常用JVM垃圾回收算法
前言
谈常用GC回收算法之前,先说一下引用计数法
算法原理
引用计数算法很简单,它实际上是通过在对象头中分配一个空间来保存该对象被引用的次数。如果该对象被其它对象引用,则它的引用计数加一,如果删除对该对象的引用,那么它的引用计数就减一,当该对象的引用计数为0时,那么该对象就会被回收。
比如说,当我们编写以下代码时,
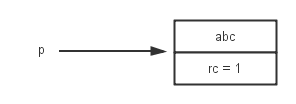
String p = new String("abc")
abc这个字符串对象的引用计数值为1
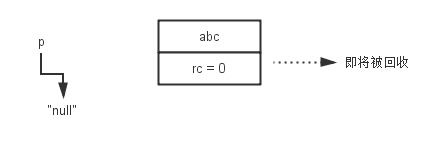
而当我们去除abc字符串对象的引用时,则abc字符串对象的引用计数减1
常用GC回收算法
一、复制算法(Copying)
所谓复制算法(Copying),即将内存平均分成A区、B区两块,进行复制+清除垃圾的操作,算法图解如下:

算法过程:
- 新生对象被分配到A块中未使用的内存当中。当A块的内存用完了, 把A块的存活对象复制到B块。
- 清理A块所有对象。
- 新生对象被分配到B块中未使用的内存当中。当B块的内存用完了, 把B块的存活对象复制到A块。
- 清理B块所有对象。
- 循环1。
分析:
这种算法简单高效,但是内存代价极高,有效内存只为总内存的一半,会浪费掉50%的空间。所以这种算法只是纸面算法,不具备可用性,一般来说都会使用优化的复制算法。
适用场景:
这种方法不涉及到对象的删除,只是把可用的对象从一个地方拷贝到另一个地方,因此适合大量对象回收的场景,比如新生代的回收。
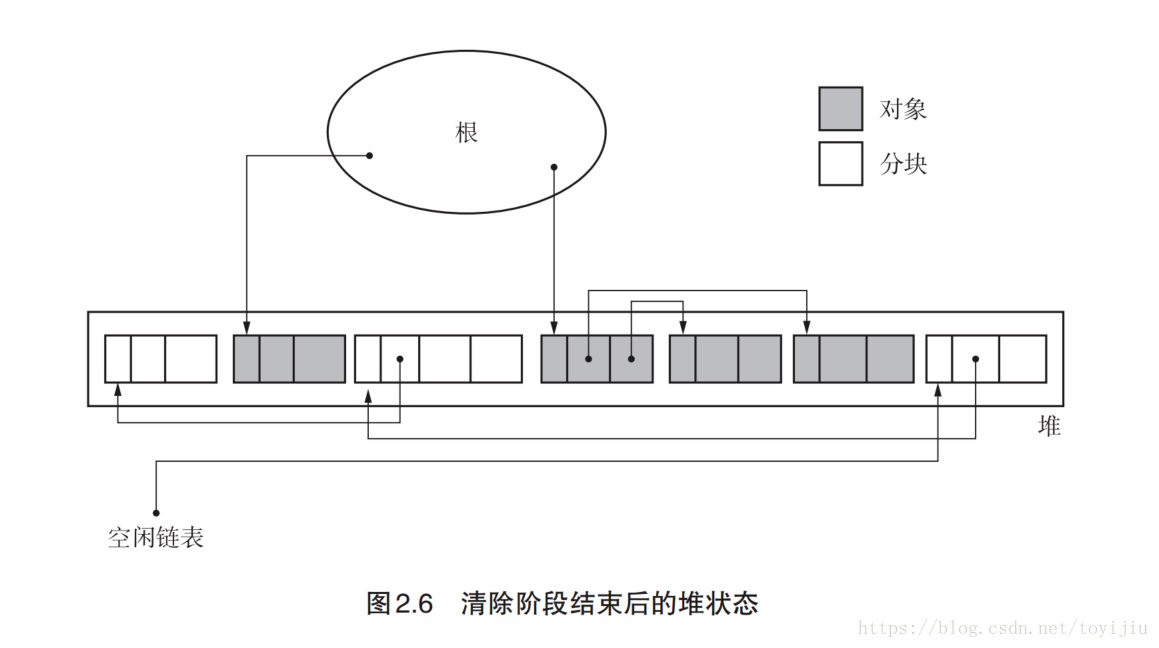
二、标记清除算法(Mark-Sweep)
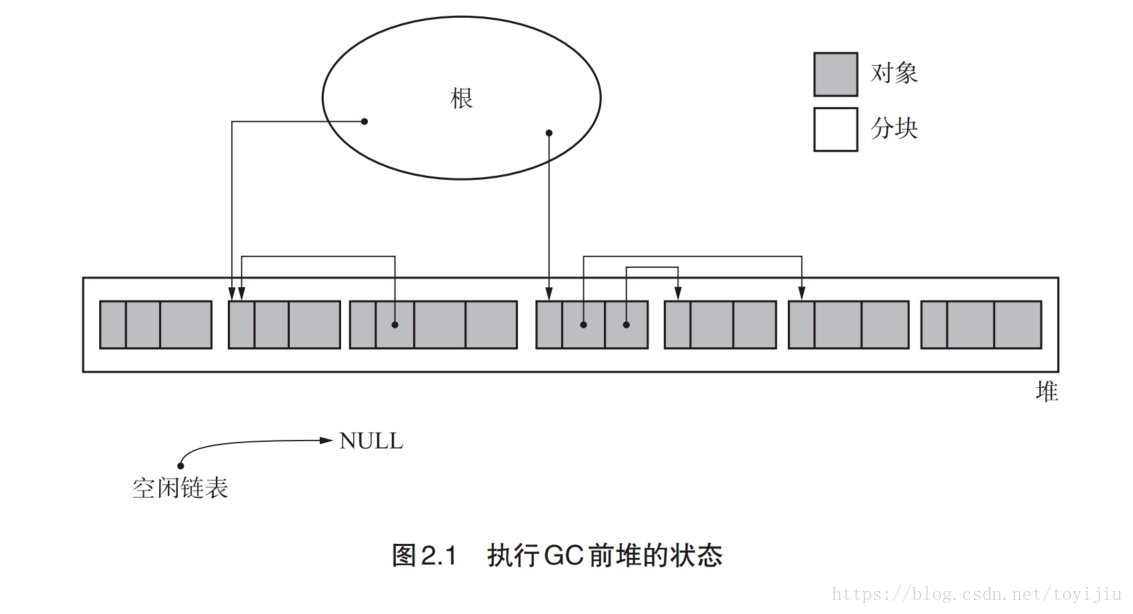
由标记阶段和清除阶段组成。标记是把所有活动对象做上标记,清除是把哪些没有标记(活动)的对象回收的阶段。
标记阶段
伪代码:
1 mark(obj){ 2 if(obj.mark == FALSE) 3 obj.mark = TRUE 4 for(child : children(obj)) 5 mark(*child) 6 } 7 8 mark_phase(){ 9 for(r : $roots) 10 mark(*r) 11 }
标记阶段从root开始递归地给堆里所有对象打上标记。标记算法一般是用深度或者广度搜索,深度搜索可以压缩内存使用量,所以一般用深度
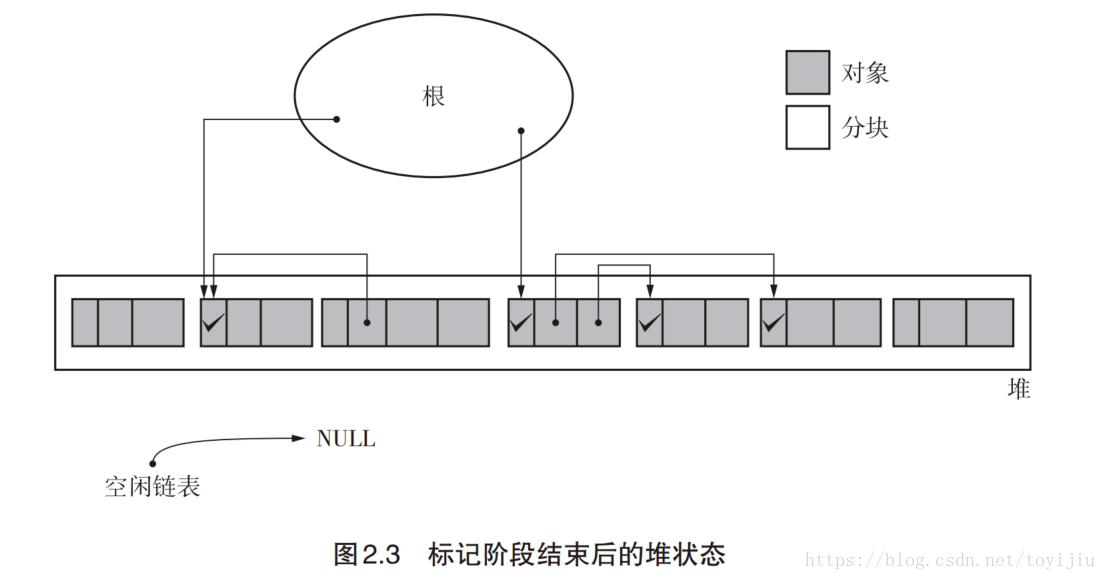
清除阶段
collector会遍历整个堆,回收没有被标记的对象,将要回收的block插入free_list 链表,还在使用的对象则取消标志位
伪代码:
1 sweep_phase(){ 2 sweeping = $heap_start 3 while(sweeping < $heap_end) 4 if(sweeping.mark == TRUE) 5 sweeping.mark = FALSE 6 else 7 //将需要回收的block头插入到free_list 链表,再跳到下一个block 8 sweeping.next = $free_list 9 $free_list = sweeping 10 sweeping += sweeping.size 11 }
三、标记整理算法(Mark-compact)
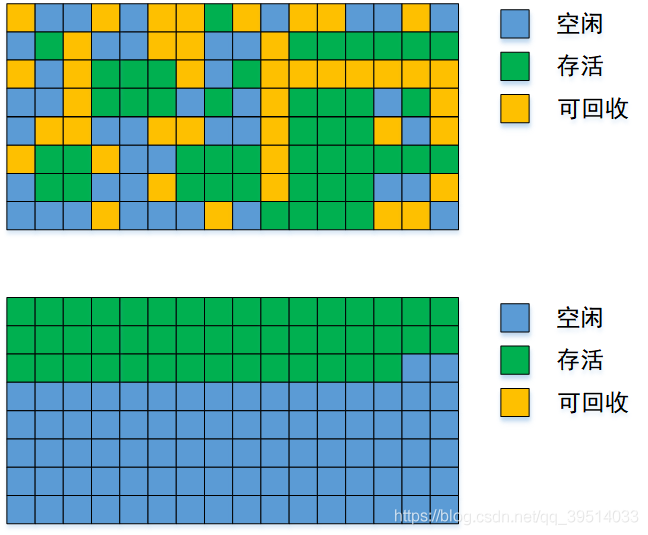
内存碎片问题:每次回收的内存都是比较分散的, 可以加起来是一个比较大的数值, 但是由于可用内存都不连续, 没有办法分配给需要内存较多的新对象, 因此导致这些内存被浪费掉。
或许聪明的你会有这样的一个问题: 如果我的内存空间特别大, 每次回收对象都很多, 即使回收空间很碎, 也还好吧?
对这个问题的回答是, 碎片始终是带来的利用率的下降, 并且也带来了管理上的成本(指针会多很多).
另外, 在回答这个问题之后, 还有一点要强调一下, 就是GC机制是一个平民机制, 土豪同学其实可以不用学这个. 因为假设你足够豪也足够土, 你可以购置一个超级大的内存, 然后让你的JAVA进程欢快的在上面申请个几百年也不用担心内存被用满的情况.
为啥会引出标记整理算法呢?
原因:为了解决内存碎片问题
标记/整理算法与标记/清除算法非常相似,它也是分为两个阶段:标记和整理。下面给各位介绍一下这两个阶段都做了什么。
- 标记:它的第一个阶段与标记/清除算法是一模一样的,均是遍历GC Roots,然后将存活的对象标记。
- 整理:移动所有存活的对象,且按照内存地址次序依次排列,然后将末端内存地址以后的内存全部回收。因此,第二阶段才称为整理阶段。
问题:为什么非要等到标记全部结束才开始整理, 为什么不一边标记一边整理?
原因:对象的遍历过程和内存的摆放顺序不是一致的, 很可能一个对象摆放在内存的前面部分, 但是需要等到最后的时候才能遍历到这个对象, 因此, 如果提前开始整理, 会影响到这个对象.
不足之处:标记整理算法解决了内存碎片的问题, 但是也带来一个问题, 就是效率比原来的标记清除算法要低, 主要的原因在于需要在标记结束之后, 整理所有存活对象的引用地址。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号