7、线性回归模型原理与实现(二)——学习率的调整,梯度爆炸,作用域
(1) 训练参数问题:trainable参数限制在优化的过程中是否变化,Ture表示变化,False表示不改变
weights = tf.Variable(tf.random_normal([1,1],mean=0.0, stddev=1.0), name="w", trainable=True)
如果是False
weights = tf.Variable(tf.random_normal([1,1],mean=0.0, stddev=1.0), name="w", trainable=False)
输出:
随机初始化的参数,权重为: 0.649509, 偏置为: 0.000000 第0次优化后的参数,权重为: 0.649509, 偏置为: 0.178874 第1次优化后的参数,权重为: 0.649509, 偏置为: 0.320899 第2次优化后的参数,权重为: 0.649509, 偏置为: 0.433686 第3次优化后的参数,权重为: 0.649509, 偏置为: 0.523746 第4次优化后的参数,权重为: 0.649509, 偏置为: 0.596887 第5次优化后的参数,权重为: 0.649509, 偏置为: 0.655301 第6次优化后的参数,权重为: 0.649509, 偏置为: 0.701020 第7次优化后的参数,权重为: 0.649509, 偏置为: 0.738476 第8次优化后的参数,权重为: 0.649509, 偏置为: 0.768768 第9次优化后的参数,权重为: 0.649509, 偏置为: 0.793133 第10次优化后的参数,权重为: 0.649509, 偏置为: 0.811534 第11次优化后的参数,权重为: 0.649509, 偏置为: 0.826162 第12次优化后的参数,权重为: 0.649509, 偏置为: 0.838186 第13次优化后的参数,权重为: 0.649509, 偏置为: 0.849078 . . .
可以看到weights在随机初始化之后就没有变化。
(2)学习率问题(步长)
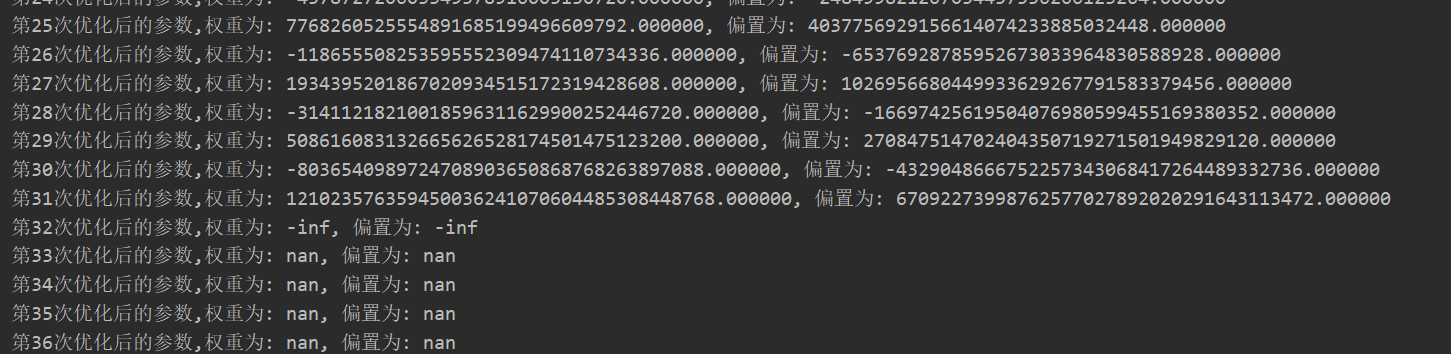
学习的大小影响梯度下降过程中山顶到达山底的速度。当学习率非常大的时候(如2)会造成梯度爆炸。如图所示
train_op = tf.train.GradientDescentOptimizer(2).minimize(loss)
关于梯度爆炸/梯度消失
在极端情况下,权重的值变得非常大,以至于溢出,导致NaN值
如何解决梯度爆炸问题(深度神经网络(如RNN)当中更容易出现)
1、重新设计网络
2、调整学习率
3、使用梯度截断(在训练过程中检查和限制梯度的大小)
4、使用激活函数
(3)TensorFlow作用域 ,相当于在web中的name之上再分配一个作用域
tf.variable_scope(<scope_name>) 创建指定名字的变量作用域
嵌套使用变量作用域
例:对图结构进行区域划分,取名 ”data“
1 with tf.variable_scope("data"): 2 x = tf.random_normal([100,1], mean=1.75, stddev=0.5, name="x_data") 3 y_ture = tf.matmul(x, [[0.7]]) + 0.8
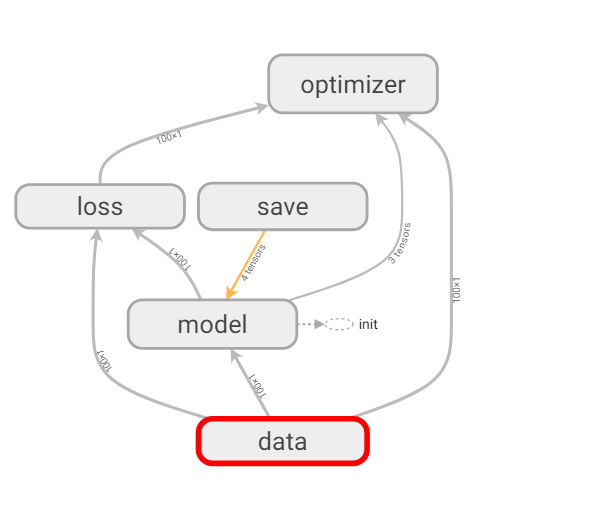 查看data作用域
查看data作用域 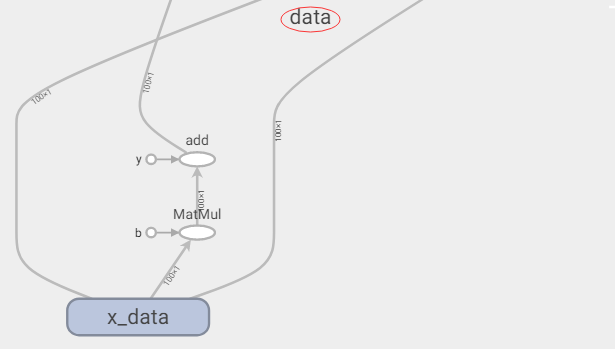
建立作用域之后,方便对代码块进行快速的划分,便于程序员对结构的掌控,也有利于在可视化中程序流程图的结构看到更加清晰
1 with tf.variable_scope("data"): #准备数据(即“data”)的作用域 2 # 1. 准备数据 [X, 特征值] 这里假设是100个样本,1个特征,即[100, 1], 目标值y是100个值,即[100] 3 x = tf.random_normal([100,1], mean=1.75, stddev=0.5, name="x_data") #自己定义一个假的数据集 4 y_ture = tf.matmul(x, [[0.7]]) + 0.8 #矩阵相乘,w值必须设置成相应的维数 5 6 with tf.variable_scope("model"): #模型的作用域 7 # 2. 建立线性回归模型 1个特征-->1个权重值, 一个偏置 y = x * w +b 8 # 随机给一个权重和偏置值, 然后计算损失函数,利用梯度下降在当前状态下优化损失函数 9 # 用变量定义才能优化 10 weights = tf.Variable(tf.random_normal([1,1],mean=0.0, stddev=1.0), name="w", trainable=True) #模型中的参数要用变量进行定义,在括号里面给一个随机的值,让模型从该值开始优化 11 bias = tf.Variable(0.0, name="b") #定义变量 12 y_predict = tf.matmul(x, weights) + bias #预测值 13 14 with tf.variable_scope("loss"): #损失的作用域 15 # 3. 建立计算损失函数,均方误差 16 loss = tf.reduce_mean(tf.square(y_ture - y_predict)) #平方之后,相加再除以总数 17 18 with tf.variable_scope("optimizer"): #优化的作用域 19 # 4. 梯度下降优化损失op (学习率: learning_rate) 20 train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss) #最小化损失 0.1是学习率(步长),自己调
