(R计划分享)浅谈非关系型数据库Redis
一、Redis是什么
百度百科:Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
Redis是一种Key-Value存储形式的非关系型的内存数据库,整个数据库加载在内存当中操作,定期通过异步操作把数据库中的数据flush到硬盘上进行保存。
整个数据库加载在内存当中操作,定期通过异步操作把数据库中的数据flush到硬盘上进行保存。
优点:
- 读写性能极高, Redis能读的速度是110000次/s,写的速度是81000次/s。
- 支持数据持久化,支持AOF和RDB两种持久化方式。
- 支持事务, Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
- 数据结构丰富,除了支持string类型的value外,还支持hash、set、zset、list等数据结构。
- 支持主从复制,主机会自动将数据同步到从机,可以进行读写分离。
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等特性。
缺点:
- 数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。
二、Redis安装
Linux:Linux安装包下载
Windows:redis下载安装教程-Windows版本(详细)
注意:Redis官方只有Linux系统安装包,Windows版本是他人封装出来的。
三、基本数据类型
- string:字符串类型(键-值)
- list:列表类型(键-集合 可以重复)
- set:集合类型(键-集合 不可以重复)
- hash:哈希类型(键-键值对)
- zset:有序集合(键-值-值 不可以重复)
3.1 string
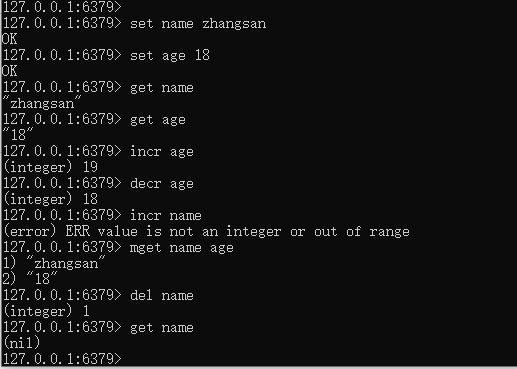
set [key] [value] 插入键值对
get [key] 获取值
incr [key] 自增(值为integer类型)
decr [key] 自减(值为integer类型)
mget [key...] 获取多个值
del [key] 删除键值对
3.2 list
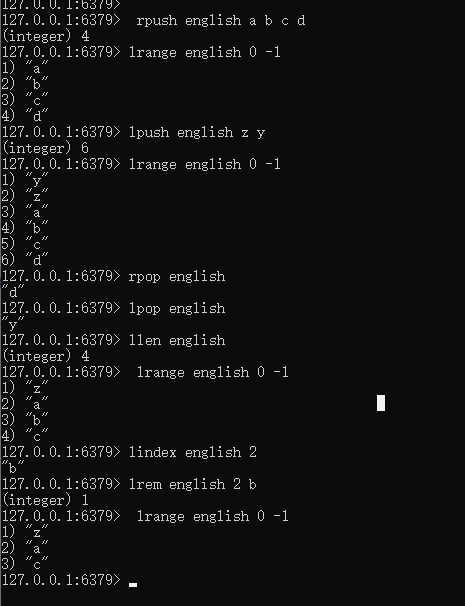
lpush [key] [value...] 从列表list的左边插入一个元素 lpop [key] 从列表list的左边移除一个元素 rpush [key] [value...] 从列表list的右边插入一个元素 rpop [key] 从列表list的右边移除一个元素 lrange [key] [start] [stop] 从列表中获取对应下标的值[start,stop] llen [key] 打印当前列表list中的元素个数 lindex [key] [index] 获取指定列表中指定下标的元素 lrem [key] [count] [value] 根据count值移除指定列表中跟value相等的数据 //count>0:从列表的左侧移除count个跟value相等的数据; //count<0:从列表的右侧移除count个跟vlaue相等的数据; //count=0:从列表中移除所有跟value相等的数据
ltrim key startIndex endIndex 截取指定列表中指定下标区间的元素组成新的列表,并且赋值给key
lset key index value 将指定列表中指定下标的元素设置为指定值
linsert key before/after pivot vlaue 将value插入到指定列表中位于pivot元素之前/之后的位置
3.3 set
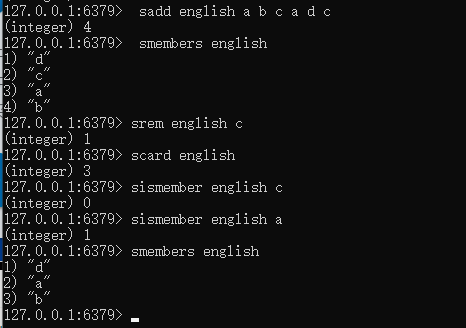
sadd [key] [member...] 往set中添加数据()
srem [key] [member...] 从set中删除数据
smembers [key] 获取集合 key 中的所有成员元素,不存在的 key 视为空集合
scard [key] 查看set中存在的元素个数
sismember [key] [member] 查看set中是否存在某个数据
3.4 hash
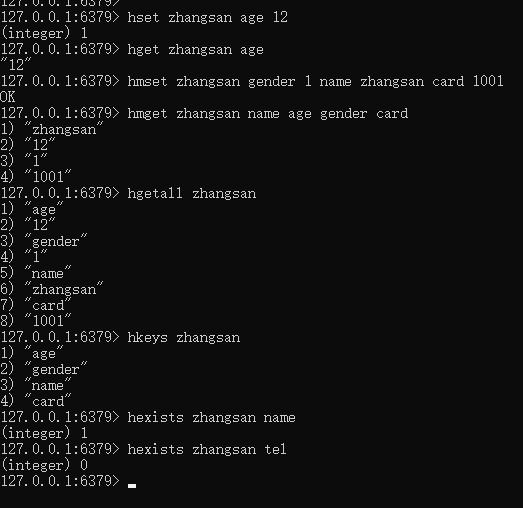
hset [key] [field] [value] 往hash里,添加key-[field-value]
hget [key] [field] 通过key值,从hash里取对应的value
hmget [key] [field...] 一次性获取多个key的value
hmset [key] [field value...] 一次性添加多个key的value
hgetall <key> 查看key的所有键值对
hkeys <key> 返回所有hash表中的key的所有域
hexists <key> <field> 查看hash表中,给定key的域field是否存在。如果存在,则返回1
3.5 zset
zadd [key] [score member ...] 添加数据,score表示member成员的得分,根据得分排序
zcard [key] 查询成员数据个数
zrange [key] [start] [stop] 数据排序,根据分数从小到大
zrevrange [key] [start] [stop] 数据排序,根据分数从大到小

3.6 特殊数据类型
1、Bitmap:
位图,Bitmap想象成一个以位为单位数组,数组中的每个单元只能存0或者1,数组的下标在Bitmap中叫做偏移量。使用Bitmap实现统计功能,更省空间。如果只需要统计数据的二值状态,例如商品有没有、用户在不在等,就可以使用 Bitmap,因为它只用一个 bit 位就能表示 0 或 1。
2、HyperLogLog:
HyperLogLog 是一种用于统计基数的数据集合类型,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。
场景:统计网页的UV(即Unique Visitor,不重复访客,一个人访问某个网站多次,但是还是只计算为一次)。
要注意,HyperLogLog 的统计规则是基于概率完成的,所以它给出的统计结果是有一定误差的,标准误算率是 0.81%。
3、Geospatial :
主要用于存储地理位置信息,并对存储的信息进行操作,适用场景如朋友的定位、附近的人、打车距离计算等。
四、Redis的高性能
-
内存存储:Redis是使用内存(in-memeroy)存储,没有磁盘IO上的开销。数据存在内存中,类似于 HashMap,HashMap 的优势就是查找和操作的时间复杂度都是O(1)。
-
单线程实现( Redis 6.0以前):Redis使用单个线程处理请求,避免了多个线程之间线程切换和锁资源争用的开销。注意:单线程是指的是在核心网络模型中,网络请求模块使用一个线程来处理,即一个线程处理所有网络请求。
-
非阻塞IO:Redis使用多路复用IO技术,将epoll作为I/O多路复用技术的实现,再加上Redis自身的事件处理模型将epoll中的连接、读写、关闭都转换为事件,不在网络I/O上浪费过多的时间。
-
优化的数据结构:Redis有诸多可以直接应用的优化数据结构的实现,应用层可以直接使用原生的数据结构提升性能。
-
使用底层模型不同:Redis直接自己构建了 VM (虚拟内存)机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
Redis属于缓存数据库,数据存放在内存中,当程序获取数据时,直接通过内存调用,极大的提高了Redis 的性能。
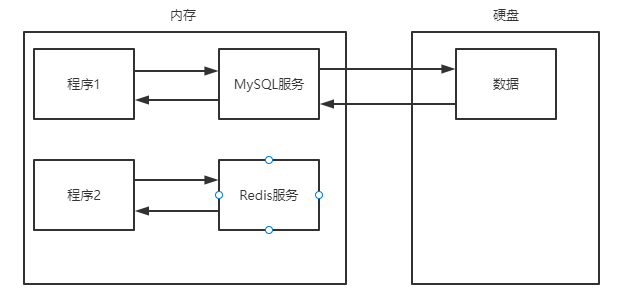
在一般项目中,常常是根据不同的应用场景,结合各数据库的特点,选择性的使用数据库,例如MySQL和Redis这两种数据库结合起来使用会达到一种比较理想的效果。
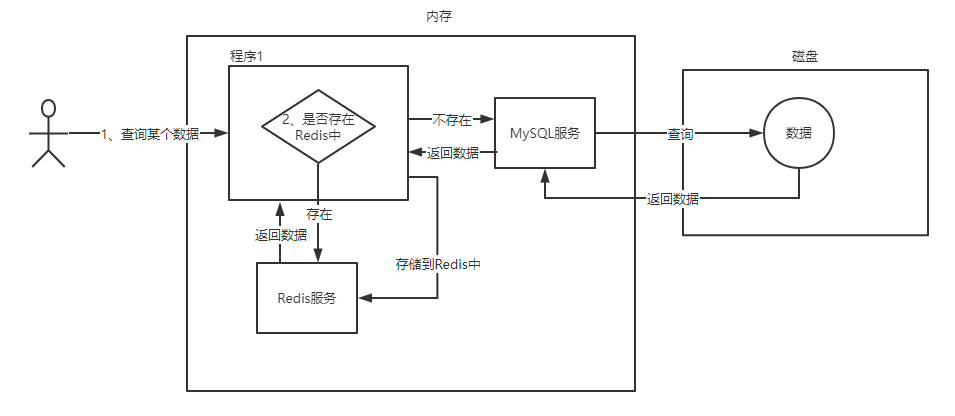
五、Redis的内存回收策略
5.1 过期回收策略
删除到达过期时间的键对象。
- 惰性删除:惰性删除用于当客户端读取带有超时属性的键时,如果已经超过键设置的过期时间,会执行删除操作并返回空,这种策略是出于节省CPU成本考虑,不需要单独维护TTL链表来处理过期键的删除。但是单独用这种方式存在内存泄露的问题,当过期键一直没有访问将无法得到及时删除,从而导致内存不能及时释放。正因为如此,Redis还提供另一种定时任务删除机制作为惰性删除的补充。
- 定时任务删除:Redis内部维护一个定时任务,默认每秒运行10次(通过配置hz控制)。定时任务中删除过期键逻辑采用了自适应算法,根据键的过期比例,使用快慢两种速率模式回收键。
- 定时任务在每个数据库空间随机检查20个键,当发现过期时删除对应的键。
- 如果超过检查数25%的键过期,循环执行回收逻辑直到不足25%或运行超时为止,慢模式下超时时间为25ms。
- 如果之前回收键逻辑超时,则在Redis触发内部事件之前再次以快模式运行回收过期键任务,快模式下超时时间为1ms且2s内只能运行1次。
- 快慢两种模式内部删除逻辑相同,只是执行的超时时间不同。
5.2 内存溢出控制策略
- noeviction:默认策略,当内存不足以容纳新写入数据时,新写入操作会报错。应该没人用吧。
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 Key。推荐使用,目前很多项目在用这种。
- allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个 Key。很少用。
- volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的 Key。这种情况一般是把 Redis 既当缓存,又做持久化存储的时候才用。不推荐。
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个 Key。依然不推荐。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的 Key 优先移除。不推荐。如果没有对应的键,则回退到noeviction策略。
六、Redis缓存雪崩、缓存穿透、缓存击穿
6.1缓存雪崩
redis雪崩是指,在某个时间key大量失效,或者redis服务宕机了,突然造成数据库访问压力急剧增大,像雪崩一样。redis雪崩危害巨大,甚至有可能导致整个服务器宕机,给公司造成巨大的经济损失。
解决方法:
1、建立Redis集群,避免宕机。
2、设置超时时间的时候要设置随机值,不要设置固定值
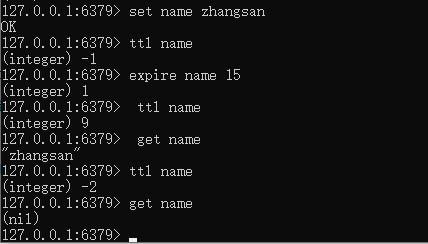
ttl [key] 查看key的超时时间,以秒计算,-1代表没有超时时间,如果不存在key或者key已经超时则为-2
expire [key] [seconds] 设置超时时间戳,以秒为单位
6.2缓存穿透
缓存穿透是指缓存和数据库中都没有这个数据,而用户不断发起请求。由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
解决办法:
1、设置过滤器,对于不存在的key进行过滤。
例如:
2、不存在的key也加到缓存中,设置值为null,但它的过期时间会很短,最长不超过五分钟。(常用)
6.3缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),某个时刻由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。
解决方案:
1.设置热点数据永不过期
2.加互斥锁(mutex key)
- 缓存雪崩 Redis服务宕机或大量key失效
- 缓存穿透 Redis和数据库都没有这个数据
- 缓存击穿 Redis中没有数据,数据库中有数据
七、Redis持久化
数据存放在内存中,虽然访问速度极快,但是数据存储却不安全,若出现断电等情况,内存中数据将会丢失,所以Redis有一系列持久化机制。
7.1RDB(快照)
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘。也是默认的持久化方式,这种方式是就是将内存中数据以快照的方式写入到二进制文件中,默认的文件名为dump.rdb。
修改redis.config中配置文件
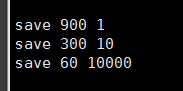
触发条件,900秒内,1个key值被修改。(两者必须同时满足才能够)
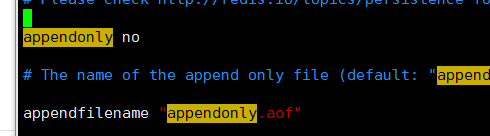
7.2AOF(全量)
AOF持久化后,每执行一条会更改Redis中的数据的命令,Redis就会将该命令写入硬盘中的AOF文件,这一过程显然会降低Redis的性能。
需要手动设置appendonly为yes
本文仅限于技术交流,若造成不良影响,本文创作人员概不负责,请支持正版应用,注重产权保护!!
(您的“打赏”将是我最大的写作动力!转载请注明出处.)
 关注微信公众号 |
