14、fashion_mnist 数据集实战
- def preprocess(x,y) map() 第一个参数 function 以参数序列中的每一个元素调用 function 函数
- map( function,iterable)
- shuffe(10000)
- Sequential 序贯模型
- 优化器optimizers.Adam(lr=1e-3)
- GradientTape 梯度带
- logits
- 方差、标准差、均方差、均方误差
- 信息熵、条件熵、相对熵、交叉熵
(1)def preprocess()
预处理函数,将样本中的每一个数据进行处理,即通过map函数进行处理,将x转换为float32格式,将y转换为int32格式
(2)map( function,iterable)
第一个参数 function 以参数序列中的每一个元素调用 function 函数
(3)shuffe(10000)
在一个epoch中最后一个batch大小可能小于等于batch size ,dataset.repeat就是俗称epoch,但在tf中与dataset.shuffle的使用顺序可能会导致个epoch的混合 ,dataset.shuffle就是说维持一个buffer size 大小的 shuffle buffer,图中所需的每个样本从shuffle buffer中获取,取得一个样本后,就从源数据集中加入一个样本到shuffle buffer中。shuffle(1)时,即buffer size为1,相当于不进行打乱,buffer size=数据集样本数量,随机打乱整个数据集。
(4)Sequential 序贯模型
序贯模型是函数式模型的简略版,为最简单的线性、从头到尾的结构顺序,不分叉,是多个网络层的线性堆叠。Keras实现了很多层,包括core核心层,Convolution卷积层、Pooling池化层等。通过将层的列表传递给Sequential的构造函数
model = Sequential([ layers.Dense(256, activation=tf.nn.relu), # 256是该层的输入,[b, 784] => [b, 256] layers.Dense(128, activation=tf.nn.relu), #[b, 256] => [b, 128] layers.Dense(64, activation=tf.nn.relu), #[b, 128] => [b, 64] layers.Dense(32, activation=tf.nn.relu), # [b, 64] => [b, 32] layers.Dense(10) # [b, 32] => [b, 10], 330 = 32*10 + 10 最后一层不需要激活函数 ])
此外我们还需要一个输入层,模型需要知道它所期待的输入的尺寸(shape)。所以,序贯模型中的第一层(只有第一层,因为下面的层可以自动的推断尺寸)需要接收关于其输入尺寸的信息,后面的各个层则可以自动的推导出中间数据的shape,因此不需要为每个层都指定这个参数,通过传递一个input_shape参数给第一层。它是一个表示尺寸的元组(一个整数或None的元组,其中None表示可能为任何正整数)。在input_shape中不包含数据的batch大小。
# dense表示全连接层 model.build(input_shape=[None,28*28]) #对第一层进行输入,建立模型,传入数据 model.summary() #调试的功能,作用是打印网络结构
(5)优化器optimizers.Adam(lr=1e-3)
Adam 算法和传统的随机梯度下降不同。随机梯度下降保持单一的学习率(即 alpha)更新所有的权重,学习率在训练过程中并不会改变。而 Adam 通过计算梯度的一阶矩估计和二阶矩估计而为不同的参数设计独立的自适应性学习率。Adam 算法的提出者描述其为两种随机梯度下降扩展式的优点集合,即:
- 适应性梯度算法(AdaGrad)为每一个参数保留一个学习率以提升在稀疏梯度(即自然语言和计算机视觉问题)上的性能。
- 均方根传播(RMSProp)基于权重梯度最近量级的均值为每一个参数适应性地保留学习率。这意味着算法在非稳态和在线问题上有很有优秀的性能。
- Adam 是一种可以替代传统随机梯度下降(SGD)过程的一阶优化算法,它能基于训练数据迭代地更新神经网络权重。
(6)GradientTape 梯度带
使用上下文环境,用来包裹将要求梯度的函数或者损失函数
(7)logits
logits表示输出结果, 把没有加激活函数的输出值称作logits
(8)方差、标准差、均方差、均方误差
方差:概率论和统计学中衡量随机变量或一组数据时离散程度的度量。概率论中方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数。方差可以用来描述变量的波动程度。方差在统计学和概率分布中各有不同的定义,并有不同的公式。在统计学中,方差用来计算每一个变量(观察值)与总体均数之间的差异。为避免出现离均差总和为零,离均差平方和受样本含量的影响,统计学采用平均离均差平方和来描述变量的变异程度。总体方差计算公式:
方差: 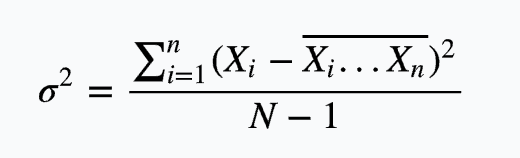 标准差:
标准差: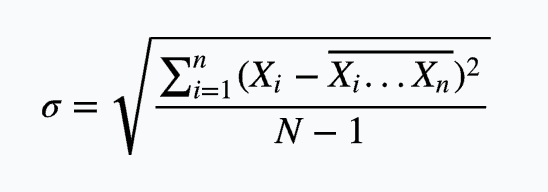
标准差在中文坏境中也被称为均方差
而均方误差(mean squared error),即MSE,是样本数据值偏离真实样本数据值的平方和的平均数,也即误差平方和的平均数
均方误差: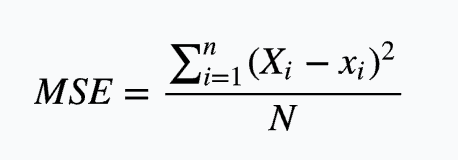 均方误差根:
均方误差根: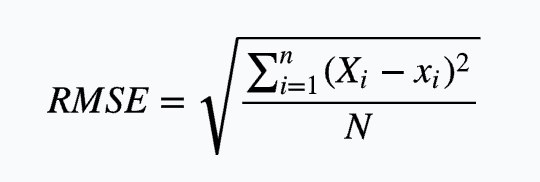
(9)信息熵、条件熵、相对熵、交叉熵
信息熵 (information entropy):信息量的度量就等于不确定性的多少,
假设一个发送者想传送一个随机变量的值给接收者。那么在这个过程中,他们传输的平均信息量可以通过求 ![]()
关于概率分布 p(x)p(x) 的期望得到,即:
条件熵 (Conditional entropy):条件熵 H(Y|X)H(Y|X) 表示在已知随机变量 XX 的条件下随机变量 YY 的不确定性。条件熵 H(Y|X)H(Y|X)
定义为 XX 给定条件下 YY 的条件概率分布的熵对 XX 的数学期望:条件熵 H(Y|X)H(Y|X) 相当于联合熵 H(X,Y)H(X,Y) 减去单独的熵 H(X)H(X),即H(Y|X)=H(X,Y)−H(X)
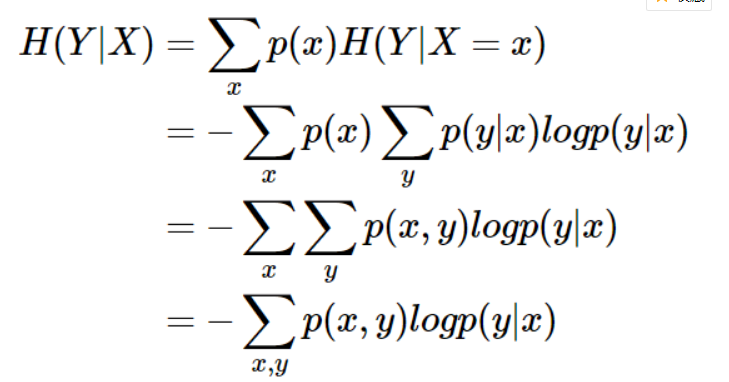
相对熵 (Relative entropy),也称KL散度 (Kullback–Leibler divergence)

交叉熵 (Cross entropy):

(10)完整代码
1 import tensorflow as tf 2 from tensorflow import keras 3 from tensorflow.keras import datasets, layers, optimizers, Sequential, metrics 4 import os 5 # 优化器optimizer 损失函数loss 评估标准metrics 序贯模型Sequential 6 os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' 7 8 def preProcess(x,y): 9 x = tf.cast(x, dtype = tf.float32)/255 #归一化 10 y = tf.cast(y, dtype = tf.int32) #y要转换为int类型 11 return x, y 12 13 14 (x, y),(x_test, y_test) = datasets.fashion_mnist.load_data() 15 print(x.shape,x_test.shape) 16 print(type(x)) # numpy数组 17 18 19 batchsize = 128 20 db = tf.data.Dataset.from_tensor_slices((x, y)) #numpy数组转换为tensor 21 db = db.map(preProcess).shuffle(1000).batch(batchsize) 22 23 db_test = tf.data.Dataset.from_tensor_slices((x_test,y_test)) 24 db_test = db_test.map(preProcess).batch(batchsize) 25 26 27 db_iter = iter(db) 28 sample = next(db_iter) 29 print('batch:', sample[0].shape, sample[1].shape) #batch: (128, 28, 28) (128,) 要next后才能有形状 30 31 # Sequential 32 # layers.Dense dense:全连接层, 相当于添加一个层,即初学的add_layer()函数 33 # tf.nn :提供神经网络相关操作的支持,包括卷积操作(conv)、池化操作(pooling)、归一化、 34 # loss、分类操作、embedding、RNN、Evaluation。 35 36 model = Sequential([ 37 layers.Dense(256, activation=tf.nn.relu), # 256是该层的输入,[b, 784] => [b, 256] 38 layers.Dense(128, activation=tf.nn.relu), #[b, 256] => [b, 128] 39 layers.Dense(64, activation=tf.nn.relu), #[b, 128] => [b, 64] 40 layers.Dense(32, activation=tf.nn.relu), # [b, 64] => [b, 32] 41 layers.Dense(10) # [b, 32] => [b, 10], 330 = 32*10 + 10 最后一层需要激活函数 42 ]) 43 # dense表示全连接层 44 model.build(input_shape=[None,28*28]) #对第一层进行输入 45 model.summary() 46 47 # w = w - lr*grad 权值更新 48 optimizer = optimizers.Adam(lr=1e-3) 49 #适应性矩估计(adaptive moment estimation) Adam 是一种可以替代传统随机梯度下降(SGD)过程的一阶优化算法, 50 #它能基于训练数据迭代地更新神经网络权重 51 52 def main(): 53 print("kkkkkkkkkkkkkkk") 54 for epoch in range(20): #进行20个循环 55 for step, (x,y) in enumerate(db): 56 # x: [b, 28, 28] => [b, 784] 57 # y: [b] 58 x= tf.reshape(x,[-1,28*28]) 59 60 with tf.GradientTape() as tape: 61 logits = model(x) # ? logits表示输出结果, 把没有加激活函数的输出值称作logits 62 y_onehot = tf.one_hot(y, depth=10) 63 64 # 均方差损失函数 65 loss_mse = tf.reduce_mean(tf.losses.MSE(y_onehot,logits)) 66 #方差用来度量随机变量和其数学期望(即均值)之间的偏离程度 ,均方误差表示各数据偏离真实值的距离平方和的平均数 67 #均方差是数据序列与均值的关系,而均方误差是数据序列与真实值之间的关系 68 69 #sigmoid函数会造成梯度消失,则考虑使用下面的交叉熵损失函数,交叉熵是用来评估当前训练得到的概率分布与真实分布的差异情况。 70 # 它刻画的是实际输出(概率)与期望输出(概率)的距离,也就是交叉熵的值越小,两个概率分布就越接近 71 # 交叉熵损失函数,直接用logits进行运算,一定要设置from_logits = True 72 loss_ce = tf.losses.categorical_crossentropy(y_onehot, logits, from_logits=True) 73 loss_ce = tf.reduce_mean(loss_ce) # 由于上一步计算的loss_ce是tensor,这里要做一下求平均值 74 75 grads = tape.gradient(loss_ce,model.trainable_variables) #计算梯度 model.trainable_variables返回变量列表,不需要我们再额外管理变量 76 optimizer.apply_gradients(zip(grads, model.trainable_variables))#反向传播计算。参数中 梯度(grads)和变量要一一对应,所以用了zip() 77 78 if step % 100 == 0: 79 print(epoch, step,"loss: ",float(loss_ce),float(loss_mse)) 80 81 82 #test 83 total_correct = 0 84 total_num = 0 85 for x, y in db_test: 86 # x: [b, 28, 28] => [b, 784] 87 # y: [b] 88 x = tf.reshape(x,[-1,28*28]) 89 90 # [b, 10] 每一个样本有10个预测值 91 logits = model(x) #没有经过激活函数处理得到结果 92 93 # logits => prob, [b, 10] 94 prob = tf.nn.softmax(logits, axis=1) #压缩列,操作每一行,将每一行的每个数通过softmax处理 95 pred = tf.argmax(prob, axis=1)#预测 96 pred = tf.cast(pred, dtype=tf.int32) #将float32转换为int32类型 97 # pred:[b] 取出了最大概率的索引即为预测值 98 # y: [b] 测试情况下,y不需要做one_hot 99 100 correct = tf.equal(pred,y) 101 correct = tf.reduce_sum(tf.cast(correct, tf.int32)) #ture转换为int数字之后进行求和 102 total_correct += int(correct) #每一个循环的求和 103 104 total_num += x.shape[0] #计算样本的总数 105 106 acc = total_correct/total_num #计算准确率 107 print(total_num) 108 print(epoch,"acc:",acc) 109 110 if __name__ == '__main__': 111 main()
