【JVM源码解析】虚拟机解释执行Java方法(上)
本文由HeapDump性能社区首席讲师鸠摩(马智)授权整理发布
第29篇-调用Java主类的main()方法
前面已经写了许多篇介绍字节码指令对应的汇编代码执行逻辑,还有一些字节码指令对应的汇编代码逻辑没有介绍,这些指令包括方法调用指令、同步指令、异常抛出指令,这些指令的汇编代码实现逻辑比较复杂,所以后面在介绍到方法调用、同步和异常处理的知识点时,会通过大篇幅的文章进行详细介绍!
在第1篇中大概介绍过Java中主类方法main()的调用过程,这一篇介绍的详细一点,大概的调用过程如下图所示。
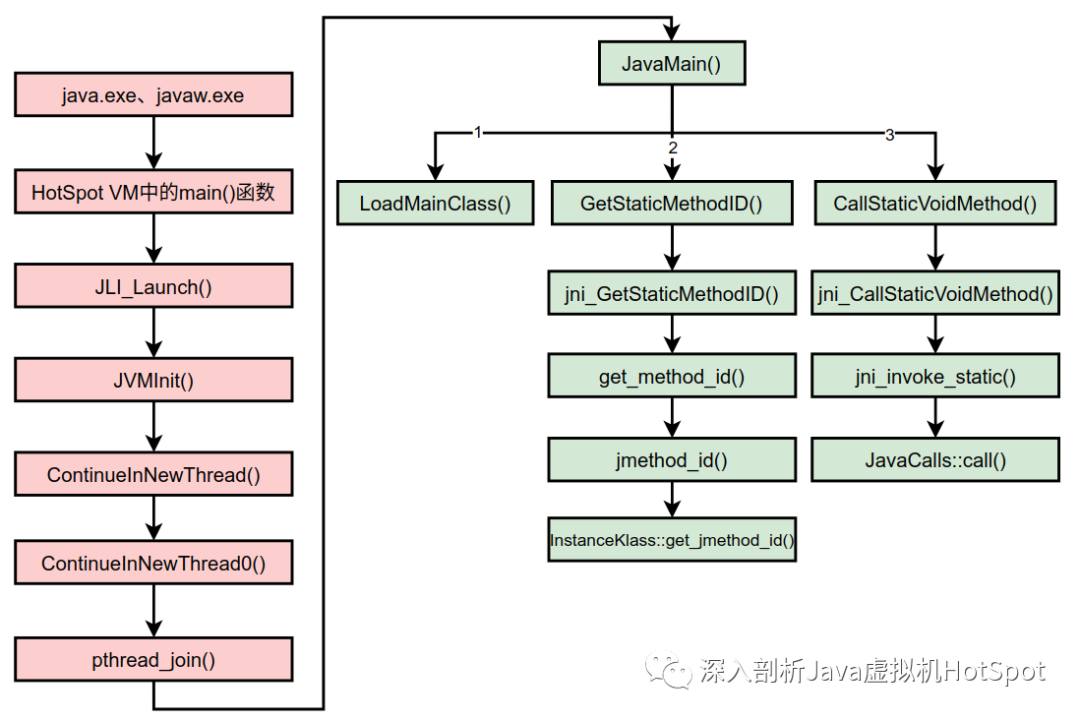
其中浅红色的函数由主线程执行,而另外的浅绿色部分由另外一个线程执行,浅绿色的线程最终也会负责执行Java主类中的main()方法。在JavaMain()函数中调用LoadMainClass()函数加载Java主类。接着在JavaMain()函数中有如下调用:
源代码位置:openjdk/jdk/src/share/bin/java.c
mainID = (*env)->GetStaticMethodID(
env,
mainClass,
"main",
"([Ljava/lang/String;)V");
env为JNIEnv*类型。调用JNIEnv类型中定义的GetStaticMethodID()函数获取Java主类中main()方法的方法唯一ID,调用GetStaticMethodID()函数就是调用jni_GetStaticMethodID()函数,此函数的实现如下:
源代码位置:openjdk/hotspot/src/share/vm/prims/jni.cpp
JNI_ENTRY(jmethodID, jni_GetStaticMethodID(JNIEnv *env, jclass clazz,const char *name, const char *sig))
jmethodID ret = get_method_id(env, clazz, name, sig, true, thread);
return ret;
JNI_END
static jmethodID get_method_id(
JNIEnv *env,
jclass clazz,
const char *name_str,
const char *sig,
bool is_static,
TRAPS
){
const char *name_to_probe = (name_str == NULL)
? vmSymbols::object_initializer_name()->as_C_string()
: name_str;
TempNewSymbol name = SymbolTable::probe(name_to_probe, (int)strlen(name_to_probe));
TempNewSymbol signature = SymbolTable::probe(sig, (int)strlen(sig));
KlassHandle klass(THREAD,java_lang_Class::as_Klass(JNIHandles::resolve_non_null(clazz)));
// 保证java.lang.Class类已经初始化完成
klass()->initialize(CHECK_NULL);
Method* m;
if ( name == vmSymbols::object_initializer_name() || 查找的是<init>方法
name == vmSymbols::class_initializer_name() ) { 查找的是<clinit>方法
// 因为要查找的是构造函数,构造函数没有继承特性,所以当前类找不到时不向父类中继续查找
if (klass->oop_is_instance()) {
// find_method()函数不会向上查找
m = InstanceKlass::cast(klass())->find_method(name, signature);
} else {
m = NULL;
}
} else {
// lookup_method()函数会向上查找
m = klass->lookup_method(name, signature);
if (m == NULL && klass->oop_is_instance()) {
m = InstanceKlass::cast(klass())->lookup_method_in_ordered_interfaces(name, signature);
}
}
return m->jmethod_id();
}
获取Java类中main()方法的jmethod_id。
源代码位置:method.hpp
// Get this method's jmethodID -- allocate if it doesn't exist
jmethodID jmethod_id() {
methodHandle this_h(this);
return InstanceKlass::get_jmethod_id(method_holder(), this_h);
}
调用的InstanceKlass::get_jmethod_id()函数获取唯一ID,关于如何获取或生成ID的过程这里不再详细介绍,有兴趣的自行研究。
在JavaMain()函数中有如下调用:
mainArgs = CreateApplicationArgs(env, argv, argc);
(*env)->CallStaticVoidMethod(env, mainClass, mainID, mainArgs);
通过调用CallStaticVoidMethod()函数来调用Java主类中的main()方法。控制权转移到Java主类中的main()方法之中。调用CallStaticVoidMethod()函数就是调用jni_CallStaticVoidMethod()函数,此函数的实现如下:
源代码位置:openjdk/hotspot/src/share/vm/prims/jni.cpp
JNI_ENTRY(void, jni_CallStaticVoidMethod(JNIEnv *env, jclass cls, jmethodID methodID, ...))
va_list args;
va_start(args, methodID);
JavaValue jvalue(T_VOID);
JNI_ArgumentPusherVaArg ap(methodID, args);
jni_invoke_static(env, &jvalue, NULL, JNI_STATIC, methodID, &ap, CHECK);
va_end(args);
JNI_END
将传给Java方法的参数以C的可变长度参数传入后,使用JNI_ArgumentPusherVaArg实例ap是将其封装起来。JNI_ArgumentPusherVaArg类的继承体系如下:
JNI_ArgumentPusherVaArg->JNI_ArgumentPusher->SignatureIterator
调用的jni_invoke_static()函数的实现如下:
// 通过jni的方式调用Java静态方法
static void jni_invoke_static(
JNIEnv *env,
JavaValue* result,
jobject receiver,
JNICallType call_type,
jmethodID method_id,
JNI_ArgumentPusher *args,
TRAPS
){
Method* m = Method::resolve_jmethod_id(method_id);
methodHandle method(THREAD, m);
ResourceMark rm(THREAD);
int number_of_parameters = method->size_of_parameters();
// 这里进一步将要传给Java的参数转换为JavaCallArguments对象传下去
JavaCallArguments java_args(number_of_parameters);
args->set_java_argument_object(&java_args);
// Fill out(填,填写) JavaCallArguments object
Fingerprinter fp = Fingerprinter(method);
uint64_t x = fp.fingerprint();
args->iterate(x);
// Initialize result type
BasicType bt = args->get_ret_type();
result->set_type(bt);
// Invoke the method. Result is returned as oop.
JavaCalls::call(result, method, &java_args, CHECK);
// Convert result
if (
result->get_type() == T_OBJECT ||
result->get_type() == T_ARRAY
) {
oop tmp = (oop) result->get_jobject();
jobject jobj = JNIHandles::make_local(env,tmp);
result->set_jobject(jobj);
}
}
通过JavaCalls::call()函数来调用Java主类的main()方法。关于JavaCalls::call()函数大家应该不会陌生,这个函数是怎么建立Java栈帧以及找到Java方法入口在之前已经详细介绍过,这里不再介绍。
第30篇-解释执行main()方法小实例
我们在介绍完一些常用字节码指令的汇编代码执行逻辑后,基本看到一个main()方法从开始调用、栈帧建立、字节码执行的整个逻辑了,但是方法退栈、同步方法以及异常抛出等知识点还没有介绍,我们这里只举个最简单的例子,可以帮助大家回顾一下之前那么多篇文章所学到的内容。
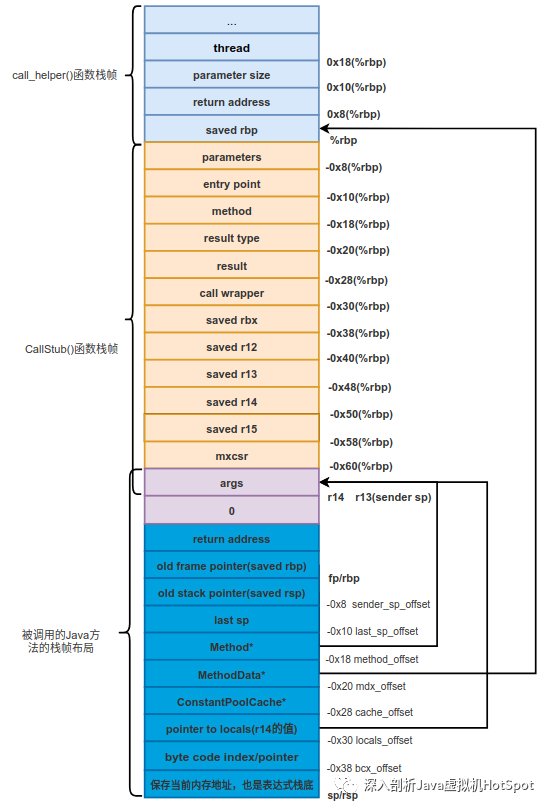
在第7篇详细介绍过为Java方法创建的栈帧,如下图所示。
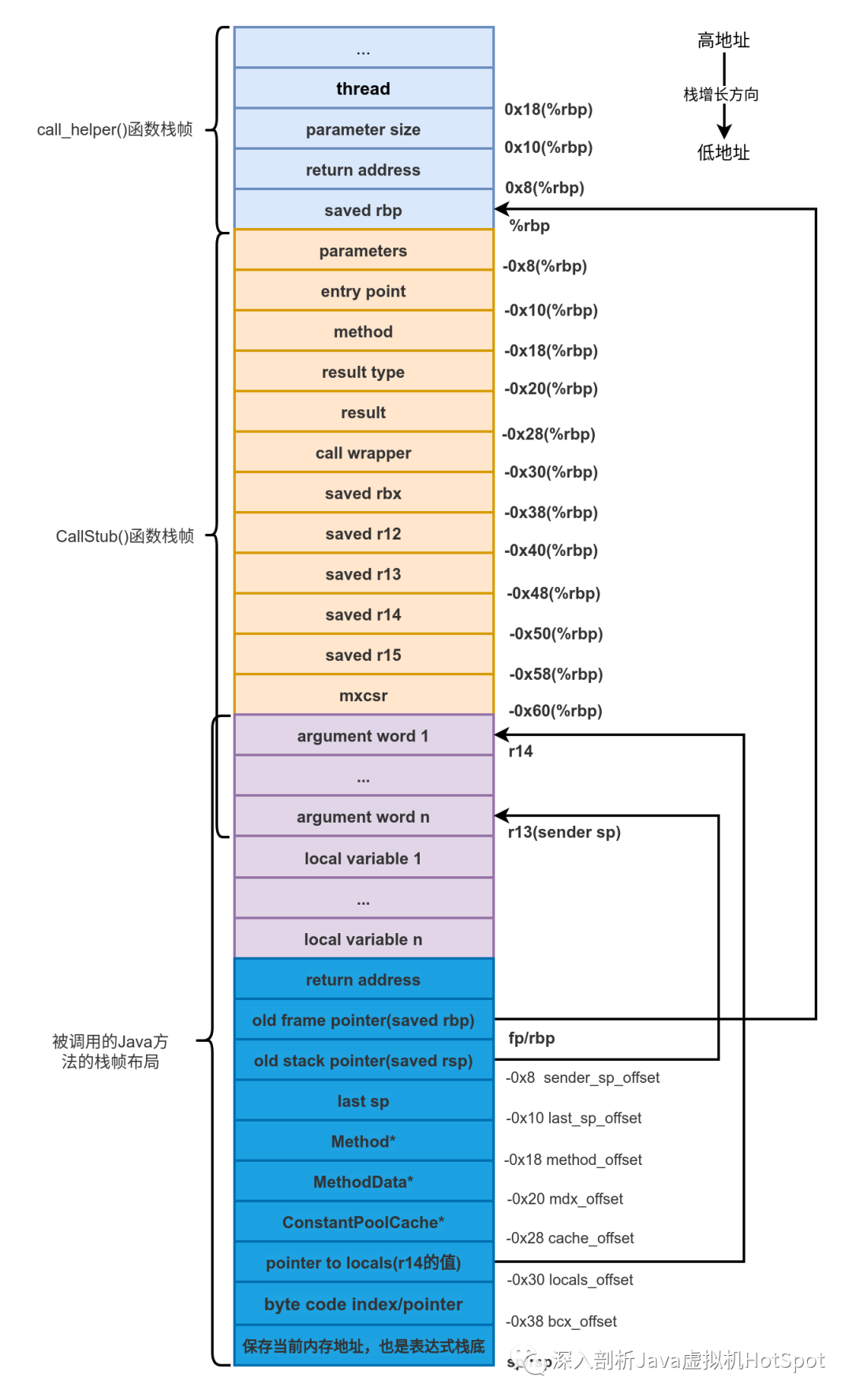
调用完generate_fixed_frame()函数后一些寄存器中保存的值如下:
rbx:Method*
ecx:invocation counter
r13:bcp(byte code pointer)
rdx:ConstantPool* 常量池的地址
r14:本地变量表第1个参数的地址
现在我们举一个例子,来完整的走一下解释执行的过程。这个例子如下:
package com.classloading;
public class Test {
public static void main(String[] args) {
int i = 0;
i = i++;
}
}
通过javap -verbose Test.class命令反编译后的字节码文件内容如下:
Constant pool:
#1 = Methodref #3.#12 // java/lang/Object."<init>":()V
#2 = Class #13 // com/classloading/Test
#3 = Class #14 // java/lang/Object
#4 = Utf8 <init>
#5 = Utf8 ()V
#6 = Utf8 Code
#7 = Utf8 LineNumberTable
#8 = Utf8 main
#9 = Utf8 ([Ljava/lang/String;)V
#10 = Utf8 SourceFile
#11 = Utf8 Test.java
#12 = NameAndType #4:#5 // "<init>":()V
#13 = Utf8 com/classloading/Test
#14 = Utf8 java/lang/Object
{
...
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=1, locals=2, args_size=1
0: iconst_0
1: istore_1
2: return
}
如上实例对应的栈帧状态如下图所示。
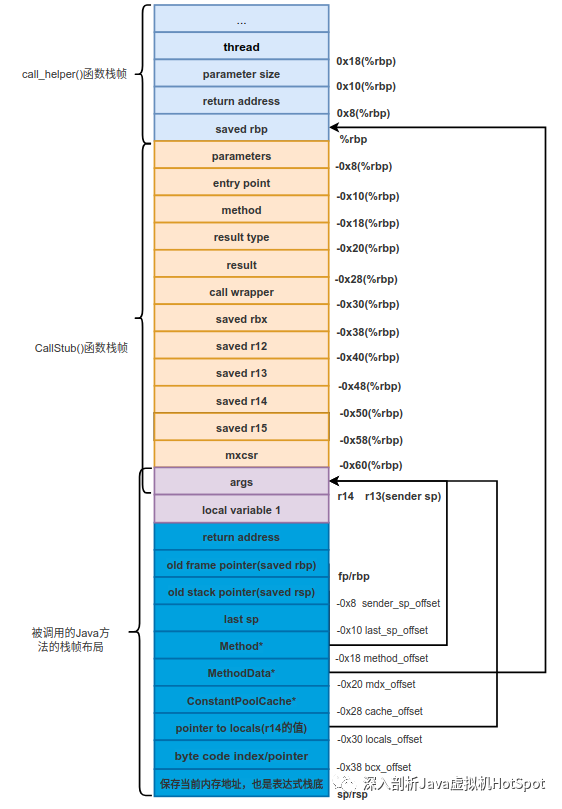
现在我们就以解释执行的方式执行main()方法中的字节码。由于是从虚拟机调用过来的,而调用完generate_fixed_frame()函数后一些寄存器中保存的值并没有涉及到栈顶缓存,所以需要从iconst_0这个字节码指令的vtos入口进入,然后找到iconst_0这个字节码指令对应的机器指令片段。
现在回顾一下字节码分派的逻辑,在generate_normal_entry()函数中会调用generate_fixed_frame()函数为Java方法的执行生成对应的栈帧,接下来还会调用dispatch_next()函数执行Java方法的字节码,首次获取字节码时的汇编如下:
// 在generate_fixed_frame()方法中已经让%r13存储了bcp
movzbl 0x0(%r13),%ebx // %ebx中存储的是字节码的操作码
// $0x7ffff73ba4a0这个地址指向的是对应state状态下的一维数组,长度为256
movabs $0x7ffff73ba4a0,%r10
// 注意%r10中存储的是常量,根据计算公式%r10+%rbx*8来获取指向存储入口地址的地址,
// 通过*(%r10+%rbx*8)获取到入口地址,然后跳转到入口地址执行
jmpq *(%r10,%rbx,8)
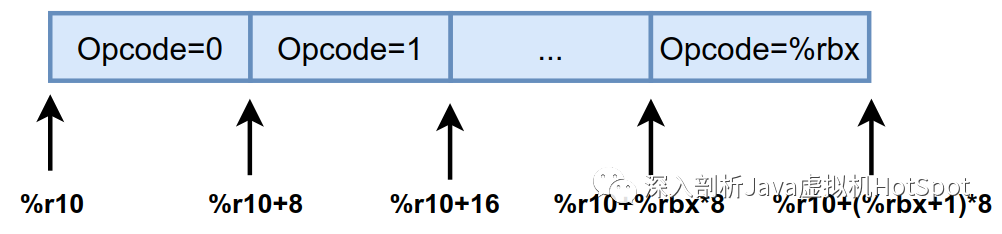
注意如上的$0x7ffff73ba4a0这个常量值已经表示了栈顶缓存状态为vtos下的一维数组首地址。而在首次进行方法的字节码分派时,通过0x0(%r13)即可取出字节码对应的Opcode,使用这个Opcode可定位到iconst_0的入口地址。
%r10指向的是对应栈顶缓存状态state下的一维数组,长度为256,其中存储的值为Opcode,这在第8篇详细介绍过,示意图如下图所示。
现在就是看入口为vtos,出口为itos的iconst_0所要执行的汇编代码了,如下:
...
// vtos入口
mov $0x1,%eax
...
// iconst_0对应的汇编代码
xor %eax,%eax
汇编指令足够简单,最后将值存储到了%eax中,所以也就是栈顶缓存的出口状态为itos。
上图紫色的部分是本地变量表,由于本地变量表的大小为2,所以我画了2个方格表示slot。
执行下一个字节码指令istore_1,也会执行字节码分派相关的逻辑。这里需要提醒下,其实之前在介绍字节码指令对应的汇编时,只关注了字节码指令本身的执行逻辑,其实在为每个字节码指令生成机器指令时,一般都会为这些字节码指令生成3部分机器指令片段:
(1)不同栈顶状态对应的入口执行逻辑;
(2)字节码指令本身需要执行的逻辑;
(3)分派到下一个字节码指令的逻辑。
对于字节码指令模板定义中,如果flags中指令有disp,那么这些指令自己会含有分派的逻辑,如goto、ireturn、tableswitch、lookupswitch、jsr等。由于我们的指令是iconst_0,所以会为这个字节码指令生成分派逻辑,生成的逻辑如下:
movzbl 0x1(%r13),%ebx // %ebx中存储的是字节码的操作码
movabs itos对应的一维数组的首地址,%r10
jmpq *(%r10,%rbx,8)
需要注意的是,如果要让%ebx中存储istore_1的Opcode,则%r13需要加上iconst_0指令的长度,即1。由于iconst_0执行后的出口栈顶缓存为itos,所以要找到入口状态为itos,而Opcode为istore_1的机器指令片段执行。指令片段如下:
mov %eax,-0x8(%r14)
代码将栈顶的值%eax存储到本地变量表下标索引为1的位置处。通过%r14很容易定位到本地变量表的位置,执行完成后的栈状态如下图所示。
执行iconst_0和istore_1时,整个过程没有向表达式栈(上图中sp/rsp开始以下的部分就是表达式栈)中压入0,实际上如果没有栈顶缓存的优化,应该将0压入栈顶,然后弹出栈顶存储到局部变量表,但是有了栈顶缓存后,没有压栈操作,也就有弹栈操作,所以能极大的提高程序的执行效率。
return指令判断的逻辑比较多,主要是因为有些方法可能有synchronized关键字,所以会在方法栈中保存锁相关的信息,而在return返回时,退栈要释放锁。不过我们现在只看针对本实例要运行的部分代码,如下:
// 将JavaThread::do_not_unlock_if_synchronized属性存储到%dl中
0x00007fffe101b770: mov 0x2ad(%r15),%dl
// 重置JavaThread::do_not_unlock_if_synchronized属性值为false
0x00007fffe101b777: movb $0x0,0x2ad(%r15)
// 将Method*加载到%rbx中
0x00007fffe101b77f: mov -0x18(%rbp),%rbx
// 将Method::_access_flags加载到%ecx中
0x00007fffe101b783: mov 0x28(%rbx),%ecx
// 检查Method::flags是否包含JVM_ACC_SYNCHRONIZED
0x00007fffe101b786: test $0x20,%ecx
// 如果方法不是同步方法,跳转到----unlocked----
0x00007fffe101b78c: je 0x00007fffe101b970
main()方法为非同步方法,所以跳转到unlocked处执行,在unlocked处执行的逻辑中会执行一些释放锁的逻辑,对于我们本实例来说这不重要,我们直接看退栈的操作,如下:
// 将-0x8(%rbp)处保存的old stack pointer(saved rsp)取出来放到%rbx中
0x00007fffe101bac7: mov -0x8(%rbp),%rbx
// 移除栈帧
// leave指令相当于:
// mov %rbp, %rsp
// pop %rbp
0x00007fffe101bacb: leaveq
// 将返回地址弹出到%r13中
0x00007fffe101bacc: pop %r13
// 设置%rsp为调用者的栈顶值
0x00007fffe101bace: mov %rbx,%rsp
0x00007fffe101bad1: jmpq *%r13
这个汇编不难,这里不再继续介绍。退栈后的栈状态如下图所示。

这就完全回到了调用Java方法之前的栈状态,接下来如何退出如上栈帧并结束方法调用就是C++语言的事儿了。
第31篇-方法调用指令之invokevirtual
invokevirtual字节码指令的模板定义如下:
def(Bytecodes::_invokevirtual , ubcp|disp|clvm|____, vtos, vtos, invokevirtual , f2_byte );
生成函数为invokevirtual,传递的参数为f2_byte,也就是2,如果为2时,ConstantPoolCacheEntry::indices中取[b2,b1,original constant pool index]中的b2部分。调用的TemplateTable::invokevirtual()函数的实现如下:
void TemplateTable::invokevirtual(int byte_no) {
prepare_invoke(byte_no,
rbx, // method or vtable index
noreg, // unused itable index
rcx, // recv
rdx); // flags
// rbx: index
// rcx: receiver
// rdx: flags
invokevirtual_helper(rbx, rcx, rdx);
}
先调用prepare_invoke()函数,后调用invokevirtual_helper()函数来生成invokevirtual字节码指令对应的汇编代码(其实是生成机器指令,然后反编译对应的汇编代码,在后面我们就直接表述为汇编代码,读者要知道)。
1、prepare_invoke()函数
调用TemplateTable::prepare_invoke()函数生成的汇编代码比较多,所以我们分三部分进行查看。
第1部分:
0x00007fffe1021f90: mov %r13,-0x38(%rbp) // 将bcp保存到栈中
// invokevirtual x中取出x,也就是常量池索引存储到%edx,
// 其实这里已经是ConstantPoolCacheEntry的index,因为在类的连接
// 阶段会对方法中特定的一些字节码指令进行重写
0x00007fffe1021f94: movzwl 0x1(%r13),%edx
// 将ConstantPoolCache的首地址存储到%rcx
0x00007fffe1021f99: mov -0x28(%rbp),%rcx
// 左移2位,因为%edx中存储的是ConstantPoolCacheEntry索引,左移2位是因为
// ConstantPoolCacheEntry占用4个字
0x00007fffe1021f9d: shl $0x2,%edx
// 计算%rcx+%rdx*8+0x10,获取ConstantPoolCacheEntry[_indices,_f1,_f2,_flags]中的_indices
// 因为ConstantPoolCache的大小为0x16字节,%rcx+0x10定位
// 到第一个ConstantPoolCacheEntry的位置
// %rdx*8算出来的是相对于第一个ConstantPoolCacheEntry的字节偏移
0x00007fffe1021fa0: mov 0x10(%rcx,%rdx,8),%ebx
// 获取ConstantPoolCacheEntry中indices[b2,b1,constant pool index]中的b2
0x00007fffe1021fa4: shr $0x18,%ebx
// 取出indices中含有的b2,即bytecode存储到%ebx中
0x00007fffe1021fa7: and $0xff,%ebx
// 查看182的bytecode是否已经连接
0x00007fffe1021fad: cmp $0xb6,%ebx
// 如果连接就进行跳转,跳转到resolved
0x00007fffe1021fb3: je 0x00007fffe1022052
主要查看字节码是否已经连接,如果没有连接则需要连接,如果已经进行了连接,则跳转到resolved直接执行方法调用操作。
第2部分:
// 调用InterpreterRuntime::resolve_invoke()函数,因为指令还没有连接
// 将bytecode为182的指令移动到%ebx中
0x00007fffe1021fb9: mov $0xb6,%ebx
// 通过调用MacroAssembler::call_VM()函数来调用
// InterpreterRuntime::resolve_invoke(JavaThread* thread, Bytecodes::Code bytecode)函数
// 进行方法连接
0x00007fffe1021fbe: callq 0x00007fffe1021fc8
0x00007fffe1021fc3: jmpq 0x00007fffe1022046 // 跳转到----E----
// 准备第2个参数,也就是bytecode
0x00007fffe1021fc8: mov %rbx,%rsi
0x00007fffe1021fcb: lea 0x8(%rsp),%rax
0x00007fffe1021fd0: mov %r13,-0x38(%rbp)
0x00007fffe1021fd4: mov %r15,%rdi
0x00007fffe1021fd7: mov %rbp,0x200(%r15)
0x00007fffe1021fde: mov %rax,0x1f0(%r15)
0x00007fffe1021fe5: test $0xf,%esp
0x00007fffe1021feb: je 0x00007fffe1022003
0x00007fffe1021ff1: sub $0x8,%rsp
0x00007fffe1021ff5: callq 0x00007ffff66ac528
0x00007fffe1021ffa: add $0x8,%rsp
0x00007fffe1021ffe: jmpq 0x00007fffe1022008
0x00007fffe1022003: callq 0x00007ffff66ac528
0x00007fffe1022008: movabs $0x0,%r10
0x00007fffe1022012: mov %r10,0x1f0(%r15)
0x00007fffe1022019: movabs $0x0,%r10
0x00007fffe1022023: mov %r10,0x200(%r15)
0x00007fffe102202a: cmpq $0x0,0x8(%r15)
0x00007fffe1022032: je 0x00007fffe102203d
0x00007fffe1022038: jmpq 0x00007fffe1000420
0x00007fffe102203d: mov -0x38(%rbp),%r13
0x00007fffe1022041: mov -0x30(%rbp),%r14
0x00007fffe1022045: retq
// 结束MacroAssembler::call_VM()函数的调用
// **** E ****
// 将invokevirtual x中的x加载到%edx中,也就是ConstantPoolCacheEntry的索引
0x00007fffe1022046: movzwl 0x1(%r13),%edx
// 将ConstantPoolCache的首地址存储到%rcx中
0x00007fffe102204b: mov -0x28(%rbp),%rcx
// %edx中存储的是ConstantPoolCacheEntry index,转换为字偏移
0x00007fffe102204f: shl $0x2,%edx
方法连接的逻辑和之前介绍的字段的连接逻辑类似,都是完善ConstantPoolCache中对应的ConstantPoolCacheEntry添加相关信息。
调用InterpreterRuntime::resolve_invoke()函数进行方法连接,这个函数的实现比较多,我们在下一篇中详细介绍。连接完成后ConstantPoolCacheEntry中的各个项如下图所示。
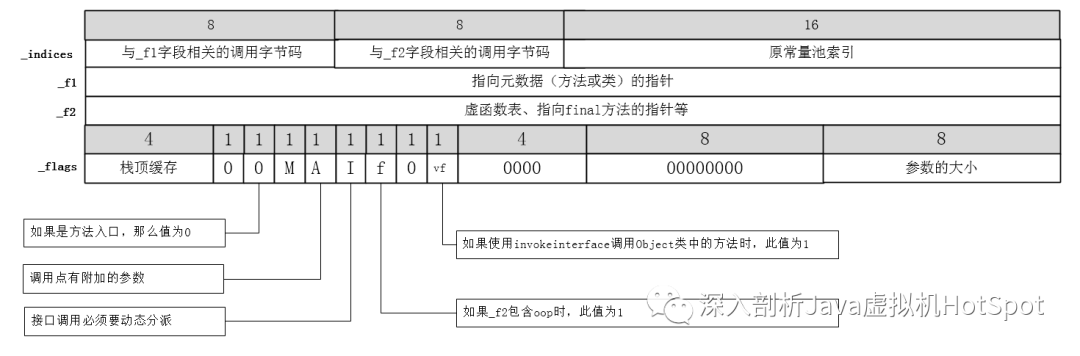
所以对于invokevirtual来说,通过vtable进行方法的分发,在ConstantPoolCacheEntry中,_f1字段没有使用,而对_f2字段来说,如果调用的是非final的virtual方法,则保存的是目标方法在vtable中的索引编号,如果是virtual final方法,则_f2字段直接指向目标方法的Method实例。
第3部分:
// **** resolved ****
// resolved的定义点,到这里说明invokevirtual字节码已经连接
// 获取ConstantPoolCacheEntry::_f2,这个字段只对virtual有意义
// 在计算时,因为ConstantPoolCacheEntry在ConstantPoolCache之后保存,
// 所以ConstantPoolCache为0x10,而
// _f2还要偏移0x10,这样总偏移就是0x20
// ConstantPoolCacheEntry::_f2存储到%rbx
0x00007fffe1022052: mov 0x20(%rcx,%rdx,8),%rbx
// ConstantPoolCacheEntry::_flags存储到%edx
0x00007fffe1022057: mov 0x28(%rcx,%rdx,8),%edx
// 将flags移动到ecx中
0x00007fffe102205b: mov %edx,%ecx
// 从flags中取出参数大小
0x00007fffe102205d: and $0xff,%ecx
// 获取到recv,%rcx中保存的是参数大小,最终计算参数所需要的大小为%rsp+%rcx*8-0x8,
// flags中的参数大小对实例方法来说,已经包括了recv的大小
// 如调用实例方法的第一个参数是this(recv)
0x00007fffe1022063: mov -0x8(%rsp,%rcx,8),%rcx // recv保存到%rcx
// 将flags存储到r13中
0x00007fffe1022068: mov %edx,%r13d
// 从flags中获取return type,也就是从_flags的高4位保存的TosState
0x00007fffe102206b: shr $0x1c,%edx
// 将TemplateInterpreter::invoke_return_entry地址存储到%r10
0x00007fffe102206e: movabs $0x7ffff73b6380,%r10
// %rdx保存的是return type,计算返回地址
// 因为TemplateInterpreter::invoke_return_entry是数组,
// 所以要找到对应return type的入口地址
0x00007fffe1022078: mov (%r10,%rdx,8),%rdx
// 向栈中压入返回地址
0x00007fffe102207c: push %rdx
// 还原ConstantPoolCacheEntry::_flags
0x00007fffe102207d: mov %r13d,%edx
// 还原bcp
0x00007fffe1022080: mov -0x38(%rbp),%r13
TemplateInterpreter::invoke_return_entry保存了一段例程的入口,这段例程在后面会详细介绍。
执行完如上的代码后,已经向相关的寄存器中存储了相关的值。相关的寄存器状态如下:
rbx: 存储的是ConstantPoolCacheEntry::_f2属性的值
rcx: 就是调用实例方法时的第一个参数this
rdx: 存储的是ConstantPoolCacheEntry::_flags属性的值
栈的状态如下图所示。
栈中压入了TemplateInterpreter::invoke_return_entry的返回地址。
2、invokevirtual_helper()函数
调用TemplateTable::invokevirtual_helper()函数生成的代码如下:
// flags存储到%eax
0x00007fffe1022084: mov %edx,%eax
// 测试调用的方法是否为final
0x00007fffe1022086: and $0x100000,%eax
// 如果不为final就直接跳转到----notFinal----
0x00007fffe102208c: je 0x00007fffe10220c0
// 通过(%rcx)来获取receiver的值,如果%rcx为空,则会引起OS异常
0x00007fffe1022092: cmp (%rcx),%rax
// 省略统计相关代码部分
// 设置调用者栈顶并保存
0x00007fffe10220b4: lea 0x8(%rsp),%r13
0x00007fffe10220b9: mov %r13,-0x10(%rbp)
// 跳转到Method::_from_interpretered_entry入口去执行
0x00007fffe10220bd: jmpq *0x58(%rbx)
对于final方法来说,其实没有动态分派,所以也不需要通过vtable进行目标查找。调用时的栈如下图所示。
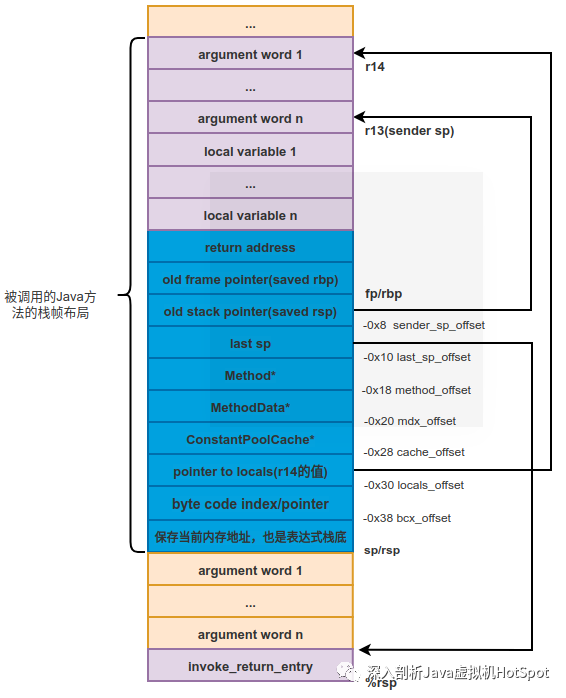
如下代码是通过vtable查找动态分派需要调用的方法入口 。
// **** notFinal ****
// invokevirtual指令调用的如果是非final方法,直接跳转到这里
// %rcx中存储的是receiver,用oop来表示。通过oop获取Klass
0x00007fffe10220c0: mov 0x8(%rcx),%eax
// 调用MacroAssembler::decode_klass__not_null()函数生成下面的一个汇编代码
0x00007fffe10220c3: shl $0x3,%rax // LogKlassAlignmentInBytes=0x03
// 省略统计相关代码部分
// %rax中存储的是recv_klass
// %rbx中存储的是vtable_index,
// 而0x1b8为InstanceKlass::vtable_start_offset()*wordSize+vtableEntry::method_offset_in_bytes(),
// 其实就是通过动态分派找到需要调用的Method*并存储到%rbx中
0x00007fffe1022169: mov 0x1b8(%rax,%rbx,8),%rbx
// 设置调用者的栈顶地址并保存
0x00007fffe1022171: lea 0x8(%rsp),%r13
0x00007fffe1022176: mov %r13,-0x10(%rbp)
// 跳转到Method::_from_interpreted_entry处执行
0x00007fffe102217a: jmpq *0x58(%rbx)
理解如上代码时需要知道vtable方法分派以及vtable在InstanceKlass中的布局,这在《深入剖析Java虚拟机:源码剖析与实例详解》一书中详细介绍过,这里不再介绍。
跳转到Method::_from_interpretered_entry保存的例程处执行,也就是以解释执行运行invokevirtual字节码指令调用的目标方法,关于Method::_from_interpretered_entry保存的例程的逻辑在第6篇、第7篇、第8篇中详细介绍过,这里不再介绍。
如上的汇编语句 mov 0x1b8(%rax,%rbx,8),%rbx 是通过调用调用lookup_virtual_method()函数生成的,此函数将vtable_entry_addr加载到%rbx中,实现如下:
void MacroAssembler::lookup_virtual_method(Register recv_klass,
RegisterOrConstant vtable_index,
Register method_result) {
const int base = InstanceKlass::vtable_start_offset() * wordSize;
Address vtable_entry_addr(
recv_klass,
vtable_index,
Address::times_ptr,
base + vtableEntry::method_offset_in_bytes());
movptr(method_result, vtable_entry_addr);
}
其中的vtable_index取的就是ConstantPoolCacheEntry::_f2属性的值。
最后还要说一下,如上生成的一些汇编代码中省略了统计相关的执行逻辑,这里统计相关的代码也是非常重要的,它会辅助进行编译,所以后面我们还会介绍这些统计相关的逻辑。
第32篇-解析interfacevirtual字节码指令
在前面介绍invokevirtual指令时,如果判断出ConstantPoolCacheEntry中的_indices字段的_f2属性的值为空,则认为调用的目标方法没有连接,也就是没有向ConstantPoolCacheEntry中保存调用方法的相关信息,需要调用InterpreterRuntime::resolve_invoke()函数进行方法连接,这个函数的实现比较多,我们分几部分查看:
InterpreterRuntime::resolve_invoke()函数第1部分:
Handle receiver(thread, NULL);
if (bytecode == Bytecodes::_invokevirtual || bytecode == Bytecodes::_invokeinterface) {
ResourceMark rm(thread);
// 调用method()函数从当前的栈帧中获取到需要执行的方法
Method* m1 = method(thread);
methodHandle m (thread, m1);
// 调用bci()函数从当前的栈帧中获取需要执行的方法的字节码索引
int i1 = bci(thread);
Bytecode_invoke call(m, i1);
// 当前需要执行的方法的签名
Symbol* signature = call.signature();
frame fm = thread->last_frame();
oop x = fm.interpreter_callee_receiver(signature);
receiver = Handle(thread,x);
}
当字节码为invokevirtual或invokeinterface这样的动态分派字节码时,执行如上的逻辑。获取到了receiver变量的值。接着看实现,如下:
InterpreterRuntime::resolve_invoke()函数第2部分:
CallInfo info;
constantPoolHandle pool(thread, method(thread)->constants());
{
JvmtiHideSingleStepping jhss(thread);
int cpcacheindex = get_index_u2_cpcache(thread, bytecode);
LinkResolver::resolve_invoke(info, receiver, pool,cpcacheindex, bytecode, CHECK);
...
}
// 如果已经向ConstantPoolCacheEntry中更新了调用的相关信息则直接返回
if (already_resolved(thread))
return;
根据存储在当前栈中的bcp来获取字节码指令的操作数,这个操作数通常就是常量池缓存项索引。然后调用LinkResolver::resolve_invoke()函数进行方法连接。 这个函数会间接调用LinkResolver::resolve_invokevirtual()函数,实现如下:
void LinkResolver::resolve_invokevirtual(
CallInfo& result,
Handle recv,
constantPoolHandle pool,
int index,
TRAPS
){
KlassHandle resolved_klass;
Symbol* method_name = NULL;
Symbol* method_signature = NULL;
KlassHandle current_klass;
resolve_pool(resolved_klass, method_name, method_signature, current_klass, pool, index, CHECK);
KlassHandle recvrKlass(THREAD, recv.is_null() ? (Klass*)NULL : recv->klass());
resolve_virtual_call(result, recv, recvrKlass, resolved_klass, method_name, method_signature, current_klass, true, true, CHECK);
}
其中会调用resolve_pool()和resolve_vritual_call()函数分别连接常量池和方法调用指令。调用会涉及到的相关函数大概如下图所示。
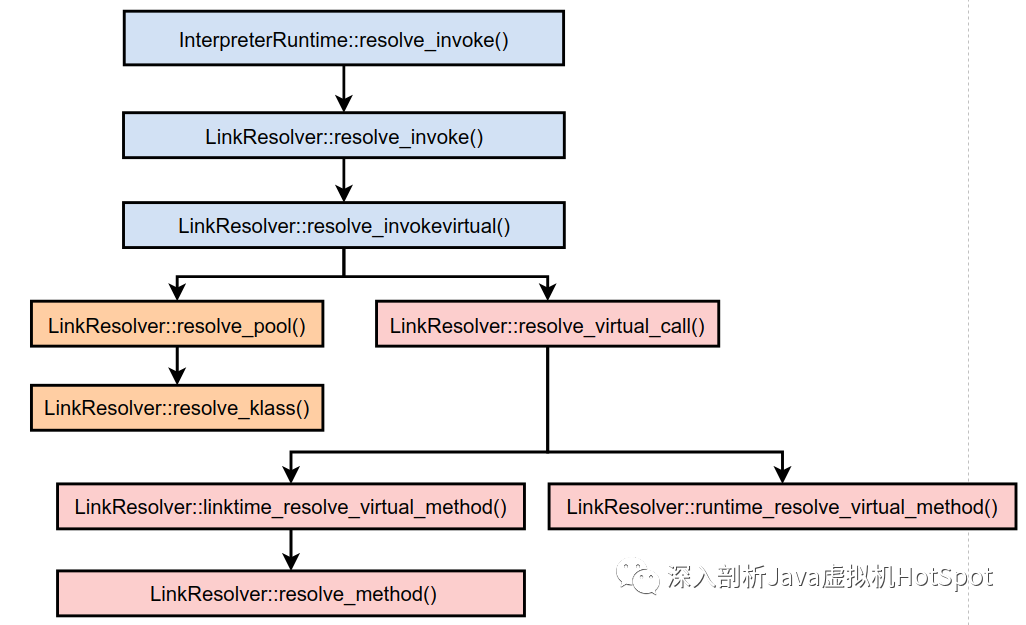
下面介绍resolve_pool()和resolve_virtual_call()函数及其调用的相关函数的实现。
01 resolve_pool()函数
调用的resolve_pool()函数会调用一些函数,如下图所示。
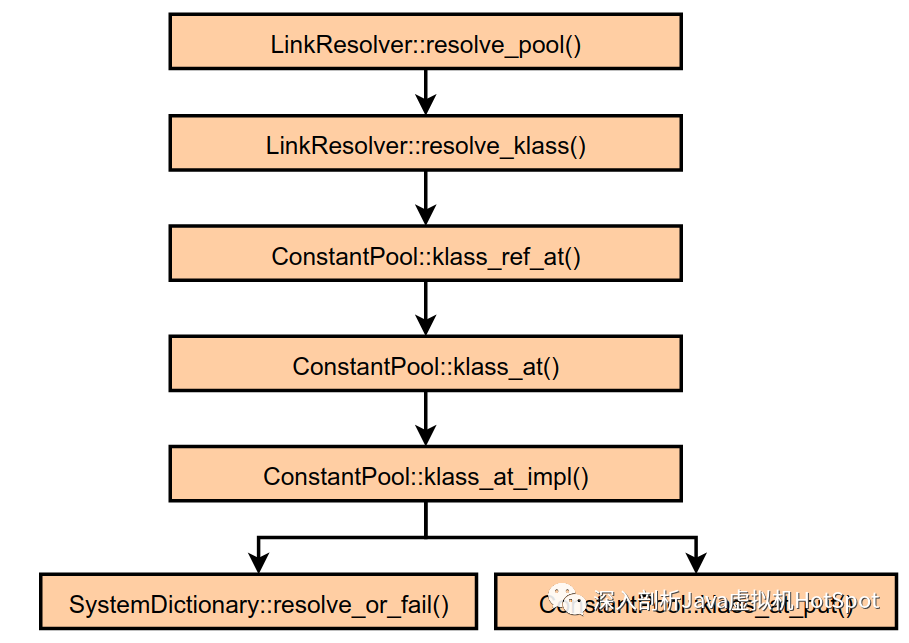
每次调用LinkResolver::resolve_pool()函数时不一定会按如上的函数调用链执行,但是当类还没有解析时,通常会调用SystemDictionary::resolve_or_fail()函数进行解析,最终会获取到指向Klass实例的指针,最终将这个类更新到常量池中。
resolve_pool()函数的实现如下:
void LinkResolver::resolve_pool(
KlassHandle& resolved_klass,
Symbol*& method_name,
Symbol*& method_signature,
KlassHandle& current_klass,
constantPoolHandle pool,
int index,
TRAPS
) {
resolve_klass(resolved_klass, pool, index, CHECK);
method_name = pool->name_ref_at(index);
method_signature = pool->signature_ref_at(index);
current_klass = KlassHandle(THREAD, pool->pool_holder());
}
其中的index为常量池缓存项的索引。resolved_klass参数表示需要进行解析的类(解析是在类生成周期中连接相关的部分,所以我们之前有时候会称为连接,其实具体来说是解析的意思),而current_klass为当前拥有常量池的类,由于传递参数时是C++的引用传递,所以同值会直接改变变量的值,调用者中的值也会随着改变。
调用resolve_klass()函数进行类解析,一般来说,类解析会在解释常量池项时就会进行,这在《深入剖析Java虚拟机:源码剖析与实例详解(基础卷)》一书中介绍过,这里需要再说一下。
调用的resolve_klass()函数及相关函数的实现如下:
void LinkResolver::resolve_klass(
KlassHandle& result,
constantPoolHandle pool,
int index,
TRAPS
) {
Klass* result_oop = pool->klass_ref_at(index, CHECK);
// 通过引用进行传递
result = KlassHandle(THREAD, result_oop);
}
Klass* ConstantPool::klass_ref_at(int which, TRAPS) {
int x = klass_ref_index_at(which);
return klass_at(x, CHECK_NULL);
}
int klass_ref_index_at(int which) {
return impl_klass_ref_index_at(which, false);
}
调用的impl_klass_ref_index_at()函数的实现如下:
int ConstantPool::impl_klass_ref_index_at(int which, bool uncached) {
int i = which;
if (!uncached && cache() != NULL) {
// 从which对应的ConstantPoolCacheEntry项中获取ConstantPoolIndex
i = remap_instruction_operand_from_cache(which);
}
assert(tag_at(i).is_field_or_method(), "Corrupted constant pool");
// 获取
jint ref_index = *int_at_addr(i);
// 获取低16位,那就是class_index
return extract_low_short_from_int(ref_index);
}
根据断言可知,在原常量池索引的i处的项肯定为JVM_CONSTANT_Fieldref、JVM_CONSTANT_Methodref或JVM_CONSTANT_InterfaceMethodref,这几项的格式如下:
CONSTANT_Fieldref_info{
u1 tag;
u2 class_index;
u2 name_and_type_index; // 必须是字段描述符
}
CONSTANT_InterfaceMethodref_info{
u1 tag;
u2 class_index; // 必须是接口
u2 name_and_type_index; // 必须是方法描述符
}
CONSTANT_Methodref_info{
u1 tag;
u2 class_index; // 必须是类
u2 name_and_type_index; // 必须是方法描述符
}
3项的格式都一样,其中的class_index索引处的项必须为CONSTANT_Class_info结构,表示一个类或接口,当前类字段或方法是这个类或接口的成员。name_and_type_index索引处必须为CONSTANT_NameAndType_info项。
通过调用int_at_addr()函数和extract_low_short_from_int()函数获取class_index的索引值,如果了解了常量池内存布局,这里函数的实现理解起来会很简单,这里不再介绍。
在klass_ref_at()函数中调用klass_at()函数,此函数的实现如下:
Klass* klass_at(int which, TRAPS) {
constantPoolHandle h_this(THREAD, this);
return klass_at_impl(h_this, which, CHECK_NULL);
}
调用的klass_at_impl()函数的实现如下:
Klass* ConstantPool::klass_at_impl(
constantPoolHandle this_oop,
int which,
TRAPS
) {
CPSlot entry = this_oop->slot_at(which);
if (entry.is_resolved()) { // 已经进行了连接
return entry.get_klass();
}
bool do_resolve = false;
bool in_error = false;
Handle mirror_handle;
Symbol* name = NULL;
Handle loader;
{
MonitorLockerEx ml(this_oop->lock());
if (this_oop->tag_at(which).is_unresolved_klass()) {
if (this_oop->tag_at(which).is_unresolved_klass_in_error()) {
in_error = true;
} else {
do_resolve = true;
name = this_oop->unresolved_klass_at(which);
loader = Handle(THREAD, this_oop->pool_holder()->class_loader());
}
}
} // unlocking constantPool
// 省略当in_error变量的值为true时的处理逻辑
if (do_resolve) {
oop protection_domain = this_oop->pool_holder()->protection_domain();
Handle h_prot (THREAD, protection_domain);
Klass* k_oop = SystemDictionary::resolve_or_fail(name, loader, h_prot, true, THREAD);
KlassHandle k;
if (!HAS_PENDING_EXCEPTION) {
k = KlassHandle(THREAD, k_oop);
mirror_handle = Handle(THREAD, k_oop->java_mirror());
}
if (HAS_PENDING_EXCEPTION) {
...
return 0;
}
if (TraceClassResolution && !k()->oop_is_array()) {
...
} else {
MonitorLockerEx ml(this_oop->lock());
do_resolve = this_oop->tag_at(which).is_unresolved_klass();
if (do_resolve) {
ClassLoaderData* this_key = this_oop->pool_holder()->class_loader_data();
this_key->record_dependency(k(), CHECK_NULL); // Can throw OOM
this_oop->klass_at_put(which, k()); // 注意这里会更新常量池中存储的内容,这样就表示类已经解析完成,下次就不需要重复解析了
}
}
}
entry = this_oop->resolved_klass_at(which);
assert(entry.is_resolved() && entry.get_klass()->is_klass(), "must be resolved at this point");
return entry.get_klass();
}
函数首先调用slot_at()函数获取常量池中一个slot中存储的值,然后通过CPSlot来表示这个slot,这个slot中可能存储的值有2个,分别为指向Symbol实例(因为类名用CONSTANT_Utf8_info项表示,在虚拟机内部统一使用Symbol对象表示字符串)的指针和指向Klass实例的指针,如果类已经解释,那么指针表示的地址的最后一位为0,如果还没有被解析,那么地址的最后一位为1。
当没有解析时,需要调用SystemDictionary::resolve_or_fail()函数获取类Klass的实例,然后更新常量池中的信息,这样下次就不用重复解析类了。最后返回指向Klass实例的指针即可。
继续回到LinkResolver::resolve_pool()函数看接下来的执行逻辑,也就是会获取JVM_CONSTANT_Fieldref、JVM_CONSTANT_Methodref或JVM_CONSTANT_InterfaceMethodref项中的name_and_type_index,其指向的是CONSTANT_NameAndType_info项,格式如下:
CONSTANT_NameAndType_info{
u1 tag;
u2 name_index;
u2 descriptor index;
}
获取逻辑就是先根据常量池缓存项的索引找到原常量池项的索引,然后查找到CONSTANT_NameAndType_info后,获取到方法名称和签名的索引,进而获取到被调用的目标方法的名称和签名。这些信息将在接下来调用的resolve_virtual_call()函数中使用。
02 resolve_virtual_call()函数
resolve_virtual_call()函数会调用的相关函数如下图所示。
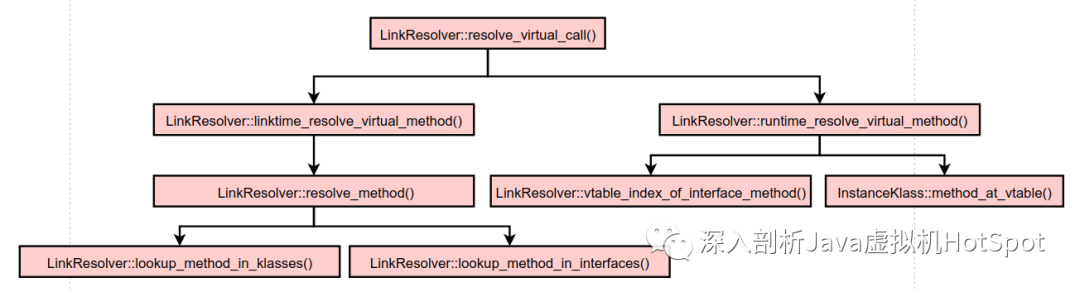
LinkResolver::resolve_virtual_call()的实现如下:
void LinkResolver::resolve_virtual_call(
CallInfo& result,
Handle recv,
KlassHandle receiver_klass,
KlassHandle resolved_klass,
Symbol* method_name,
Symbol* method_signature,
KlassHandle current_klass,
bool check_access,
bool check_null_and_abstract,
TRAPS
) {
methodHandle resolved_method;
linktime_resolve_virtual_method(resolved_method, resolved_klass, method_name, method_signature, current_klass, check_access, CHECK);
runtime_resolve_virtual_method(result, resolved_method, resolved_klass, recv, receiver_klass, check_null_and_abstract, CHECK);
}
首先调用LinkResolver::linktime_resolve_virtual_method()函数,这个函数会调用如下函数:
void LinkResolver::resolve_method(
methodHandle& resolved_method,
KlassHandle resolved_klass,
Symbol* method_name,
Symbol* method_signature,
KlassHandle current_klass,
bool check_access,
bool require_methodref,
TRAPS
) {
// 从解析的类和其父类中查找方法
lookup_method_in_klasses(resolved_method, resolved_klass, method_name, method_signature, true, false, CHECK);
// 没有在解析类的继承体系中查找到方法
if (resolved_method.is_null()) {
// 从解析类实现的所有接口(包括间接实现的接口)中查找方法
lookup_method_in_interfaces(resolved_method, resolved_klass, method_name, method_signature, CHECK);
// ...
if (resolved_method.is_null()) {
// 没有找到对应的方法
...
}
}
// ...
}
如上函数中最主要的就是根据method_name和method_signature从resolved_klass类中找到合适的方法,如果找到就赋值给resolved_method变量。
调用lookup_method_in_klasses()、lookup_method_in_interfaces()等函数进行方法的查找,这里暂时不介绍。
下面接着看runtime_resolve_virtual_method()函数,这个函数的实现如下:
void LinkResolver::runtime_resolve_virtual_method(
CallInfo& result,
methodHandle resolved_method,
KlassHandle resolved_klass,
Handle recv,
KlassHandle recv_klass,
bool check_null_and_abstract,
TRAPS
) {
int vtable_index = Method::invalid_vtable_index;
methodHandle selected_method;
// 当方法定义在接口中时,表示是miranda方法
if (resolved_method->method_holder()->is_interface()) {
vtable_index = vtable_index_of_interface_method(resolved_klass,resolved_method);
InstanceKlass* inst = InstanceKlass::cast(recv_klass());
selected_method = methodHandle(THREAD, inst->method_at_vtable(vtable_index));
} else {
// 如果走如下的代码逻辑,则表示resolved_method不是miranda方法,需要动态分派且肯定有正确的vtable索引
vtable_index = resolved_method->vtable_index();
// 有些方法虽然看起来需要动态分派,但是如果这个方法有final关键字时,可进行静态绑定,所以直接调用即可
// final方法其实不会放到vtable中,除非final方法覆写了父类中的方法
if (vtable_index == Method::nonvirtual_vtable_index) {
selected_method = resolved_method;
} else {
// 根据vtable和vtable_index以及inst进行方法的动态分派
InstanceKlass* inst = (InstanceKlass*)recv_klass();
selected_method = methodHandle(THREAD, inst->method_at_vtable(vtable_index));
}
}
// setup result resolve的类型为CallInfo,为CallInfo设置了连接后的相关信息
result.set_virtual(resolved_klass, recv_klass, resolved_method, selected_method, vtable_index, CHECK);
}
当为miranda方法时,调用 LinkResolver::vtable_index_of_interface_method()函数查找;当为final方法时,因为final方法不可能被子类覆写,所以resolved_method就是目标调用方法;除去前面的2种情况后,剩下的方法就需要结合vtable和vtable_index进行动态分派了。
如上函数将查找到调用时需要的所有信息并存储到CallInfo类型的result变量中。
在获取到调用时的所有信息并存储到CallInfo中后,就可以根据info中相关信息填充ConstantPoolCacheEntry。我们回看InterpreterRuntime::resolve_invoke()函数的执行逻辑。
InterpreterRuntime::resolve_invoke()函数第2部分:
switch (info.call_kind()) {
case CallInfo::direct_call: // 直接调用
cache_entry(thread)->set_direct_call(
bytecode,
info.resolved_method());
break;
case CallInfo::vtable_call: // vtable分派
cache_entry(thread)->set_vtable_call(
bytecode,
info.resolved_method(),
info.vtable_index());
break;
case CallInfo::itable_call: // itable分派
cache_entry(thread)->set_itable_call(
bytecode,
info.resolved_method(),
info.itable_index());
break;
default: ShouldNotReachHere();
}
无论直接调用,还是vtable和itable动态分派,都会在方法解析完成后将相关的信息存储到常量池缓存项中。调用cache_entry()函数获取对应的ConstantPoolCacheEntry项,然后调用set_vtable_call()函数,此函数会调用如下函数更新ConstantPoolCacheEntry项中的信息,如下:
void ConstantPoolCacheEntry::set_direct_or_vtable_call(
Bytecodes::Code invoke_code,
methodHandle method,
int vtable_index
) {
bool is_vtable_call = (vtable_index >= 0); // FIXME: split this method on this boolean
int byte_no = -1;
bool change_to_virtual = false;
switch (invoke_code) {
case Bytecodes::_invokeinterface:
change_to_virtual = true;
// ...
// 可以看到,通过_invokevirtual指令时,并不一定都是动态分发,也有可能是静态绑定
case Bytecodes::_invokevirtual: // 当前已经在ConstantPoolCacheEntry类中了
{
if (!is_vtable_call) {
assert(method->can_be_statically_bound(), "");
// set_f2_as_vfinal_method checks if is_vfinal flag is true.
set_method_flags(as_TosState(method->result_type()),
( 1 << is_vfinal_shift) |
((method->is_final_method() ? 1 : 0) << is_final_shift) |
((change_to_virtual ? 1 : 0) << is_forced_virtual_shift), // 在接口中调用Object中定义的方法
method()->size_of_parameters());
set_f2_as_vfinal_method(method());
} else {
// 执行这里的逻辑时,表示方法是非静态绑定的非final方法,需要动态分派,则vtable_index的值肯定大于等于0
set_method_flags(as_TosState(method->result_type()),
((change_to_virtual ? 1 : 0) << is_forced_virtual_shift),
method()->size_of_parameters());
// 对于动态分发来说,ConstantPoolCacheEntry::_f2中保存的是vtable_index
set_f2(vtable_index);
}
byte_no = 2;
break;
}
// ...
}
if (byte_no == 1) {
// invoke_code为非invokevirtual和非invokeinterface字节码指令
set_bytecode_1(invoke_code);
} else if (byte_no == 2) {
if (change_to_virtual) {
if (method->is_public())
set_bytecode_1(invoke_code);
} else {
assert(invoke_code == Bytecodes::_invokevirtual, "");
}
// set up for invokevirtual, even if linking for invokeinterface also:
set_bytecode_2(Bytecodes::_invokevirtual);
}
}
连接完成后ConstantPoolCacheEntry中的各个项如下图所示。
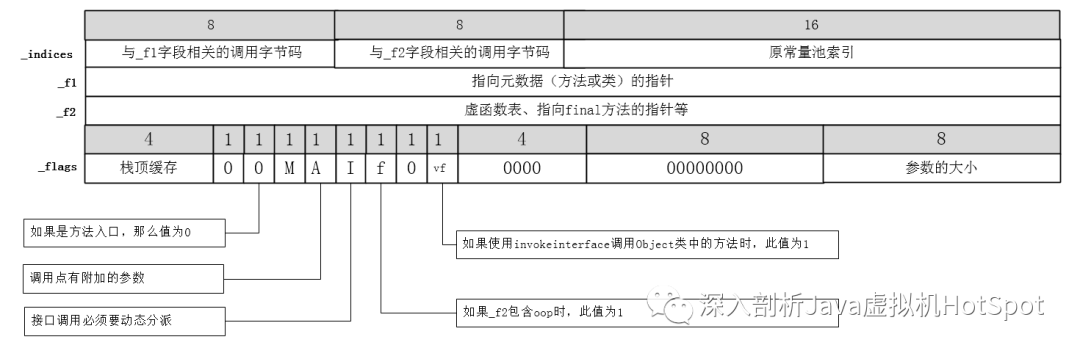
所以对于invokevirtual来说,通过vtable进行方法的分发,在ConstantPoolCacheEntry中,_f1字段没有使用,而对_f2字段来说,如果调用的是非final的virtual方法,则保存的是目标方法在vtable中的索引编号,如果是virtual final方法,则_f2字段直接指向目标方法的Method实例。
第33篇-方法调用指令之invokeinterface
invokevirtual字节码指令的模板定义如下:
def(Bytecodes::_invokeinterface , ubcp|disp|clvm|____, vtos, vtos, invokeinterface , f1_byte );
可以看到指令的生成函数为TemplateTable::invokeinterface(),在这个函数中首先会调用TemplateTable::prepare_invoke()函数,TemplateTable::prepare_invoke()函数生成的汇编代码如下:
第1部分
0x00007fffe1022610: mov %r13,-0x38(%rbp)
0x00007fffe1022614: movzwl 0x1(%r13),%edx
0x00007fffe1022619: mov -0x28(%rbp),%rcx
0x00007fffe102261d: shl $0x2,%edx
// 获取ConstantPoolCacheEntry[_indices,_f1,_f2,_flags]中的_indices
0x00007fffe1022620: mov 0x10(%rcx,%rdx,8),%ebx
// 获取ConstantPoolCacheEntry中indices[b2,b1,constant pool index]中的b1
// 如果已经连接,那这个b1应该等于185,也就是invokeinterface指令的操作码
0x00007fffe1022624: shr $0x10,%ebx
0x00007fffe1022627: and $0xff,%ebx
0x00007fffe102262d: cmp $0xb9,%ebx
// 如果invokeinterface已经连接就跳转到----resolved----
0x00007fffe1022633: je 0x00007fffe10226d2
汇编代码的判断逻辑与invokevirutal一致,这里不在过多解释。
第2部分
由于方法还没有解析,所以需要设置ConstantPoolCacheEntry中的信息,这样再一次调用时就不需要重新找调用相关的信息了。生成的汇编如下:
// 执行如下汇编代码时,表示invokeinterface指令还没有连接,也就是ConstantPoolCacheEntry中
// 还没有保存调用相关的信息
// 通过调用call_VM()函数生成如下汇编,通过这些汇编
// 调用InterpreterRuntime::resolve_invoke()函数
// 将bytecode存储到%ebx中
0x00007fffe1022639: mov $0xb9,%ebx
// 通过MacroAssembler::call_VM()来调用InterpreterRuntime::resolve_invoke()
0x00007fffe102263e: callq 0x00007fffe1022648
0x00007fffe1022643: jmpq 0x00007fffe10226c6
0x00007fffe1022648: mov %rbx,%rsi
0x00007fffe102264b: lea 0x8(%rsp),%rax
0x00007fffe1022650: mov %r13,-0x38(%rbp)
0x00007fffe1022654: mov %r15,%rdi
0x00007fffe1022657: mov %rbp,0x200(%r15)
0x00007fffe102265e: mov %rax,0x1f0(%r15)
0x00007fffe1022665: test $0xf,%esp
0x00007fffe102266b: je 0x00007fffe1022683
0x00007fffe1022671: sub $0x8,%rsp
0x00007fffe1022675: callq 0x00007ffff66ae13a
0x00007fffe102267a: add $0x8,%rsp
0x00007fffe102267e: jmpq 0x00007fffe1022688
0x00007fffe1022683: callq 0x00007ffff66ae13a
0x00007fffe1022688: movabs $0x0,%r10
0x00007fffe1022692: mov %r10,0x1f0(%r15)
0x00007fffe1022699: movabs $0x0,%r10
0x00007fffe10226a3: mov %r10,0x200(%r15)
0x00007fffe10226aa: cmpq $0x0,0x8(%r15)
0x00007fffe10226b2: je 0x00007fffe10226bd
0x00007fffe10226b8: jmpq 0x00007fffe1000420
0x00007fffe10226bd: mov -0x38(%rbp),%r13
0x00007fffe10226c1: mov -0x30(%rbp),%r14
0x00007fffe10226c5: retq
// 结束MacroAssembler::call_VM()函数
// 将invokeinterface x中的x加载到%edx中
0x00007fffe10226c6: movzwl 0x1(%r13),%edx
// 将ConstantPoolCache的首地址存储到%rcx中
0x00007fffe10226cb: mov -0x28(%rbp),%rcx
// %edx中存储的是ConstantPoolCacheEntry项的索引,转换为字节
// 偏移,因为一个ConstantPoolCacheEntry项占用4个字
0x00007fffe10226cf: shl $0x2,%edx
与invokevirtual的实现类似,这里仍然在方法没有解释时调用InterpreterRuntime::resolve_invoke()函数进行方法解析,后面我们也详细介绍一下InterpreterRuntime::resolve_invoke()函数的实现。
在调用完resolve_invoke()函数后,会将调用相信的信息存储到CallInfo实例info中。所以在调用的InterpreterRuntime::resolve_invoke()函数的最后会有如下的实现:
switch (info.call_kind()) {
case CallInfo::direct_call: // 直接调用
cache_entry(thread)->set_direct_call(
bytecode,
info.resolved_method());
break;
case CallInfo::vtable_call: // vtable分派
cache_entry(thread)->set_vtable_call(
bytecode,
info.resolved_method(),
info.vtable_index());
break;
case CallInfo::itable_call: // itable分派
cache_entry(thread)->set_itable_call(
bytecode,
info.resolved_method(),
info.itable_index());
break;
default: ShouldNotReachHere();
}
之前已经介绍过vtable分派,现在看一下itable分派。
当为itable分派时,会调用set_itable_call()函数设置ConstantPoolCacheEntry中的相关信息,这个函数的实现如下:
void ConstantPoolCacheEntry::set_itable_call(
Bytecodes::Code invoke_code,
methodHandle method,
int index
) {
InstanceKlass* interf = method->method_holder();
// interf一定是接口,method一定是非final方法
set_f1(interf); // 对于itable,则_f1为InstanceKlass
set_f2(index);
set_method_flags(as_TosState(method->result_type()),
0, // no option bits
method()->size_of_parameters());
set_bytecode_1(Bytecodes::_invokeinterface);
}
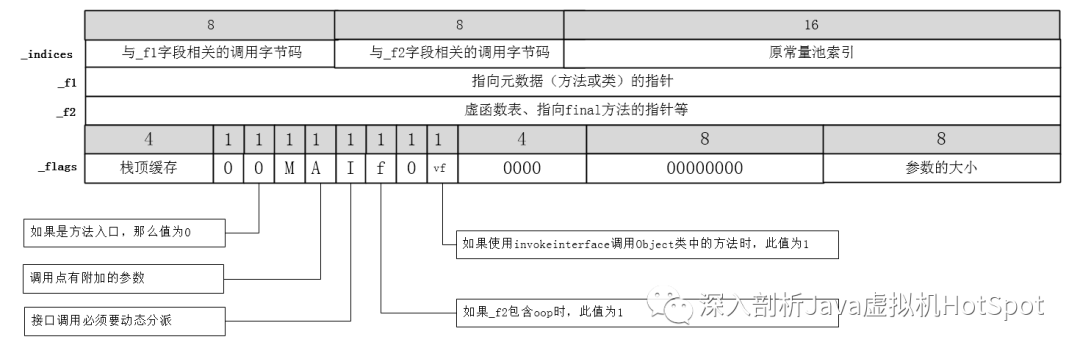
ConstantPoolCacheEntry中存储的信息为:
-
bytecode存储到了_f2字段上,这样当这个字段有值时表示已经对此方法完成了解析;
-
_f1字段存储声明方法的接口类,也就是_f1是指向表示接口的Klass实例的指针;
-
_f2表示_f1接口类对应的方法表中的索引,如果是final方法,则存储指向Method实例的指针。
解析完成后ConstantPoolCacheEntry中的各个项如下图所示。
第3部分
如果invokeinterface字节码指令已经解析,则直接跳转到resolved执行,否则调用resolve_invoke进行解析,解析完成后也会接着执行resolved处的逻辑,如下:
// **** resolved ****
// resolved的定义点,到这里说明invokeinterface字节码已经连接
// 执行完如上汇编后寄存器的值如下:
// %edx:ConstantPoolCacheEntry index
// %rcx:ConstantPoolCache
// 获取到ConstantPoolCacheEntry::_f1
// 在计算时,因为ConstantPoolCacheEntry在ConstantPoolCache
// 之后保存,所以ConstantPoolCache为0x10,而
// _f1还要偏移0x8,这样总偏移就是0x18
0x00007fffe10226d2: mov 0x18(%rcx,%rdx,8),%rax
// 获取ConstantPoolCacheEntry::_f2属性
0x00007fffe10226d7: mov 0x20(%rcx,%rdx,8),%rbx
// 获取ConstantPoolCacheEntry::_flags属性
0x00007fffe10226dc: mov 0x28(%rcx,%rdx,8),%edx
// 执行如上汇编后寄存器的值如下:
// %rax:ConstantPoolCacheEntry::_f1
// %rbx:ConstantPoolCacheEntry::_f2
// %edx:ConstantPoolCacheEntry::_flags
// 将flags移动到ecx中
0x00007fffe10226e0: mov %edx,%ecx
// 从ConstantPoolCacheEntry::_flags中获取参数大小
0x00007fffe10226e2: and $0xff,%ecx
// 让%rcx指向recv
0x00007fffe10226e8: mov -0x8(%rsp,%rcx,8),%rcx
// 暂时用%r13d保存ConstantPoolCacheEntry::_flags属性
0x00007fffe10226ed: mov %edx,%r13d
// 从_flags的高4位保存的TosState中获取方法返回类型
0x00007fffe10226f0: shr $0x1c,%edx
// 将TemplateInterpreter::invoke_return_entry地址存储到%r10
0x00007fffe10226f3: movabs $0x7ffff73b63e0,%r10
// %rdx保存的是方法返回类型,计算返回地址
// 因为TemplateInterpreter::invoke_return_entry是数组,
// 所以要找到对应return type的入口地址
0x00007fffe10226fd: mov (%r10,%rdx,8),%rdx
// 获取结果处理函数TemplateInterpreter::invoke_return_entry的地址并压入栈中
0x00007fffe1022701: push %rdx
// 恢复ConstantPoolCacheEntry::_flags中%edx
0x00007fffe1022702: mov %r13d,%edx
// 还原bcp
0x00007fffe1022705: mov -0x38(%rbp),%r13
在TemplateTable::invokeinterface()函数中首先会调用prepare_invoke()函数,上面的汇编就是由这个函数生成的。调用完后各个寄存器的值如下:
rax: interface klass (from f1)
rbx: itable index (from f2)
rcx: receiver
rdx: flags
然后接着执行TemplateTable::invokeinterface()函数生成的汇编片段,如下:
第4部分
// 将ConstantPoolCacheEntry::_flags的值存储到%r14d中
0x00007fffe1022709: mov %edx,%r14d
// 检测一下_flags中是否含有is_forced_virtual_shift标识,如果有,
// 表示调用的是Object类中的方法,需要通过vtable进行动态分派
0x00007fffe102270c: and $0x800000,%r14d
0x00007fffe1022713: je 0x00007fffe1022812 // 跳转到----notMethod----
// ConstantPoolCacheEntry::_flags存储到%eax
0x00007fffe1022719: mov %edx,%eax
// 测试调用的方法是否为final
0x00007fffe102271b: and $0x100000,%eax
0x00007fffe1022721: je 0x00007fffe1022755 // 如果为非final方法,则跳转到----notFinal----
// 下面汇编代码是对final方法的处理
// 对于final方法来说,rbx中存储的是Method*,也就是ConstantPoolCacheEntry::_f2指向Method*
// 跳转到Method::from_interpreted处执行即可
0x00007fffe1022727: cmp (%rcx),%rax
// ... 省略统计相关的代码
// 设置调用者栈顶并存储
0x00007fffe102274e: mov %r13,-0x10(%rbp)
// 跳转到Method::_from_interpreted_entry
0x00007fffe1022752: jmpq *0x58(%rbx) // 调用final方法
// **** notFinal ****
// 调用load_klass()函数生成如下2句汇编
// 查看recv这个oop对应的Klass,存储到%eax中
0x00007fffe1022755: mov 0x8(%rcx),%eax
// 调用decode_klass_not_null()函数生成的汇编
0x00007fffe1022758: shl $0x3,%rax
// 省略统计相关的代码
// 调用lookup_virtual_method()函数生成如下这一句汇编
0x00007fffe10227fe: mov 0x1b8(%rax,%rbx,8),%rbx
// 设置调用者栈顶并存储
0x00007fffe1022806: lea 0x8(%rsp),%r13
0x00007fffe102280b: mov %r13,-0x10(%rbp)
// 跳转到Method::_from_interpreted_entry
0x00007fffe102280f: jmpq *0x58(%rbx)
如上汇编包含了对final和非final方法的分派逻辑。对于final方法来说,由于ConstantPoolCacheEntry::_f2中存储的就是指向被调用的Method实例,所以非常简单;对于非final方法来说,需要通过vtable实现动态分派。分派的关键一个汇编语句如下:
mov 0x1b8(%rax,%rbx,8),%rbx
需要提示的是,只有少量的方法可能才会走这个逻辑进行vtable的动态分派,如调用Object类中的方法。
如果跳转到notMethod后,那就需要通过itable进行方法的动态分派了,我们看一下这部分的实现逻辑:
第5部分
// **** notMethod ****
// 让%r14指向本地变量表
0x00007fffe1022812: mov -0x30(%rbp),%r14
// %rcx中存储的是receiver,%edx中保存的是Klass
0x00007fffe1022816: mov 0x8(%rcx),%edx
// LogKlassAlignmentInBytes=0x03,进行对齐处理
0x00007fffe1022819: shl $0x3,%rdx
// 如下代码是调用如下函数生成的:
__ lookup_interface_method(rdx, // inputs: rec. class
rax, // inputs: interface
rbx, // inputs: itable index
rbx, // outputs: method
r13, // outputs: scan temp. reg
no_such_interface);
// 获取vtable的起始地址
// %rdx中存储的是recv.Klass,获取Klass中
// vtable_length属性的值
0x00007fffe10228c1: mov 0x118(%rdx),%r13d
// %rdx:recv.Klass,%r13为vtable_length,
// 最后r13指向第一个itableOffsetEntry
// 加一个常量0x1b8是因为vtable之前是InstanceKlass
0x00007fffe10228c8: lea 0x1b8(%rdx,%r13,8),%r13
0x00007fffe10228d0: lea (%rdx,%rbx,8),%rdx
// 获取itableOffsetEntry::_interface并与%rax比较,%rax中存储的是要查找的接口
0x00007fffe10228d4: mov 0x0(%r13),%rbx
0x00007fffe10228d8: cmp %rbx,%rax
// 如果相等,则直接跳转到---- found_method ----
0x00007fffe10228db: je 0x00007fffe10228f3
// **** search ****
// 检测%rbx中的值是否为NULL,如果为NULL,
// 那就说明receiver没有实现要查询的接口
0x00007fffe10228dd: test %rbx,%rbx
// 跳转到---- L_no_such_interface ----
0x00007fffe10228e0: je 0x00007fffe1022a8c
0x00007fffe10228e6: add $0x10,%r13
0x00007fffe10228ea: mov 0x0(%r13),%rbx
0x00007fffe10228ee: cmp %rbx,%rax
// 如果还是没有在itableOffsetEntry中找到接口类,
// 则跳转到search继续进行查找
0x00007fffe10228f1: jne 0x00007fffe10228dd // 跳转到---- search ----
// **** found_method ****
// 已经找到匹配接口的itableOffsetEntry,获取
// itableOffsetEntry的offset属性并存储到%r13d中
0x00007fffe10228f3: mov 0x8(%r13),%r13d
// 通过recv_klass进行偏移后找到此接口下声明
// 的一系列方法的开始位置
0x00007fffe10228f7: mov (%rdx,%r13,1),%rbx
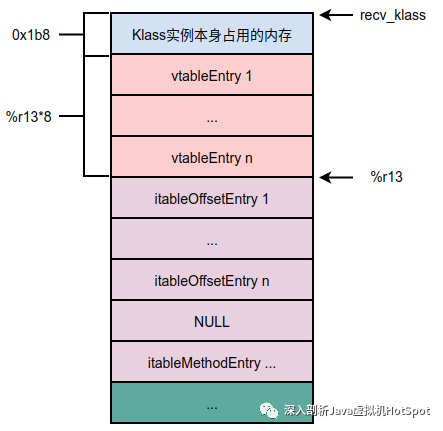
我们需要重点关注itable的分派逻辑,首先生成了如下汇编:
mov 0x118(%rdx),%r13d
%rdx中存储的是recv.Klass,获取Klass中vtable_length属性的值,有了这个值,我们就可以计算出vtable的大小,从而计算出itable的开始地址。
接着执行了如下汇编:
lea 0x1b8(%rdx,%r13,8),%r13
其中的0x1b8表示的是recv.Klass首地址到vtable的距离,这样最终的%r13指向的是itable的首地址。如下图所示。
后面我们就可以开始循环从itableOffsetEntry中查找匹配的接口了, 如果找到则跳转到found_method,在found_method中,要找到对应的itableOffsetEntry的offset,这个offset指明了接口中定义的方法的存储位置相对于Klass的偏移量,也就是找到接口对应的第一个itableMethodEntry,因为%rbx中已经存储了itable的索引,所以根据这个索引直接定位对应的itableMethodEntry即可,我们现在合起来看如下的2个汇编:
lea (%rdx,%rbx,8),%rdx
...
mov (%rdx,%r13,1),%rbx
当执行到如上的第2个汇编时,%r13存储的是相对于Klass实例的偏移,而%rdx在执行第1个汇编时存储的是Klass首地址,然后根据itable索引加上了相对于第1个itableMethodEntry的偏移,这样就找到了对应的itableMethodEntry。
第6部分
在执行如下汇编时,各个寄存器的值如下:
rbx: Method* to call
rcx: receiver
生成的汇编代码如下:
0x00007fffe10228fb: test %rbx,%rbx
// 如果本来应该存储Method*的%rbx是空,则表示没有找到
// 这个方法,跳转到---- no_such_method ----
0x00007fffe10228fe: je 0x00007fffe1022987
// 保存调用者的栈顶指针
0x00007fffe1022904: lea 0x8(%rsp),%r13
0x00007fffe1022909: mov %r13,-0x10(%rbp)
// 跳转到Method::from_interpreted指向的例程并执行
0x00007fffe102290d: jmpq *0x58(%rbx)
// 省略should_not_reach_here()函数生成的汇编
// **** no_such_method ****
// 当没有找到方法时,会跳转到这里执行
// 弹出调用prepare_invoke()函数压入的返回地址
0x00007fffe1022987: pop %rbx
// 恢复让%r13指向bcp
0x00007fffe1022988: mov -0x38(%rbp),%r13
// 恢复让%r14指向本地变量表
0x00007fffe102298c: mov -0x30(%rbp),%r14
// ... 省略通过call_VM()函数生成的汇编来调用InterpreterRuntime::throw_abstractMethodError()函数
// ... 省略调用should_not_reach_here()函数生成的汇编代码
// **** no_such_interface ****
// 当没有找到匹配的接口时执行的汇编代码
0x00007fffe1022a8c: pop %rbx
0x00007fffe1022a8d: mov -0x38(%rbp),%r13
0x00007fffe1022a91: mov -0x30(%rbp),%r14
// ... 省略通过call_VM()函数生成的汇编代码来调用InterpreterRuntime::throw_IncompatibleClassChangeError()函数
// ... 省略调用should_not_reach_here()函数生成的汇编代码
对于一些异常的处理这里就不过多介绍了,有兴趣的可以看一下相关汇编代码的实现。
由于字数限制,《虚拟机解释执行Java方法(下)》将在下篇中释出
有性能问题,找HeapDump性能社区

 浙公网安备 33010602011771号
浙公网安备 33010602011771号