

CopyOnWriteArrayList 是如何保证线程安全的?
本文已收录到 AndroidFamily,技术和职场问题,请关注公众号 [彭旭锐] 提问。
前言
大家好,我是小彭。
在上一篇文章里,我们聊到了ArrayList 的线程安全问题,其中提到了 CopyOnWriteArrayList 的解决方法。那么 CopyOnWriteArrayList 是如何解决线程安全问题的,背后的设计思想是什么,今天我们就围绕这些问题展开。
本文源码基于 Java 8 CopyOnWriteArrayList。
小彭的 Android 交流群 02 群已经建立啦,扫描文末二维码进入~
思维导图:
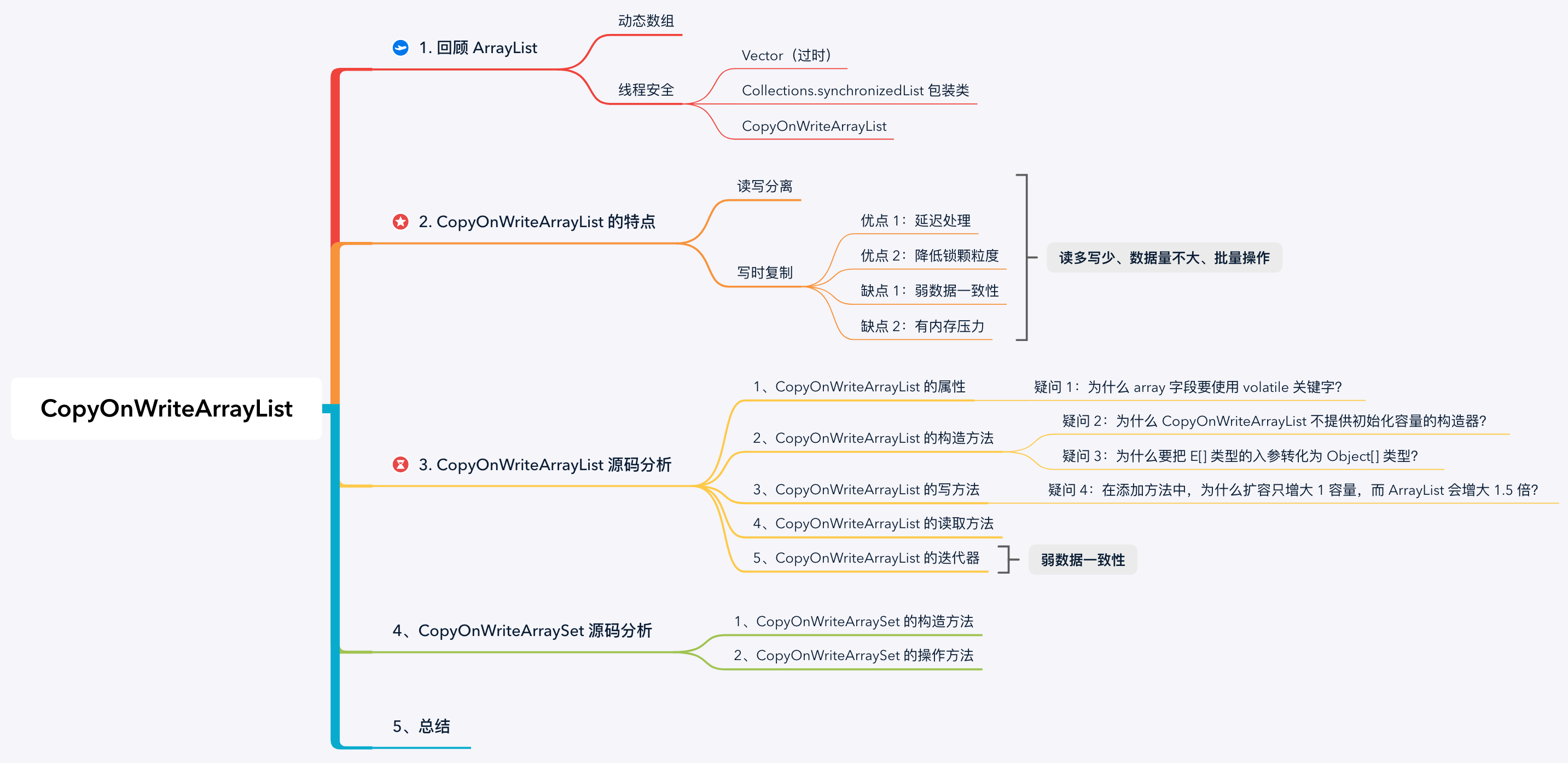
1. 回顾 ArrayList
ArrayList 是基于数组实现的动态数据,是线程不安全的。例如,我们在遍历 ArrayList 的时候,如果其他线程并发修改数组(当然也不一定是被其他线程修改),在迭代器中就会触发 fail-fast 机制,抛出 ConcurrentModificationException 异常。
示例程序
List<String> list = new ArrayList();
list.add("xiao");
list.add("peng");
list.add(".");
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
// 可能抛出 ConcurrentModificationException 异常
iterator.next();
}
要实现线程安全有 3 种方式:
- 方法 1 - 使用 Vector 容器: Vector 是线程安全版本的数组容器,它会在所有方法上增加 synchronized 关键字(过时,了解即可);
- 方法 2 - 使用 Collections.synchronizedList 包装类
- 方法 3 - 使用 CopyOnWriteArrayList 容器
Collections.synchronizedList 包装类的原理很简单,就是使用 synchronized 加锁,源码摘要如下:
Collections.java
public static <T> List<T> synchronizedList(List<T> list) {
return (list instanceof RandomAccess ?
new SynchronizedRandomAccessList<>(list) :
new SynchronizedList<>(list));
}
// 使用 synchronized 实现线程安全
static class SynchronizedList<E> extends SynchronizedCollection<E> implements List<E> {
final List<E> list;
public boolean equals(Object o) {
if (this == o) return true;
synchronized (mutex) {return list.equals(o);}
}
public int hashCode() {
synchronized (mutex) {return list.hashCode();}
}
public E get(int index) {
synchronized (mutex) {return list.get(index);}
}
public E set(int index, E element) {
synchronized (mutex) {return list.set(index, element);}
}
public void add(int index, E element) {
synchronized (mutex) {list.add(index, element);}
}
public E remove(int index) {
synchronized (mutex) {return list.remove(index);}
}
...
}
如果我们将 ArrayList 替换为 CopyOnWriteArrayList,即使其他线程并发修改数组,也不会抛出 ConcurrentModificationException 异常,这是为什么呢?
2. CopyOnWriteArrayList 的特点
CopyOnWriteArrayList 和 ArrayList 都是基于数组的动态数组,封装了操作数组时的搬运和扩容等逻辑。除此之外,CopyOnWriteArrayList 还是用了基于加锁的 “读写分离” 和 “写时复制” 的方案解决线程安全问题:
- 思想 1 - 读写分离(Read/Write Splitting): 将对资源的读取和写入操作分离,使得读取和写入没有依赖,在 “读多写少” 的场景中能有效减少资源竞争;
- 思想 2 - 写时复制(CopyOnWrite,COW): 在写入数据时,不直接在原数据上修改,而是复制一份新数据后写入到新数据,最后再替换到原数据的引用上。这个特性各有优缺点:
- 优点 1 - 延迟处理: 在没有写入操作时不会复制 / 分配资源,能够避免瞬时的资源消耗。例如操作系统的 fork 操作也是一种写时复制的思想;
- 优点 2 - 降低锁颗粒度: 在写的过程中,读操作不会被影响,读操作也不需要加锁,锁的颗粒度从整个列表降低为写操作;
- 缺点 1 - 弱数据一致性: 在读的过程中,如果数据被其他线程修改,是无法实时感知到最新的数据变化的;
- 缺点 2 - 有内存压力: 在写操作中需要复制原数组,在复制的过程中内存会同时存在两个数组对象(只是引用,数组元素的对象还是只有一份),会带来内存占用和垃圾回收的压力。如果是 “写多读少” 的场景,就不适合。
所以,使用 CopyOnWriteArrayList 的场景一定要保证是 “读多写少” 且数据量不大的场景,而且在写入数据的时候,要做到批量操作。否则每个写入操作都会触发一次复制,想想就可怕。举 2 个例子:
- 例如批量写入一组数据,要使用 addAll 方法 批量写入;
- 例如在做排序时,要先输出为 ArrayList,在 ArrayList 上完成排序后再写回 CopyOnWriteArrayList。
3. CopyOnWriteArrayList 源码分析
这一节,我们来分析 CopyOnWriteArrayList 中主要流程的源码。
3.1 CopyOnWriteArrayList 的属性
ArrayList 的属性很好理解,底层是一个 Object 数组,我要举手提问 🙋🏻♀️:
- 疑问 1: 为什么 array 字段要使用 volatile 关键字?
// 锁
final transient ReentrantLock lock = new ReentrantLock();
// 在 Java 11 中,ReentrantLock 被替换为 synchronized 锁
// The lock protecting all mutators. (We have a mild preference for builtin monitors over ReentrantLock when either will do.)
final transient Object lock = new Object();
// 底层数组
// 疑问 1:为什么 array 要使用 volatile 关键字?
private transient volatile Object[] array;
这个问题我们在分析源码的过程中回答。有了 ArrayList 的分析基础,疑问也变少了,CopyOnWriteArrayList 真香。
3.2 CopyOnWriteArrayList 的构造方法
构造器的源码不难,但小朋友总有太多的问号,举手提问 🙋🏻♀️:
- 疑问 2:为什么 CopyOnWriteArrayList 不提供初始化容量的构造器?
这是因为 CopyOnWriteArrayList 建议我们使用批量操作写入数据。如果提供了带初始化容量的构造器,意味着开发者预期会一个个地写入数据,这不符合 CopyOnWriteArrayList 的正确使用方法。所以,不提供这个构造器才是合理的。
- 疑问 3:为什么要把 E[] 类型的入参转化为 Object[] 类型?
如果不转化数组类型,那么在 toArray() 方法返回的数组中插入 Object 类型对象时,会抛出 ArrayStoreException。
提示: 这个问题与 “奇怪” 分支的原因相同,具体分析可以看讲 《Java 面试题:ArrayList 可以完全替代数组吗?》 的文章中,这里不重复讲了。
// 疑问 2:为什么 CopyOnWriteArrayList 不提供预初始化容量的构造器?
// 无参构造方法
public CopyOnWriteArrayList() {
// 创建空数组
setArray(new Object[0]);
}
// 带集合的构造方法
public CopyOnWriteArrayList(Collection<? extends E> c) {
Object[] elements;
if (c.getClass() == CopyOnWriteArrayList.class)
elements = ((CopyOnWriteArrayList<?>)c).getArray();
else {
elements = c.toArray();
// 这个“奇怪”的分支在 ArrayList 文章中分析过,去看看
if (elements.getClass() != Object[].class)
elements = Arrays.copyOf(elements, elements.length, Object[].class);
}
setArray(elements);
}
// 带数组的构造方法
public CopyOnWriteArrayList(E[] toCopyIn) {
// 疑问 3:为什么要把 E[] 类型的入参转化为 Object[] 类型
setArray(Arrays.copyOf(toCopyIn, toCopyIn.length, *Object[]*.class));
}
final Object[] getArray() {
return array;
}
final void setArray(Object[] a) {
array = a;
}
public Object[] toArray() {
Object[] elements = getArray();
return Arrays.copyOf(elements, elements.length);
}
3.3 CopyOnWriteArrayList 的写方法
我们将 CopyOnWriteArrayList 的添加、删除和修改方法统一为 “写方法”,三种写方法的模板其实是一样的:
- 1、在写入之前先获取对象的锁;
- 2、复制新数组;
- 3、在新数组上完成写入操作;
- 4、将新数组设置为底层数组;
- 5、释放对象的锁。
小朋友总是有太多问号,举手提问 🙋🏻♀️:
- 疑问 4:在添加方法中,为什么扩容只增大 1 容量,而 ArrayList 会增大 1.5 倍?
这还是因为 CopyOnWriteArrayList 建议我们使用批量操作写入数据。ArrayList 额外扩容 1.5 倍是为了避免每次 add 都扩容,而 CopyOnWriteArrayList 并不建议一个个地添加数据,而是建议批量操作写入数据,例如 addAll 方法。所以,CopyOnWriteArrayList 不额外扩容才是合理的。
另外,网上有观点看到 CopyOnWriteArrayList 没有限制数组最大容量,就说 CopyOnWriteArrayList 是无界的,没有容量限制。这显然太表面了。数组的长度限制是被虚拟机固化的,CopyOnWriteArrayList 没有限制的原因是:它没有做额外扩容,而且不适合大数据的场景,所以没有限制的必要。
最后还剩下 1 个问题:
- 疑问 1:为什么 array 字段要使用 volatile 关键字?
volatile 变量是 Java 轻量级的线程同步原语,volatile 变量的读取和写入操作中会加入内存屏障,能够保证变量写入的内存可见性,保证一个线程的写入能够被另一个线程观察到。
添加方法
// 在数组尾部添加元素
public boolean add(E e) {
final ReentrantLock lock = this.lock;
// 获取锁
lock.lock();
// 复制新数组
Object[] elements = getArray();
int len = elements.length;
// 疑问 4:在添加方法中,为什么扩容只增大 1 容量,而 ArrayList 会增大 1.5 倍?
Object[] newElements = Arrays.copyOf(elements, len + 1 /* 容量 + 1*/);
// 在新数组上添加元素
newElements[len] = e;
// 设置新数组
setArray(newElements);
// 释放锁
lock.unlock();
return true;
}
// 在数组尾部添加元素
public void add(int index, E element) {
// 原理相同,省略
...
}
// 批量在数组尾部添加元素
public boolean addAll(Collection<? extends E> c) {
// 原理相同,省略
...
}
修改方法
// 修改数组元素
public E set(int index, E element) {
final ReentrantLock lock = this.lock;
// 获取锁
lock.lock();
// 旧元素
Object[] elements = getArray();
E oldValue = get(elements, index);
if (oldValue != element) {
// 复制新数组
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len);
// 在新数组上添加元素
newElements[index] = element;
// 设置新数组
setArray(newElements);
} else {
// Not quite a no-op; ensures volatile write semantics
setArray(elements);
}
// 释放锁
lock.unlock();
// 返回旧数据
return oldValue;
}
删除方法
// 删除数组元素
public E remove(int index) {
final ReentrantLock lock = this.lock;
// 获取锁
lock.lock();
Object[] elements = getArray();
int len = elements.length;
// 旧元素
E oldValue = get(elements, index);
int numMoved = len - index - 1;
if (numMoved == 0)
// 删除首位元素
setArray(Arrays.copyOf(elements, len - 1));
else {
// 删除中间元素
// 复制新数组
Object[] newElements = new Object[len - 1];
System.arraycopy(elements, 0, newElements, 0, index);
System.arraycopy(elements, index + 1, newElements, index, numMoved);
// 设置新数组
setArray(newElements);
}
// 释放锁
lock.unlock();
// 返回旧数据
return oldValue;
}
3.4 CopyOnWriteArrayList 的读取方法
可以看到读取方法并没有加锁。
private E get(Object[] a, int index) {
return (E) a[index];
}
public E get(int index) {
return get(getArray(), index);
}
public boolean contains(Object o) {
Object[] elements = getArray();
return indexOf(o, elements, 0, elements.length) >= 0;
}
3.5 CopyOnWriteArrayList 的迭代器
CopyOnWriteArrayList 的迭代器 COWIterator 是 “弱数据一致性的” ,所谓数据一致性问题讨论的是同一份数据在多个副本之间的一致性问题,你也可以理解为多个副本的状态一致性问题。例如内存与多核心 Cache 副本之间的一致性,或者数据在主从数据库之间的一致性。
提示: 关于 “数据一致性和顺序一致性” 的区别,在小彭的计算机组成原理专栏讨论过 《已经有 MESI 协议,为什么还需要 volatile 关键字?》,去看看。
为什么是 “弱” 的呢?这是因为 COWIterator 迭代器会持有 CopyOnWriteArrayList “底层数组” 的引用,而 CopyOnWriteArrayList 的写入操作是写入到新数组,因此 COWIterator 是无法感知到的,除非重新创建迭代器。
相较之下,ArrayList 的迭代器是通过持有 “外部类引用” 的方式访问 ArrayList 的底层数组,因此在 ArrayList 上的写入操作会实时被迭代器观察到。
CopyOnWriteArrayList.java
// 注意看:有 static 关键字,直接引用底层数组
static final class COWIterator<E> implements ListIterator<E> {
// 底层数组
private final Object[] snapshot;
private int cursor;
private COWIterator(Object[] elements, int initialCursor) {
cursor = initialCursor;
snapshot = elements;
}
}
ArrayList.java
// 注意看:没有 static 关键字,通过外部类引用来访问底层数组
private class Itr implements Iterator<E> {
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
Itr() {}
...
}
3.6 CopyOnWriteArraySet 的序列化过程
与 ArrayList 类似,CopyOnWriteArraySet 也重写了 JDK 序列化的逻辑,只把 elements 数组中有效元素的部分序列化,而不会序列化整个数组。
同时,ReentrantLock 对象是锁对象,序列化没有意义。在反序列化时,会通过 resetLock() 设置一个新的 ReentrantLock 对象。
// 序列化过程
private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException {
s.defaultWriteObject();
Object[] elements = getArray();
// 写入数组长度
s.writeInt(elements.length);
// 写入有效元素
for (Object element : elements)
s.writeObject(element);
}
// 反序列化过程
private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException {
s.defaultReadObject();
// 设置 ReentrantLock 对象
resetLock();
// 读取数组长度
int len = s.readInt();
SharedSecrets.getJavaOISAccess().checkArray(s, Object[].class, len);
// 创建底层数组
Object[] elements = new Object[len];
// 读取数组对象
for (int i = 0; i < len; i++)
elements[i] = s.readObject();
// 设置新数组
setArray(elements);
}
// 疑问 5:resetLock() 方法不好理解,解释一下?
private void resetLock() {
// 等价于带 Volatile 语义的 this.lock = new ReentrantLock()
UNSAFE.putObjectVolatile(this, lockOffset, new ReentrantLock());
}
// Unsafe API
private static final sun.misc.Unsafe UNSAFE;
// lock 字段在对象实例数据中的偏移量
private static final long lockOffset;
static {
// 这三行的作用:lock 字段在对象实例数据中的偏移量
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = CopyOnWriteArrayList.class;
lockOffset = UNSAFE.objectFieldOffset(k.getDeclaredField("lock"));
}
小朋友又是有太多问号,举手提问 🙋🏻♀️:
- 🙋🏻♀️疑问 5:
resetLock()方法不好理解,解释一下?
在 static 代码块中,会使用 Unsafe API 获取 CopyOnWriteArrayList 的 “lock 字段在对象实例数据中的偏移量” 。由于字段的偏移是全局固定的,所以这个偏移量可以记录在 static 字段 lockOffset 中。
在 resetLock() 中,通过 UnSafe API putObjectVolatile 将新建的 ReentrantLock 对象设置到 CopyOnWriteArrayList 的 lock 字段中,等价于带 volatile 语义的 this.lock = new ReentrantLock(),保证这个字段的写入具备内存可见性。
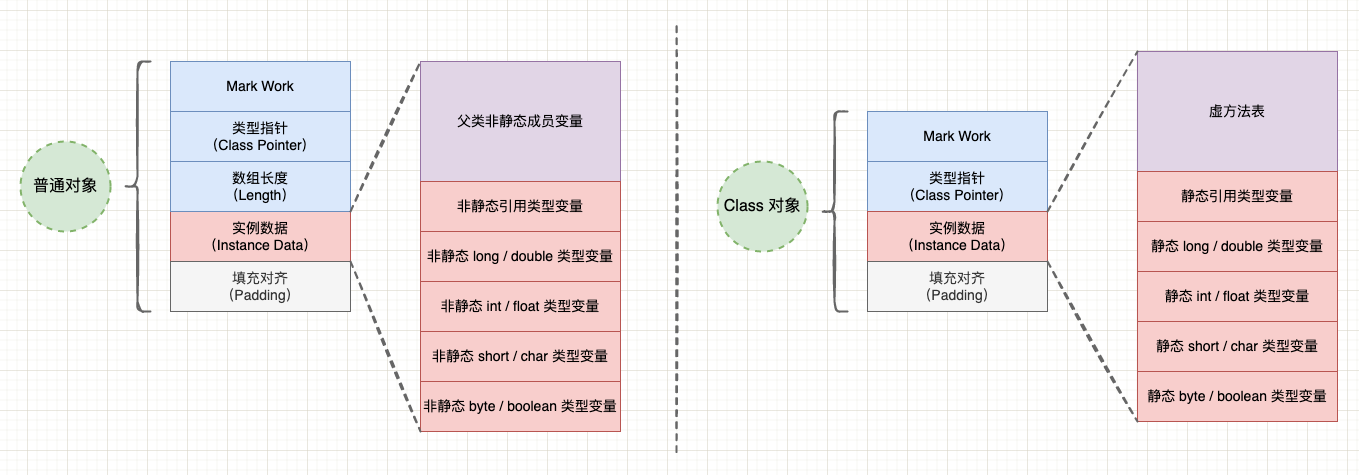
字段的偏移量是什么意思呢?简单来说,普通对象和 Class 对象的实例数据区域是不同的:
- 1、普通对象: 包括当前类声明的实例字段以及父类声明的实例字段,不包括类的静态字段。UnSafe API objectFieldOffset(Filed) 就是获取了参数 Filed 在实例数据中的偏移量,后续就可以通过这个偏移量为字段赋值;
- 2、Class 对象: 包括当前类声明的静态字段和方法表等。
对象内存布局
提示: 关于字段的偏移量,我们在 《对象的内存分为哪几个部分?》 这篇文章里讨论过,去看看。
3.7 CopyOnWriteArraySet 的 clone() 过程
CopyOnWriteArraySet 的 clone() 很巧妙。按照正常的思维,CopyOnWriteArraySet 中的 array 数组是引用类型,因此在 clone() 中需要实现深拷贝,否则原对象与克隆对象就会相互影响。但事实上,array 数组并没有被深拷贝,哇点解啊?
- 🙋🏻♀️疑问 6:为什么 array 数组没有深拷贝?
这就是因为 CopyOnWrite 啊!没有 Write 为什么要 Copy 呢?(我觉得已经提醒到位了,只要你仔细阅读前文对 CopyOnWrite 的论证,你一定会懂的。要是是在不懂,私信我吧~)
public Object clone() {
try {
@SuppressWarnings("unchecked")
// 疑问 6:为什么 array 数组没有深拷贝?
CopyOnWriteArrayList<E> clone = (CopyOnWriteArrayList<E>) super.clone();
// 设置 ReentrantLock 对象(相当于 lock 字段的深拷贝)
clone.resetLock();
return clone;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError();
}
}
4. CopyOnWriteArraySet 源码分析
在 Java 标准库中,还提供了一个使用 COW 思想的 Set 集合 —— CopyOnWriteArraySet。
CopyOnWriteArraySet 和 HashSet 都是继承于 AbstractSet 的,但 CopyOnWriteArraySet 是基于 CopyOnWriteArrayList 动态数组的,并没有使用哈希思想。而 HashSet 是基于 HashMap 散列表的,能够实现 O(1) 查询。
4.1 CopyOnWriteArraySet 的构造方法
看一下 CopyOnWriteArraySet 的构造方法,底层就是有一个 CopyOnWriteArrayList 动态数组。
CopyOnWriteArraySet.java
public class CopyOnWriteArraySet<E> extends AbstractSet<E> implements java.io.Serializable {
// 底层就是 OnWriteArrayList
private final CopyOnWriteArrayList<E> al;
// 无参构造方法
public CopyOnWriteArraySet() {
al = new CopyOnWriteArrayList<E>();
}
// 带集合的构造方法
public CopyOnWriteArraySet(Collection<? extends E> c) {
if (c.getClass() == CopyOnWriteArraySet.class) {
// 入参是 CopyOnWriteArraySet,说明是不重复的,直接添加
CopyOnWriteArraySet<E> cc = (CopyOnWriteArraySet<E>)c;
al = new CopyOnWriteArrayList<E>(cc.al);
}
else {
// 使用 addAllAbsent 添加不重复的元素
al = new CopyOnWriteArrayList<E>();
al.addAllAbsent(c);
}
}
public int size() {
return al.size();
}
}
4.2 CopyOnWriteArraySet 的操作方法
CopyOnWriteArraySet 的方法基本上都是交给 CopyOnWriteArraySet 代理的,由于没有使用哈希思想,所以操作的时间复杂度是 O(n)。
CopyOnWriteArraySet.java
public boolean add(E e) {
return al.addIfAbsent(e);
}
public boolean contains(Object o) {
return al.contains(o);
}
CopyOnWriteArrayList.java
public boolean addIfAbsent(E e) {
Object[] snapshot = getArray();
return indexOf(e, snapshot, 0, snapshot.length) >= 0 ? false : addIfAbsent(e, snapshot);
}
public boolean contains(Object o) {
Object[] elements = getArray();
return indexOf(o, elements, 0, elements.length) >= 0;
}
// 通过线性扫描匹配元素位置,而不是计算哈希匹配,时间复杂度是 O(n)
private static int indexOf(Object o, Object[] elements, int index, int fence) {
if (o == null) {
for (int i = index; i < fence; i++)
if (elements[i] == null) return i;
} else {
for (int i = index; i < fence; i++)
if (o.equals(elements[i])) return i;
}
return -1;
}
5. 总结
-
1、CopyOnWriteArrayList 和 ArrayList 都是基于数组的动态数组,封装了操作数组时的搬运和扩容等逻辑;
-
2、CopyOnWriteArrayList 还是 “读写分离” 和 “写时复制” 的方案解决线程安全问题;
-
3、使用 CopyOnWriteArrayList 的场景一定要保证是 “读多写少” 且数据量不大的场景,而且在写入数据的时候,要做到批量操作;
-
4、CopyOnWriteArrayList 的迭代器是 “弱数据一致性的” 的,迭代器会持有 “底层数组” 的引用,而 CopyOnWriteArrayList 的写入操作是写入到新数组,因此迭代器是无法感知到的;
-
5、CopyOnWriteArraySet 是基于 CopyOnWriteArrayList 动态数组的,并没有使用哈希思想。
小彭的 Android 交流群 02 群


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY