImmediate() 与 setTimeout(() => {}, 0)(传入 0 毫秒的延时)、process.nextTick() 有何不同?
- 传给 process.nextTick() 的函数会在事件循环的当前迭代中(当前操作结束之后)被执行; 这意味着它会始终在 setTimeout 和 setImmediate 之前执行。
- 延迟 0 毫秒的 setTimeout() 回调与 setImmediate() 非常相似; 执行顺序取决于各种因素,但是它们都会在事件循环的下一个迭代中运行。
异步编程与回调
- 回调函数
- 事件监听
- 发布/订阅
- Promise对象
Javascript的异步性
JavaScript 默认情况下是同步的,并且是单线程的,这意味着代码无法创建新的线程并且不能并行运行。
但是 JavaScript 诞生于浏览器内部,一开始的主要工作是响应用户的操作,例如 onClick、onMouseOver、onChange、onSubmit 等,使用同步的编程模型该如何做到这一点?
答案就在于它的环境: 浏览器通过提供一组可以处理这种功能的 API 来提供了一种实现方式。【回调】
而在 Node.js 这里,引入了非阻塞的 I/O 环境,以将该概念扩展到文件访问、网络调用等。
回调
我们不知道用户何时单击按钮,因此,为点击事件定义了一个事件处理程序,该事件处理程序会接受一个函数,该函数会在该事件被触发时被调用:
document.getElementById('button').addEventListener('click', () => {
//被点击
});
这就是所谓的回调。
回调是一个简单的函数,会作为值被传给另一个函数,并且仅在事件发生时才被执行; 之所以这样做,是因为 JavaScript 具有顶级的函数,这些函数可以被分配给变量并传给其他函数(称为高阶函数)。
回调的替代方法
从 ES 6 开始,JavaScript 引入了一些特性,可以帮助处理异步代码而不涉及使用回调:Promise(ES 6)和 Async/Await(ES 2017),都是非常好的替代方式,这样回调可以修改成更为直观的链式操作,譬如上面的例子:
$.get('https://www.bing.com')
.done( () => {
// 操作
}).fail( () => {
// 报错操作
});
再比如 Promise 的例子(当然是很简单的例子):
const myPromise = new Promise((resolve, reject) => { resolve('done'); reject('error'); }); myPromise.then(value => { console.log(value); // expected output: "foo" });
Promise简介
Promise 通常被定义为最终会变为可用值的代理,它是一种处理异步代码(而不会陷入Callback Hell 回调地狱)的方式。
异步函数( async 和 await)在底层使用了 promise,因此了解 promise 的工作方式是了解 async 和 await 的基础。
Promise如何运作
当 promise 被调用后,它会以处理中状态开始; 这意味着调用的函数会继续执行,而 promise 仍处于处理中直到解决为止,从而为调用的函数提供所请求的任何数据。
被创建的 promise 最终会以被解决状态【resolve】或被拒绝状态【reject】结束,并在完成时调用相应的回调函数(传给 then 和 catch)。
创建Promise
Promise API 公开了一个 Promise 构造函数,可以使用 new Promise() 对其进行初始化:
const done = true; const isItDoneYet = new Promise((resolve, reject) => { if (done) { const workDone = '这是创建的东西'; resolve(workDone); } else { const why = '仍然在处理其他事情'; reject(why); } });
这里 promise 检查了 done 全局常量,如果为真,则 promise 进入被解决状态(因为调用了 resolve 回调);否则,则执行 reject 回调(将 promise 置于被拒绝状态);如果在执行路径中从未调用过这些函数之一,则 promise 会保持处理中状态。
使用 resolve 和 reject,可以向调用者传达最终的 promise 状态以及该如何处理;在上面的例子中,只返回了一个字符串,但是它可以是一个对象,也可以为 null;
一个更常见的示例是一种被称为 Promisifying 的技术,这项技术能够使用经典的 JavaScript 函数来接受回调并使其返回 promise(就是 return new Promise()):


const fs = require('fs');
const getFile = fileName => {
return new Promise((resolve, reject) => {
fs.readFile(fileName, (err, data) => {
if (err) {
reject (err); // 调用 reject 会导致 promise 失败,无论是否传入错误作为参数,
return; // 且不再进行下去。
}
resolve(data);
});
});
};
getFile('/etc/passwd')
.then(data => console.log(data))
.catch(err => console.error(err));
async/await
JavaScript 在很短的时间内从回调发展到了 promise(ES 6 或者 ES 2015),且自 ES 2017 以来,异步的 JavaScript 使用 async/await 语法甚至更加简单。
异步函数是 promise 和生成器的组合,基本上,它们是 promise 的更高级别的抽象; 而 async/await 建立在 promise 之上,减少了 promises 自身的语法复杂性,且减少了 promise 链的“不破坏链条”的限制
当 ES 6 中引入 Promise 时,本来旨在解决异步代码的问题,并且确实做到了,但是很明显,promise 不可能成为最终的解决方案:Promise 反而引入了语法复杂性。
故而在 ES 2017 当中,async/await 出现了,它们可以向开发人员提供更容易理解和更简洁的语法,它们使代码看起来像是同步的,但实际上是异步的并且在后台无阻塞。
简单示例
const aFunction = async () => { return '测试'; }; aFunction().then(alert);
在任何函数之前加上 async 关键字意味着该函数会返回 promise;即使没有显式地这样做,它也会在内部返回 promise。
const aFunction = async () => { return Promise.resolve('测试'); }; aFunction().then(alert);
代码更容易阅读
例如,这是使用 promise 获取并解析 JSON 资源的方法:
const getFirstUserData = () => { return fetch('/users.json') // 获取用户列表 .then(response => response.json()) // 解析 JSON .then(users => users[0]) // 选择第一个用户 .then(user => fetch(`/users/${user.name}`)) // 获取用户数据 .then(userResponse => userResponse.json()); // 解析 JSON }; getFirstUserData();
这是使用 await/async 提供的相同功能:
const getFirstUserData = async () => { const response = await fetch('/users.json'); // 获取用户列表 const users = await response.json(); // 解析 JSON const user = users[0]; // 选择第一个用户 const userResponse = await fetch(`/users/${user.name}`); // 获取用户数据 const userData = await userResponse.json(); // 解析 JSON return userData; } getFirstUserData();
看起来后者更像是同步的代码,仅仅是多增加了 await 命令,这样对编程人员来说更容易理解,也更不容易出错。
组件
HTTP服务器
其实 Node.js 最初的目的,就是实现一个完全可以由 JavaScript 来进行开发的服务器端,所以归根到底,它的后端能力之一就是实现一个 HTTP 服务器,
见 示例程序
使用Node.js发送Http请求
get请求
const https = require('http');
const options = {
hostname: '127.0.0.1',
port: 3000,
path: '/',
method: 'GET'
};
const req = https.request(options, res => {
console.log(`状态码: ${res.statusCode}`);
res.on('data', d => {
process.stdout.write(d);
});
});
req.on('error', error => {
console.error(error);
});
req.end();
Post请求
const https = require('http');
const data = JSON.stringify({
todo: '做点事情'
});
const options = {
hostname: '127.0.0.1',
port: 3000,
path: '/',
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Content-Length': data.length
}
};
const req = https.request(options, res => {
console.log(`状态码: ${res.statusCode}`);
res.on('data', d => {
process.stdout.write(d);
});
});
req.on('error', error => {
console.error(error);
});
req.write(data);
req.end();
使用Axios发送Http请求
在 Node.js 中,有多种方式可以执行 HTTP POST 请求,具体取决于要使用的抽象级别。
使用 Node.js 执行 HTTP 请求的最简单的方式是使用 f="https://github.com/axios/axios">Axios 库(多嘴说一句,Vue.js 推荐使用的也是这个库):
const axios = require('axios');
axios
.post('http://nodejs.cn/todos', {
todo: '做点事情'
})
.then(res => {
console.log(`状态码: ${res.statusCode}`);
console.log(res);
})
.catch(error => {
console.error(error);
});
Axios 是第三方的库,所以需要通过包管理器先进行安装。
HTTP模块
HTTP 核心模块是 Node.js 网络的关键模块。
方法:
(1)http.createServer()
返回 http.Server 类的新实例。
const server = http.createServer((req, res) => { //使用此回调处理每个单独的请求 })
(2)http.request()
发送 HTTP 请求到服务器,并创建 http.ClientRequest 类的实例。
(3)http.get()
类似于 http.request(),但会自动地设置 HTTP 方法为 GET,并自动地调用 req.end()。
类:
HTTP 模块提供了 5 个类:
- http.Agent
- http.ClientRequest
- http.Server
- http.ServerResponse
- http.IncomingMessage
文件系统
1、fs 模块
提供了许多非常实用的函数来访问文件系统并与文件系统进行交互,它作为 Node.js 核心的组成部分,无需安装,可以通过简单地引用来使用它:
const fs = require('fs');- fs.access():检查文件是否存在,以及 Node.js 是否有权限访问
- fs.appendFile():追加数据到文件,如果文件不存在,则创建文件
- fs.chmod(): 更改文件(通过传入的文件名指定)的权限,相关方法:fs.lchmod()、fs.fchmod()
- fs.chown():更改文件(通过传入的文件名指定)的所有者和群组,相关方法:fs.fchown()、fs.lchown()
- fs.close():关闭文件描述符
- fs.copyFile():拷贝文件
- fs.createReadStream():创建可读的文件流
- fs.createWriteStream():创建可写的文件流
- fs.link():新建指向文件的硬链接
- fs.mkdir():新建文件夹
- fs.mkdtemp():创建临时目录
- fs.open():设置文件模式
- fs.readdir():读取目录的内容
- fs.readFile():读取文件的内容,相关方法:fs.read()
- fs.readlink():读取符号链接的值
- fs.realpath():将相对的文件路径指针(.、..)解析为完整的路径
- fs.rename():重命名文件或文件夹
- fs.rmdir():删除文件夹
- fs.stat():返回文件(通过传入的文件名指定)的状态,相关方法:fs.fstat()、fs.lstat()
- fs.symlink():新建文件的符号链接
- fs.truncate():将传递的文件名标识的文件截断为指定的长度,相关方法:fs.ftruncate()
- fs.unlink():删除文件或符号链接
- fs.unwatchFile():停止监视文件上的更改
- fs.utimes():更改文件(通过传入的文件名指定)的时间戳,相关方法:fs.futimes()
- fs.watchFile():开始监视文件上的更改,相关方法:fs.watch()
- fs.writeFile():将数据写入文件,相关方法:fs.write()
关于 fs 模块的特殊之处是,所有的方法默认情况下都是异步的,但是通过加上 Sync 后缀也可以同步地工作。
例如:
- fs.rename()
- fs.renameSync()
- fs.write()
- fs.writeSync()
2、path模块
提供了许多非常实用的函数来访问文件系统并与文件系统进行交互,同样作为 Node.js 核心的组成部分,也是无需安装的。
该模块提供了 path.sep(作为路径段分隔符,在 Windows 上是 \,在 Linux/macOS 上是 /)和 path.delimiter(作为路径定界符,在 Windows 上是 ;,在 Linux/macOS 上是 :)。
事件触发、操作系统、流
因为我们之前在浏览器中使用 JavaScript,所以知道 JS 通过事件处理了许多用户的交互:鼠标的单击、键盘按钮的按下、对鼠标移动的反应等等。
在后端,Node.js 也提供了使用 events 模块 构建类似系统的选项。
具体上,此模块提供了 EventEmitter 类,用于处理事件。
使用以下代码进行初始化:
const EventEmitter = require('events');
const eventEmitter = new EventEmitter();
该对象公开了 on 和 emit 方法:
- emit 用于触发事件
- on 用于添加回调函数(会在事件被触发时执行)
例如,创建 start 事件,并提供一个示例,通过记录到控制台进行交互:
eventEmitter.on('start', () => {
console.log('开始');
});
//当运行以下代码时:事件处理函数会被触发,且获得控制台日志。
eventEmitter.emit('start');
通过将参数作为额外参数传给 emit() 来将参数传给事件处理程序,以下是两个参数的示例:
eventEmitter.on('start', (start, end) => {
console.log(`从 ${start} 到 ${end}`);
});
eventEmitter.emit('start', 1, 100);
更多参考

 浙公网安备 33010602011771号
浙公网安备 33010602011771号