
BUAAOO_第三单元总结与反思
BUAAOO_第三单元总结与反思
题目简要回顾:模拟社交关系网络
第一次作业(建立模型)
第二次作业(添加分组、消息发送相关功能)
第三次作业(添加区分不同类型消息相关功能)
一、架构介绍
本单元作业的特殊性在于,架构已由JML规格确定,包括类与其中包括的方法,以及各调用关系,三次作业完全满足迭代关系,因此在此直接介绍第三次作业的架构。
类介绍:
普通类:
MainClass:主类,用于启动程序、调用Runner类;
Runner:程序外部运行类,用于调用根据接口构造的各类(官方包提供,非笔者实现);
MyPerson:社交关系中每个个体的抽象,包含各种属性;
MyNetWork:社交网络抽象,存储了已添加的Person对象、已添加的Group对象、已添加的Message对象,已添加的emoji等属性;
MyGroup:群组抽象,存储了群组中包含的Person对象等属性;
MyMessage:信息抽象,包含各种属性;
MyEmojiMessage:emoji信息抽象,是一种信息类型,除基本属性还外包含了其emoji的编号属性;
MyNoticeMessaege:通知信息抽象,是一种信息类型,除基本属性外还包含了其信息的字符串内容属性;
MyRedEnvelopMessage:红包信息抽象,是一种信息类型,除基本属性外还包含了红包钱数属性。异常类:
未找到id异常:
MyPersonIdNotFoundException、MyMessageIdNotFoundException、MyGroupIdNotFoundException、MyEmojiNotFoundException、MyRelationNotFoundException;找到相同id异常:
MyEqualPersonIdException、MyEqualMessageIdException、MyEqualGroupIdException、MyEqualEmojiIdException、MyEqualRelationExeption。
架构设计:
UML图:(不考虑异常类)
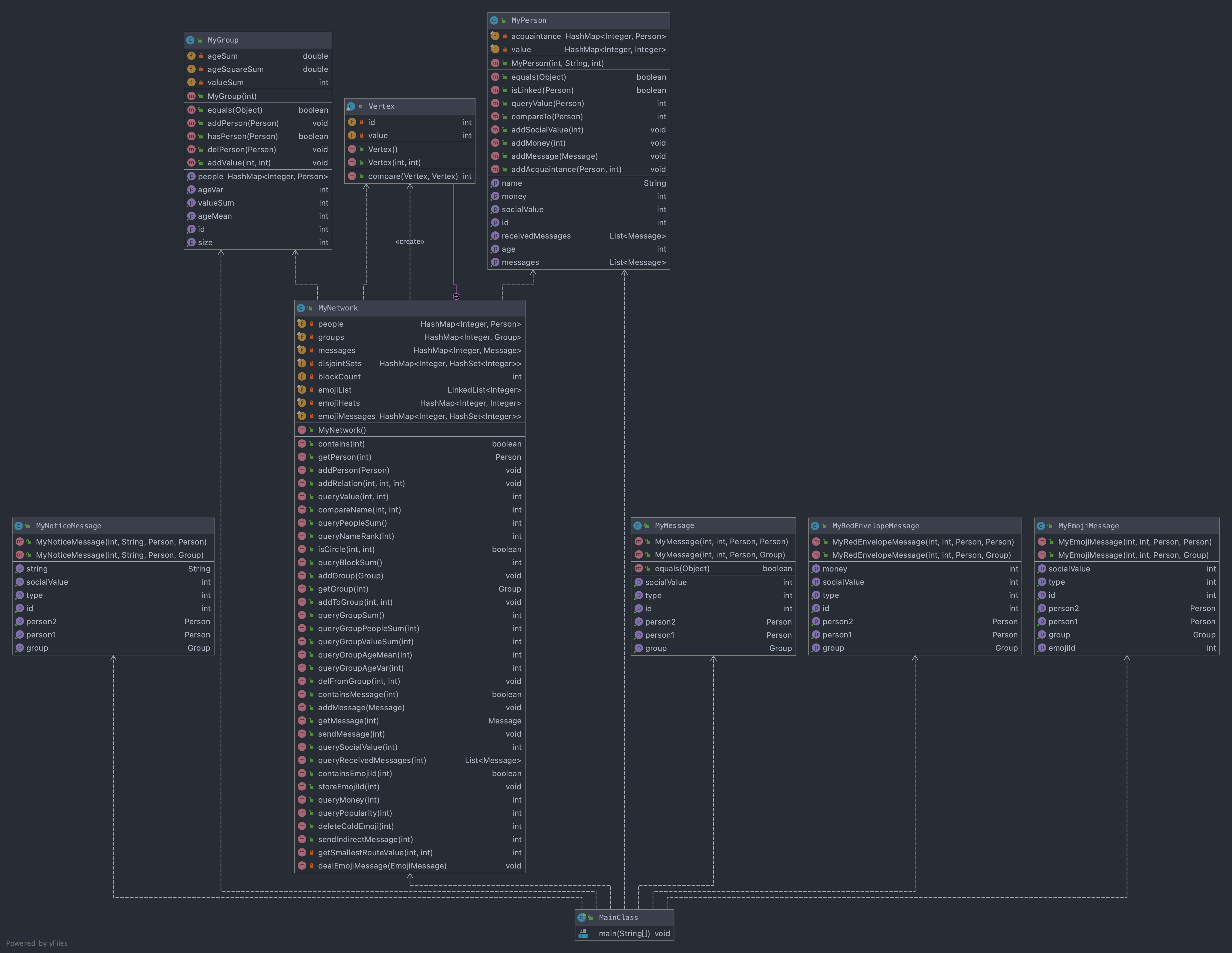
图构建:
-
基本思路:
NetWork类中保存了全部已添加Person对象的信息,每个Persno对象中包含acquaintance域存储与其相关联的Person对象信息,如此构成图网络。 -
维护思路:按JML规格添加异常抛出;在添加非规格内的方法时,要注意其调用链,观察链中是否有异常抛出以保证数据稳定。
核心算法:
本单元一个核心点在于在保证正确性的基础上,对算法效率、程序性能进行最大程度优化,核心主要体现在以下四个位置:
-
查询方法的耗时:
-
问题:对于
pure方法(即查询方法),每次查询均需要对某些容器进行遍历、计算等操作,当查询操作多次重复时很容易浪费大量时间; -
解决:采用牺牲空间拯救时间的思路,在类中增加可以直接或间接计算该属性的域,在将容器中增加或删除元素并可能导致所查询属性的改变时,对添加域进行更改,使查询时仅进行简单计算即可,达到性能优化的目的。
-
举例:
-
Group中的getAgeMean()方法:该方法查询当前该Group对象中所有Person对象的年龄平均值。若每次都遍历求值,在多次查询时会造成无意义的时间浪费。然而平均值无法直接累加,因此增加年龄和
ageSum域,在每次调用addPerson()方法增加Person对象时对其进行累加、调用delPerson()方法删除Person对象时对其做减法;查询时结合size间接计算每次的平均值,则不需要每次进行遍历。private double ageSum; public int getAgeMean() { if (getSize() == 0) { return 0; } return (int) (ageSum / getSize()); } -
Group中的getAgeVar()方法:该方法查询当前该Group对象中所有Person对象年龄的方差。若每次都遍历求值,在多次查询时会造成无意义的时间浪费。然而方差无法直接累加,因此对方差公式进行展开$S=\frac{\sum(x_i-\overline x)2}{n}=\frac{\sum{x_i}2-2\overline x\sum x_i+n{\overline x}^2}{n}$,可以通过增加可累加域
ageSquareSum间接求得方差,原理同getAgeMean()。private double ageSquareSum; public int getAgeVar() { if (getSize() == 0) { return 0; } double ageMean = getAgeMean(); return (int) (ageSquareSum - 2 * ageMean * ageSum + ageMean * ageMean * getSize()) / getSize(); }
-
-
-
容器的选择使用:
本单元作业容器的选择分为以下三种情况:
-
HashMap:对于查询和增删操作较多、遍历较少的大部分数据结构,采取HashMap容器,其中键值为id,内容为id对应对象。例如NetWork类中的people域。 -
LinkedList:对于(在特定位置)增删特征明显的数据结构,采用了LinkedList容器。例如Person类中的messages域与表示最新的四条信息的receivedMessages域,本类中仅存在增删操作,不存在查询操作,且信息新旧需要有序(因而采取按序在特定位置插入删除的方式):在新加入信息时,将新信息插入链表头,同时receivedMessage如果长度大于4则删除尾节点(即最老的信息)。 -
HashSet:对于查询和增删操作较多、遍历较少的无序数据结构,采取HashSet容器。例如NetWork中服务于并查集算法的disjointSets容器(详见后并查集算法描述)。 -
不同容器的综合运用:有多种不同操作时,采用牺牲空间拯救时间的思路,设立多个容器综合管理,使性能最优化。
例子:
NetWork中的emoji管理若仅考虑功能实现,仅设置
HashMap<Integer, Integer> emojiHeatList一个容器即可完成。但
deleteColdEmoji()方法首先需要对已存在的emojiId进行遍历,而HashMap容器遍历查询操作效率较低,但同时要兼顾从容器中添加、删除emojiId的效率,因此不选择增删操作较慢的ArrayList,添加LinkedList<Integer> emojiList域辅助。但
deleteColdEmoji()方法同时要对存在被删除emojiId的Message对象进行删除。为避免对messages进行遍历,增加HashMap<Integer, HashSet<Integer>> emojiMessages域,键值为emojiId,内容为该emojiId所对应的Message对象的id集合。这样在获得coldEmoji后,则无需遍历messages,直接获得了所有包含该emojiId的messageId并在messages中删除(HashMap按键值删除快)。综上,
deleteColdEmoji()实现如下:public int deleteColdEmoji(int limit) { // 效率与正确性的问题 Iterator<Integer> it = emojiList.iterator(); while (it.hasNext()) { int emojiId = it.next(); if (emojiHeats.get(emojiId) < limit) { emojiHeats.remove(emojiId); for (Integer messageId : emojiMessages.get(emojiId)) { messages.remove(messageId); } emojiMessages.remove(emojiId); it.remove(); } } return emojiHeats.size(); }同时注意在其他可能更改这三个域内容的方法(如
addMessage()、storeEmojiId()等)中,要对三者进行更改。
-
-
查询是否存在路径:并查集算法
isCircle()方法查询社交网络中两人是否存在关联,即图中两节点间是否存在路径。采取与前述类似的思想,空间换取时间,避免多次查询造成的时间浪费,选择了并查集算法。并查集算法思想描述:每个节点都会出现在一个内部元素互相关联的节点集合中,因此节点间存在路径与节点是否在一个集合中是等价的。
因此在实现中,笔者添加了
HashMap<Integer, HashSet<Integer>> disjointSets域,键值为Person对象的id,内容为其对应的与之存在路径的节点集合;isCircle()方法中只需要查询两节点是否在同一个集合中即可:public boolean isCircle(int id1, int id2) throws PersonIdNotFoundException { if (!contains(id1)) { throw new MyPersonIdNotFoundException(id1); } if (!contains(id2)) { throw new MyPersonIdNotFoundException(id2); } // 检查是否有路径,检查是否在同一个集合中即可 return disjointSets.get(id1).equals(disjointSets.get(id2)); }该实现的核心在于添加关系与
Person对象时对disjointSets的操作。-
添加
Person对象addPerson()时:此时刚刚添加新的Person对象,尚未添加任何该新对象的关系,因此该对象孤立,所在集合仅有其一个元素,因而在HashMap添加该键值,设置其对应内容为仅有其一个元素的new HashSet<>()。disjointSets.put(person.getId(), new HashSet<Integer>() {{ add(person.getId()); }}); blockCount++; -
添加关系
addRelation()时:此时保证添加关系的两个Person对象已存在,二者对应的集合也已存在;如果二者对应集合相同,则无需更新;如果二者对应集合不同,则需要将两集合中所有元素合并为一个新的集合,并将该集合中的所有元素作为键值对应的集合设置为新内容。if (!disjointSets.get(id1).equals(disjointSets.get(id2))) { // 合并并查集 disjointSets.get(id1).addAll(disjointSets.get(id2)); HashSet<Integer> tmp = disjointSets.get(id2); for (Integer id : tmp) { disjointSets.put(id, disjointSets.get(id1)); } blockCount--; }其中
blockCount域用于存储孤立集合个数,供queryBlockSum()查询。
-
-
查询最短权值路径:
Dijkstra算法MyNetWork()中的sendIndirectMessage()方法需要返回两节点间权值最短路径的权值和,采用经典的Dijkstra算法:private int getSmallestRouteValue(int src, int dst) { HashSet<Integer> set = disjointSets.get(src); PriorityQueue<Vertex> priorityQueue = new PriorityQueue<>(new Vertex()); priorityQueue.add(new Vertex(src, 0)); HashMap<Integer, Integer> visited = new HashMap<>(); // initial for (Integer id : set) { visited.put(id, 0); } while (!priorityQueue.isEmpty()) { Vertex ver = priorityQueue.poll(); if (ver.id == dst) { return ver.value; } if (visited.get(ver.id) == 0) { visited.put(ver.id, -1); for (Integer id : set) { if (getPerson(ver.id).isLinked(getPerson(id)) && visited.get(id) == 0) { priorityQueue.add(new Vertex(id, ver.value + getPerson(ver.id).queryValue(getPerson(id)))); } } } } return -1; } static class Vertex implements Comparator<Vertex> { private int id; private int value; public Vertex(){} public Vertex(int id, int value) { this.id = id; this.value = value; } @Override public int compare(Vertex vertex1, Vertex vertex2) { return vertex1.value - vertex2.value; } }此处采用了
PriorityQueue容器实现,其底层实现为堆,适合于Dijksra算法中的操作需求。
二、bug分析
第一次作业
由于对时间性能的把握还好,第一次作业并未产生TLE,但存在WA:
Bug1:在前述并查集算法中,合并并查集时仅对二者中对应的集合进行了更新,忽略了两个键值对应集合中其他元素作为键值对应的集合更新,导致错误。(因为合并集合后集合中所有元素相互之间都是存在路径的,因此要对所有节点都进行更新)
原代码:
if (!disjointSets.get(id1).equals(disjointSets.get(id2))) {
// 合并并查集(注:包含相同元素的集合均为共享对象)
disjointSets.get(id1).addAll(disjointSets.get(id2));
disjointSets.put(id2, disjointSets.get(id1));
// 只更新了两个节点,错误
blockCount--;
}
正确代码见前并查集算法部分。
第二次作业
第二次作业同样未产生TLE,但存在较多细节疏忽导致全WA爆零:
Bug1:求方差时整型非整形转换存在丢失精度问题
原代码:
private int ageSum;
private int ageSquareSum;
public int getAgeMean() {
return ageSum / size;
}
public int getAgeVar() {
int ageMean = getAgeMean();
return (ageSquareSum - 2 * ageMean * ageSum) / size + ageMean * ageMean;
}
ageSquareSum - 2 * ageMean * ageSum部分在于size做除法时单独丢失精度,与ageMean * ageMean不同时丢失精度,导致结果存在正负1的误差。
现代码:
private double ageSum;
private double ageSquareSum;
public int getAgeMean() {
return (int) (ageSum / size);
}
public int getAgeVar() {
double ageMean = getAgeMean();
return (int) (ageSquareSum - 2 * ageMean * ageSum + ageMean * ageMean * size) / size;
}
统一用高精度计算,最后除以size时统一取整,则满足JML中描述的计算规则。
Bug2:Group类中delPerson()方法对age相关变量做减法时,减成了person.getId(),属笔误。
Bug3:JML规格阅读不周(JML规格本身也有误并未描述另一种情况),导致忽略了getAgeMean()方法中size为0时返回0的情况,导致除以0,出现re错误。
Bug4:未考虑先将Person对象加入group中,后添加已在Group对象中的Person对象关系对Group对象中valueSum的改变:
为性能优化,原本采用了在向Group对象中添加Person对象时进行遍历、更新全部关系值的总和,避免重复查询低性能的方法,但忽视了后添加关系对Group对象内部该域值的更新。
修正:在NetWork类中添加关系时,对二者均存在的Group对象中的valueSum进行累加。
// in NetWork
public void addRelation(int id1, int id2, int value) throws PersonIdNotFoundException, EqualRelationException {
// ...
for (Integer id : groups.keySet()) {
MyGroup group = (MyGroup) getGroup(id);
if (group.hasPerson(getPerson(id1)) && getGroup(id).hasPerson(getPerson(id2))) {
group.addValue(id1, id2);
}
}
}
// in Group
public void addValue(int id1, int id2) {
valueSum += people.get(id1).queryValue(people.get(id2));
}
Bug5:JML规格中要求NeyWork类中的addToGroup()方法中,当Group对象中的Person对象数量大于1111时不进行任何操作。原代码中对于该数量的判断判断成了groups的size大于1111时而非group自身的size大于1111时不进行任何操作,属笔误。
Bug6:JML规格理解有误,getValueSum()方法中对于valueSum要求每对关系的双方都要计算一次,而非仅计算一次。将返回值乘2即可。
第三次作业
未出现WA,存在一个TLE,存在还可以进行性能优化的位置。
三、发现别人bug采取的策略
本单元一个典型bug是tle,因此尝试数据量较大的测试点,特别是需要有重复多次的查询操作,是一个时间卡点。
四、心得体会
本单元核心在于JML规格阅读理解,并在其基础上进行代码实现。JML本身是为工程化而生的代码编写规格,可以作为需求提供给程序员实现需求,架构是给定的,但内部算法实现、与数据管理等则由程序员自己决定。本单元作业结束后,笔者对于JML的意义有了更深刻的理解、也能熟练阅读、撰写JML规格了。
另一方面,JML中着重强调的异常处理也是令人印象颇深的一处。为使程序稳定、维护数据安全所添加的各类异常若想考虑周到,也并非一件容易的事情;添加新方法时也同样要注意方法调用链中是否对不同异常进行了保护。异常处理是工程化编程的关键一环。
最后,是本单元最容易产生令人头疼问题的一点——性能问题。java面向对象程序中的性能问题与面向过程编程中的性能问题样貌不同:后者只有通过对最底层算法的优化提升性能,而前者则不仅在于算法的选择,还有对于查询方法的优化(空间换取时间的思想在这里有明显的体现)、与java已经用最优算法封装好的容器的选择(需要按需选择)等等,优化过程不仅涉及底层算法,更是包括高层抽象的性能提升,需要从局部中脱离出来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号