强化学习理论-第7课-时序差分方法
1. TD learning of state values

公式1是用来根据\(s_t\)的state value来更新t+1的状态。
公式2是没有被访问的状态,下一刻的state value等于上一刻的。
1.1两个概念:TD target ,TD error

TD target:

TD error:
\(v_t\)是当前估计的值,\(v_{\pi}\)是要估计的值。

这个TD算法只用来估计state value of a given policy
2. TD算法是在没有模型的情况下求解贝尔曼公式




3. TD learning of action values - Sarsa
和上面的公式一模一样

policy update:

4. TD learning of action values - expected Sarsa

5. TD learning of action values - n-step Sarsa
蒙特卡洛和sarsa算法融合


6. TD learning of action values - Q-learning
直接估计optimal action value,不需要像上面的sarsa进行policy evaluation和policy improvement

求一个贝尔曼最优方程
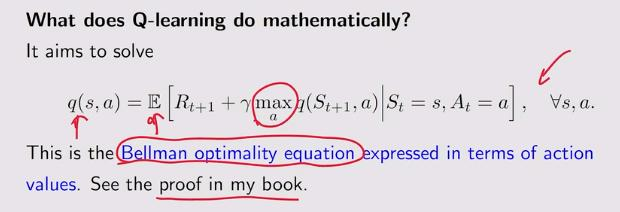


贝尔曼最优公式不包含策略

7. Q-learning 伪代码


8.总结


def sarsa(self, alpha = 0.1, epsilon = 0.1, num_episodes = 80):
while num_episodes > 0:
done = False
self.env.reset()
next_state = 0
num_episodes -= 1
total_reward = 0
episode_length = 0
while not done:
state = next_state
action = np.random.choice(np.arange(self.action_space_size), p = self.policy[state])
_, reward, done, _, _ = self.env.step(action)
episode_length += 1
total_reward += reward
next_state = self.env.pos2state(self.env.agent_location)
next_action = np.random.choice(np.arange(self.action_space_size), p = self.policy[next_state])
target = reward + self.gama * self.qvalue[next_state, next_action]
error = self.qvalue[state, action] - target
self.qvalue[state, action] = self.qvalue[state, action] - alpha * error
qvalue_star = self.qvalue[state].max()
action_star = self.qvalue[state].tolist().index(qvalue_star)
for a in range(self.action_space_size):
if a == action_star:
self.policy[state, a] = 1- (self.action_space_size - 1) / self.action_space_size * epsilon
else:
self.policy[state, a] = 1 / self.action_space_size * epsilon
def expected_sarsa(self, alpha = 0.1, epsilon = 0.1, num_episodes = 1000):
init_num = num_episodes
qvalue_list = [self.qvalue, self.qvalue + 1]
episode_index_list = []
reward_list = []
length_list = []
while num_episodes > 0:
episode_index_list.append(init_num - num_episodes)
done = False
self.env.reset()
next_state = 0
total_rewards = 0
episode_length = 0
num_episodes -= 1
print(np.linalg.norm(qvalue_list[-1] - qvalue_list[-2], ord = 1), num_episodes)
while not done:
state = next_state
action = np.random.choice(np.arange(self.action_space_size),
p=self.policy[state])
_, reward, done, _, _ = self.env.step(action)
next_state = self.env.pos2state(self.env.agent_location)
expected_qvalue = 0
episode_length += 1
total_rewards += reward
for next_action in range(self.action_space_size):
expected_qvalue += self.qvalue[next_state, next_action] * self.policy[next_state, next_action]
target = reward + self.gama * expected_qvalue
error = self.qvalue[state, action] - target
self.qvalue[state, action] = self.qvalue[state, action] - alpha * error
qvalue_star = self.qvalue[state].max()
action_star = self.qvalue[state].tolist().index(qvalue_star)
for a in range(self.action_space_size):
if a == action_star:
self.policy[state, a] = 1- (self.action_space_size - 1) / self.action_space_size * epsilon
if self.policy[state, a] <= 0:
print("fu:%d %d %f", state, a, self.policy[state, a])
else:
self.policy[state, a] = 1 / self.action_space_size * epsilon
if self.policy[state, a] <= 0:
print("fu:%d %d %f", state, a, self.policy[state, a])
qvalue_list.append(self.qvalue.copy())
reward_list.append(total_rewards)
length_list.append(episode_length)
fig = plt.figure(figsize=(10, 10))
self.env.render_.add_subplot_to_fig(fig=fig, x=episode_index_list, y=reward_list, subplot_position=211,
xlabel='episode_index', ylabel='total_reward')
self.env.render_.add_subplot_to_fig(fig=fig, x=episode_index_list, y=length_list, subplot_position=212,
xlabel='episode_index', ylabel='total_length')
fig.show()
def q_learning_on_policy(self, alpha=0.001, epsilon=0.4, num_episodes=1000):
init_num = num_episodes
qvalue_list = [self.qvalue, self.qvalue + 1]
episode_index_list = []
reward_list = []
length_list = []
while num_episodes > 0:
episode_index_list.append(init_num - num_episodes)
done = False
self.env.reset()
next_state = 0
total_rewards = 0
episode_length = 0
num_episodes -= 1
print(np.linalg.norm(qvalue_list[-1] - qvalue_list[-2], ord=1), num_episodes)
while not done:
state = next_state
action = np.random.choice(np.arange(self.action_space_size),
p=self.policy[state])
_, reward, done, _, _ = self.env.step(action)
next_state = self.env.pos2state(self.env.agent_location)
episode_length += 1
total_rewards += reward
next_qvalue_star = self.qvalue[next_state].max()
target = reward + self.gama * next_qvalue_star
error = self.qvalue[state, action] - target
self.qvalue[state, action] = self.qvalue[state, action] - alpha * error
qvalue_star = self.qvalue[state].max()
action_star = self.qvalue[state].tolist().index(qvalue_star)
for a in range(self.action_space_size):
if a == action_star:
self.policy[state, a] = 1 - (
self.action_space_size - 1) / self.action_space_size * epsilon
else:
self.policy[state, a] = 1 / self.action_space_size * epsilon
qvalue_list.append(self.qvalue.copy())
reward_list.append(total_rewards)
length_list.append(episode_length)
fig = plt.figure(figsize=(10, 10))
self.env.render_.add_subplot_to_fig(fig=fig, x=episode_index_list, y=reward_list, subplot_position=211,
xlabel='episode_index', ylabel='total_reward')
self.env.render_.add_subplot_to_fig(fig=fig, x=episode_index_list, y=length_list, subplot_position=212,
xlabel='episode_index', ylabel='total_length')
fig.show()
def q_learning_off_policy(self, alpha=0.01, epsilon=0.1, num_episodes=2000, episode_length=2000):
start_state = self.env.pos2state(self.env.agent_location)
start_action = np.random.choice(np.arange(self.action_space_size),
p=self.mean_policy[start_state])
episode = self.obtain_episode(self.mean_policy.copy(), start_state=start_state, start_action=start_action,
length=episode_length)
for step in range(len(episode) - 1):
reward = episode[step]['reward']
state = episode[step]['state']
action = episode[step]['action']
next_state = episode[step + 1]['state']
next_qvalue_star = self.qvalue[next_state].max()
target = reward + self.gama * next_qvalue_star
error = self.qvalue[state, action] - target
self.qvalue[state, action] = self.qvalue[state, action] - alpha * error
action_star = self.qvalue[state].argmax()
self.policy[state] = np.zeros(self.action_space_size)
self.policy[state][action_star] = 1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号