【超硬核】JVM源码解读:Java方法main在虚拟机上解释执行
本文由HeapDump性能社区首席讲师鸠摩授权整理发布
第1篇-关于Java虚拟机HotSpot,开篇说的简单点
开讲Java运行时,这一篇讲一些简单的内容。我们写的主类中的main()方法是如何被Java虚拟机调用到的?在Java类中的一些方法会被由C/C++编写的HotSpot虚拟机的C/C++函数调用,不过由于Java方法与C/C++函数的调用约定不同,所以并不能直接调用,需要JavaCalls::call()这个函数辅助调用。(我把由C/C++编写的叫函数,把Java编写的叫方法,后续也会延用这样的叫法)如下图所示。
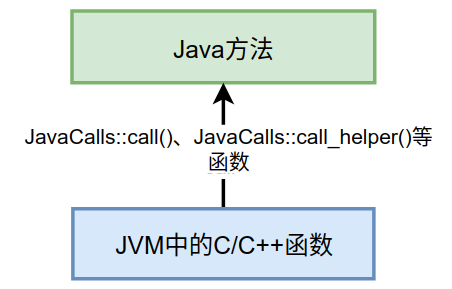
从C/C++函数中调用的一些Java方法主要有:
(1)Java主类中的main()方法;
(2)Java主类装载时,调用JavaCalls::call()函数执行checkAndLoadMain()方法;
(3)类的初始化过程中,调用JavaCalls::call()函数执行的Java类初始化方法,可以查看JavaCalls::call_default_constructor()函数,有对方法的调用逻辑;
(4)我们先省略main方法的执行流程(其实main方法的执行也是先启动一个JavaMain线程,套路都是一样的),单看某个JavaThread的启动过程。JavaThread的启动最终都要通过一个native方法java.lang.Thread#start0()方法完成的,这个方法经过解释器的native_entry入口,调用到了JVM_StartThread()函数。其中的static void thread_entry(JavaThread* thread, TRAPS)函数中会调用JavaCalls::call_virtual()函数。JavaThread最终会通过JavaCalls::call_virtual()函数来调用字节码中的run()方法;
(5)在SystemDictionary::load_instance_class()这个能体现双亲委派的函数中,如果类加载器对象不为空,则会调用这个类加载器的loadClass()函数(通过call_virtual()函数来调用)来加载类。
当然还会有其它方法,这里就不一一列举了。通过JavaCalls::call()、JavaCalls::call_helper()等函数调用Java方法,这些函数定义在JavaCalls类中,这个类的定义如下:
从C/C++函数中调用的一些Java方法主要有:
(1)Java主类中的main()方法;
(2)Java主类装载时,调用JavaCalls::call()函数执行checkAndLoadMain()方法;
(3)类的初始化过程中,调用JavaCalls::call()函数执行的Java类初始化方法,可以查看JavaCalls::call_default_constructor()函数,有对方法的调用逻辑;
(4)我们先省略main方法的执行流程(其实main方法的执行也是先启动一个JavaMain线程,套路都是一样的),单看某个JavaThread的启动过程。JavaThread的启动最终都要通过一个native方法java.lang.Thread#start0()方法完成的,这个方法经过解释器的native_entry入口,调用到了JVM_StartThread()函数。其中的static void thread_entry(JavaThread* thread, TRAPS)函数中会调用JavaCalls::call_virtual()函数。JavaThread最终会通过JavaCalls::call_virtual()函数来调用字节码中的run()方法;
(5)在SystemDictionary::load_instance_class()这个能体现双亲委派的函数中,如果类加载器对象不为空,则会调用这个类加载器的loadClass()函数(通过call_virtual()函数来调用)来加载类。
当然还会有其它方法,这里就不一一列举了。通过JavaCalls::call()、JavaCalls::call_helper()等函数调用Java方法,这些函数定义在JavaCalls类中,这个类的定义如下:
源代码位置:openjdk/hotspot/src/share/vm/runtime/javaCalls.hpp
class JavaCalls: AllStatic {
static void call_helper(JavaValue* result, methodHandle* method, JavaCallArguments* args, TRAPS);
public:
static void call_default_constructor(JavaThread* thread, methodHandle method, Handle receiver, TRAPS);
// 使用如下函数调用Java中一些特殊的方法,如类初始化方法<clinit>等
// receiver表示方法的接收者,如A.main()调用中,A就是方法的接收者
static void call_special(JavaValue* result, KlassHandle klass, Symbol* name,Symbol* signature, JavaCallArguments* args, TRAPS);
static void call_special(JavaValue* result, Handle receiver, KlassHandle klass,Symbol* name, Symbol* signature, TRAPS);
static void call_special(JavaValue* result, Handle receiver, KlassHandle klass,Symbol* name, Symbol* signature, Handle arg1, TRAPS);
static void call_special(JavaValue* result, Handle receiver, KlassHandle klass,Symbol* name, Symbol* signature, Handle arg1, Handle arg2, TRAPS);
// 使用如下函数调用动态分派的一些方法
static void call_virtual(JavaValue* result, KlassHandle spec_klass, Symbol* name,Symbol* signature, JavaCallArguments* args, TRAPS);
static void call_virtual(JavaValue* result, Handle receiver, KlassHandle spec_klass,Symbol* name, Symbol* signature, TRAPS);
static void call_virtual(JavaValue* result, Handle receiver, KlassHandle spec_klass,Symbol* name, Symbol* signature, Handle arg1, TRAPS);
static void call_virtual(JavaValue* result, Handle receiver, KlassHandle spec_klass,Symbol* name, Symbol* signature, Handle arg1, Handle arg2, TRAPS);
// 使用如下函数调用Java静态方法
static void call_static(JavaValue* result, KlassHandle klass,Symbol* name, Symbol* signature, JavaCallArguments* args, TRAPS);
static void call_static(JavaValue* result, KlassHandle klass,Symbol* name, Symbol* signature, TRAPS);
static void call_static(JavaValue* result, KlassHandle klass,Symbol* name, Symbol* signature, Handle arg1, TRAPS);
static void call_static(JavaValue* result, KlassHandle klass,Symbol* name, Symbol* signature, Handle arg1, Handle arg2, TRAPS);
// 更低一层的接口,如上的一些函数可能会最终调用到如下这个函数
static void call(JavaValue* result, methodHandle method, JavaCallArguments* args, TRAPS);
};
如上的函数都是自解释的,通过名称我们就能看出这些函数的作用。其中JavaCalls::call()函数是更低一层的通用接口。Java虚拟机规范定义的字节码指令共有5个,分别为invokestatic、invokedynamic、invokestatic、invokespecial、invokevirtual几种方法调用指令。这些call_static()、call_virtual()函数内部调用了call()函数。这一节我们先不介绍各个方法的具体实现。下一篇将详细介绍。
我们选一个重要的main()方法来查看具体的调用逻辑。如下基本照搬R大的内容,不过我略做了一些修改,如下:
假设我们的Java主类的类名为JavaMainClass,下面为了区分java launcher里C/C++的main()与Java层程序里的main(),把后者写作JavaMainClass.main()方法。
从刚进入C/C++的main()函数开始:
启动并调用HotSpot虚拟机的main()函数的线程执行的主要逻辑如下:
main()
-> //... 做一些参数检查
-> //... 开启新线程作为main线程,让它从JavaMain()函数开始执行;该线程等待main线程执行结束
在如上线程中会启动另外一个线程执行JavaMain()函数,如下:
JavaMain()
-> //... 找到指定的JVM
-> //... 加载并初始化JVM
-> //... 根据Main-Class指定的类名加载JavaMainClass
-> //... 在JavaMainClass类里找到名为"main"的方法,签名为"([Ljava/lang/String;)V",修饰符是public的静态方法
-> (*env)->CallStaticVoidMethod(env, mainClass, mainID, mainArgs); // 通过JNI调用JavaMainClass.main()方法
以上步骤都还在java launcher的控制下;当控制权转移到JavaMainClass.main()方法之后就没java launcher什么事了,等JavaMainClass.main()方法返回之后java launcher才接手过来清理和关闭JVM。
下面看一下调用Java主类main()方法时会经过的主要方法及执行的主要逻辑,如下:
// HotSpot VM里对JNI的CallStaticVoidMethod的实现。留意要传给Java方法的参数
// 以C的可变长度参数传入,这个函数将其收集打包为JNI_ArgumentPusherVaArg对象
-> jni_CallStaticVoidMethod()
// 这里进一步将要传给Java的参数转换为JavaCallArguments对象传下去
-> jni_invoke_static()
// 真正底层实现的开始。这个方法只是层皮,把JavaCalls::call_helper()
// 用os::os_exception_wrapper()包装起来,目的是设置HotSpot VM的C++层面的异常处理
-> JavaCalls::call()
-> JavaCalls::call_helper()
-> //... 检查目标方法是否为空方法,是的话直接返回
-> //... 检查目标方法是否“首次执行前就必须被编译”,是的话调用JIT编译器去编译目标方法
-> //... 获取目标方法的解释模式入口from_interpreted_entry,下面将其称为entry_point
-> //... 确保Java栈溢出检查机制正确启动
-> //... 创建一个JavaCallWrapper,用于管理JNIHandleBlock的分配与释放,
// 以及在调用Java方法前后保存和恢复Java的frame pointer/stack pointer
//... StubRoutines::call_stub()返回一个指向call stub的函数指针,
// 紧接着调用这个call stub,传入前面获取的entry_point和要传给Java方法的参数等信息
-> StubRoutines::call_stub()(...)
// call stub是在VM初始化时生成的。对应的代码在
// StubGenerator::generate_call_stub()函数中
-> //... 把相关寄存器的状态调整到解释器所需的状态
-> //... 把要传给Java方法的参数从JavaCallArguments对象解包展开到解释模
// 式calling convention所要求的位置
-> //... 跳转到前面传入的entry_point,也就是目标方法的from_interpreted_entry
-> //... 在-Xcomp模式下,实际跳入的是i2c adapter stub,将解释模式calling convention
// 传入的参数挪到编译模式calling convention所要求的位置
-> //... 跳转到目标方法被JIT编译后的代码里,也就是跳到 nmethod 的 VEP 所指向的位置
-> //... 正式开始执行目标方法被JIT编译好的代码 <- 这里就是"main()方法的真正入口"
后面3个步骤是在编译执行的模式下,不过后续我们从解释执行开始研究,所以需要为虚拟机配置-Xint选项,有了这个选项后,Java主类的main()方法就会解释执行了。
在调用Java主类main()方法的过程中,我们看到了虚拟机是通过JavaCalls::call()函数来间接调用main()方法的,下一篇我们研究一下具体的调用逻辑。
第2篇-Java虚拟机这样来调用Java主类的main()方法
在前一篇第1篇-关于Java虚拟机HotSpot,开篇说的简单些 中介绍了call_static()、call_virtual()等函数的作用,这些函数会调用JavaCalls::call()函数。我们看Java类中main()方法的调用,调用栈如下:
JavaCalls::call_helper() at javaCalls.cpp
os::os_exception_wrapper() at os_linux.cpp
JavaCalls::call() at javaCalls.cpp
jni_invoke_static() at jni.cpp
jni_CallStaticVoidMethod() at jni.cpp
JavaMain() at java.c
start_thread() at pthread_create.c
clone() at clone.S
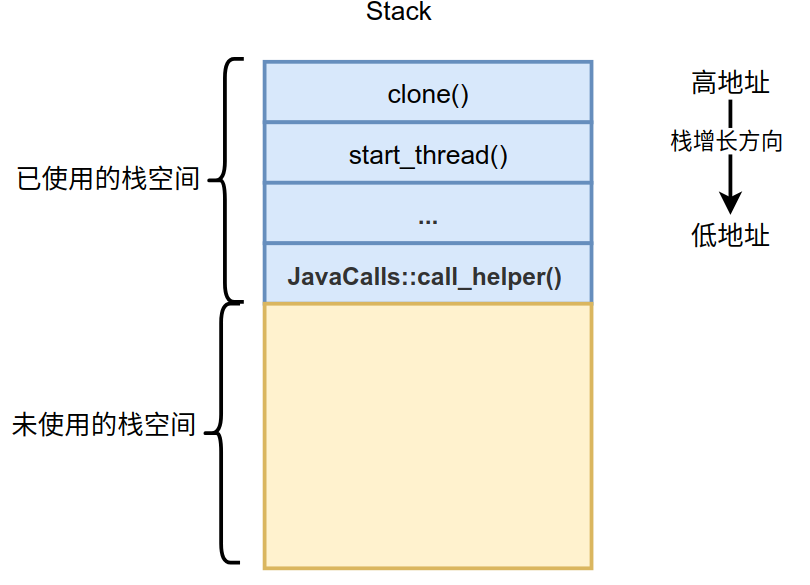
这是Linux上的调用栈,通过JavaCalls::call_helper()函数来执行main()方法。栈的起始函数为clone(),这个函数会为每个进程(Linux进程对应着Java线程)创建单独的栈空间,这个栈空间如下图所示。
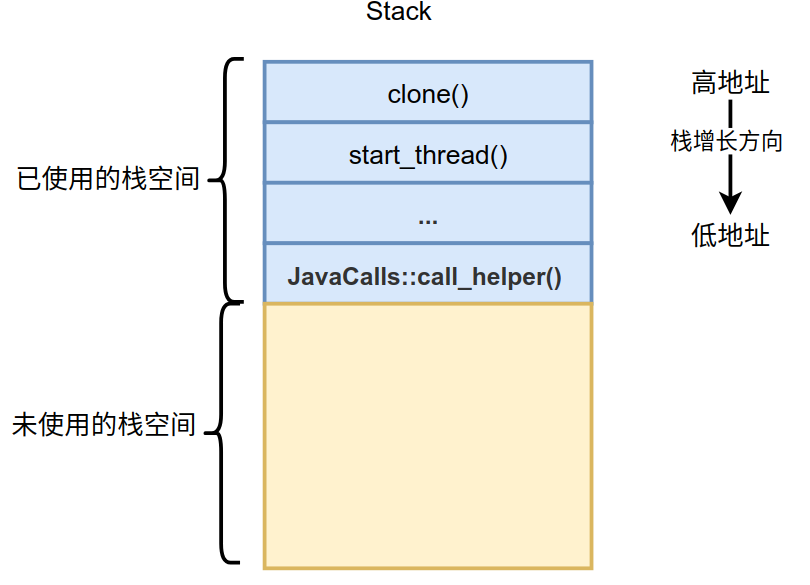
在Linux操作系统上,栈的地址向低地址延伸,所以未使用的栈空间在已使用的栈空间之下。图中的每个蓝色小格表示对应方法的栈帧,而栈就是由一个一个的栈帧组成。native方法的栈帧、Java解释栈帧和Java编译栈帧都会在黄色区域中分配,所以说他们寄生在宿主栈中,这些不同的栈帧都紧密的挨在一起,所以并不会产生什么空间碎片这类的问题,而且这样的布局非常有利于进行栈的遍历。上面给出的调用栈就是通过遍历一个一个栈帧得到的,遍历过程也是栈展开的过程。后续对于异常的处理、运行jstack打印线程堆栈、GC查找根引用等都会对栈进行展开操作,所以栈展开是后面必须要介绍的。
下面我们继续看JavaCalls::call_helper()函数,这个函数中有个非常重要的调用,如下:
// do call
{
JavaCallWrapper link(method, receiver, result, CHECK);
{
HandleMark hm(thread); // HandleMark used by HandleMarkCleaner
StubRoutines::call_stub()(
(address)&link,
result_val_address,
result_type,
method(),
entry_point,
args->parameters(),
args->size_of_parameters(),
CHECK
);
result = link.result();
// Preserve oop return value across possible gc points
if (oop_result_flag) {
thread->set_vm_result((oop) result->get_jobject());
}
}
}
调用StubRoutines::call_stub()函数返回一个函数指针,然后通过函数指针来调用函数指针指向的函数。通过函数指针调用和通过函数名调用的方式一样,这里我们需要清楚的是,调用的目标函数仍然是C/C++函数,所以由C/C++函数调用另外一个C/C++函数时,要遵守调用约定。这个调用约定会规定怎么给被调用函数(Callee)传递参数,以及被调用函数的返回值将存储在什么地方。
下面我们就来简单说说Linux X86架构下的C/C++函数调用约定,在这个约定下,以下寄存器用于传递参数:
第1个参数:rdi c_rarg0
第2个参数:rsi c_rarg1
第3个参数:rdx c_rarg2
第4个参数:rcx c_rarg3
第5个参数:r8 c_rarg4
第6个参数:r9 c_rarg5
在函数调用时,6个及小于6个用如下寄存器来传递,在HotSpot中通过更易理解的别名c_rarg* 来使用对应的寄存器。如果参数超过六个,那么程序将会用调用栈来传递那些额外的参数。
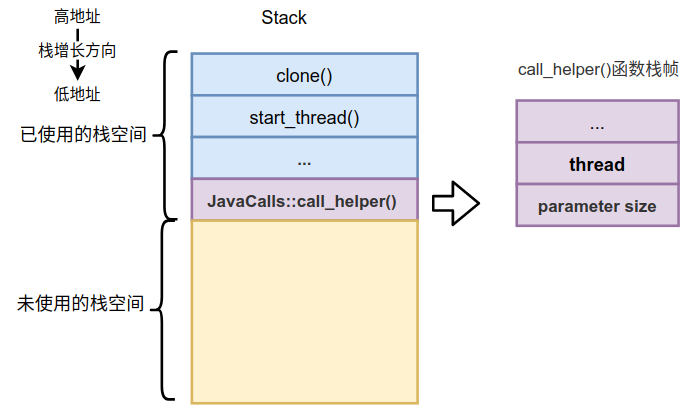
数一下我们通过函数指针调用时传递了几个参数?8个,那么后面的2个就需要通过调用函数(Caller)的栈来传递,这两个参数就是args->size_of_parameters()和CHECK(这是个宏,扩展后就是传递线程对象)。
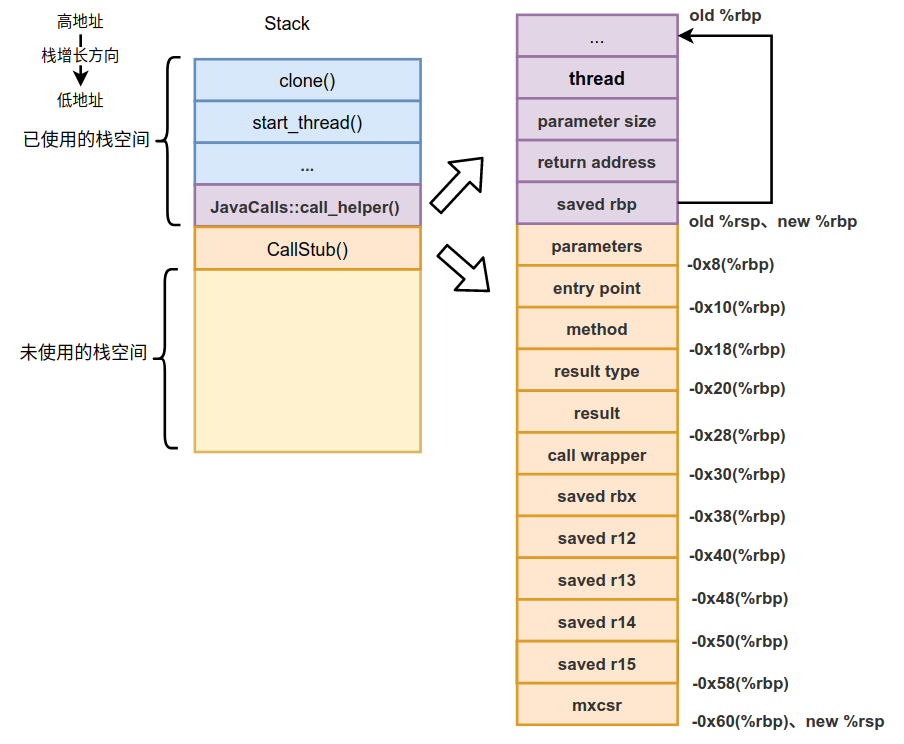
所以我们的调用栈在调用函数指针指向的函数时,变为了如下状态:
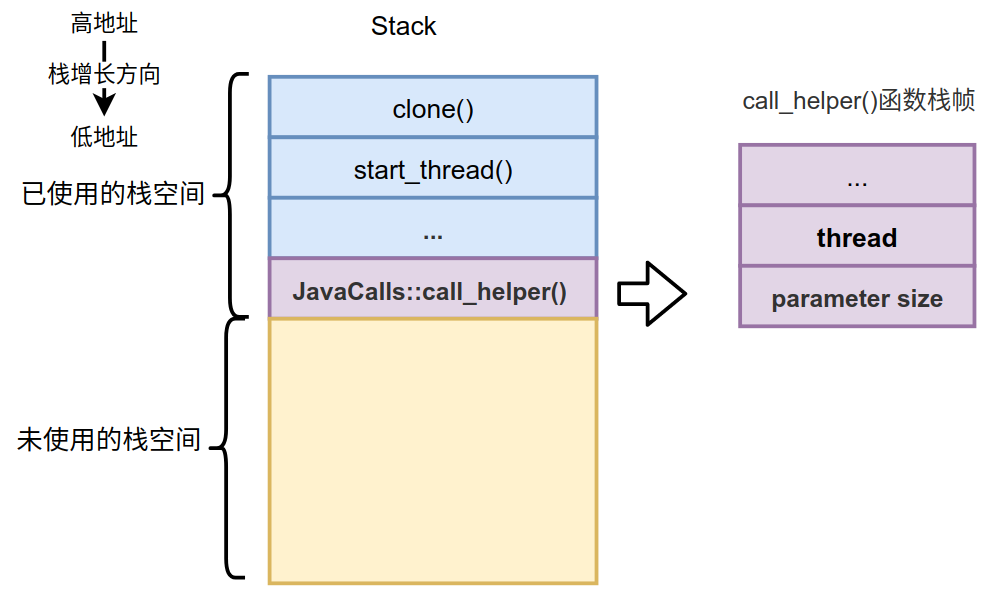
右边是具体的call_helper()栈帧中的内容,我们把thread和parameter size压入了调用栈中,其实在调目标函数的过程还会开辟新的栈帧并在parameter size后压入返回地址和调用栈的栈底,下一篇我们再详细介绍。先来介绍下JavaCalls::call_helper()函数的实现,我们分3部分依次介绍。
1、检查目标方法是否"首次执行前就必须被编译”,是的话调用JIT编译器去编译目标方法;
代码实现如下:
void JavaCalls::call_helper(
JavaValue* result,
methodHandle* m,
JavaCallArguments* args,
TRAPS
) {
methodHandle method = *m;
JavaThread* thread = (JavaThread*)THREAD;
...
assert(!thread->is_Compiler_thread(), "cannot compile from the compiler");
if (CompilationPolicy::must_be_compiled(method)) {
CompileBroker::compile_method(method, InvocationEntryBci,
CompilationPolicy::policy()->initial_compile_level(),
methodHandle(), 0, "must_be_compiled", CHECK);
}
...
}
对于main()方法来说,如果配置了-Xint选项,则是以解释模式执行的,所以并不会走上面的compile_method()函数的逻辑。后续我们要研究编译执行时,可以强制要求进行编译执行,然后查看执行过程。
2、获取目标方法的解释模式入口from_interpreted_entry,也就是entry_point的值。获取的entry_point就是为Java方法调用准备栈桢,并把代码调用指针指向method的第一个字节码的内存地址。entry_point相当于是method的封装,不同的method类型有不同的entry_point。
接着看call_helper()函数的代码实现,如下:
address entry_point = method->from_interpreted_entry();
调用method的from_interpreted_entry()函数获取Method实例中_from_interpreted_entry属性的值,这个值到底在哪里设置的呢?我们后面会详细介绍。
3、调用call_stub()函数,需要传递8个参数。这个代码在前面给出过,这里不再给出。下面我们详细介绍一下这几个参数,如下:
(1)link 此变量的类型为JavaCallWrapper,这个变量对于栈展开过程非常重要,后面会详细介绍;
(2)result_val_address 函数返回值地址;
(3)result_type 函数返回类型;
(4)method() 当前要执行的方法。通过此参数可以获取到Java方法所有的元数据信息,包括最重要的字节码信息,这样就可以根据字节码信息解释执行这个方法了;
(5)entry_point HotSpot每次在调用Java函数时,必然会调用CallStub函数指针,这个函数指针的值取自_call_stub_entry,HotSpot通过_call_stub_entry指向被调用函数地址。在调用函数之前,必须要先经过entry_point,HotSpot实际是通过entry_point从method()对象上拿到Java方法对应的第1个字节码命令,这也是整个函数的调用入口;
(6)args->parameters() 描述Java函数的入参信息;
(7)args->size_of_parameters() 参数需要占用的,以字为单位的内存大小
(8)CHECK 当前线程对象。
这里最重要的就是entry_point了,这也是下一篇要介绍的内容。
第3篇-CallStub新栈帧的创建
在前一篇文章第2篇-JVM虚拟机这样来调用Java主类的main()方法中我们介绍了在call_helper()函数中通过函数指针的方式调用了一个函数,如下:
StubRoutines::call_stub()(
(address)&link,
result_val_address,
result_type,
method(),
entry_point,
args->parameters(),
args->size_of_parameters(),
CHECK
);
其中调用StubRoutines::call_stub()函数会返回一个函数指针,查清楚这个函数指针指向的函数的实现是我们这一篇的重点。 调用的call_stub()函数的实现如下:
源代码位置:openjdk/hotspot/src/share/vm/runtime/stubRoutines.hpp
static CallStub call_stub() {
return CAST_TO_FN_PTR(CallStub, _call_stub_entry);
}
call_stub()函数返回一个函数指针,指向依赖于操作系统和cpu架构的特定的方法,原因很简单,要执行native代码,得看看是什么cpu架构以便确定寄存器,看看什么os以便确定ABI。
其中CAST_TO_FN_PTR是宏,具体定义如下:
源代码位置:/src/share/vm/runtime/utilities/globalDefinitions.hpp
#define CAST_TO_FN_PTR(func_type, value) ((func_type)(castable_address(value)))
对call_stub()函数进行宏替换和展开后会变为如下的形式:
static CallStub call_stub(){
return (CallStub)( castable_address(_call_stub_entry) );
}
CallStub的定义如下:
源代码位置:openjdk/hotspot/src/share/vm/runtime/stubRoutines.hpp
typedef void (*CallStub)(
// 连接器
address link,
// 函数返回值地址
intptr_t* result,
//函数返回类型
BasicType result_type,
// JVM内部所表示的Java方法对象
Method* method,
// JVM调用Java方法的例程入口。JVM内部的每一段
// 例程都是在JVM启动过程中预先生成好的一段机器指令。
// 要调用Java方法, 必须经过本例程,
// 即需要先执行这段机器指令,然后才能跳转到Java方法
// 字节码所对应的机器指令去执行
address entry_point,
intptr_t* parameters,
int size_of_parameters,
TRAPS
);
如上定义了一种函数指针类型,指向的函数声明了8个形式参数。
在call_stub()函数中调用的castable_address()函数定义在globalDefinitions.hpp文件中,具体实现如下:
inline address_word castable_address(address x) {
return address_word(x) ;
}
address_word是一定自定义的类型,在globalDefinitions.hpp文件中的定义如下:
typedef uintptr_t address_word;
其中uintptr_t也是一种自定义的类型,在Linux内核的操作系统下使用globalDefinitions_gcc.hpp文件中的定义,具体定义如下:
typedef unsigned int uintptr_t;
这样call_stub()函数其实等同于如下的实现形式:
static CallStub call_stub(){
return (CallStub)( unsigned int(_call_stub_entry) );
}
将_call_stub_entry强制转换为unsigned int类型,然后以强制转换为CallStub类型。CallStub是一个函数指针,所以_call_stub_entry应该也是一个函数指针,而不应该是一个普通的无符号整数。
在call_stub()函数中,_call_stub_entry的定义如下:
address StubRoutines::_call_stub_entry = NULL;
_call_stub_entry的初始化在在openjdk/hotspot/src/cpu/x86/vm/stubGenerator_x86_64.cpp文件下的generate_initial()函数,调用链如下:
StubGenerator::generate_initial() stubGenerator_x86_64.cpp
StubGenerator::StubGenerator() stubGenerator_x86_64.cpp
StubGenerator_generate() stubGenerator_x86_64.cpp
StubRoutines::initialize1() stubRoutines.cpp
stubRoutines_init1() stubRoutines.cpp
init_globals() init.cpp
Threads::create_vm() thread.cpp
JNI_CreateJavaVM() jni.cpp
InitializeJVM() java.c
JavaMain() java.c
其中的StubGenerator类定义在openjdk/hotspot/src/cpu/x86/vm目录下的stubGenerator_x86_64.cpp文件中,这个文件中的generate_initial()方法会初始化call_stub_entry变量,如下:
StubRoutines::_call_stub_entry = generate_call_stub(StubRoutines::_call_stub_return_address);
现在我们终于找到了函数指针指向的函数的实现逻辑,这个逻辑是通过调用generate_call_stub()函数来实现的。
不过经过查看后我们发现这个函数指针指向的并不是一个C++函数,而是一个机器指令片段,我们可以将其看为C++函数经过C++编译器编译后生成的指令片段即可。在generate_call_stub()函数中有如下调用语句:
__ enter();
__ subptr(rsp, -rsp_after_call_off * wordSize);
这两段代码直接生成机器指令,不过为了查看机器指令,我们借助了HSDB工具将其反编译为可读性更强的汇编指令。如下:
push %rbp
mov %rsp,%rbp
sub $0x60,%rsp
这3条汇编是非常典型的开辟新栈帧的指令。之前我们介绍过在通过函数指针进行调用之前的栈状态,如下:
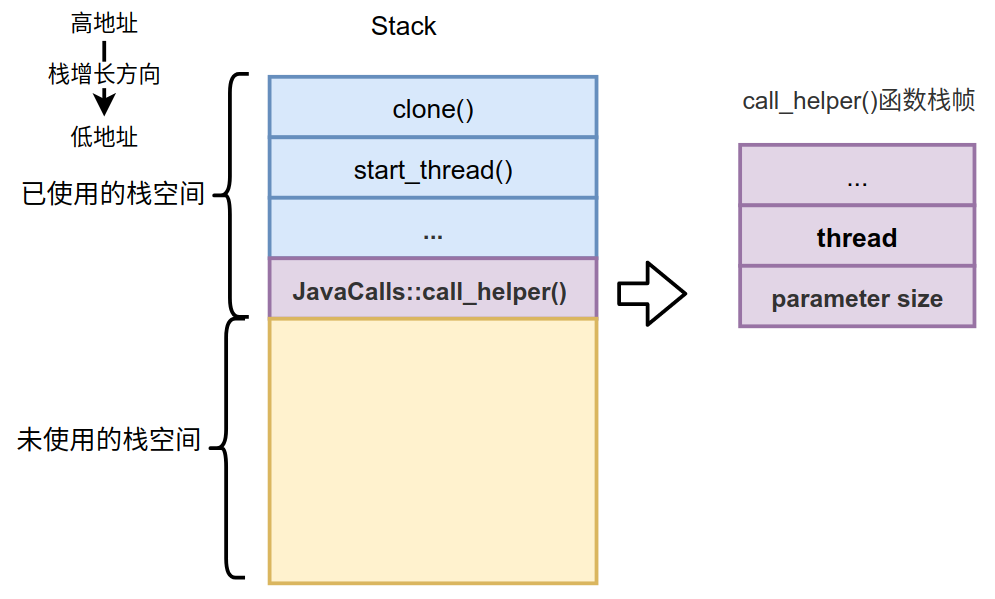
那么经过运行如上3条汇编后这个栈状态就变为了如下的状态:
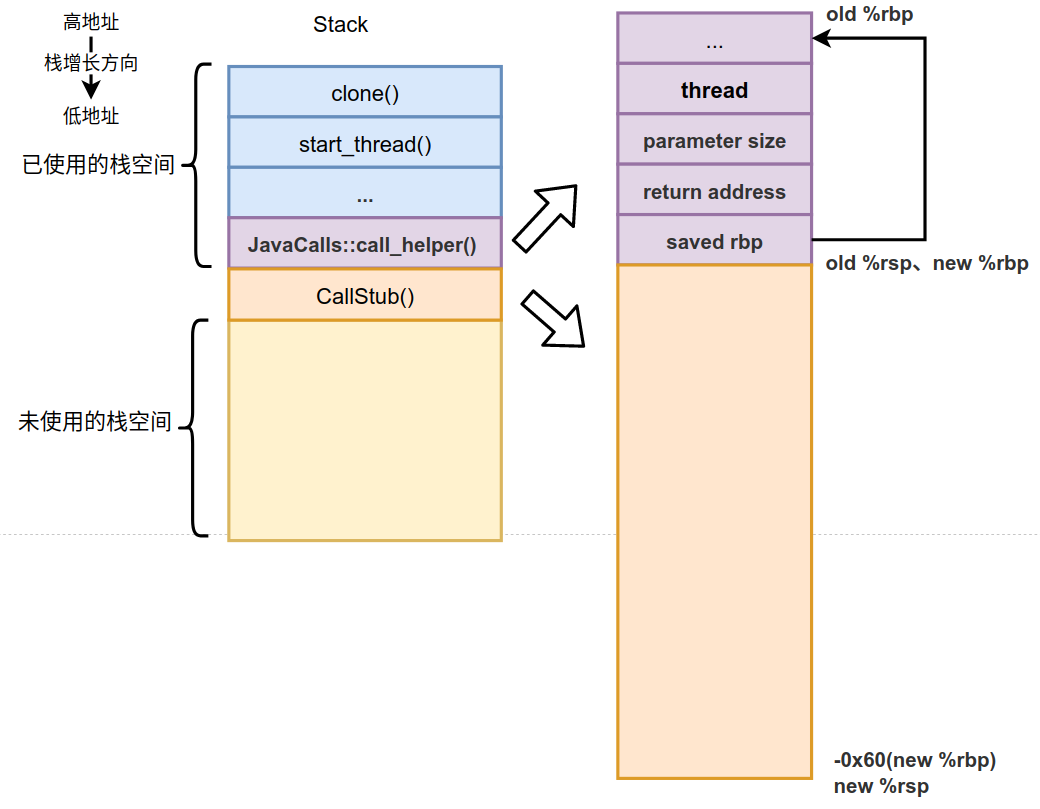
我们需要关注的就是old %rbp和old %rsp在没有运行开辟新栈帧(CallStub()栈帧)时的指向,以及开辟新栈帧(CallStub()栈帧)时的new %rbp和new %rsp的指向。另外还要注意saved rbp保存的就是old %rbp,这个值对于栈展开非常重要,因为能通过它不断向上遍历,最终能找到所有的栈帧。
下面接着看generate_call_stub()函数的实现,如下:
address generate_call_stub(address& return_address) {
...
address start = __ pc();
const Address rsp_after_call(rbp, rsp_after_call_off * wordSize);
const Address call_wrapper (rbp, call_wrapper_off * wordSize);
const Address result (rbp, result_off * wordSize);
const Address result_type (rbp, result_type_off * wordSize);
const Address method (rbp, method_off * wordSize);
const Address entry_point (rbp, entry_point_off * wordSize);
const Address parameters (rbp, parameters_off * wordSize);
const Address parameter_size(rbp, parameter_size_off * wordSize);
const Address thread (rbp, thread_off * wordSize);
const Address r15_save(rbp, r15_off * wordSize);
const Address r14_save(rbp, r14_off * wordSize);
const Address r13_save(rbp, r13_off * wordSize);
const Address r12_save(rbp, r12_off * wordSize);
const Address rbx_save(rbp, rbx_off * wordSize);
// 开辟新的栈帧
__ enter();
__ subptr(rsp, -rsp_after_call_off * wordSize);
// save register parameters
__ movptr(parameters, c_rarg5); // parameters
__ movptr(entry_point, c_rarg4); // entry_point
__ movptr(method, c_rarg3); // method
__ movl(result_type, c_rarg2); // result type
__ movptr(result, c_rarg1); // result
__ movptr(call_wrapper, c_rarg0); // call wrapper
// save regs belonging to calling function
__ movptr(rbx_save, rbx);
__ movptr(r12_save, r12);
__ movptr(r13_save, r13);
__ movptr(r14_save, r14);
__ movptr(r15_save, r15);
const Address mxcsr_save(rbp, mxcsr_off * wordSize);
{
Label skip_ldmx;
__ stmxcsr(mxcsr_save);
__ movl(rax, mxcsr_save);
__ andl(rax, MXCSR_MASK); // Only check control and mask bits
ExternalAddress mxcsr_std(StubRoutines::addr_mxcsr_std());
__ cmp32(rax, mxcsr_std);
__ jcc(Assembler::equal, skip_ldmx);
__ ldmxcsr(mxcsr_std);
__ bind(skip_ldmx);
}
// ... 省略了接下来的操作
}
其中开辟新栈帧的逻辑我们已经介绍过,下面就是将call_helper()传递的6个在寄存器中的参数存储到CallStub()栈帧中了,除了存储这几个参数外,还需要存储其它寄存器中的值,因为函数接下来要做的操作是为Java方法准备参数并调用Java方法,我们并不知道Java方法会不会破坏这些寄存器中的值,所以要保存下来,等调用完成后进行恢复。
生成的汇编代码如下:
mov %r9,-0x8(%rbp)
mov %r8,-0x10(%rbp)
mov %rcx,-0x18(%rbp)
mov %edx,-0x20(%rbp)
mov %rsi,-0x28(%rbp)
mov %rdi,-0x30(%rbp)
mov %rbx,-0x38(%rbp)
mov %r12,-0x40(%rbp)
mov %r13,-0x48(%rbp)
mov %r14,-0x50(%rbp)
mov %r15,-0x58(%rbp)
// stmxcsr是将MXCSR寄存器中的值保存到-0x60(%rbp)中
stmxcsr -0x60(%rbp)
mov -0x60(%rbp),%eax
and $0xffc0,%eax // MXCSR_MASK = 0xFFC0
// cmp通过第2个操作数减去第1个操作数的差,根据结果来设置eflags中的标志位。
// 本质上和sub指令相同,但是不会改变操作数的值
cmp 0x1762cb5f(%rip),%eax # 0x00007fdf5c62d2c4
// 当ZF=1时跳转到目标地址
je 0x00007fdf45000772
// 将m32加载到MXCSR寄存器中
ldmxcsr 0x1762cb52(%rip) # 0x00007fdf5c62d2c4
加载完成这些参数后如下图所示。
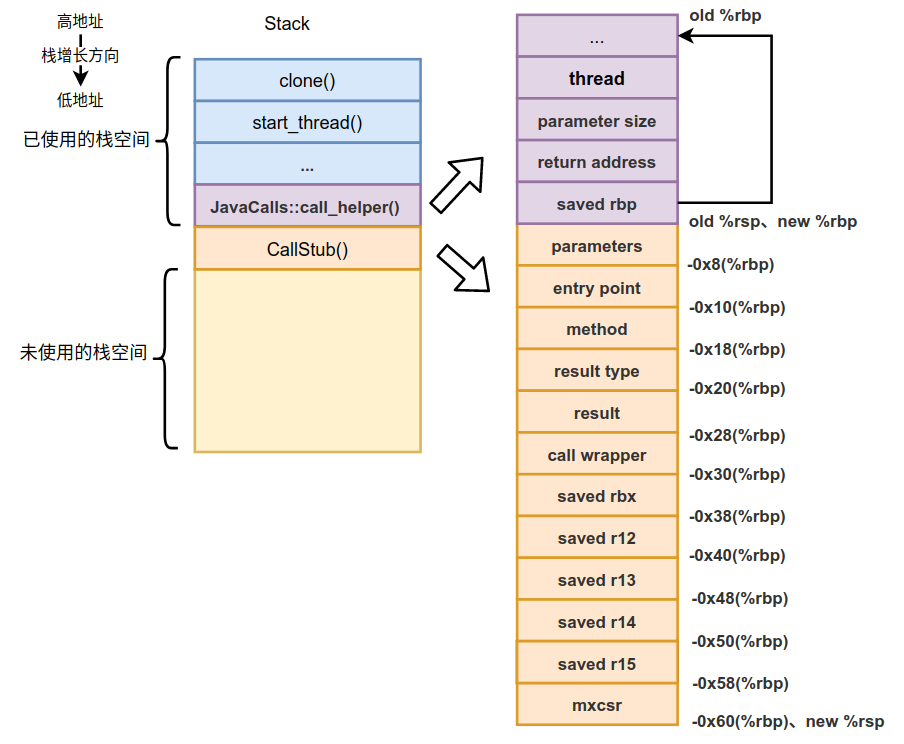
下一篇我们继续介绍下generate_call_stub()函数中其余的实现。
第4篇-JVM终于开始调用Java主类的main()方法啦
在前一篇 第3篇-CallStub新栈帧的创建 中我们介绍了generate_call_stub()函数的部分实现,完成了向CallStub栈帧中压入参数的操作,此时的状态如下图所示。
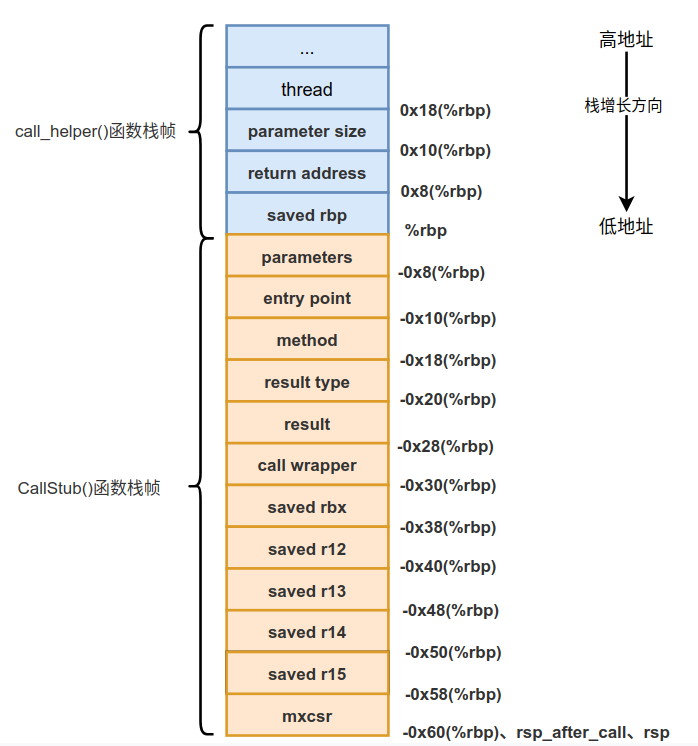
继续看generate_call_stub()函数的实现,接来下会加载线程寄存器,代码如下:
__ movptr(r15_thread, thread);
__ reinit_heapbase();
生成的汇编代码如下:
mov 0x18(%rbp),%r15
mov 0x1764212b(%rip),%r12 # 0x00007fdf5c6428a8
对照着上面的栈帧可看一下0x18(%rbp)这个位置存储的是thread,将这个参数存储到%r15寄存器中。
如果在调用函数时有参数的话需要传递参数,代码如下:
Label parameters_done;
// parameter_size拷贝到c_rarg3即rcx寄存器中
__ movl(c_rarg3, parameter_size);
// 校验c_rarg3的数值是否合法。两操作数作与运算,仅修改标志位,不回送结果
__ testl(c_rarg3, c_rarg3);
// 如果不合法则跳转到parameters_done分支上
__ jcc(Assembler::zero, parameters_done);
// 如果执行下面的逻辑,那么就表示parameter_size的值不为0,也就是需要为
// 调用的java方法提供参数
Label loop;
// 将地址parameters包含的数据即参数对象的指针拷贝到c_rarg2寄存器中
__ movptr(c_rarg2, parameters);
// 将c_rarg3中值拷贝到c_rarg1中,即将参数个数复制到c_rarg1中
__ movl(c_rarg1, c_rarg3);
__ BIND(loop);
// 将c_rarg2指向的内存中包含的地址复制到rax中
__ movptr(rax, Address(c_rarg2, 0));
// c_rarg2中的参数对象的指针加上指针宽度8字节,即指向下一个参数
__ addptr(c_rarg2, wordSize);
// 将c_rarg1中的值减一
__ decrementl(c_rarg1);
// 传递方法调用参数
__ push(rax);
// 如果参数个数大于0则跳转到loop继续
__ jcc(Assembler::notZero, loop);
这里是个循环,用于传递参数,相当于如下代码:
while(%esi){
rax = *arg
push_arg(rax)
arg++; // ptr++
%esi--; // counter--
}
生成的汇编代码如下:
// 将栈中parameter size送到%ecx中
mov 0x10(%rbp),%ecx
// 做与运算,只有当%ecx中的值为0时才等于0
test %ecx,%ecx
// 没有参数需要传递,直接跳转到parameters_done即可
je 0x00007fdf4500079a
// -- loop --
// 汇编执行到这里,说明paramter size不为0,需要传递参数
mov -0x8(%rbp),%rdx
mov %ecx,%esi
mov (%rdx),%rax
add $0x8,%rdx
dec %esi
push %rax
// 跳转到loop
jne 0x00007fdf4500078e
因为要调用Java方法,所以会为Java方法压入实际的参数,也就是压入parameter size个从parameters开始取的参数。压入参数后的栈如下图所示。
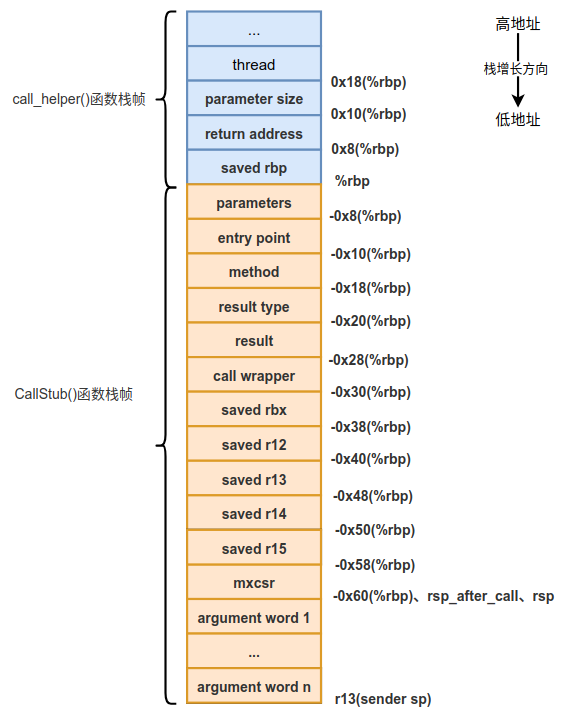
当把需要调用Java方法的参数准备就绪后,接下来就会调用Java方法。这里需要重点提示一下Java解释执行时的方法调用约定,不像C/C++在x86下的调用约定一样,不需要通过寄存器来传递参数,而是通过栈来传递参数的,说的更直白一些,是通过局部变量表来传递参数的,所以上图CallStub()函数栈帧中的argument word1 ... argument word n其实是被调用的Java方法局部变量表的一部分。
下面接着看调用Java方法的代码,如下:
// 调用Java方法
// -- parameters_done --
__ BIND(parameters_done);
// 将method地址包含的数据接Method*拷贝到rbx中
__ movptr(rbx, method);
// 将解释器的入口地址拷贝到c_rarg1寄存器中
__ movptr(c_rarg1, entry_point);
// 将rsp寄存器的数据拷贝到r13寄存器中
__ mov(r13, rsp);
// 调用解释器的解释函数,从而调用Java方法
// 调用的时候传递c_rarg1,也就是解释器的入口地址
__ call(c_rarg1);
生成的汇编代码如下:
// 将Method*送到%rbx中
mov -0x18(%rbp),%rbx
// 将entry_point送到%rsi中
mov -0x10(%rbp),%rsi
// 将调用者的栈顶指针保存到%r13中
mov %rsp,%r13
// 调用Java方法
callq *%rsi
注意调用callq指令后,会将callq指令的下一条指令的地址压栈,再跳转到第1操作数指定的地址,也就是*%rsi表示的地址。压入下一条指令的地址是为了让函数能通过跳转到栈上的地址从子函数返回。
callq指令调用的是entry_point。entry_point在后面会详细介绍。
第5篇-调用Java方法后弹出栈帧及处理返回结果
在前一篇第4篇-JVM终于开始调用Java主类的main()方法啦介绍了通过callq调用entry point,不过我们并没有看完generate_call_stub()函数的实现。接下来在generate_call_stub()函数中会处理调用Java方法后的返回值,同时还需要执行退栈操作,也就是将栈恢复到调用Java方法之前的状态。调用之前是什么状态呢?在 第2篇-JVM虚拟机这样来调用Java主类的main()方法 中介绍过,这个状态如下图所示。
generate_call_stub()函数接下来的代码实现如下:
// 保存方法调用结果依赖于结果类型,只要不是T_OBJECT, T_LONG, T_FLOAT or T_DOUBLE,都当做T_INT处理
// 将result地址的值拷贝到c_rarg0中,也就是将方法调用的结果保存在rdi寄存器中,注意result为函数返回值的地址
__ movptr(c_rarg0, result);
Label is_long, is_float, is_double, exit;
// 将result_type地址的值拷贝到c_rarg1中,也就是将方法调用的结果返回的类型保存在esi寄存器中
__ movl(c_rarg1, result_type);
// 根据结果类型的不同跳转到不同的处理分支
__ cmpl(c_rarg1, T_OBJECT);
__ jcc(Assembler::equal, is_long);
__ cmpl(c_rarg1, T_LONG);
__ jcc(Assembler::equal, is_long);
__ cmpl(c_rarg1, T_FLOAT);
__ jcc(Assembler::equal, is_float);
__ cmpl(c_rarg1, T_DOUBLE);
__ jcc(Assembler::equal, is_double);
// 当逻辑执行到这里时,处理的就是T_INT类型,
// 将rax中的值写入c_rarg0保存的地址指向的内存中
// 调用函数后如果返回值是int类型,则根据调用约定
// 会存储在eax中
__ movl(Address(c_rarg0, 0), rax);
__ BIND(exit);
// 将rsp_after_call中保存的有效地址拷贝到rsp中,即将rsp往高地址方向移动了,
// 原来的方法调用实参argument 1、...、argument n,
// 相当于从栈中弹出,所以下面语句执行的是退栈操作
__ lea(rsp, rsp_after_call); // lea指令将地址加载到寄存器中
这里我们要关注result和result_type,result在调用call_helper()函数时就会传递,也就是会指示call_helper()函数将调用Java方法后的返回值存储在哪里。对于类型为JavaValue的result来说,其实在调用之前就已经设置了返回类型,所以如上的result_type变量只需要从JavaValue中获取结果类型即可。例如,调用Java主类的main()方法时,在jni_CallStaticVoidMethod()函数和jni_invoke_static()函数中会设置返回类型为T_VOID,也就是main()方法返回void。
生成的汇编代码如下:
// 栈中的-0x28位置保存result
mov -0x28(%rbp),%rdi
// 栈中的-0x20位置保存result type
mov -0x20(%rbp),%esi
cmp $0xc,%esi // 是否为T_OBJECT类型
je 0x00007fdf450007f6
cmp $0xb,%esi // 是否为T_LONG类型
je 0x00007fdf450007f6
cmp $0x6,%esi // 是否为T_FLOAT类型
je 0x00007fdf450007fb
cmp $0x7,%esi // 是否为T_DOUBLE类型
je 0x00007fdf45000801
// 如果是T_INT类型,直接将返回结果%eax写到栈中-0x28(%rbp)的位置
mov %eax,(%rdi)
// -- exit --
// 将rsp_after_call的有效地址拷到rsp中
lea -0x60(%rbp),%rsp
为了让大家看清楚,我贴一下在调用Java方法之前的栈帧状态,如下:

由图可看到-0x60(%rbp)地址指向的位置,恰好不包括调用Java方法时压入的实际参数argument word 1 ... argument word n。所以现在rbp和rsp就是图中指向的位置了。
接下来恢复之前保存的caller-save寄存器,这也是调用约定的一部分,如下:
__ movptr(r15, r15_save);
__ movptr(r14, r14_save);
__ movptr(r13, r13_save);
__ movptr(r12, r12_save);
__ movptr(rbx, rbx_save);
__ ldmxcsr(mxcsr_save);
生成的汇编代码如下:
mov -0x58(%rbp),%r15
mov -0x50(%rbp),%r14
mov -0x48(%rbp),%r13
mov -0x40(%rbp),%r12
mov -0x38(%rbp),%rbx
ldmxcsr -0x60(%rbp)
在弹出了为调用Java方法保存的实际参数及恢复caller-save寄存器后,继续执行退栈操作,实现如下:
// restore rsp
__ addptr(rsp, -rsp_after_call_off * wordSize);
// return
__ pop(rbp);
__ ret(0);
生成的汇编代码如下:
// %rsp加上0x60,也就是执行退栈操作,也就相
// 当于弹出了callee_save寄存器和压栈的那6个参数
add $0x60,%rsp
pop %rbp
// 方法返回,指令中的q表示64位操作数,就是指
// 的栈中存储的return address是64位的
retq
记得在之前 第3篇-CallStub新栈帧的创建时,通过如下的汇编完成了新栈帧的创建:
push %rbp
mov %rsp,%rbp
sub $0x60,%rsp
现在要退出这个栈帧时要在%rsp指向的地址加上$0x60,同时恢复%rbp的指向。然后就是跳转到return address指向的指令继续执行了。
为了方便大家查看,我再次给出了之前使用到的图片,这个图是退栈之前的图片:
退栈之后如下图所示。
至于paramter size与thread则由JavaCalls::call_hlper()函数负责释放,这是C/C++调用约定的一部分。所以如果不看这2个参数,我们已经完全回到了本篇给出的第一张图表示的栈的样子。
上面这些图片大家应该不陌生才对,我们在一步步创建栈帧时都给出过,现在怎么创建的就会怎么退出。
之前介绍过,当Java方法返回int类型时(如果返回char、boolean、short等类型时统一转换为int类型),根据Java方法调用约定,这个返回的int值会存储到%rax中;如果返回对象,那么%rax中存储的就是这个对象的地址,那后面到底怎么区分是地址还是int值呢?答案是通过返回类型区分即可;如果返回非int,非对象类型的值呢?我们继续看generate_call_stub()函数的实现逻辑:
// handle return types different from T_INT
__ BIND(is_long);
__ movq(Address(c_rarg0, 0), rax);
__ jmp(exit);
__ BIND(is_float);
__ movflt(Address(c_rarg0, 0), xmm0);
__ jmp(exit);
__ BIND(is_double);
__ movdbl(Address(c_rarg0, 0), xmm0);
__ jmp(exit);
对应的汇编代码如下:
// -- is_long --
mov %rax,(%rdi)
jmp 0x00007fdf450007d4
// -- is_float --
vmovss %xmm0,(%rdi)
jmp 0x00007fdf450007d4
// -- is_double --
vmovsd %xmm0,(%rdi)
jmp 0x00007fdf450007d4
当返回long类型时也存储到%rax中,因为Java的long类型是64位,我们分析的代码也是x86下64位的实现,所以%rax寄存器也是64位,能够容纳64位数;当返回为float或double时,存储到%xmm0中。
统合这一篇和前几篇文章,我们应该学习到C/C++的调用约定以及Java方法在解释执行下的调用约定(包括如何传递参数,如何接收返回值等),如果大家不明白,多读几遍文章就会有一个清晰的认识。
第6篇-Java方法新栈帧的创建
在第2篇-JVM虚拟机这样来调用Java主类的main()方法介绍JavaCalls::call_helper()函数的实现时提到过如下一句代码:
address entry_point = method->from_interpreted_entry();
这个参数会做为实参传递给StubRoutines::call_stub()函数指针指向的“函数”,然后在 第4篇-JVM终于开始调用Java主类的main()方法啦 介绍到通过callq指令调用entry_point,那么这个entry_point到底是什么呢?这一篇我们将详细介绍。
首先看from_interpreted_entry()函数实现,如下:
源代码位置:/openjdk/hotspot/src/share/vm/oops/method.hpp
volatile address from_interpreted_entry() const{
return (address)OrderAccess::load_ptr_acquire(&_from_interpreted_entry);
}
_from_interpreted_entry只是Method类中定义的一个属性,如上方法直接返回了这个属性的值。那么这个属性是何时赋值的?其实是在方法连接(也就是在类的生命周期中的类连接阶段会进行方法连接)时会设置。方法连接时会调用如下方法:
void Method::link_method(methodHandle h_method, TRAPS) {
// ...
address entry = Interpreter::entry_for_method(h_method);
// Sets both _i2i_entry and _from_interpreted_entry
set_interpreter_entry(entry);
// ...
}
首先调用Interpreter::entry_for_method()函数根据特定方法类型获取到方法的入口,得到入口entry后会调用set_interpreter_entry()函数将值保存到对应属性上。set_interpreter_entry()函数的实现非常简单,如下:
void set_interpreter_entry(address entry) {
_i2i_entry = entry;
_from_interpreted_entry = entry;
}
可以看到为_from_interpreted_entry属性设置了entry值。
下面看一下entry_for_method()函数的实现,如下:
static address entry_for_method(methodHandle m) {
return entry_for_kind(method_kind(m));
}
首先通过method_kind()函数拿到方法对应的类型,然后调用entry_for_kind()函数根据方法类型获取方法对应的入口entry_point。调用的entry_for_kind()函数的实现如下:
static address entry_for_kind(MethodKind k){
return _entry_table[k];
}
这里直接返回了_entry_table数组中对应方法类型的entry_point地址。
这里涉及到Java方法的类型MethodKind,由于要通过entry_point进入Java世界,执行Java方法相关的逻辑,所以entry_point中一定会为对应的Java方法建立新的栈帧,但是不同方法的栈帧其实是有差别的,如Java普通方法、Java同步方法、有native关键字的Java方法等,所以就把所有的方法进行了归类,不同类型获取到不同的entry_point入口。到底有哪些类型,我们可以看一下MethodKind这个枚举类中定义出的枚举常量:
enum MethodKind {
zerolocals, // 普通的方法
zerolocals_synchronized, // 普通的同步方法
native, // native方法
native_synchronized, // native同步方法
...
}
当然还有其它一些类型,不过最主要的就是如上枚举类中定义出的4种类型方法。
为了能尽快找到某个Java方法对应的entry_point入口,把这种对应关系保存到了_entry_table中,所以entry_for_kind()函数才能快速的获取到方法对应的entry_point入口。 给数组中元素赋值专门有个方法:
void AbstractInterpreter::set_entry_for_kind(AbstractInterpreter::MethodKind kind, address entry) {
_entry_table[kind] = entry;
}
那么何时会调用set_entry_for_kind()函数呢,答案就在TemplateInterpreterGenerator::generate_all()函数中,generate_all()函数会调用generate_method_entry()函数生成每种Java方法的entry_point,每生成一个对应方法类型的entry_point就保存到_entry_table中。
下面详细介绍一下generate_all()函数的实现逻辑,在HotSpot启动时就会调用这个函数生成各种Java方法的entry_point。调用栈如下:
TemplateInterpreterGenerator::generate_all() templateInterpreter.cpp
InterpreterGenerator::InterpreterGenerator() templateInterpreter_x86_64.cpp
TemplateInterpreter::initialize() templateInterpreter.cpp
interpreter_init() interpreter.cpp
init_globals() init.cpp
Threads::create_vm() thread.cpp
JNI_CreateJavaVM() jni.cpp
InitializeJVM() java.c
JavaMain() java.c
start_thread() pthread_create.c
调用的generate_all()函数将生成一系列HotSpot运行过程中所执行的一些公共代码的入口和所有字节码的InterpreterCodelet,一些非常重要的入口实现逻辑会在后面详细介绍,这里只看普通的、没有native关键字修饰的Java方法生成入口的逻辑。generate_all()函数中有如下实现:
#define method_entry(kind) \
{ \
CodeletMark cm(_masm, "method entry point (kind = " #kind ")"); \
Interpreter::_entry_table[Interpreter::kind] = generate_method_entry(Interpreter::kind); \
}
method_entry(zerolocals)
其中method_entry是一个宏,扩展后如上的method_entry(zerolocals)语句变为如下的形式:
Interpreter::_entry_table[Interpreter::zerolocals] = generate_method_entry(Interpreter::zerolocals);
_entry_table变量定义在AbstractInterpreter类中,如下:
static address _entry_table[number_of_method_entries];
number_of_method_entries表示方法类型的总数,使用方法类型做为数组下标就可以获取对应的方法入口。调用generate_method_entry()函数为各种类型的方法生成对应的方法入口。generate_method_entry()函数的实现如下:
address AbstractInterpreterGenerator::generate_method_entry(AbstractInterpreter::MethodKind kind) {
bool synchronized = false;
address entry_point = NULL;
InterpreterGenerator* ig_this = (InterpreterGenerator*)this;
// 根据方法类型kind生成不同的入口
switch (kind) {
// 表示普通方法类型
case Interpreter::zerolocals :
break;
// 表示普通的、同步方法类型
case Interpreter::zerolocals_synchronized:
synchronized = true;
break;
// ...
}
if (entry_point) {
return entry_point;
}
return ig_this->generate_normal_entry(synchronized);
}
zerolocals表示正常的Java方法调用,包括Java程序的main()方法,对于zerolocals来说,会调用ig_this->generate_normal_entry()函数生成入口。generate_normal_entry()函数会为执行的方法生成堆栈,而堆栈由局部变量表(用来存储传入的参数和被调用方法的局部变量)、Java方法栈帧数据和操作数栈这三大部分组成,所以entry_point例程(其实就是一段机器指令片段,英文名为stub)会创建这3部分来辅助Java方法的执行。
我们还是回到开篇介绍的知识点,通过callq指令调用entry_point例程。此时的栈帧状态在 第4篇-JVM终于开始调用Java主类的main()方法啦 中介绍过,为了大家阅读的方便,这里再次给出:
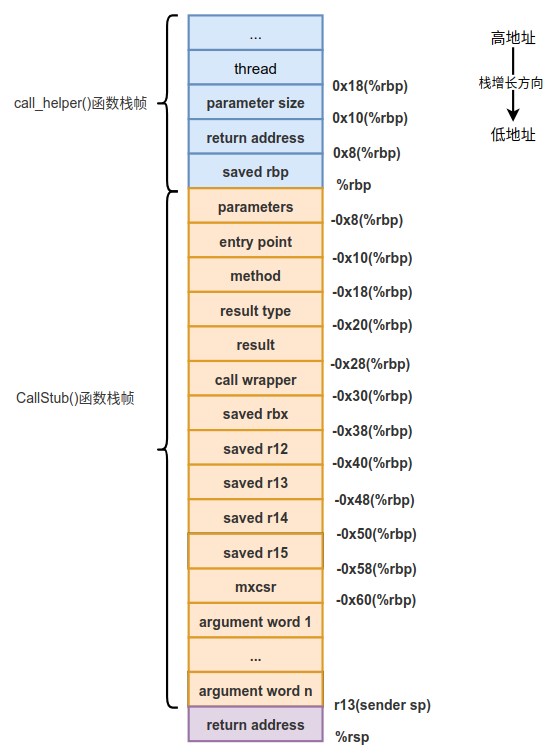
注意,在执行callq指令时,会将函数的返回地址存储到栈顶,所以上图中会压入return address一项。
CallStub()函数在通过callq指令调用generate_normal_entry()函数生成的entry_point时,有几个寄存器中存储着重要的值,如下:
rbx -> Method*
r13 -> sender sp
rsi -> entry point
下面就是分析generate_normal_entry()函数的实现逻辑了,这是调用Java方法的最重要的部分。函数的重要实现逻辑如下:
address InterpreterGenerator::generate_normal_entry(bool synchronized) {
// ...
// entry_point函数的代码入口地址
address entry_point = __ pc();
// 当前rbx中存储的是指向Method的指针,通过Method*找到ConstMethod*
const Address constMethod(rbx, Method::const_offset());
// 通过Method*找到AccessFlags
const Address access_flags(rbx, Method::access_flags_offset());
// 通过ConstMethod*得到parameter的大小
const Address size_of_parameters(rdx,ConstMethod::size_of_parameters_offset());
// 通过ConstMethod*得到local变量的大小
const Address size_of_locals(rdx, ConstMethod::size_of_locals_offset());
// 上面已经说明了获取各种方法元数据的计算方式,
// 但并没有执行计算,下面会生成对应的汇编来执行计算
// 计算ConstMethod*,保存在rdx里面
__ movptr(rdx, constMethod);
// 计算parameter大小,保存在rcx里面
__ load_unsigned_short(rcx, size_of_parameters);
// rbx:保存基址;rcx:保存循环变量;rdx:保存目标地址;rax:保存返回地址(下面用到)
// 此时的各个寄存器中的值如下:
// rbx: Method*
// rcx: size of parameters
// r13: sender_sp (could differ from sp+wordSize
// if we were called via c2i ) 即调用者的栈顶地址
// 计算local变量的大小,保存到rdx
__ load_unsigned_short(rdx, size_of_locals);
// 由于局部变量表用来存储传入的参数和被调用方法的局部变量,
// 所以rdx减去rcx后就是被调用方法的局部变量可使用的大小
__ subl(rdx, rcx);
// ...
// 返回地址是在CallStub中保存的,如果不弹出堆栈到rax,中间
// 会有个return address使的局部变量表不是连续的,
// 这会导致其中的局部变量计算方式不一致,所以暂时将返
// 回地址存储到rax中
__ pop(rax);
// 计算第1个参数的地址:当前栈顶地址 + 变量大小 * 8 - 一个字大小
// 注意,因为地址保存在低地址上,而堆栈是向低地址扩展的,所以只
// 需加n-1个变量大小就可以得到第1个参数的地址
__ lea(r14, Address(rsp, rcx, Address::times_8, -wordSize));
// 把函数的局部变量设置为0,也就是做初始化,防止之前遗留下的值影响
// rdx:被调用方法的局部变量可使用的大小
{
Label exit, loop;
__ testl(rdx, rdx);
// 如果rdx<=0,不做任何操作
__ jcc(Assembler::lessEqual, exit);
__ bind(loop);
// 初始化局部变量
__ push((int) NULL_WORD);
__ decrementl(rdx);
__ jcc(Assembler::greater, loop);
__ bind(exit);
}
// 生成固定桢
generate_fixed_frame(false);
// ... 省略统计及栈溢出等逻辑,后面会详细介绍
// 如果是同步方法时,还需要执行lock_method()函数,所以
// 会影响到栈帧布局
if (synchronized) {
// Allocate monitor and lock method
lock_method();
}
// 跳转到目标Java方法的第一条字节码指令,并执行其对应的机器指令
__ dispatch_next(vtos);
// ... 省略统计相关逻辑,后面会详细介绍
return entry_point;
}
这个函数的实现看起来比较多,但其实逻辑实现比较简单,就是根据被调用方法的实际情况创建出对应的局部变量表,然后就是2个非常重要的函数generate_fixed_frame()和dispatch_next()函数了,这2个函数我们后面再详细介绍。
在调用generate_fixed_frame()函数之前,栈的状态变为了下图所示的状态。
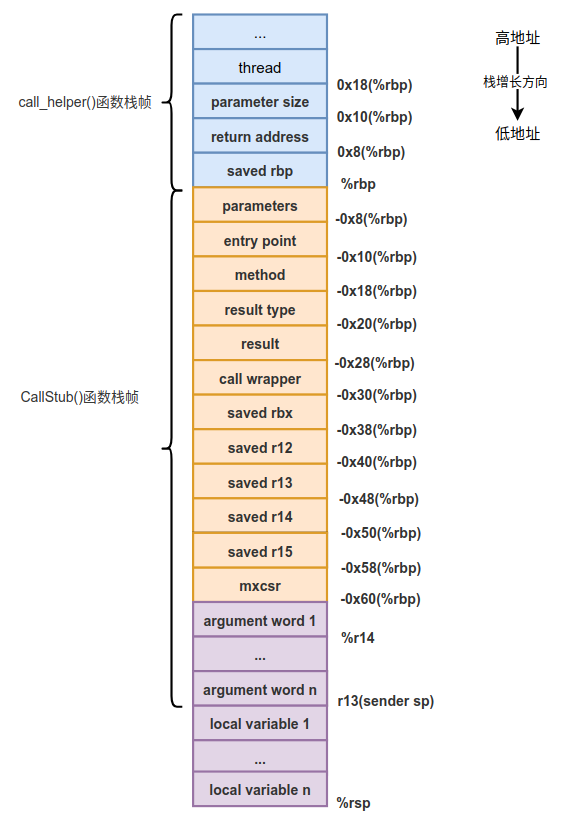
与前一个图对比一下,可以看到多了一些local variable 1 ... local variable n等slot,这些slot与argument word 1 ... argument word n共同构成了被调用的Java方法的局部变量表,也就是图中紫色的部分。其实local variable 1 ... local variable n等slot属于被调用的Java方法栈帧的一部分,而argument word 1 ... argument word n却属于CallStub()函数栈帧的一部分,这2部分共同构成局部变量表,专业术语叫栈帧重叠。
另外还能看出来,%r14指向了局部变量表的第1个参数,而CallStub()函数的return address被保存到了%rax中,另外%rbx中依然存储着Method*。这些寄存器中保存的值将在调用generate_fixed_frame()函数时用到,所以我们需要在这里强调一下。
第7篇-为Java方法创建栈帧
在第6篇-Java方法新栈帧的创建介绍过局部变量表的创建,创建完成后的栈帧状态如下图所示。
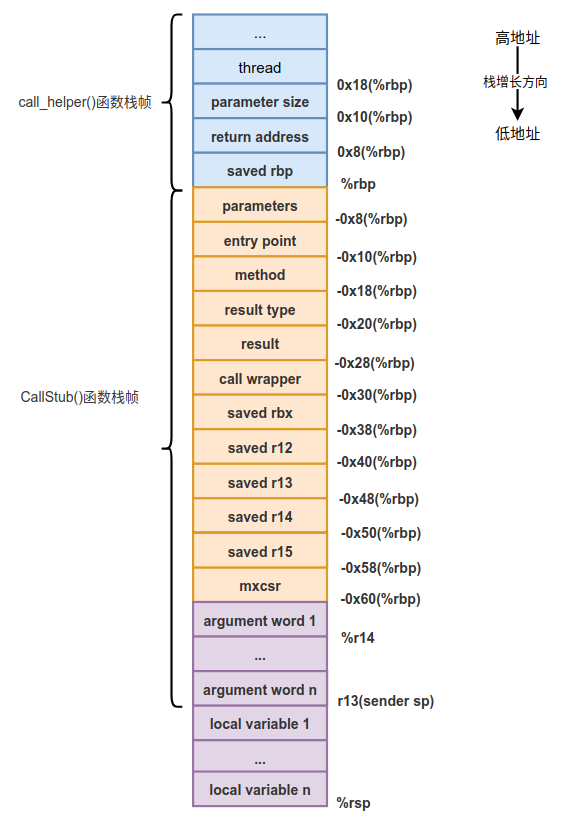
各个寄存器的状态如下所示。
// %rax寄存器中存储的是返回地址
rax: return address
// 要执行的Java方法的指针
rbx: Method*
// 本地变量表指针
r14: pointer to locals
// 调用者的栈顶
r13: sender sp
注意rax中保存的返回地址,因为在generate_call_stub()函数中通过__ call(c_rarg1) 语句调用了由generate_normal_entry()函数生成的entry_point,所以当entry_point执行完成后,还会返回到generate_call_stub()函数中继续执行__ call(c_rarg1) 语句下面的代码,也就是
第5篇-调用Java方法后弹出栈帧及处理返回结果涉及到的那些代码。
调用的generate_fixed_frame()函数的实现如下:
源代码位置:openjdk/hotspot/src/cpu/x86/vm/templateInterpreter_x86_64.cpp
void TemplateInterpreterGenerator::generate_fixed_frame(bool native_call) {
// 把返回地址紧接着局部变量区保存
__ push(rax);
// 为Java方法创建栈帧
__ enter();
// 保存调用者的栈顶地址
__ push(r13);
// 暂时将last_sp属性的值设置为NULL_WORD
__ push((int)NULL_WORD);
// 获取ConstMethod*并保存到r13中
__ movptr(r13, Address(rbx, Method::const_offset()));
// 保存Java方法字节码的地址到r13中
__ lea(r13, Address(r13, ConstMethod::codes_offset()));
// 保存Method*到堆栈上
__ push(rbx);
// ProfileInterpreter属性的默认值为true,
// 表示需要对解释执行的方法进行相关信息的统计
if (ProfileInterpreter) {
Label method_data_continue;
// MethodData结构基础是ProfileData,
// 记录函数运行状态下的数据
// MethodData里面分为3个部分,
// 一个是函数类型等运行相关统计数据,
// 一个是参数类型运行相关统计数据,
// 还有一个是extra扩展区保存着
// deoptimization的相关信息
// 获取Method中的_method_data属性的值并保存到rdx中
__ movptr(rdx, Address(rbx,
in_bytes(Method::method_data_offset())));
__ testptr(rdx, rdx);
__ jcc(Assembler::zero, method_data_continue);
// 执行到这里,说明_method_data已经进行了初始化,
// 通过MethodData来获取_data属性的值并存储到rdx中
__ addptr(rdx, in_bytes(MethodData::data_offset()));
__ bind(method_data_continue);
__ push(rdx);
} else {
__ push(0);
}
// 获取ConstMethod*存储到rdx
__ movptr(rdx, Address(rbx,
Method::const_offset()));
// 获取ConstantPool*存储到rdx
__ movptr(rdx, Address(rdx,
ConstMethod::constants_offset()));
// 获取ConstantPoolCache*并存储到rdx
__ movptr(rdx, Address(rdx,
ConstantPool::cache_offset_in_bytes()));
// 保存ConstantPoolCache*到堆栈上
__ push(rdx);
// 保存第1个参数的地址到堆栈上
__ push(r14);
if (native_call) {
// native方法调用时,不需要保存Java
// 方法的字节码地址,因为没有字节码
__ push(0);
} else {
// 保存Java方法字节码地址到堆栈上,
// 注意上面对r13寄存器的值进行了更改
__ push(r13);
}
// 预先保留一个slot,后面有大用处
__ push(0);
// 将栈底地址保存到这个slot上
__ movptr(Address(rsp, 0), rsp);
}
对于普通的Java方法来说,生成的汇编代码如下:
push %rax
push %rbp
mov %rsp,%rbp
push %r13
pushq $0x0
mov 0x10(%rbx),%r13
lea 0x30(%r13),%r13 // lea指令获取内存地址本身
push %rbx
mov 0x18(%rbx),%rdx
test %rdx,%rdx
je 0x00007fffed01b27d
add $0x90,%rdx
push %rdx
mov 0x10(%rbx),%rdx
mov 0x8(%rdx),%rdx
mov 0x18(%rdx),%rdx
push %rdx
push %r14
push %r13
pushq $0x0
mov %rsp,(%rsp)
汇编比较简单,这里不再多说。执行完如上的汇编后生成的栈帧状态如下图所示。
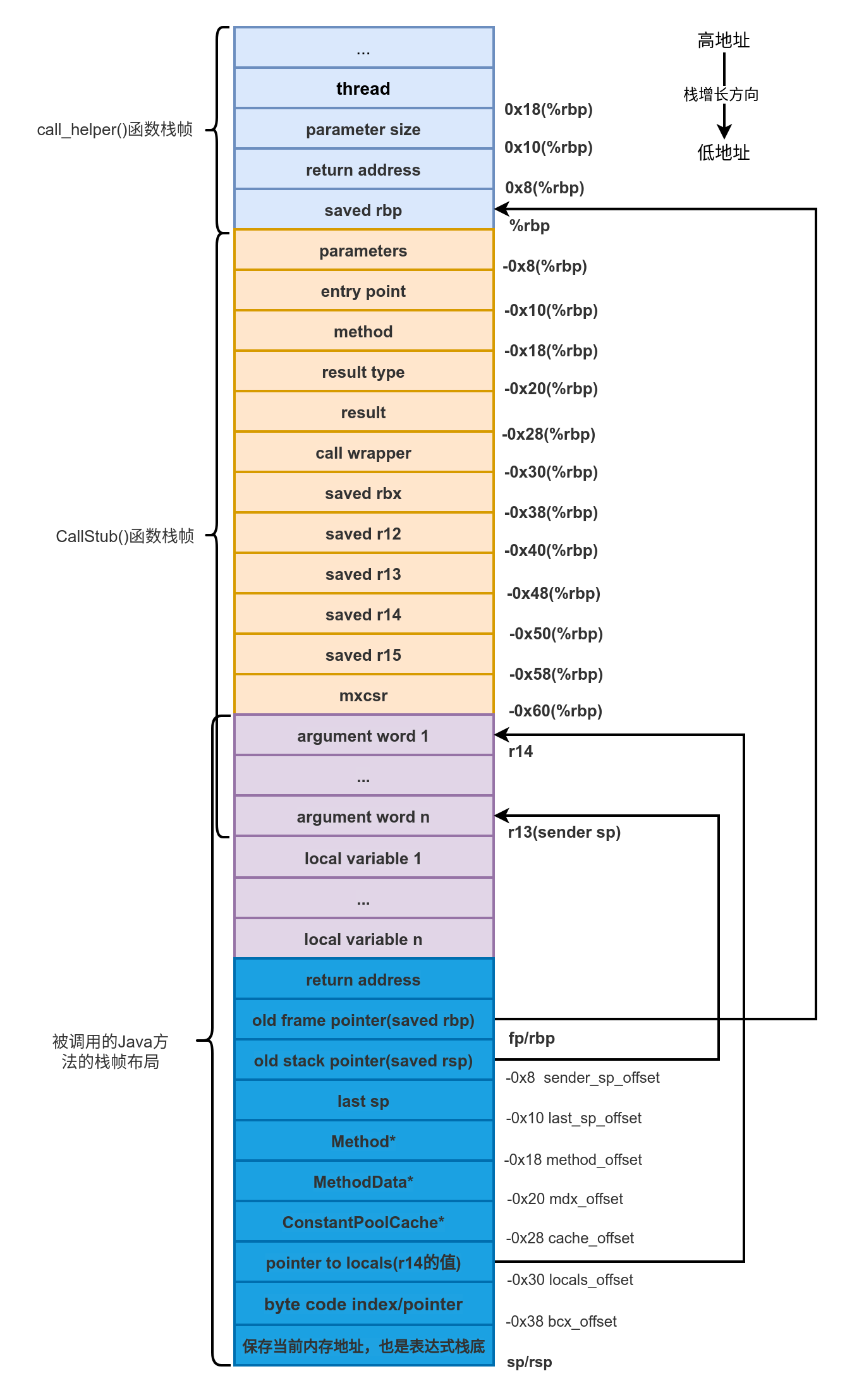
调用完generate_fixed_frame()函数后一些寄存器中保存的值如下:
rbx:Method*
ecx:invocation counter
r13:bcp(byte code pointer)
rdx:ConstantPool* 常量池的地址
r14:本地变量表第1个参数的地址
执行完generate_fixed_frame()函数后会继续返回执行InterpreterGenerator::generate_normal_entry()函数,如果是为同步方法生成机器码,那么还需要调用lock_method()函数,这个函数会改变当前栈帧的状态,添加同步所需要的一些信息,在后面介绍锁的实现时会详细介绍。
InterpreterGenerator::generate_normal_entry()函数最终会返回生成机器码的入口执行地址,然后通过变量_entry_table数组来保存,这样就可以使用方法类型做为数组下标获取对应的方法入口了。
第8篇-dispatch_next()函数分派字节码
在generate_normal_entry()函数中会调用generate_fixed_frame()函数为Java方法的执行生成对应的栈帧,接下来还会调用dispatch_next()函数执行Java方法的字节码。generate_normal_entry()函数调用的dispatch_next()函数之前一些寄存器中保存的值如下:
rbx:Method*
ecx:invocation counter
r13:bcp(byte code pointer)
rdx:ConstantPool* 常量池的地址
r14:本地变量表第1个参数的地址
dispatch_next()函数的实现如下:
// 从generate_fixed_frame()函数生成Java方法调用栈帧的时候,
// 如果当前是第一次调用,那么r13指向的是字节码的首地址,
// 即第一个字节码,此时的step参数为0
void InterpreterMacroAssembler::dispatch_next(TosState state, int step) {
load_unsigned_byte(rbx, Address(r13, step));
// 在当前字节码的位置,指针向前移动step宽度,
// 获取地址上的值,这个值是Opcode(范围1~202),存储到rbx
// step的值由字节码指令和它的操作数共同决定
// 自增r13供下一次字节码分派使用
increment(r13, step);
// 返回当前栈顶状态的所有字节码入口点
dispatch_base(state, Interpreter::dispatch_table(state));
}
r13指向字节码的首地址,当第1次调用时,参数step的值为0,那么load_unsigned_byte()函数从r13指向的内存中取一个字节的值,取出来的是字节码指令的操作码。增加r13的步长,这样下次执行时就会取出来下一个字节码指令的操作码。
调用的dispatch_table()函数的实现如下:
static address* dispatch_table(TosState state) {
return _active_table.table_for(state);
}
在_active_table中获取对应栈顶缓存状态的入口地址,_active_table变量定义在TemplateInterpreter类中,如下:
static DispatchTable _active_table;
DispatchTable类及table_for()等函数的定义如下:
DispatchTable TemplateInterpreter::_active_table;
class DispatchTable VALUE_OBJ_CLASS_SPEC {
public:
enum {
length = 1 << BitsPerByte
}; // BitsPerByte的值为8
private:
// number_of_states=9,length=256
// _table是字节码分发表
address _table[number_of_states][length];
public:
// ...
address* table_for(TosState state){
return _table[state];
}
address* table_for(){
return table_for((TosState)0);
}
// ...
};
address为u_char*类型的别名。_table是一个二维数组的表,维度为栈顶状态(共有9种)和字节码(最多有256个),存储的是每个栈顶状态对应的字节码的入口点。这里由于还没有介绍栈顶缓存,所以理解起来并不容易,不过后面会详细介绍栈顶缓存和字节码分发表的相关内容,等介绍完了再看这部分逻辑就比较容易理解了。
InterpreterMacroAssembler::dispatch_next()函数中调用的dispatch_base()函数的实现如下:
void InterpreterMacroAssembler::dispatch_base(
TosState state, // 表示栈顶缓存状态
address* table,
bool verifyoop
) {
// ...
// 获取当前栈顶状态字节码转发表的地址,保存到rscratch1
lea(rscratch1, ExternalAddress((address)table));
// 跳转到字节码对应的入口执行机器码指令
// address = rscratch1 + rbx * 8
jmp(Address(rscratch1, rbx, Address::times_8));
}
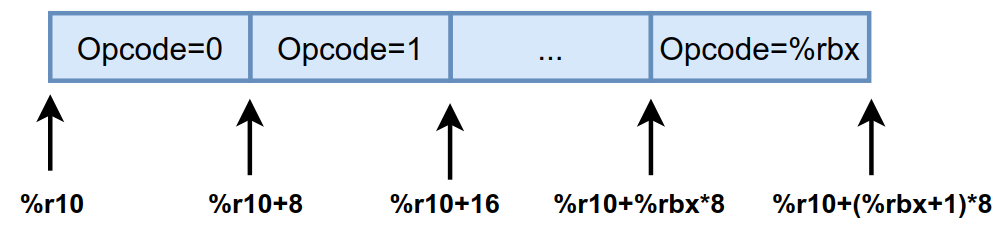
比如取一个字节大小的指令(如iconst_0、aload_0等都是一个字节大小的指令),那么InterpreterMacroAssembler::dispatch_next()函数生成的汇编代码如下 :
// 在generate_fixed_frame()函数中
// 已经让%r13存储了bcp
// %ebx中存储的是字节码的Opcode,也就是操作码
movzbl 0x0(%r13),%ebx
// $0x7ffff73ba4a0这个地址指向的
// 是对应state状态下的一维数组,长度为256
movabs $0x7ffff73ba4a0,%r10
// 注意%r10中存储的是常量,根据计算公式
// %r10+%rbx*8来获取指向存储入口地址的地址,
// 通过*(%r10+%rbx*8)获取到入口地址,
// 然后跳转到入口地址执行
jmpq *(%r10,%rbx,8)
%r10指向的是对应栈顶缓存状态state下的一维数组,长度为256,其中存储的值为opcode,如下图所示。
下面的函数显示了对每个字节码的每个栈顶状态都设置入口地址。
void DispatchTable::set_entry(int i, EntryPoint& entry) {
assert(0 <= i && i < length, "index out of bounds");
assert(number_of_states == 9, "check the code below");
_table[btos][i] = entry.entry(btos);
_table[ctos][i] = entry.entry(ctos);
_table[stos][i] = entry.entry(stos);
_table[atos][i] = entry.entry(atos);
_table[itos][i] = entry.entry(itos);
_table[ltos][i] = entry.entry(ltos);
_table[ftos][i] = entry.entry(ftos);
_table[dtos][i] = entry.entry(dtos);
_table[vtos][i] = entry.entry(vtos);
}
其中的参数i就是opcode,各个字节码及对应的opcode可参考https://docs.oracle.com/javase/specs/jvms/se8/html/index.html。
所以_table表如下图所示。
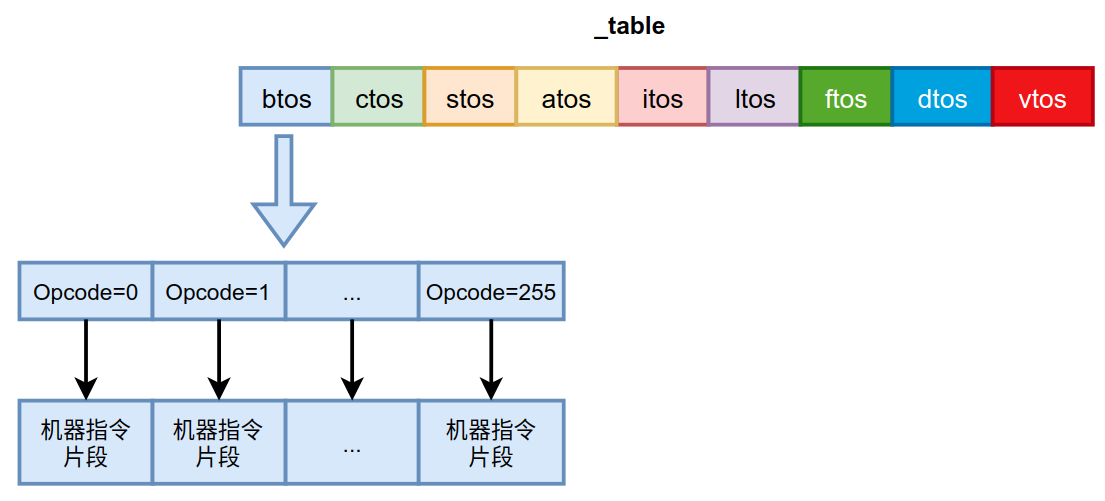
_table的一维为栈顶缓存状态,二维为Opcode,通过这2个维度能够找到一段机器指令,这就是根据当前的栈顶缓存状态定位到的字节码需要执行的机器指令片段。
调用dispatch_next()函数执行Java方法的字节码,其实就是根据字节码找到对应的机器指令片段的入口地址来执行,这段机器码就是根据对应的字节码语义翻译过来的,这些都会在后面详细介绍。
公众号【深入剖析Java虚拟机HotSpot】已经更新虚拟机源代码剖析相关文章到60+,欢迎关注,如果有任何问题,可加作者微信mazhimazh,拉你入虚拟机群交流。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号