

在分布式领域有个CAP理论(Brewer’s CAP Theorem) ,是说Consistency(一致性), Availability(可用性), Partition tolerance(分布) 三部分在系统实现只可同时满足二点,没法三者兼顾。
http://www.julianbrowne.com/article/viewer/brewers-cap-theorem
BTW,C有人认为用 Atomic 表示更加合适,只是用AAP定律显得......
原子性 参见 http://baike.baidu.com/view/600227.htm
整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
normal case:
A B share 通过一个数据V,里面有一个值V0,
1.A写入V1
2.N1用M消息来更新N2的V0 COPY
3.然后B读取出来
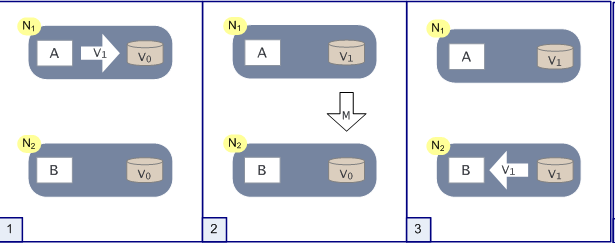
下面发生了 network partion
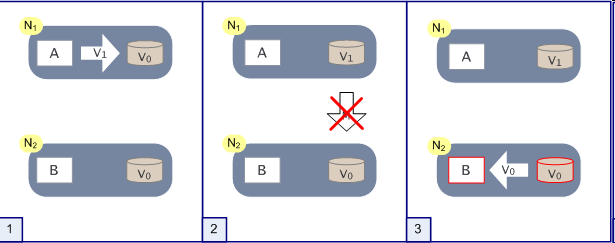
这种情况如何处理?
1. 牺牲P
就是说把所有的东西都放在一台机器或者是一个机架(atomically-fail?)。这样往往存在scaling的问题
2. 牺牲A
碰到 partition问题,影响相应的业务,直到数据一致前,业务一直是 unavailable
3. 牺牲C
B就不要太追求一致了,就把V0将就着用,但是应用需要能够处理这种不一致的情况
我们可以
下面是我的其他博客:
博客园,写一些工作和学习的笔记: http://www.cnblogs.com/peon/
博客堂,开发方面的一些文章:http://blog.joycode.com/peon/
流媒体博客,流媒体方面的一些文章:http://blog.lmtw.com/b/peon/
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号