keras实战教程二(文本分类BiLSTM)
什么是文本分类
给模型输入一句话,让模型判断这句话的类别(预定义)。
以文本情感分类为例
输入:的确是专业,用心做,出品方面都给好评。
输出:2
输出可以是[0,1,2]其中一个,0表示情感消极,1表示情感中性,2表示情感积极。
数据样式

网上应该能找到相关数据。
模型图
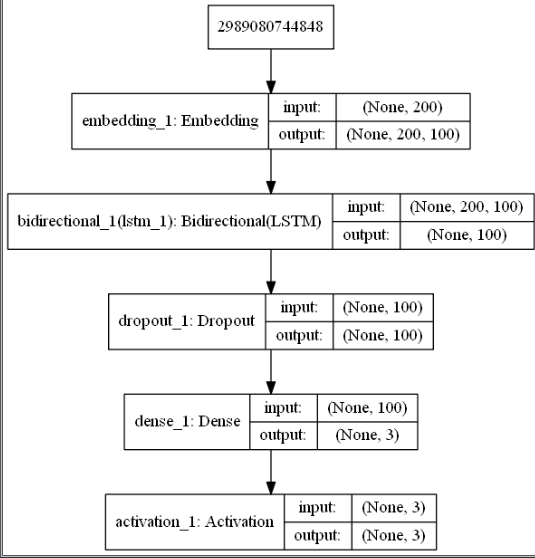
训练过程

仅仅作为测试训练一轮
代码
读取数据
import numpy as np from gensim.models.word2vec import Word2Vec from gensim.corpora.dictionary import Dictionary from gensim import models import pandas as pd import jieba import logging from keras import Sequential from keras.preprocessing.sequence import pad_sequences from keras.layers import Bidirectional,LSTM,Dense,Embedding,Dropout,Activation,Softmax from sklearn.model_selection import train_test_split from keras.utils import np_utils def read_data(data_path): senlist = [] labellist = [] with open(data_path, "r",encoding='gb2312',errors='ignore') as f: for data in f.readlines(): data = data.strip() sen = data.split("\t")[2] label = data.split("\t")[3] if sen != "" and (label =="0" or label=="1" or label=="2" ) : senlist.append(sen) labellist.append(label) else: pass assert(len(senlist) == len(labellist)) return senlist ,labellist sentences,labels = read_data("data_train.csv")
词向量
def train_word2vec(sentences,save_path): sentences_seg = [] sen_str = "\n".join(sentences) res = jieba.lcut(sen_str) seg_str = " ".join(res) sen_list = seg_str.split("\n") for i in sen_list: sentences_seg.append(i.split()) print("开始训练词向量") # logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO) model = Word2Vec(sentences_seg, size=100, # 词向量维度 min_count=5, # 词频阈值 window=5) # 窗口大小 model.save(save_path) return model model = train_word2vec(sentences,'word2vec.model')
数据处理
def generate_id2wec(word2vec_model): gensim_dict = Dictionary() gensim_dict.doc2bow(model.wv.vocab.keys(), allow_update=True) w2id = {v: k + 1 for k, v in gensim_dict.items()} # 词语的索引,从1开始编号 w2vec = {word: model[word] for word in w2id.keys()} # 词语的词向量 n_vocabs = len(w2id) + 1 embedding_weights = np.zeros((n_vocabs, 100)) for w, index in w2id.items(): # 从索引为1的词语开始,用词向量填充矩阵 embedding_weights[index, :] = w2vec[w] return w2id,embedding_weights def text_to_array(w2index, senlist): # 文本转为索引数字模式 sentences_array = [] for sen in senlist: new_sen = [ w2index.get(word,0) for word in sen] # 单词转索引数字 sentences_array.append(new_sen) return np.array(sentences_array) def prepare_data(w2id,sentences,labels,max_len=200): X_train, X_val, y_train, y_val = train_test_split(sentences,labels, test_size=0.2) X_train = text_to_array(w2id, X_train) X_val = text_to_array(w2id, X_val) X_train = pad_sequences(X_train, maxlen=max_len) X_val = pad_sequences(X_val, maxlen=max_len) return np.array(X_train), np_utils.to_categorical(y_train) ,np.array(X_val), np_utils.to_categorical(y_val)
w2id,embedding_weights = generate_id2wec(model)# 获取词向量矩阵和词典
x_train,y_trian, x_val , y_val = prepare_data(w2id,sentences,labels,200)#将数据处理成模型需要的格式
构建模型
class Sentiment: def __init__(self,w2id,embedding_weights,Embedding_dim,maxlen,labels_category): self.Embedding_dim = Embedding_dim self.embedding_weights = embedding_weights self.vocab = w2id self.labels_category = labels_category self.maxlen = maxlen self.model = self.build_model() def build_model(self): model = Sequential() #input dim(140,100) model.add(Embedding(output_dim = self.Embedding_dim, input_dim=len(self.vocab)+1, weights=[self.embedding_weights], input_length=self.maxlen)) model.add(Bidirectional(LSTM(50),merge_mode='concat')) model.add(Dropout(0.5)) model.add(Dense(self.labels_category)) model.add(Activation('softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) model.summary() return model def train(self,X_train, y_train,X_test, y_test,n_epoch=5 ): self.model.fit(X_train, y_train, batch_size=32, epochs=n_epoch, validation_data=(X_test, y_test)) self.model.save('sentiment.h5') def predict(self,model_path,new_sen): model = self.model model.load_weights(model_path) new_sen_list = jieba.lcut(new_sen) sen2id =[ self.vocab.get(word,0) for word in new_sen_list] sen_input = pad_sequences([sen2id], maxlen=self.maxlen) res = model.predict(sen_input)[0] return np.argmax(res)
senti = Sentiment(w2id,embedding_weights,100,200,3)
训练预测
senti.train(x_train,y_trian, x_val ,y_val,1)#训练
label_dic = {0:"消极的",1:"中性的",2:"积极的"}
sen_new = "现如今的公司能够做成这样已经很不错了,微订点单网站的信息更新很及时,内容来源很真实"
pre = senti.predict("./sentiment.h5",sen_new)
print("'{}'的情感是:\n{}".format(sen_new,label_dic.get(pre)))
参考https://www.jianshu.com/p/fba7df3a76fa

 浙公网安备 33010602011771号
浙公网安备 33010602011771号