
BUAAOO_第一单元总结与反思
题目简要回顾:
设定的形式化表述,final version:
表达式 → 空白项 [加减 空白项] 项 空白项 | 表达式 加减 空白项 项 空白项
项 → [加减 空白项] 因子 | 项 空白项 * 空白项 因子
因子 → 变量因子 | 常数因子 | 表达式因子
变量因子 → 幂函数 | 三角函数
常数因子 → 带符号的整数
表达式因子 → '(' 表达式 ')'
三角函数 → sin 空白项 '(' 空白项 因子 空白项 ')' [空白项 指数] | cos 空白项 '(' 空白项 因子 空白项 ')' [空白项 指数]
幂函数 → x [空白项 指数]
指数 → ** 空白项 带符号的整数
带符号的整数 → [加减] 允许前导零的整数
允许前导零的整数 → (0|1|2|…|9){0|1|2|…|9}
空白字符 → (空格) | \t(水平制表符)
空白项 → {空白字符}
加减 → + | -
笔者代码架构分析
1. 架构介绍
本单元在三次作业中采取了统一的设计架构,并没有进行重构,因此做统一分析。
-
类个数:16,统计数据如图所示:
![]()
继承关系如图所示:
![]()
A. 构造逻辑
根据表达式自身的物理属性,首先建立表达式类
Expression;表达式由项相加而得,从而建立项类
Term,由ArrayList<Term>构成Expression类的主要成员;项由因子相乘而得,从而建立抽象因子类
Factor,由Map<MapIndex, Factor>构成Term类的主要成员;Factor分为幂函数、正弦三角函数、余弦三角函数、表达式四种,再将系数作为常量提出,因而继承Factor的包括Constant、PowerFunc、SineFunc、CosineFunc、Expression五个子类。MapIndex类用于对项类Map结构的索引进行生成、处理。FactorFactory类使用工厂模式对因子类进行实例化。B. 字符串处理
FormatChecker类用于在取缔空格前对输入字符串进行合法性检查;SymbolSequence类用于对叠加的正负号进行处理;StringSpliter类用于拆分特定规则下,给定字符串的最外层项,分为以下三类:ToTerm:根据最外层的“+”进行分割,获得最外层各项;
ToFactors:根据最外层的“*”进行分割,获得最外层各因子;
ToSmaller:根据最外层的“**”进行分割,获得最外层底数与指数;
C. 异常处理
ExponentTooLargeExp、IllegalFormatExp为异常类,处理建造对象过程中指数过大与非法格式的异常。2. 基于度量的程序结构分析
(采用插件MetricsReload)由于三次作业采取相同架构,下以第三次作业为例:
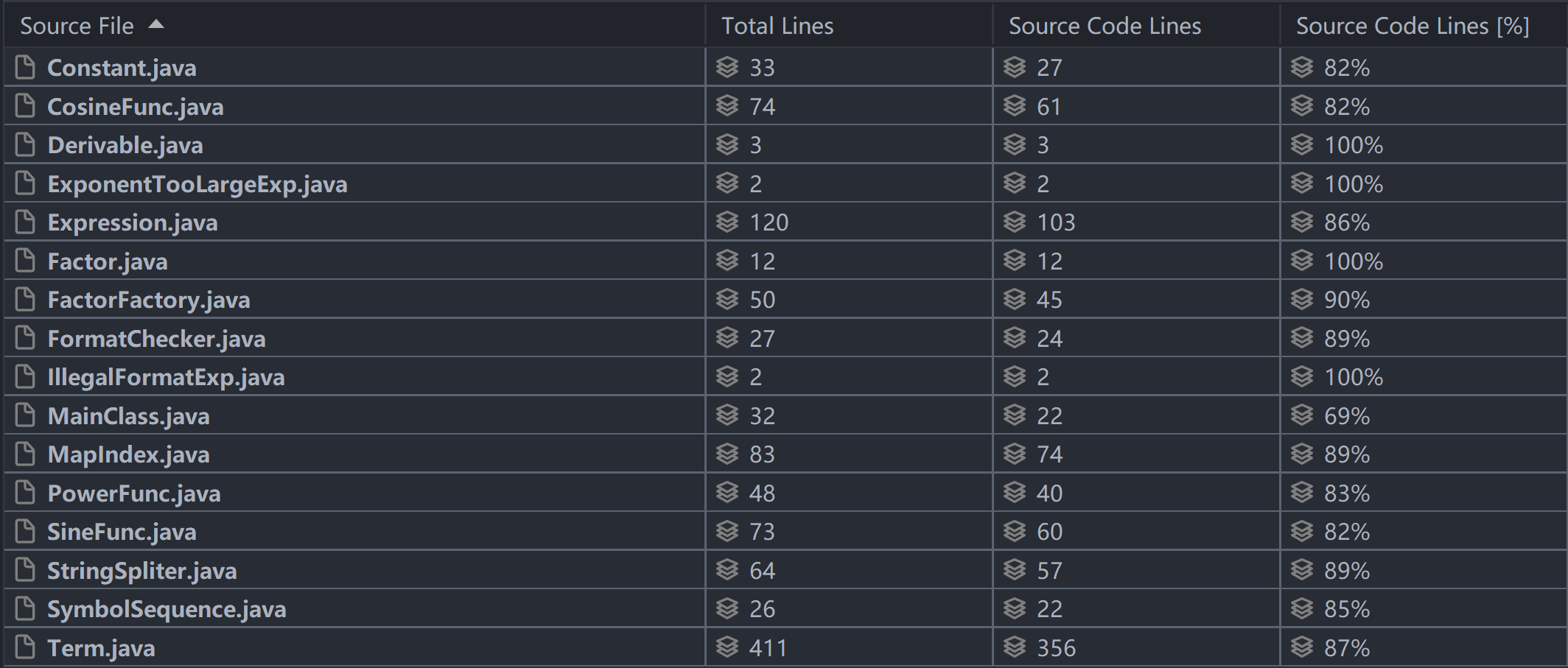

| Complexity metrics | ||||
|---|---|---|---|---|
| Method | CogC | ev(G) | iv(G) | v(G) |
| Constant.Constant(BigInteger) | 0 | 1 | 1 | 1 |
| Constant.clone() | 0 | 1 | 1 | 1 |
| Constant.getDerivative() | 0 | 1 | 1 | 1 |
| Constant.getValue() | 0 | 1 | 1 | 1 |
| Constant.multiply(Factor) | 2 | 2 | 2 | 2 |
| CosineFunc.CosineFunc(Factor,BigInteger) | 0 | 1 | 1 | 1 |
| CosineFunc.CosineFunc(String,BigInteger) | 1 | 1 | 2 | 2 |
| CosineFunc.clone() | 0 | 1 | 1 | 1 |
| CosineFunc.getDerivative() | 0 | 1 | 1 | 1 |
| CosineFunc.getExp() | 0 | 1 | 1 | 1 |
| CosineFunc.getFactor() | 0 | 1 | 1 | 1 |
| CosineFunc.multiply(Factor) | 3 | 2 | 3 | 3 |
| CosineFunc.toString() | 6 | 5 | 5 | 6 |
| Expression.Expression(Map<MapIndex, Term>) | 1 | 1 | 2 | 2 |
| Expression.Expression(String) | 3 | 1 | 3 | 3 |
| Expression.clone() | 1 | 1 | 2 | 2 |
| Expression.compareTo(Expression) | 2 | 3 | 1 | 3 |
| Expression.getDerivative() | 3 | 1 | 3 | 3 |
| Expression.getExpression() | 0 | 1 | 1 | 1 |
| Expression.multiply(Factor) | 1 | 1 | 2 | 2 |
| Expression.toString() | 7 | 3 | 5 | 6 |
| Factor.clone() | 1 | 1 | 2 | 2 |
| FactorFactory.getFactor(String) | 23 | 10 | 10 | 14 |
| FormatChecker.check(String) | 3 | 3 | 1 | 8 |
| MainClass.main(String[]) | 2 | 1 | 3 | 3 |
| MapIndex.MapIndex(List<Factor>,List<Factor>,List<Factor>,List<List<Factor>>) | 3 | 1 | 4 | 4 |
| MapIndex.compareTo(MapIndex) | 14 | 12 | 4 | 12 |
| PowerFunc.PowerFunc(BigInteger) | 0 | 1 | 1 | 1 |
| PowerFunc.clone() | 0 | 1 | 1 | 1 |
| PowerFunc.getDerivative() | 2 | 2 | 2 | 2 |
| PowerFunc.getExp() | 0 | 1 | 1 | 1 |
| PowerFunc.multiply(Factor) | 2 | 2 | 2 | 2 |
| PowerFunc.setExp(BigInteger) | 0 | 1 | 1 | 1 |
| PowerFunc.toString() | 2 | 3 | 1 | 3 |
| SineFunc.SineFunc(Factor,BigInteger) | 0 | 1 | 1 | 1 |
| SineFunc.SineFunc(String,BigInteger) | 1 | 1 | 2 | 2 |
| SineFunc.clone() | 0 | 1 | 1 | 1 |
| SineFunc.getDerivative() | 0 | 1 | 1 | 1 |
| SineFunc.getExp() | 0 | 1 | 1 | 1 |
| SineFunc.getFactor() | 0 | 1 | 1 | 1 |
| SineFunc.multiply(Factor) | 3 | 2 | 3 | 3 |
| SineFunc.toString() | 6 | 5 | 5 | 6 |
| StringSpliter.split(String,String) | 27 | 1 | 19 | 24 |
| SymbolSequence.SymbolSequence(String) | 0 | 1 | 1 | 1 |
| SymbolSequence.getNegCount() | 3 | 1 | 1 | 3 |
| SymbolSequence.getSymbols() | 0 | 1 | 1 | 1 |
| SymbolSequence.toPrefix() | 1 | 1 | 1 | 2 |
| Term.Term(Factor,Factor,List<Factor>,List<Factor>,List<Factor>) | 1 | 1 | 2 | 2 |
| Term.Term(String) | 29 | 10 | 14 | 14 |
| Term.clone() | 4 | 1 | 4 | 4 |
| Term.getCoe() | 0 | 1 | 1 | 1 |
| Term.getDerivative() | 54 | 7 | 16 | 16 |
| Term.getMapIndex() | 0 | 1 | 1 | 1 |
| Term.haveNoBehind(int) | 6 | 5 | 3 | 13 |
| Term.multiply(Factor) | 13 | 6 | 9 | 9 |
| Term.setCoe(Factor) | 0 | 1 | 1 | 1 |
| Term.toString() | 38 | 8 | 18 | 19 |
-
可以看到,Term.getDerivative方法认知复杂度是过高的,是完全的面向过程编程思维,该求导方法设计的复杂性主要是取决于程序整体的核心架构设计问题,笔者会在后文提到;
-
字符串处理部分,StringSplitter的split方法同样是认知复杂度极高,是取决于字符串处理的方法来源于面向过程的思维,层层拆分,该设计并不符合面向对象的思想,不优。
-
MapIndex相关的处理方法,认知复杂度同样很高,它取决于笔者采用了Map结构来管理表达式各项,事实证明在后期迭代过程中是不合适的,引入MapIndex也是冗余的。
3. 整体架构分析
整体而言,本单元作业的设计架构是存在着巨大问题的。
表面上看,笔者将各对象进行了明确的类别划分,甚至也构造了继承关系,在物理层面上是清晰且正确的。因此在第一次作业中困难不大,并且bug数量约等于零。
然而事实上,这实际上是一种按数据结构思维形成的架构设计,并不符合真正的面向对象思维,主要体现在:
程序的核心架构中,每个类都只利用繁杂的容器对于其子成员进行管理,用“
具象化”的物理结构层层迭代,形成了构造逻辑;抽象父类Factor中并
没有对子类共性进行概括,使其存在形同虚设。
——这与大一下学期数据结构课程中所学的内容并无二致。因而,最终导致了在求导等各方法中要考虑众多繁杂的遍历细节、在类中需要考虑子类中的实现细节,脱离了面向对象思想的本质,造成了后续迭代时巨大的工作量与第三次作业的失败。纠其源头,都来自于失败的层次化设计、与不良的核心架构。
总结:面向对象思维所注重的核心即是“层次化设计”,注重“抽象的概括能力”,要避免与“具体的层次化能力”混淆。那么优秀的面向对象架构究竟长什么样子呢?笔者将在后文展示。
笔者程序bug分析
三次作业情况如下:
-
HW1强测AK,互测hack1,被hack0;
-
HW2强侧AK,互测hack0,被hack0;
-
HW3未通过弱侧作业无效。
因此下对HW3进行主要分析:
问题根源已经在上文提出,即架构设计有问题导致程序繁杂冗余、不易调试,最终因一bug始终无法de出导致失败。debug过程中,在getDerivative方法某行中,IDE内置debugger监视以笔者不能理解的方式变化,曾经猜测原因有:
IDE自身问题:并不是,因为OJ中结果一致,且多次重复断点调试,均在同一位置产生该问题。一位经验丰富的开发人员告诫我,“IDE问题一定是最后的最后才能找的”。
深浅拷贝问题:由于程序中有众多返回构造类型对象的方法,其中多数并未严格实现深刻贝,可能导致对象共享,引起未知变化。
递归深度过深、栈爆炸、OutOfBound问题:出于所采用的结构存在众多的递归调用,导致程序栈深度过大,指针越界,产生了未知错误。
最终确定为问题3,依然是程序的架构问题所导致。另外,代码复杂度过高时,极不利于调试,要尽可能避免,保持程序的简洁性与易读性。
笔者发现别人bug策略分析
笔者在研讨课上对于杜雨新同学关于“写评测机”主题的分享印象深刻,在互测阶段中采用了自动评测机的方式对同组同学的代码进行了评测,但仅仅是发现了一个bug数据。期间对各同学的程序架构进行了欣赏,学习到了很多架构方法上的思路,如递归下降等。
重构经历总结
由于笔者并未经历重构,但对于第二次研讨课中叶焯仁同学分享的面向对象思想架构印象较为深刻,下对其构造进行简要分析,并学习日后在面对面向对象程序的架构设计时该向何方向思考。

统一管理:利用多态,并抽象公共方法。(要让多态的父类起到实际意义)
松耦合:类与类间耦合要松,类内部方法之间耦合要松。(靠向面向对象思想)
专职类(最重要):每个类要明确知道自己的职能,不需要考虑其他类的工作,互不干扰。
在笔者的程序中,经常出现遇到困难时便忽视了oo思想、转而用冗杂的数据结构进行处理的问题,以Term.getDerivative为例:到第二次迭代时,由于要考虑很多因为数据结构不当(Map)的问题,将Term变成了更繁杂的结构,即,容器中第一位固定为Constant、第二位为PowerFunc、第三位为SineFunc、第四位为CosineFunc、后面为Expression的不易处理、调试的数据结构,是完全的面向过程编程;甚至到第三次迭代时,Term内容器的结构变成了二维结构,因为要满足sin和cos的底数不同问题,导致复杂度指数增加。
事实上,到这种复杂度时我们已经完全可以将其定性,说明这种方式是不科学的,存在更符合课程、也更简洁的面向对象方法。即,回顾自己的对象设计、架构设计哪里存在问题,并勇于重构,不要贪图一时便宜。
一言以蔽之,层次化架构、类专职性、统一管理,在设计程序前应当事先考虑。
心得体会
本次作业是OO开课以来的第一个完整作业。由于我便是并未采取优良层次化结构的一员,在迭代过程中,第二次作业的爆炸性工作量、以及第三次作业的失败都让我深刻体会到了不良程序架构会带给后期迭代工作的恶劣后果:复杂度爆炸(心态更爆炸),体会到了面向对象设计的重要性;经过反思考察,也让我真正学习到了什么是优秀的面向对象架构,我的设计思维与它究竟相差在何。
更重要的,我也明白了在程序设计的过程中,我也应当避免眼界狭隘、仅集中在某几行代码的调试上的坏习惯;这里我想引用王翔学长的的一段话:(真的不是水字数!)
OO的课程设计,类似于构造性证明,不是蛮干硬莽能解决的。想到了,思路对了,写起来就会非常简单;没想到,思路不对,写起来就会困难重重。就像CO课强调的,先思考,再设计,最后实现。对问题研究对象的结构的观察,对数据和程序的结构的思考,选取和设计才是这门课的重点。写代码不是重点,只是前者的验证和实践。
如果你觉得一次迭代中的新特性,在现有数据和程序结构上实现起来非常麻烦,写起来很困难,如果这种困难感超过了数据结构课程的普通编程题的困难感,那么最好回到问题的研究对象本身,观察一下它的结构,想一想什么样的数据和程序结构最能良好地表示它,搜索一下网络上解决类似问题所使用的数据和程序结构,学习一下他们的思路,或者和同学交流一下。
不要害怕重构甚至重写,错误的思路会让你越走越难。关键在于找到正确的数据和程序结构。因此要多观察,多思考,多了解学习,多交流,少写代码,不要钻进自己的遗留代码里死磕不出来。
希望大家能从这门课里收获它真正想教给大家的,观察问题研究对象的结构,思考,选取和设计合适的数据和程序结构的能力,而不是疲惫和挫败感。
在陷入其中前,事先对于全局进行把控,思考架构问题、真正学到设计思维的精髓,才能在OO课中游刃有余、真正学习到有用的知识。
最后感谢各位老师、同学、助教学长的帮助!希望在下一次作业中我能够有所提升,真正体会到OO的强大力量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号