视觉十四讲:第八讲_光流法(特征点追踪)
1.直接法的引出
特征点估计相机运动的方法,主要是在关键点和描述子的计算非常耗时;而且在纹理信息比较少的情况下,特征点的数量会明显减少。
解决方案:
1.保留特征点,只计算关键点,不计算描述子,然后使用光流法跟踪特征点的运动,从而实现特征点的匹配。
2.只计算关键点,不计算描述子。使用直接法计算下一时刻特征点的位置,从而实现特征点的匹配。
第一种方法,是把特征点匹配换成光流法,估计相机运动时仍然采用对极几何、PnP或ICP算法。仍然需要计算角点。
第二种方法,是通过像素的灰度信息,同时估计相机运动和点的投影,不要求提取到的点必须为角点,甚至可以是随机的选点。
2.LK光流法
光流法基于灰度不变强假设。
对于t时刻位于(x,y)处的像素,设t+dt时刻它运动到了(x+dx,y+dy)处,由于灰度不变,所以有:I(x,y,t) = I(x+dx,y+dy,t+dt).
将右边进行泰勒展开,保留一阶项:
\(I(x+dx,y+dy,t+dt) \approx I(x,y,t)+ \frac{\partial I}{\partial x}dx + \frac{\partial I}{\partial y}dy + \frac{\partial I}{\partial t}dt\)
由于I(x,y,t) = I(x+dx,y+dy,t+dt),所以:\(\frac{\partial I}{\partial x}dx + \frac{\partial I}{\partial y}dy + \frac{\partial I}{\partial t}dt = 0\)
两边除dt,得:
\(\frac{\partial I}{\partial x} \frac{dx}{dt} + \frac{\partial I}{\partial y} \frac{dy}{dt} =- \frac{\partial I}{\partial t}\)
其中dx/dt为像素在x轴上的运动速度,dy/dt为y轴上的速度,记为u,v。同时\(\frac{\partial I}{\partial x}\)为该点在x方向的梯度,另一项为y方向的梯度,记为\(I_{x}\),\(I_{y}\),写成矩阵形式为:
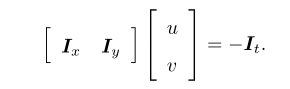
我们计算的是u、v,所以一个点无法计算,故假设该点附近的一个窗口内的像素都具有相同的运动。
考虑一个大小为w*w的窗口,共有\(w^{2}\)数量的像素,有\(w^{2}\)个方程:

这是一个关于u,v的超定方程,传统解法是求最小二乘解
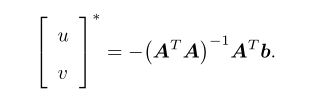
这样就得到像素在图像间的运动速度u,v。由于像素梯度仅在局部有效,如果一次迭代不够好,可以多迭代几次这个方程。
图像梯度:
图像梯度一般也可以用中值差分:
dx(i,j) = [I(i+1,j) - I(i-1,j)]/2;
dy(i,j) = [I(i,j+1) - I(i,j-1)]/2;
LK光流程序:
vector<KeyPoint> kp1;
//通过GFTT来获取角点
Ptr<GFTTDetector> detector = GFTTDetector::create(500, 0.01, 20); // maximum 500 keypoints
detector->detect(img1, kp1);
vector<Point2f> pt1, pt2;
for (auto &kp: kp1) pt1.push_back(kp.pt);
vector<uchar> status;
vector<float> error;
//直接调用LK光流函数
cv::calcOpticalFlowPyrLK(img1, img2, pt1, pt2, status, error);
3.高斯牛顿法实现光流
该问题可以看成一个优化问题:通过最小化灰度误差来估计最优的像素偏差。
相关代码:
GetPixelValue:采用双线性内插法,来估计一个点的像素:
公式为:
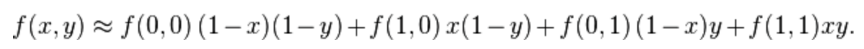
inline float GetPixelValue(const cv::Mat &img, float x, float y) {
// boundary check
if (x < 0) x = 0;
if (y < 0) y = 0;
if (x >= img.cols) x = img.cols - 1;
if (y >= img.rows) y = img.rows - 1;
uchar *data = &img.data[int(y) * img.step + int(x)];
float xx = x - floor(x);
float yy = y - floor(y);
return float(
(1 - xx) * (1 - yy) * data[0] +
xx * (1 - yy) * data[1] +
(1 - xx) * yy * data[img.step] +
xx * yy * data[img.step + 1]
);
}
class OpticalFlowTracker {
public:
OpticalFlowTracker(
const Mat &img1_,
const Mat &img2_,
const vector<KeyPoint> &kp1_,
vector<KeyPoint> &kp2_,
vector<bool> &success_,
bool inverse_ = true, bool has_initial_ = false) :
img1(img1_), img2(img2_), kp1(kp1_), kp2(kp2_), success(success_), inverse(inverse_),
has_initial(has_initial_) {}
void calculateOpticalFlow(const Range &range);
private:
const Mat &img1;
const Mat &img2;
const vector<KeyPoint> &kp1;
vector<KeyPoint> &kp2;
vector<bool> &success;
bool inverse = true;
bool has_initial = false;
};
void OpticalFlowSingleLevel(
const Mat &img1,
const Mat &img2,
const vector<KeyPoint> &kp1,
vector<KeyPoint> &kp2,
vector<bool> &success,
bool inverse, bool has_initial) {
kp2.resize(kp1.size());
success.resize(kp1.size());
OpticalFlowTracker tracker(img1, img2, kp1, kp2, success, inverse, has_initial);
//通过cv::parallel_for_并行调用了calculateOpticalFlow函数,循环次数为kp1.size(),传入了tracker数据。
parallel_for_(Range(0, kp1.size()),
std::bind(&OpticalFlowTracker::calculateOpticalFlow, &tracker, placeholders::_1));
}
void OpticalFlowTracker::calculateOpticalFlow(const Range &range) {
// parameters
int half_patch_size = 4; //窗口的大小为8*8
int iterations = 10; //每一个角点迭代10次
//总共的循环次数为 kp1.size()
for (size_t i = range.start; i < range.end; i++) {
auto kp = kp1[i];
double dx = 0, dy = 0; // dx,dy need to be estimated
if (has_initial) {
dx = kp2[i].pt.x - kp.pt.x;
dy = kp2[i].pt.y - kp.pt.y;
}
double cost = 0, lastCost = 0;
bool succ = true; // indicate if this point succeeded
// Gauss-Newton iterations
Eigen::Matrix2d H = Eigen::Matrix2d::Zero(); // hessian
Eigen::Vector2d b = Eigen::Vector2d::Zero(); // bias
Eigen::Vector2d J; // jacobian
for (int iter = 0; iter < iterations; iter++) {
if (inverse == false) {
H = Eigen::Matrix2d::Zero();
b = Eigen::Vector2d::Zero();
} else { //反向光流,H矩阵不变,只计算一次,每次迭代计算残差b
// only reset b
b = Eigen::Vector2d::Zero();
}
cost = 0;
// compute cost and jacobian
//对窗口的所有像素进行计算
for (int x = -half_patch_size; x < half_patch_size; x++)
for (int y = -half_patch_size; y < half_patch_size; y++) {
//计算误差
double error = GetPixelValue(img1, kp.pt.x + x, kp.pt.y + y) -
GetPixelValue(img2, kp.pt.x + x + dx, kp.pt.y + y + dy);;
if (inverse == false) { //雅可比矩阵,为第二个图像在x+dx,y+dy处的梯度。梯度上面已讲
J = -1.0 * Eigen::Vector2d(
0.5 * (GetPixelValue(img2, kp.pt.x + dx + x + 1, kp.pt.y + dy + y) -
GetPixelValue(img2, kp.pt.x + dx + x - 1, kp.pt.y + dy + y)),
0.5 * (GetPixelValue(img2, kp.pt.x + dx + x, kp.pt.y + dy + y + 1) -
GetPixelValue(img2, kp.pt.x + dx + x, kp.pt.y + dy + y - 1))
);
} else if (iter == 0) { //反向光流,计算第一张图像的雅可比矩阵,10次迭代只计算一次
// in inverse mode, J keeps same for all iterations
// NOTE this J does not change when dx, dy is updated, so we can store it and only compute error
J = -1.0 * Eigen::Vector2d(
0.5 * (GetPixelValue(img1, kp.pt.x + x + 1, kp.pt.y + y) -
GetPixelValue(img1, kp.pt.x + x - 1, kp.pt.y + y)),
0.5 * (GetPixelValue(img1, kp.pt.x + x, kp.pt.y + y + 1) -
GetPixelValue(img1, kp.pt.x + x, kp.pt.y + y - 1))
);
}
// compute H, b and set cost;
b += -error * J;
cost += error * error;
if (inverse == false || iter == 0) {
// also update H
H += J * J.transpose();
}
}
// compute update
Eigen::Vector2d update = H.ldlt().solve(b); //求解方程u,v
if (std::isnan(update[0])) { //解失败
// sometimes occurred when we have a black or white patch and H is irreversible
cout << "update is nan" << endl;
succ = false;
break;
}
if (iter > 0 && cost > lastCost) { //找到最小
break;
}
// 更新 dx, dy
dx += update[0];
dy += update[1];
lastCost = cost;
succ = true;
if (update.norm() < 1e-2) { //更新值范数已较小,直接退出
// converge
break;
}
}
success[i] = succ;
// kp2,找到了kp2和kp1的匹配点坐标
kp2[i].pt = kp.pt + Point2f(dx, dy);
}
}
4.多层光流
上面光流只计算了单层光流,当相机运动较快的时候,单层光流容易达到一个局部极小值,这时可以引入图像金字塔来进行优化。
图像金字塔就是对同一个图像进行缩放,得到不同分辨率下的图像,以原始图像作为金字塔的底层,没向上一层,就进行一定倍率的缩放。
计算金字塔光流时,先从顶层的图像开始计算,然后把上一层的追踪结果,作为下一层光流的初始值。这个过程称为由粗至精光流。
由粗至精的好处是,当原始图像运动较大的时候,在上几层的图像优化值里,像素运动会比较小,就避免了陷入局部极小值。
void OpticalFlowMultiLevel(
const Mat &img1,
const Mat &img2,
const vector<KeyPoint> &kp1,
vector<KeyPoint> &kp2,
vector<bool> &success,
bool inverse) {
// parameters
int pyramids = 4; //4层金字塔
double pyramid_scale = 0.5;
double scales[] = {1.0, 0.5, 0.25, 0.125};
// 创建4层金字塔,图1,图2,每层缩小0.5
chrono::steady_clock::time_point t1 = chrono::steady_clock::now();
vector<Mat> pyr1, pyr2; // image pyramids
for (int i = 0; i < pyramids; i++) {
if (i == 0) {
pyr1.push_back(img1);
pyr2.push_back(img2);
} else {
Mat img1_pyr, img2_pyr;
//进行缩放 参数:原图,输出图像,输出图像的大小
//dsize = Size(round(fxsrc.cols), round(fysrc.rows))
cv::resize(pyr1[i - 1], img1_pyr,
cv::Size(pyr1[i - 1].cols * pyramid_scale, pyr1[i - 1].rows * pyramid_scale));
cv::resize(pyr2[i - 1], img2_pyr,
cv::Size(pyr2[i - 1].cols * pyramid_scale, pyr2[i - 1].rows * pyramid_scale));
pyr1.push_back(img1_pyr);
pyr2.push_back(img2_pyr);
}
}
chrono::steady_clock::time_point t2 = chrono::steady_clock::now();
auto time_used = chrono::duration_cast<chrono::duration<double>>(t2 - t1);
cout << "build pyramid time: " << time_used.count() << endl;
// coarse-to-fine LK tracking in pyramids
vector<KeyPoint> kp1_pyr, kp2_pyr;
//最上层kp1的特征点处理 缩小 0.5*0.5*0.5
for (auto &kp:kp1) {
auto kp_top = kp;
kp_top.pt *= scales[pyramids - 1];
kp1_pyr.push_back(kp_top);
kp2_pyr.push_back(kp_top);
}
for (int level = pyramids - 1; level >= 0; level--) {
// from coarse to fine
success.clear();
t1 = chrono::steady_clock::now();
OpticalFlowSingleLevel(pyr1[level], pyr2[level], kp1_pyr, kp2_pyr, success, inverse, true);
t2 = chrono::steady_clock::now();
auto time_used = chrono::duration_cast<chrono::duration<double>>(t2 - t1);
cout << "track pyr " << level << " cost time: " << time_used.count() << endl;
if (level > 0) {
for (auto &kp: kp1_pyr)
kp.pt /= pyramid_scale;
for (auto &kp: kp2_pyr)
kp.pt /= pyramid_scale;
}
}
for (auto &kp: kp2_pyr)
kp2.push_back(kp);
}
完整代码:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号