37、Auto-Encoders原理
1、无监督学习
数据集变换,就是创建数据集新的表示算法,与数据的原始原始表示相比,新的表示可能更容易被人或其他机器学习算法所理解。
常见的应用有降维,就是对于许多特征表示的高维数据,找到表示该数据的一种新方法,用较少的特征就可以概括其重要特性。另一个应用就是找到“构成”数据的各个组成部分,比如对文本文档的关键字提取。
聚类,就是将数据划分成不同的组,每组包含相似的物项。
2、Auto-Encoders
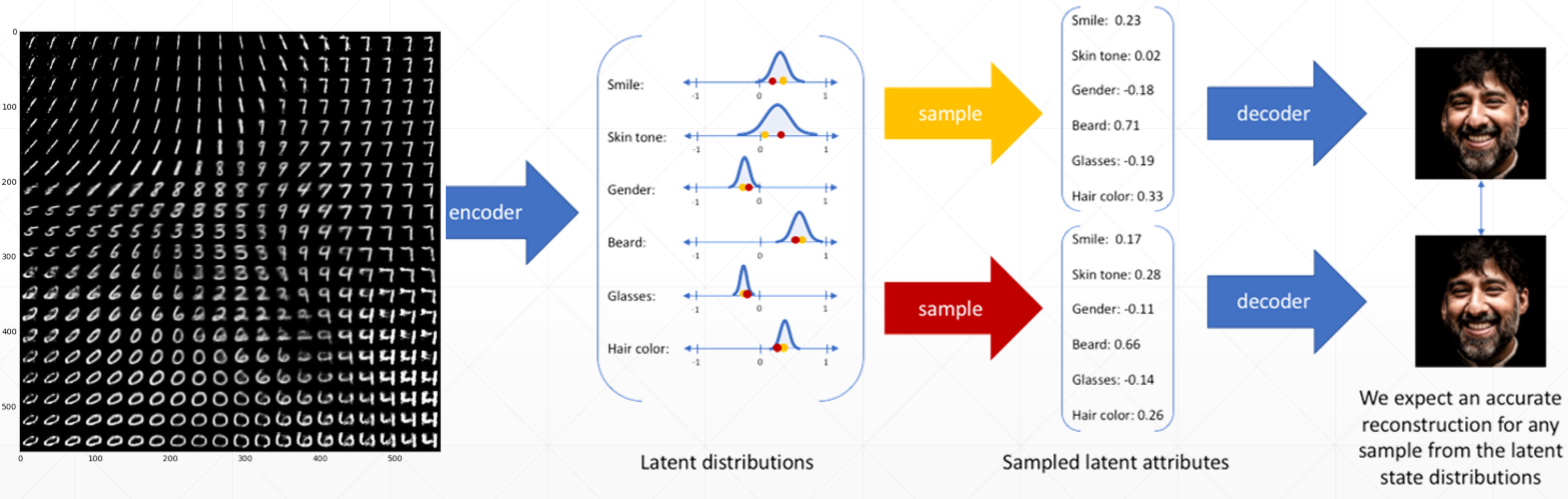
在无监督学习中,
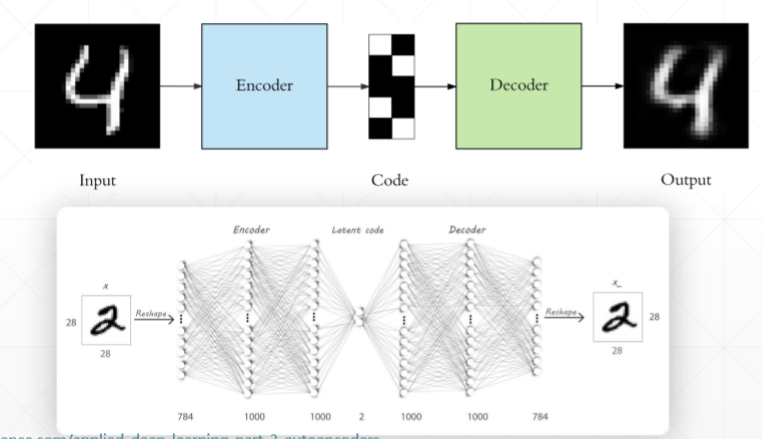
Auto-Encoders的目标是重建自己,它是一个特殊的全连接层,输入和输出的维度是一样的,这样能保证自己能够重建。中间有一个neck(脖子),这样既可以升维也可以降维,这里降到两维的好处是,二维的图片是可视化的,不仅已经降维,而且在空间中还保证了语义的相关性(通过无监督的聚类可以发现)。
3、Auto-Encoders的训练

①交叉熵,Xk是输入的图片。Xk ’是重建之后的图片,预测的结果是一个概率,大于0.5的归为1,小于0.5的归为0,当预测值是0,而真实值是1,loss希望预测值接近1,此时Xk =1,loss = -Σlog(Xk ’)最小化,当预测值是1,而真实值是0,loss希望预测值接近0,此时Xk =0,loss = -Σlog(1-Xk ’)最小化
②MSE
4、PCA降维和Auto-Encoders降维的比较
PCA在高维数据中寻找方差最大的方向,只选择方差最大的轴。然而,PCA具有线性特性,这对特征维数的提取有很大的限制。

Auto-Encoders比PCA降维的效果要好。
5、Auto-Encoders变种
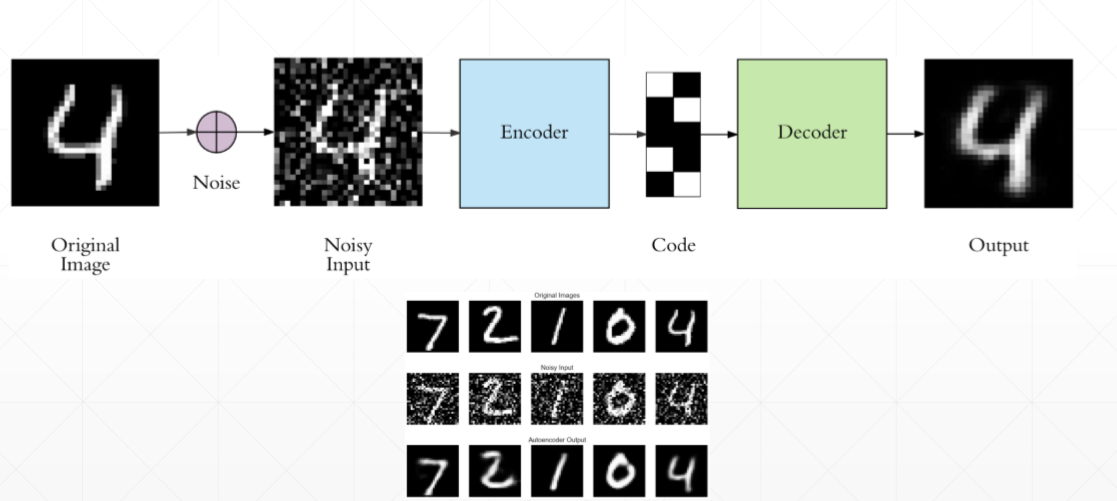
(1)Denoising AutoEncoders,去噪 AutoEncoders
如果只在像素级别的重建,便不能发现一些更加深层次的特征,网路可能会记住一些特征,为了防止这种情况出现,我们可以在原输入图片后加入随机噪声累加到原图片上,
(2)Dropout AutoEncoders
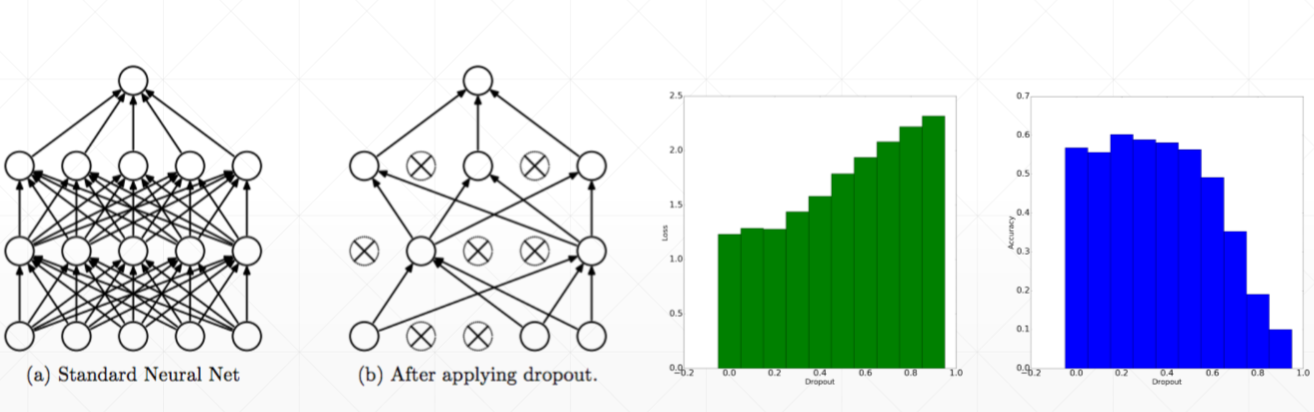
在训练的时候随机对某些连接进行断开(通过将该连接的w设置为0),那么将会迫使网络尽可能的提升还存在的连接的表征能力,降低对多个神经元的依赖程度。绿色图的x是训练时loss的Dropout率,y是loss,当为1时表示全部断开,loss最大,然而当dropout率为0时,右边蓝色图的y(test的acc)并不是最大,说明ropout率为0.2时在一定程度生可以缓解过拟合现象。
(3)Adversarial AutoEncoders,对抗 AutoEncoders
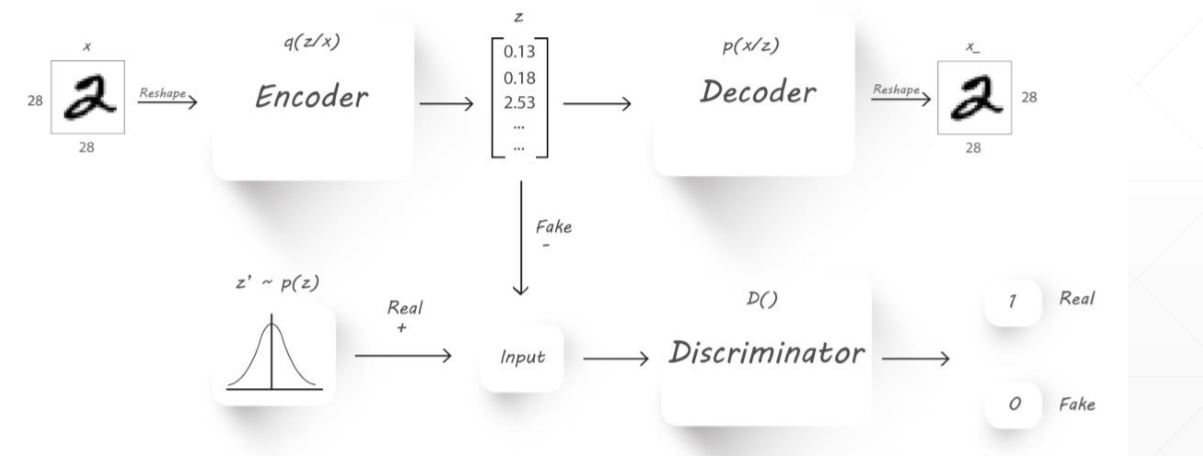
在原始的AutoEncoders中,没有呈现出原有数据的分布,有可能生成的数据是一样的,Adversarial AutoEncoders额外的添加了一个Discriminator(鉴别器),我们希望生成的Z符合真实的Z‘的分布,将真实的和生成的都送到鉴别器计算差距,如果属于希望的分布就输出为1,否则输出为0.
(4)q分布和p分布
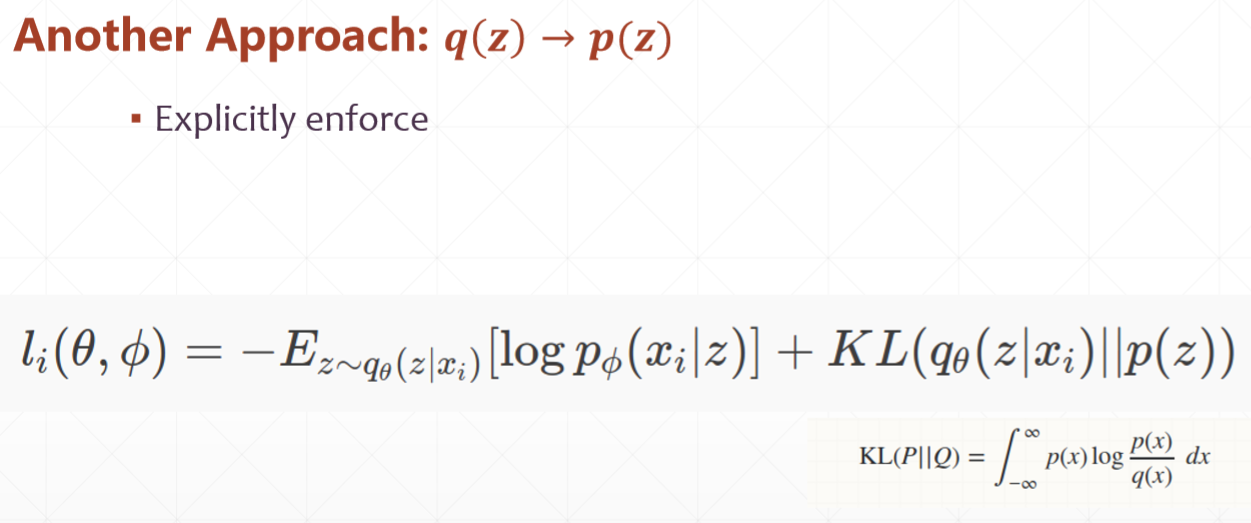
①前部分相当于欧氏距离,θ和o是两个网络,logpo(xi/z)表示在o网络下,给定一个z得到一个输出xi的概率
②KL散度:KL(P||Q)= ∫∞ p(x)log(p(x)/q(x))dx ,P和Q是两个分布,p(x)和q(x)是x分别属于这两个分布的概率,KL散度衡量了两个分布之间的距离,当两个分布的重叠区域越小时,KL散度也就越小。
假设p和q都服从 ![]()
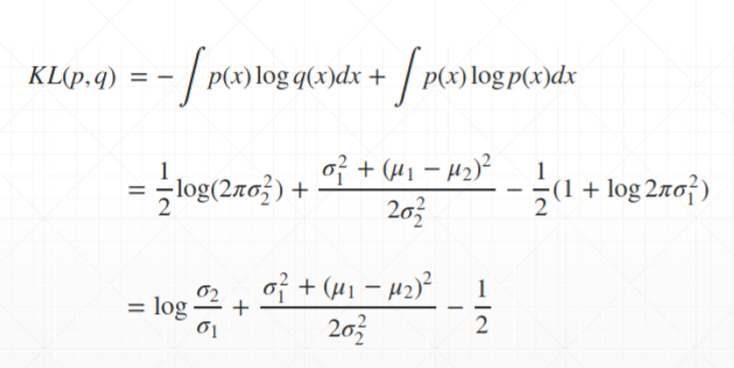
③真实数据x,通过隐藏层h,重构为x’因为通过h后,只是得到一个分布,因此需要进行sample()采样,而sample()是不可微的,将z变成z=u + nuo * eta,就能解决,而eta不可导,但是eta是不需要更新的,所以no care。
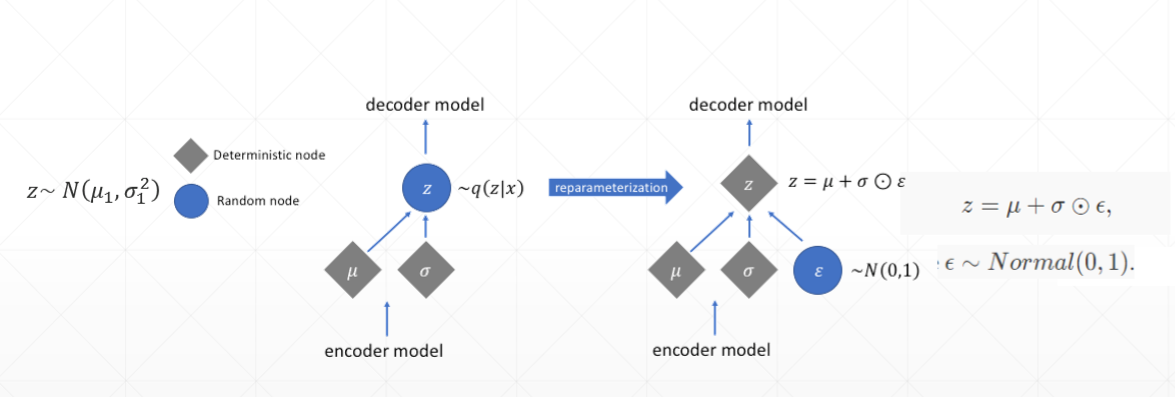
④再参数化技巧
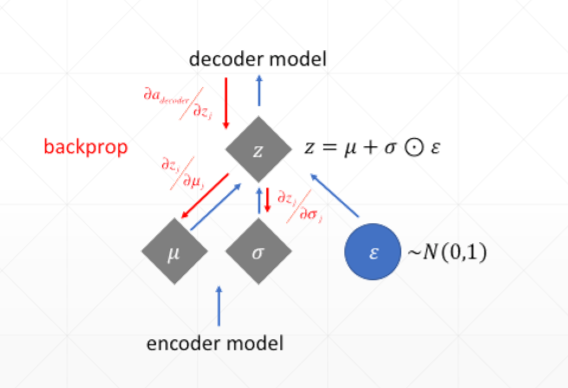
⑤
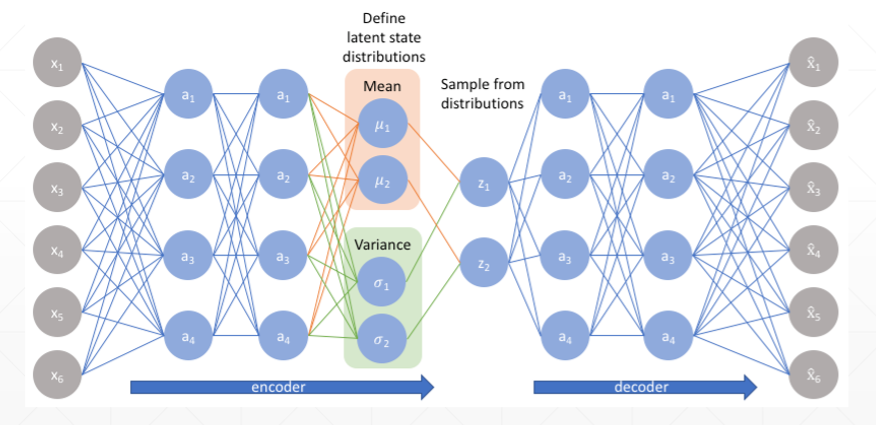
⑥生成模型,通过学习得到每一个特征的分布情况。