
Java线程池二:线程池原理
最近精读Netty源码,读到NioEventLoop部分的时候,发现对Java线程&线程池有些概念还有困惑, 所以深入总结一下
Java线程池一:线程基础
Java线程池二:线程池原理
为什么需要使用线程池
Java线程映射的是系统内核线程,是稀缺资源,使用线程池主要有以下几点好处
- 降低资源消耗:重复利用池中线程降低线程的创建和消耗造成的资源消耗。
- 提高响应速度:任务到达时直接使用池总中空闲的线程,可以不用等待线程创建。
- 提高线程的可管理性:线程是稀缺资源,不能无限制创建,使用线程池可以统一进行分配、监控、调优。
线程池框架简介
- Executor接口:提供
execute方法提交任务 - ExecutorService接口:提供可以跟踪任务执行结果的
submit方法 & 提供线程池关闭的方法(shutdown, shutdowNow) - AbstractExecutorService抽象类:实现submit方法
- ThreadPoolExecutor: 线程池实现类
- ScheduleThreadPoolExecutor:可以执行定时任务的线程池
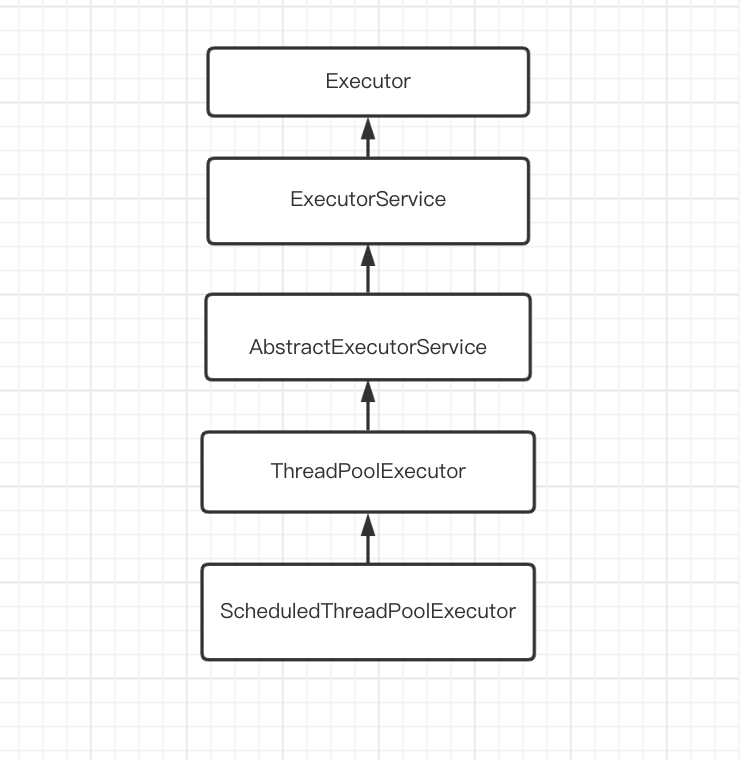
ThreadPoolExecutor原理
核心参数以及含义
- corePoolSize:核心线程池大小
- maximumPoolSize: 线程池最大大小
- workQueue: 工作队列(任务暂时存放的地方)
- RejectedExecutionHandler:拒绝策略(线程池无法执行该任务时的处理策略)
任务提交流程
任务提交过程见下流程图

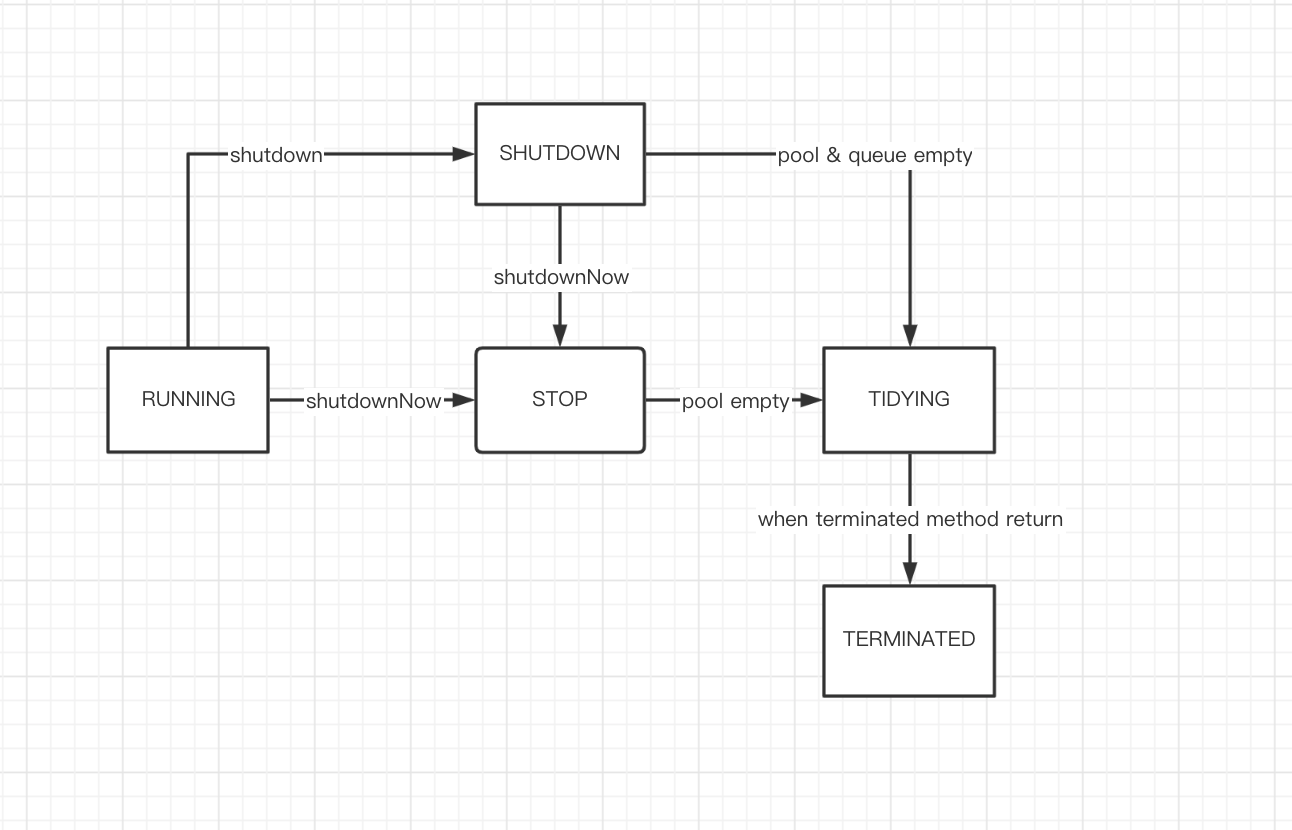
线程池的状态
- RUNNING:正常的线程池运行状态
- SHUTDOWN:调用shutdown方法到该状态,该状态下拒绝提交新任务,但会将已提交的任务的处理完毕
- STOP:调用shutdownNow方法到该状态,该状态下拒绝新任务的提交 & 丢弃工作队列中的任务 & 中断正在执行任务的工作线程
- TIDYING:工作队列和线程池都为空时自动到该状态
- TERMINATED:terminated方法返回之后自动到该状态
工作队列
核心线程池满时,任务会尝试提交到工作队列,后续工作线程会从工作队列中获取任务执行。
因为涉及到多个线程对工作队列的读写,所以工作队列需要是线程安全的,Java提供了以下几种线程安全的队列(BlockingQueue)
| 实现类 | 工作机制 |
|---|---|
| ArrayBlockingQueue | 底层实现是数组 |
| LinkedBlockingDeque | 底层实现是链表 |
| PriorityBlockingQueue | 优先队列,本质是个小顶堆 |
| DelayQueue | 延时队列 (优先队列 & 元素实现Delayed接口),ScheduledThreadPoolExecutor实现的关键 |
| SynchronousQueue | 同步队列 |
BlockingQueue 多组读写操作API
| 操作 | 描述 |
|---|---|
| add/remove | 队列已满/队列已空时,抛出异常 |
| put/take | 队列已满/队列已空时,阻塞等待 |
| offer/poll | 队列已满/队列已空时,返回特殊值(false/null) |
| offer(time) / poll(time) | 超时时间内无法写入或者读取成功,返回特殊值 |
拒绝策略
拒绝策略是当线程池满负载时(任务队列已满 & 线程池已满)对新提交任务的处理策略,jdk提供了如下四种实现,其中AbortPolicy是默认实现。
| 实现类 | 工作机制 |
|---|---|
| AbortPolicy | 抛出RejectedExecutionException异常 |
| CallerRunsPolicy | 调用线程执行该任务 |
| DiscardOldestPolicy | 丢弃工作队列头部任务,再尝试提交该任务 |
| DiscardPolicy | 直接丢弃 |
当然我们可以有自定义的实现,比如记录日志、任务实例持久化,同时发送报警到开发人员。
跟踪任务的执行结果
线程池提供了几个submit方法, 调用线程可以根据返回的Future对象获取任务执行结果,那么它的实现原理又是什么呐?
装饰模式对task的run方法进行增强
1.提交任务前,会把task装饰成一个FutureTask对象
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
2.FutureTask对象的run方法会存储返回的结果或者异常。调用方可以根据FutureTask获取任务的执行结果。
//省略了部分代码
public void run() {
Callable<V> c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
//执行任务
result = c.call();
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
//存储异常
setException(ex);
}
if (ran)
//存储返回值
set(result);
}
线程池的关闭
shutdown
shutdown将线程池的状态设置成SHUTDOWN,同时拒绝提交新的任务,但是已提交的任务会正常执行
shutdownNow
shutdownNow将线程池的状态设置成STOP,该状态下拒绝提交新的任务 & 丢弃工作队列中的任务& 中断当前活跃的线程(尝试停止正在执行的任务)
需要注意的是shutdownNow对于正在执行的任务只是尝试停止,不保证成功(取决于任务是否监听处理中断位)
ScheduledThreadPoolExecutor 定时调度原理
ScheduledThreadPoolExecutor在ThreadPoolExecutor之上扩展实现了定时调度的能力
1.实例化时工作队列使用延时队列(DelayedWorkQueue)--- 本质是个小顶堆
public ScheduledThreadPoolExecutor(int corePoolSize,
RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), handler);
}
2.提交的任务装饰成ScheduledFutureTask类型,并把任务加入到工作队列(不直接调用execute)
public ScheduledFuture<?> schedule(Runnable command,
long delay,
TimeUnit unit) {
if (command == null || unit == null)
throw new NullPointerException();
//装饰
RunnableScheduledFuture<?> t = decorateTask(command,
new ScheduledFutureTask<Void>(command, null,
triggerTime(delay, unit)));
//任务加入工作队列
delayedExecute(t);
return t;
}
3.ScheduledFutureTask实现Delayed和Comparable接口
所以提交到工作队列中的任务是按照任务执行时间排序的(最早执行的任务在头部),因为工作队列是个小顶堆。
public long getDelay(TimeUnit unit) {
return unit.convert(time - now(), NANOSECONDS);
}
public int compareTo(Delayed other) {
if (other == this) // compare zero if same object
return 0;
if (other instanceof ScheduledFutureTask) {
ScheduledFutureTask<?> x = (ScheduledFutureTask<?>)other;
long diff = time - x.time;
if (diff < 0)
return -1;
else if (diff > 0)
return 1;
else if (sequenceNumber < x.sequenceNumber)
return -1;
else
return 1;
}
long diff = getDelay(NANOSECONDS) - other.getDelay(NANOSECONDS);
return (diff < 0) ? -1 : (diff > 0) ? 1 : 0;
}
4.只能从工作队列中获取已到执行时间的任务
public RunnableScheduledFuture<?> poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
RunnableScheduledFuture<?> first = queue[0];
//如果头部的任务还没有到执行时间, 直接返回null
if (first == null || first.getDelay(NANOSECONDS) > 0)
return null;
else
return finishPoll(first);
} finally {
lock.unlock();
}
}
线程池配置
假设:CPU核心数是N,每个任务的执行时间是T,任务的超时时间是timeout,核心线程数是corePoolSize,工作队列大小是workQueue, 最大线程数是 maxPoolSize, 任务最大并发数为maxTasks
核心线程数配置
-
对于CPU密集型任务:corePoolSize 大小设置成和CPU核心数接近,如N+1 或者 N+2
-
对于IO密集型任务:corePoolSize可以设置的比较大一些,如2N~3N;也可以通过如下逻辑进行估算
假设80%的时间是IO操作,那么每个任务需要占用CPU时间大概是0.2T, 每秒每个CPU核心最大可以执行的任务数为 = (1/0.2T) = 5/T;所以
理论上80%IO的情况下corePoolSize可以设置为 5N (一个cpu可以对应5个工作线程)
工作队列大小配置
工作队列的大小取决于任务的超时时间 & 核心线程池的吞吐量
则 workQueue = corePoolSize * (1/T) * timeout = (corePoolSize * timeout) / T
需要注意的是: 工作队列不能使用无界队列。(无界队列异常情况下可能耗尽系统资源,造成服务不可用)
最大线程数配置
最大线程数的大小取决于最大的任务并发数 & 工作队列的大小 & 任务的执行时间
则 maxPoolSize = (maxTasks - workQueue) / T
拒绝策略配置
对于无关紧要的任务,我们可以直接丢弃;对于一些重要的任务需要对任务进行持久化,以便后续进行补偿和恢复。
线程池监控
我们可以有个定时脚本将线程池的最大线程数、工作队列大小、已经执行的任务数、已经拒绝的任务数等数据推送到监控系统
这样我们可以根据这些数据对线程池进行调优,也可以即使感知线上业务异常。
