17、输出方式和误差计算
输出范围
- y∈ Rd
- relu,yi∈[0,1],i = 0,1,2.....,yd - 1
- softmax,yi∈[0,1],Σi=0 yi = 1,i = 0,1,2.....,yd - 1
- tanh,yi∈[-1,1],i = 0,1,2.....,yd - 1
误差计算
- MSE,Cross Entropy Loss,Hinge Loss
神经网络面向不同的应用有着不一样的输出范围
1、y∈ Rd ,y的输出范围为实数范围
(1)线性回归
(2)MSE误差计算
(3)最后一层网络不需要加激活函数
2、yi∈[0, 1]
(1)二分类,y的输出范围是0到1,然后通过激活函数进行二分类。
- y > 0.5,—> 1
- y < 0.5,—> 0
(2)图片生成
- 将图片的像素值压缩到0到1的范围,生成的图片也是0到1的范围
(3)sigmod函数
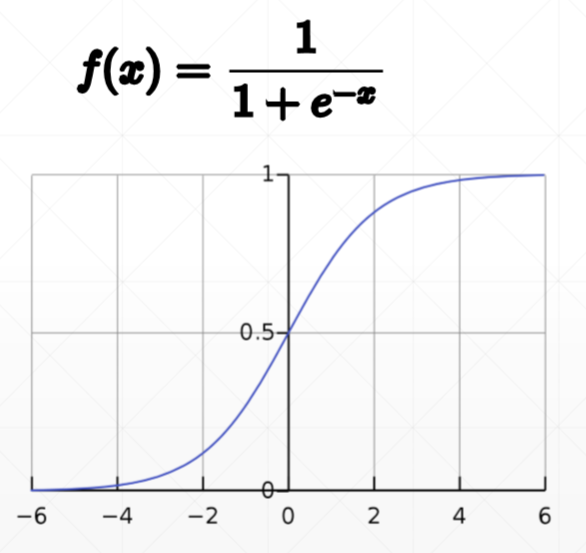
- out = X@W + b 实数范围
- out^ = sigmod(out) 将x的实数范围映射到y的0-1范围
1 a = tf.linspace(-6.,6,10) #要设置为6.才可以进行分配,由此可以看出tf对数据的类型有着严格的限制 2 print(a) 3 b = tf.sigmoid(a) 4 print(b)
输出:
tf.Tensor( [-6. -4.6666665 -3.3333333 -2. -0.6666665 0.666667 2. 3.333334 4.666667 6. ], shape=(10,), dtype=float32) tf.Tensor( [0.00247264 0.00931597 0.03444517 0.11920291 0.33924365 0.6607564 0.8807971 0.96555483 0.99068403 0.9975274 ], shape=(10,), dtype=float32)
(4)softmax函数,所有输出范围为0到1,且和为1
- 在图片分类中,如果label为10个类,我们就需要将分类的概率控制在0到1的范围,且和为1,这样就保证了在多分类的问题中每个样本只可能是这这些类别中的一类。
- 将没有加激活函数的结果值称 为Logits,logits经过softmax之后的结果就得到概率prob
- 通过softmax计算之后,原来大的值越大,小的值越小。
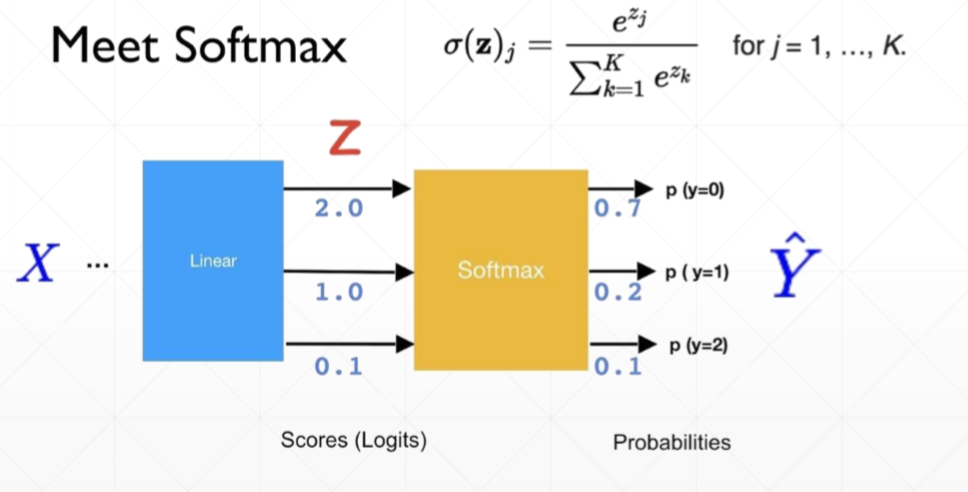
- tf.nn :提供神经网络相关操作的支持,包括卷积操作(conv)、池化操作(pooling)、归一化、loss、分类操作、embedding、RNN、Evaluation
1 a = tf.random.uniform([1,10],minval=-2,maxval=2) 2 print(a) 3 b = tf.nn.softmax(a) 4 print(b) 5 print(tf.reduce_sum(b,axis=1))
输出:
tf.Tensor( [[ 1.9517484 -0.7103443 -0.00292301 0.06679773 1.5784626 0.4067917 1.5372462 -1.298161 -0.64779663 0.5293989 ]], shape=(1, 10), dtype=float32) tf.Tensor( [[0.3048836 0.02128148 0.04317487 0.04629248 0.20990275 0.06503811 0.20142718 0.01182269 0.0226551 0.0735217 ]], shape=(1, 10), dtype=float32) tf.Tensor([0.99999994], shape=(1,), dtype=float32)
3、yi∈[-1,1]
(1)tanh函数
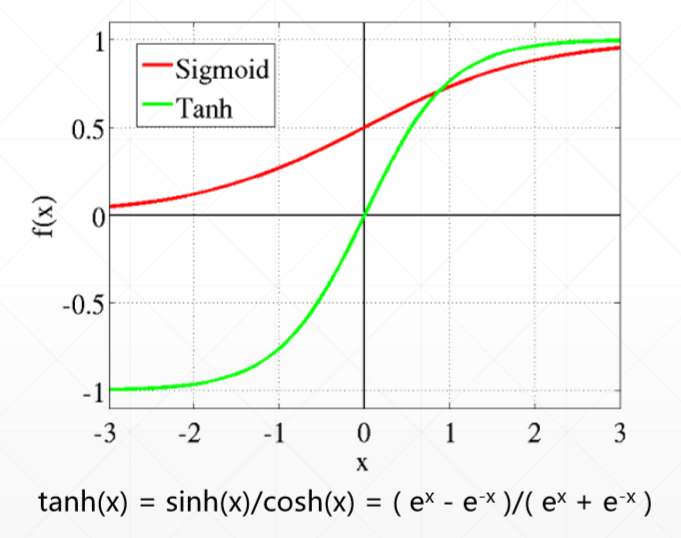
将实数的范围压缩到-1到1的y空间
1 a = tf.random.uniform([1,5],minval=-2,maxval=2) 2 print(a) 3 b = tf.tanh(a) 4 print(b)
输出:
tf.Tensor([[-1.5653028 -1.3870645 1.2212238 -0.6669798 -1.5970931]], shape=(1, 5), dtype=float32)
tf.Tensor([[-0.9162754 -0.88252336 0.8400148 -0.5829897 -0.92122984]], shape=(1, 5), dtype=float32)
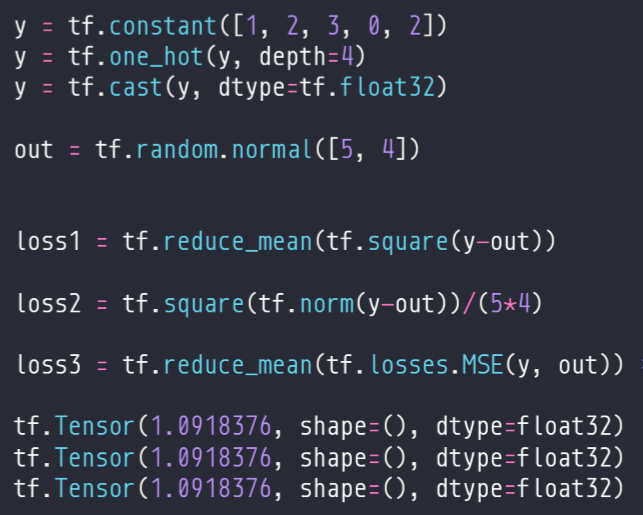
4、MSE,mean-square error 均方误差
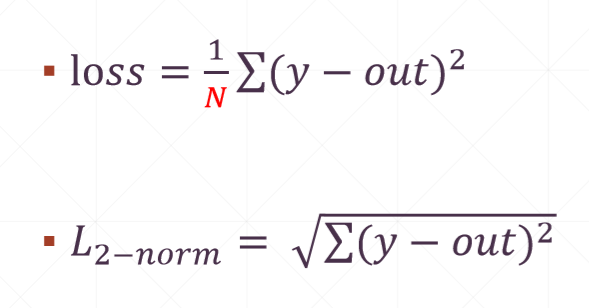
① 真实值与预测值的差的平方和,再求平均。learn rete目的是衰减更新步长,如果loss是一个比较大的数值,那么梯度往往是一个比较大的数值,因此需要做一个average,N一般是batch
5、交叉熵
熵越大,不确定性越大,因此得到的信息量越大,熵的单位是比特 bit
(1)熵:
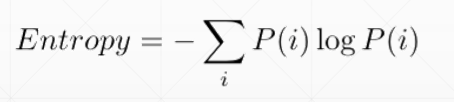
(2)交叉熵:
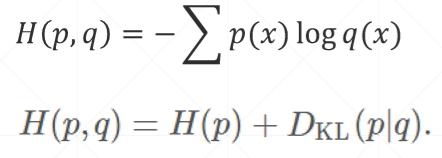
D是衡量p和q的距离的量,当p=q时,H(p,q)达到最小
(3)证明:

①当p = q时,距离最小,H(p,q)= H(p) 的熵
②当p是one-hot编码的真实分布,H(p)等于0,交叉熵退化为一个KL距离
例子:
Q1表达的概率没有很大的支撑度,虽然该网络会将结果预测为狗,但是网络的稳定性不是很好,此时的loss是比较大的,计算的时候只关注p中不为0的那一项对应的q

