21、Keras高层API
(一) Keras.Metrics
- metrics 新建metrics
- update_state 在metrics列表中添加数据(更新数据),[loss1, loss2, loss3......]
- result().numpy() 在需要使用的时候得到结果
- reset_states 清除状态
(二)compile&fit ,提供了一个快捷训练的方法
- compile 编译,类似于一个装载的功能,提供了train的loss选择,优化器的选择和评估指标的选择
- fit 完成标准的训练流程
- evaluate 测试
- predict 对新的样本使用模型进行预测
1、metrics 测量尺,内置的评估指标算子
在训练的过程中,我们经常需要计算loss和acc并进行记录,因为每一次的loss和acc并不是指每一个batch的值,而是指一个epoch的值,因此需要建立一个列表,用来记录每一个loss或者acc,一个epoch结束后对所有的loss或者acc做平均值处理并进行打印,以便观察整个模型在上一次打印和这一次打印之间模型的变化情况,将这个功能称为metrics
Keras != tf.keras
1 # Step1 建立一个meter 2 acc_meter = metrics.Accuracy() 3 loss_meter = metrics.Mean() #求平均值 4 5 # step2 更新数据 6 loss_meter.update_state(loss) 7 acc_meter.update_state(y, pred) 8 9 # step3 得到平均数据 10 print(step, "loss:", loss_meter.result().numpy()) 11 print(step, "evaluate acc: ", total_correct/total, acc_meter.result().numpy()) 12 13 # step4 清除缓存 当得到一个时间戳的loss时,需要计算下个循环的时候如果不进行清除,那么就会将以前的缓存起来 14 if step % 100 == 0: 15 print(step, "loss", loss_meter.result().numpy()) 16 loss_meter.reset_states() 17 18 if step % 500 == 0: 19 total, total_correct = 0., 0 20 acc_meter.reset_states()
2、compile&fit
(1)计算和优化梯度的标准流程图:

使用compile:

(2)处理循环
标准:

使用fit

(3)测试代码 , valuation 评估
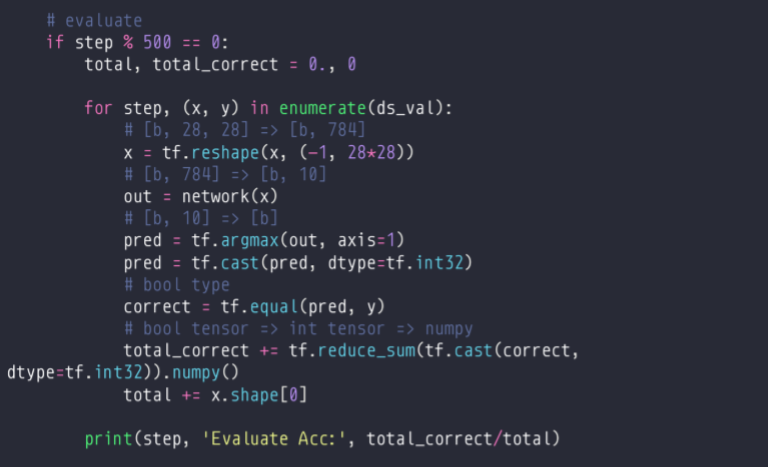
使用compile&fit
1 network.compile(optimizer=optimizers.Adam(lr=1e-3), 2 loss=tf.losses.CategoricalCrossentropy(from_logits=True), 3 metrics=['accuracy']) 4 network.fit(train_db, epochs=1500, validation_data=test_db, validation_freq=2)
