16、全连接层
- out = f(X@W + b) 线性转换
- out = relu(X@W + b) 非线性转换
1、X@W + b
h = relu(X@W + b),最后得到的值h00和h01是prob,比较prob的大小将样本归分为该类别。relu函数是将小于0的数等于0,大于0的数不变。通过全连接层网络逐渐实现对输入样本的降维,如最初的输入样本是784维,而最终需要将样本分为10类,所以需要将输出设置为10维,即最终会将样本降为10维,每一维是一个概率,通过比较10个概率的大小,选出最大的概率即可得到样本的分类。
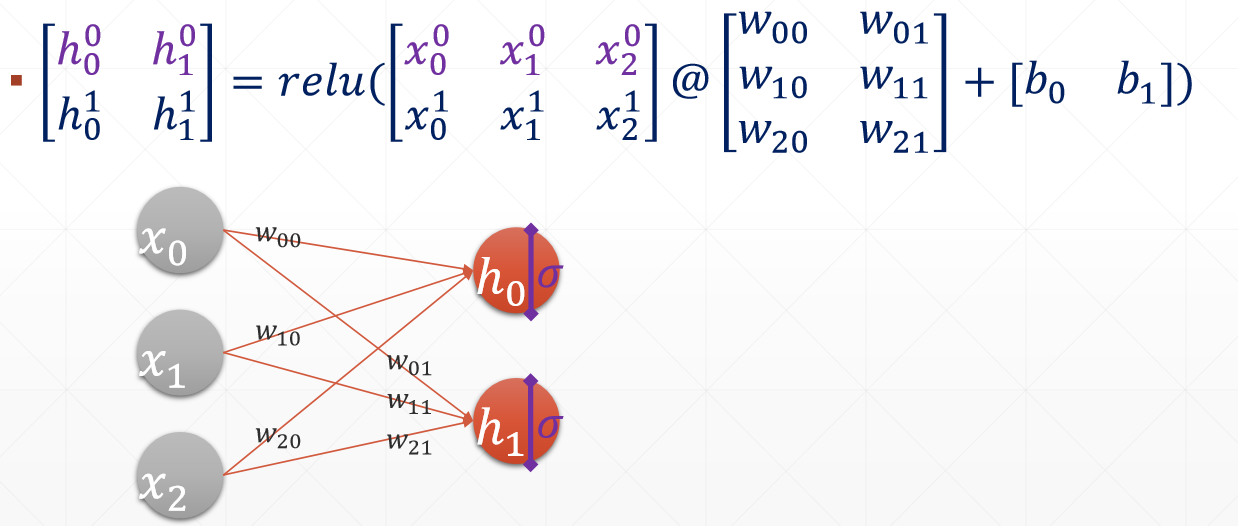
2、多层连接
第一层称为输入层,中间的称为隐藏层,最后的称为输出层,每一层包括该层与权值的乘积和加上偏置bais,全连接是指每一层的输入和该层的每一个节点都有线条进行连接。
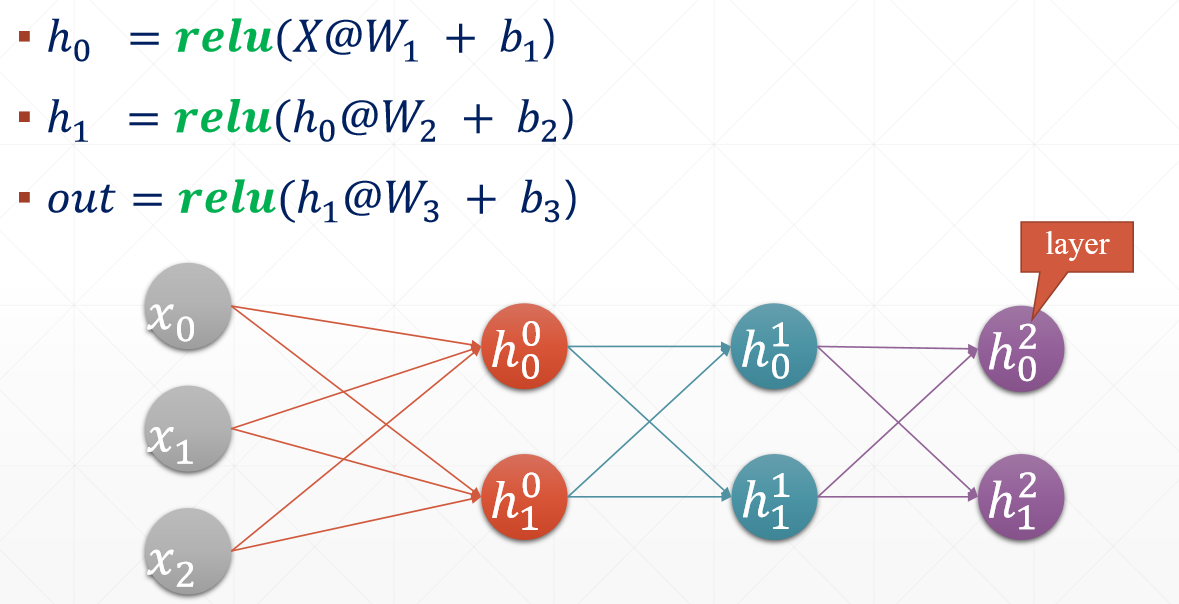
3、全连接层代码
(1)一层实现
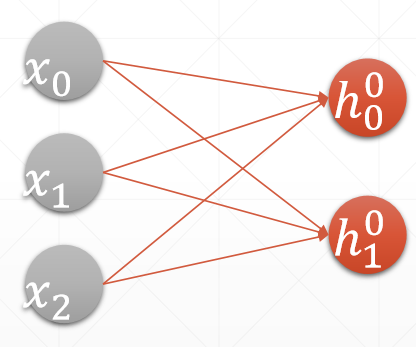
1 #建立两层的全连接层 2 x = tf.random.normal([4,784]) 3 net = tf.keras.layers.Dense(512) #建立网路,第二层(输出层)512 4 out = net(x) #out结果直接使用全连接层模型实例化得到结果 5 print(out.shape) #(4, 512) 6 # 在模型中自动创建w(kernel)和b(bias) 7 print(net.kernel.shape) #(784, 512) 8 print(net.bias.shape) #(512,)
使用net.build( )后自动创建w和b,此外build可以使用多次对输入进行形状的改变。一般来讲只需要build一次,w和b就会创建。
1 net = tf.keras.layers.Dense(10) 2 # print(net.kernel.shape) #'Dense' object has no attribute 'kernel' 3 # 在声明keras.layers.Dense时,并没用完成w和b参数的创建,使用net.build输入一个input_shape时会创建w和b 4 net.build(input_shape=[None,4]) 5 print(net.kernel.shape, net.bias.shape) #(4, 10) (10,)
(2)多层实现,通过容器Sequential([ layer1, layer1, layer1])实现模型的搭建和数据的前向流动。
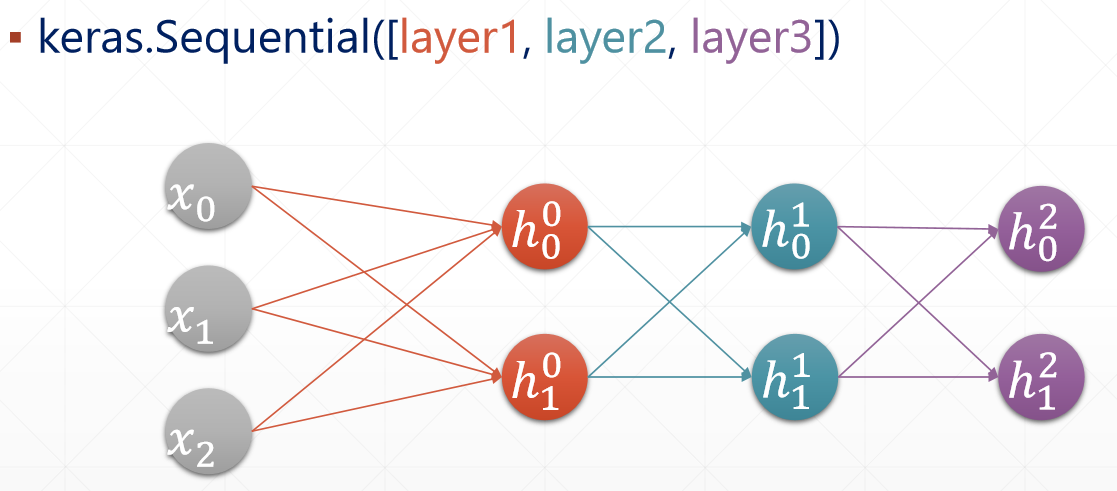
1 # 多层实现 2 x = tf.random.normal([2,3]) 3 model = Sequential([ #设置每一层的大小 4 layers.Dense(2,activation='relu'), 5 layers.Dense(2,activation='relu'), 6 layers.Dense(2,) 7 ]) 8 9 model.build(input_shape=[None,3]) 10 model.summary() 11 12 for p in model.trainable_variables: #trainable_variables返回一个list[w1,b1,w2,b2.w3.b3] 13 print(p.name, p.shape)
输出:
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense (Dense) multiple 8 _________________________________________________________________ dense_1 (Dense) multiple 6 _________________________________________________________________ dense_2 (Dense) multiple 6 ================================================================= Total params: 20 Trainable params: 20 Non-trainable params: 0 _________________________________________________________________ dense/kernel:0 (3, 2) dense/bias:0 (2,) dense_1/kernel:0 (2, 2) dense_1/bias:0 (2,) dense_2/kernel:0 (2, 2) dense_2/bias:0 (2,)

