keras实战教程一(NER)
NLP四大任务:序列标注(分词,NER),文本分类(情感分析),句子关系判断(语意相似判断),句子生成(机器翻译)
什么是序列标注
以命名实体识别为例,识别一句话中的人名地名组织时间等都属于序列标注问题。NER 的任务就是要将这些包含信息的或者专业领域的实体给识别出来
示例
句子:[我在上海工作]
tag : [O,O,B_LOC,I_LOC,O,O]
数据
训练数据样

模型
BiLSTM+CRF
LSTM 强大的拟合能力可以很好的完成这个序列标注问题。
CRF能记住实体序列的规则。它的作用是纠正LSTM的一些低级错误。
模型图
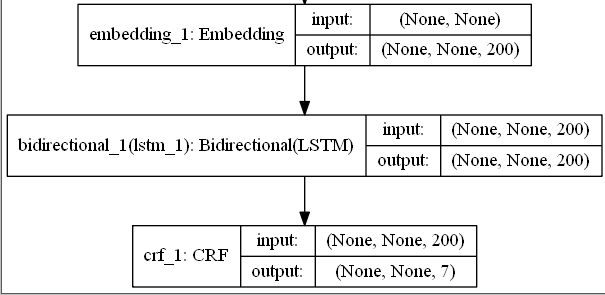
代码
数据处理
import pickle import numpy as np from keras.preprocessing.sequence import pad_sequences from keras import Sequential from keras_contrib.layers import CRF import pickle from keras.layers import Embedding ,Bidirectional,LSTM class Data_set: def __init__(self,data_path,labels): with open(data_path,"rb") as f: self.data = f.read().decode("utf-8") self.process_data = self.process_data() self.labels = labels def process_data(self): train_data =self.data.split("\n\n") train_data = [token.split("\n") for token in train_data] train_data = [[j.split() for j in i ] for i in train_data] train_data.pop() return train_data def save_vocab(self,save_path): all_char = [ char[0] for sen in self.process_data for char in sen] chars = set(all_char) word2id = {char:id_+1 for id_,char in enumerate(chars)} word2id["unk"] = 0 with open (save_path,"wb") as f: pickle.dump(word2id,f) return word2id def generate_data(self,vocab,maxlen): char_data_sen = [[token[0] for token in i ] for i in self.process_data] label_sen = [[token[1] for token in i ] for i in self.process_data] sen2id = [[ vocab.get(char,0) for char in sen] for sen in char_data_sen] label2id = {label:id_ for id_,label in enumerate(self.labels)} lab_sen2id = [[label2id.get(lab,0) for lab in sen] for sen in label_sen] sen_pad = pad_sequences(sen2id,maxlen) lab_pad = pad_sequences(lab_sen2id,maxlen,value=-1) lab_pad = np.expand_dims(lab_pad, 2) return sen_pad ,lab_pad
环境:keras==2.2.4 tf==1.12.0 安装keras-contrib :pip install git+https://www.github.com/keras-team/keras-contrib.git
data = Data_set("train_data.data",['O', 'B-PER', 'I-PER', 'B-LOC', 'I-LOC', "B-ORG", "I-ORG"]) vocab = data.save_vocab("vocab.pk") sentence,sen_tags= data.generate_data(vocab,200)
构建模型
class Ner: def __init__(self,vocab,labels_category,Embedding_dim=200): self.Embedding_dim = Embedding_dim self.vocab = vocab self.labels_category = labels_category self.model = self.build_model() def build_model(self): model = Sequential() model.add(Embedding(len(self.vocab),self.Embedding_dim,mask_zero=True)) # Random embedding model.add(Bidirectional(LSTM(100, return_sequences=True))) crf = CRF(len(self.labels_category), sparse_target=True) model.add(crf) model.summary() model.compile('adam', loss=crf.loss_function, metrics=[crf.accuracy]) return model def train(self,data,label,EPOCHS): self.model.fit(data,label,batch_size=16,epochs=EPOCHS) self.model.save('crf.h5') def predict(self,model_path,data,maxlen): model =self.model char2id = [self.vocab.get(i) for i in data] pad_num = maxlen - len(char2id) input_data = pad_sequences([char2id],maxlen) model.load_weights(model_path) result = model.predict(input_data)[0][-len(data):] result_label = [np.argmax(i) for i in result] return result_label
tags = ['O', 'B-PER', 'I-PER', 'B-LOC', 'I-LOC', "B-ORG", "I-ORG"] ner = Ner(vocab,tags)
训练预测
ner.train(sentence,sen_tags,1)
sen_test = "北京故宫,清华大学图书馆" res = ner.predict("./crf.h5",sen_test,200) label = ['O', 'B-PER', 'I-PER', 'B-LOC', 'I-LOC', "B-ORG", "I-ORG"] res2label =[label[i] for i in res] per, loc, org = '', '', '' for s, t in zip(a, res2label): if t in ('B-PER', 'I-PER'): per += ' ' + s if (t == 'B-PER') else s if t in ('B-ORG', 'I-ORG'): org += ' ' + s if (t == 'B-ORG') else s if t in ('B-LOC', 'I-LOC'): loc += ' ' + s if (t == 'B-LOC') else s print("人名:",per) print("地名:",loc) print("组织名:",org)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号