CDN基础详解
什么是 CDN?
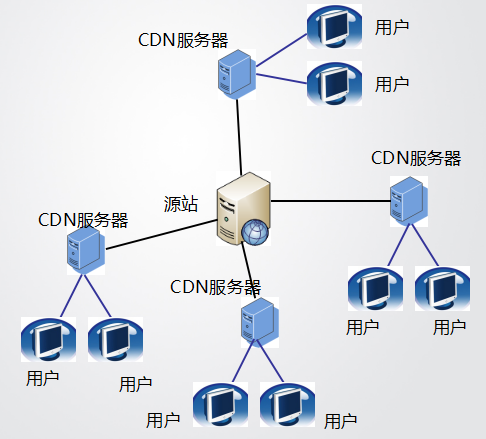 Origin Server: 源站,也就是做 CDN 之前的客户真正的服务器;
User: 访问者,也就是要访问网站的网民;
Edge Server: CDN 的服务器,不单只“边缘服务器”,这个之后细说;
Last Mile: 最后一公里,也就是网民到他所访问到的 CDN 服务器之间的路径。
|
举例:
|
我们平时所使用的DNS服务器,一般称之为LDNS,在解析一个域名的时候,一般有两个情况,一种是域名在DNS上有记录,另一种情况是没有记录,两种情况的处理流程不一样。
当你访问163这个域名时,如果LDNS上有缓存记录,那它会直接将IP地址直接给你。如果没有缓存记录,它将会一步步向后面的服务器做请求,然后将所有数据进行汇总交给最终的客户。
当你访问163这个地址时,实际上如果本身没有内容的话,它要去后面拿数据,这个过程术语叫递归,它首先会向全球13个根域服务器请求,问com域名在哪,然后根域服务器作出回答,一步步往下。
|
DNS调度
是如何进行调度和进行定位的?
 其实也是通过LDNS的具体地址来进行的,比如,看图,假设你是一个广东电信客户,那你所使用的DNS服务器去做递归的时会访问到某一个CDN厂商的GRB,全球的一个调度系统,他就能看到来自于哪个LDNS。假设如果用户和LDNS使用同一个区域的服务器,他就会间接认为用户也是广东电信的。
再举个例子,比如说北京联通的用户,它使用DNS地址,一般自动给它分配的是北京联通的服务器,这个服务器去做递归的时候,调度服务器就会看到这个请求是来自北京联通的LDNS服务器,就会给它分配一个北京联通的服务器地址,然后让来自北京联通的用户直接访问北京联通的服务器地址,这样来实现精准的区域性调度。
总结:用户在设置本身DNS上需要警惕,不同的DNS指向的地区不同,会严重影响速度。
|
Http的302调度:
|
在http协议中有一个叫302跳转的功能,它的实现并不是说你访问一个URL,然后马上吐给你想要的数据,而是吐给你一个302返回信令,这个信令头部会告诉你,有一个location目标,这个location就是告诉你下一步将要怎么做,而具体调度是通过location来实现的。
 举例:即便我所使用的DNS和我不在一个区域,但当我访问http server的时,这个server是由CDN公司提供的。客户访问server的时,虽说通过DNS方式无法拿到客户的真正IP地址,但是如果你访问的是http server,他一定能直接看到客户的真实IP,利用这种方法可以进行调度的纠偏,可以直接返回给你一个302,然后location里面携带一个真正离你最近的CDN server。
这种调度方式,优势是准确,但是也存在弊端,它不像DNS那样直接请求一个数据包过去给一个反馈就OK了,他需要一次TCP的三次握手建连。
|
存在的问题:
|
一般情况下都是通过DNS来进行第一次调度,然后用http来进行第二次纠偏。这种情况下大家可以想象,如果你下载一个大文件,比如说电影,但你访问的是一个页面小元素,比如说这个图片只有几k,那么,实际上你调度的时间就已占用了很大的成分。实际上,这种302调度是一种磨刀不误砍柴工的方案,如果你后面有很多工作要做,比如要下载一个电影时间会很长,那你调度准确,即使花一点时间调度也是值得的。但是如果你后续访问一下就完了,那么你这样调度就没有太大意义。
|
Http DNS调度:
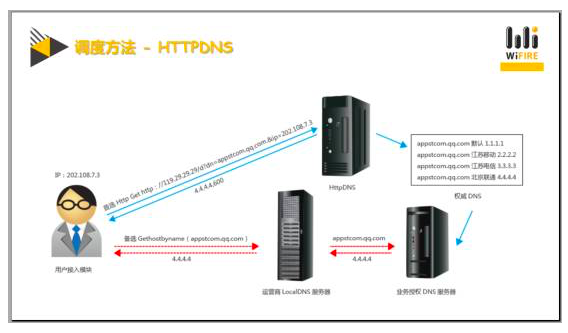 原理是通过一个正常的http请求,发一个get的请求,然后再请求里面以参数的形式携带一个目标解析的域名,然后服务器那边去通过数据库查询,查询之后又通过http的正常响应,把目标请求的IP通过http协议给用户,这种协议有一个特点就是必须双端都支持,因为这种模式是非标准的。
这有点类似是一种API的这种方式,那如果要实现的话就必须双端都支持。
一般,第三种调度的应用场景是在手机的APP端,在APP软件里面,你要访问某些东西很有可能被运营商劫持等问题。那为了避免这种劫持,可能会用到这种http DNS的调度方式。
|
CDN的接入:
|
那在没有CDN之前,返回给用户的IP地址就是在原来没做CDN时的原始服务器地址。但如果你做过CDN的话,你会发现最终拿到的这个IP地址是CDN的节点,而并不是真正的原始服务器。
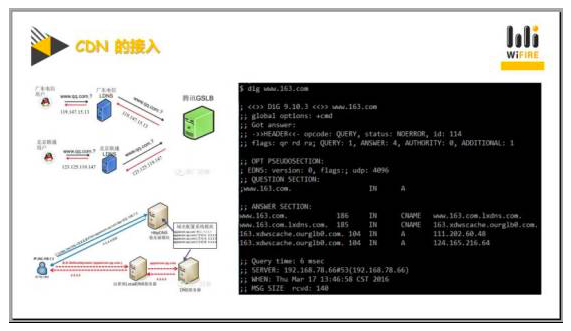 实际上第一跳是跳到网速地址,第二跳是分配了网速的一个平台,这个平台又分开其他的IP给最终的客户。
|
Cache 系统
|
在CDN里还有一个非常大的重头戏就是Cache系统,也就是缓存系统。它用于把那些可以缓存住的东西,缓存到CDN的边缘节点,这样当第二个人去访问同一节点,同一具体电影或MP3时就不用再经过CDN链路回到真正的源站去拿数据,而是由边缘节点直接给数据。
|
|
对于Cache系统来说,有两种不同的工作状态。
第一种工作状态就是所谓的命中(hit),第二种就是没有命中(miss)。如果命中了,直接通过检索找到磁盘或内存上的数据,把这个数据直接吐给客户,而不是从后面去拿数据。这样的话就起到一个很完美的加速效果。
第二种是在miss时,其实,miss的时候跟hit唯一的区别就是,当我发现我的本机上没有这个资源,我会去我的upstream(上游)去拿数据。拿完这个数据,除了第一时间给客户,同时还会在硬盘上缓存一份。如果这个硬盘空间满了,会通过一系列置换方法,把最老的数据、最冷的数据替换出去。
|
安全问题
攻击一般分成两种,第一种叫蛮力型攻击,量大的让你的带宽无法抗住最后导致拒绝服务,另外一种是技巧性攻击。
|
蛮力型攻击,作为CDN来讲,就已经将你的原始服务器的IP进行了隐藏。这样当一个攻击者去访问你的域名的时,实际上访问的并不是你真正的服务器。当他访问的是CDN的节点,就没有办法把CDN的节点打倒,换句话说,即使有能力把CDN的比如10g的节点或者是40g的大节点全部打倒,但由于CDN天然的分布式的部署方式,他也很难在同一时间之内迅速的把全国所有CDN的边缘节点全都打瘫。
技巧型攻击,比如说,像注入、挂马甚至说更严重的会直接拖走你的数据库等等。防范:如WAF,就是应用层防火墙,他可以直接去解析你的请求内容,分析内容是否有恶意性,如有恶意性的话去进行过滤,报警等一系列措施来保证你的原始服务器的安全。
|
CDN核心
|
原始的CDN其实是Content Delivery Network这三个词的缩写,也就是内容分发网络。CDN的理念是加速,所以,我们就尽一切可能去做各种优化,从一层到七层的优化来实现最终的优化效果。
 |
具体优化:
|
一层优化硬件,服务器选型就是一种优化。是用ssd,还是用saker硬盘,CPU应该用至强还是应该用阿童木的等等。
至于二层,链路层的优化指的就是资源方面。比如机房如何去选择。
三层路由层是指你在middlemell这块真正选路的具体的细节,后面会有一个图来具体讲一下。
四层是指传输层的优化,我们一般的业务全都是TCP,所以说这里面就可以明确的说这里是指TCP的优化。
七层也是可以优化的。比如说你强行对内容进行压缩,甚至你改变压缩级别去
在现今的互联网里,TCP优化是可以带来最直接客户体验感的一种实现方式。
 |
为什么没有对手快分析:
在CDN里你玩的是什么?你玩的实际上就是网络。对CDN公司来说。坦白来讲,服务器有三大部分组成,第一部分是你的操作系统,第二部分是你的Cache缓存系统,第三部分就是你的网络。
|
一般你的操作系统选型完毕优化之后你一般不会再动它了,除非遇到了重大的安全隐患或者是有重大的升级。而对你Cache系统来说也是,一般都求稳,在没有重大的bug的时,不会去轻易的改变。但最复杂的就是网络,你必须要掌握对网络的控制度,这样的话你才能驾驭它。
|
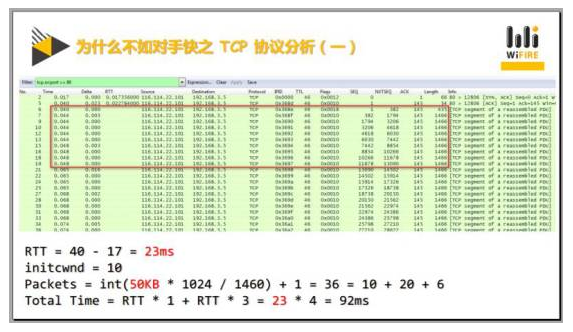

RTT: 往返时延。表示从发送端发送数据开始,到发送端收到来自接收端的确认,总共经历的时延。
|
我们可以通过第一次和第二次握手,看到他的往返时延是35毫秒。和之前的23毫秒相比,可知这个资源的ping值比原来增加了52%。通过刚才的分析方法我们也可以找到第35和37号包的跳变点。那么35号包之前是第一个发送轮回。整个的发包数量是20,它的初始发包数量实际上并不是标准的10,而是20。那么,我们可以再算一下,如果你有50kb必须要发出,你最终需要也是36个包,但是你初始是20就需两轮,分别是20+16。
通过套公式,可知需要150毫秒完成。那150毫秒跟之前的92比只慢14%。在资源落后52%的情况下,最终效果才慢了14%,中间的这个差距实际上就是你的技术带来的价值。
|
WScale、SACK是什么东西?
每个厂商无论你是做CDN,做电商、做IT企业,只要你有对外提供的server,而且server的负载比较高都会遇到的一个syncookie的坑。在TCP的标准里有两个选项一个叫WScale一个是SACK。

|
在TCP三次握手的时候,客户端如果要支持WScale选项的话,服务端被通知支持这个选项。如果服务端也支持,会记录下来说客户端支持,同时回应也支持。在客户端拿到第二次握手时,服务端就也把自己置成支持状态了。在数据传输的时,它是以2为底数,然后以WScale的这个n值为指数的一个滑动窗口递增值。
利用这个WScale是可把发送窗口的数量涨到很大的,比如说64k、128k、256k甚至更大。如果要这样再套公式,他的传输效果就会变得非常好了。
|
|
关于参数SACK,选择性应答。在你数据传输的时,没有这个选项会怎么样呢?比如,要传10个数据包,只有第6个数据包丢掉了,这时候需要把6到10重新发一遍,存在许多重复提交,速度会非常慢。
如果收到连续的序号完整的到5,但是还收到了7到10。服务端就可通过这两个信息进行拼接找到中间的空隙,就会知道只有6号丢掉了,只需传6即可。
|
syncookie需要注意的坑!
|
syncookie开启的情况下会怎么样呢?他会在协议栈之前自己伪造一个应答机制,并不是真正的协议栈去代应答第二次握手。同时他的第二次握手会携带一个算好的一个cookie值作为第三次握手的校验。如果他收到了第三次握手的校验值的会被认为是一个合法的建连,那么,他会把这个通过注入的方式,直接告诉你这个链接可以直接用了。那在前期syncookie当满的时候开始启动这个状态,他是不占用队列的,所以说他是一个非常好的防攻击的一个手段,但是他的防攻击的量不会很大,微量是可以的。
但坑也恰恰就在这。由于syncookie他不是标准的TCP协议栈,所以说他的支持,并不是非常的完备。等一段syncookie发出,他代应答的第二次握手并不携带WScale和SACK这个选项。就会让客户端误认为是不支持的,所以,后续的沟通就变得非常的低效。我们之前做过一个实验,在有一定量丢包而且大延时的情况下,你的速度可能只有300多k。后来查了很多资料发现确实是这个样子,而且我们做了很多的模拟时间。比如,都为syncookie出发的时,他速度确实就很快。
后来我们做了一个改动,在syncookie上,如果要是代应答的时,我们携带SACK的这个数据给客户,那后来建连的时都可以把这个功能用起来。用起来时我们在线上是真正的无环境试验可以提升大概25%到35%的服务质量。
|
Cache的选型
|
目前市场上常用的cache选型:
 很多公司直接使用开源; 目前并不推荐自研
原因:
第一,你要耗费大量的人力和时间。
第二,你需要去思考,你能不能cover住这些原本人家已经做好的东西。

通过上面的截图分析: 在客户端发起请求的时候期望去和服务器进行这种长连接。而服务器给出去的时,并没有明确的告诉客户端是否支持。
导致这个问题的原因是由于我们的研发人员并没有真正地领会RTT协议的精髓,他没有完全cover住这个RTT协议导致最基本的这种车轮,这个轮骨做的是有问题的导致很严重的坑。
|

转自《https://mp.weixin.qq.com/s?__biz=MjM5NTU2MTQwNA==&mid=2650653458&idx=3&sn=b658019ef6407a7d00f784f6f0cf238f&chksm=beffc9c1898840d7b75b27a3ba1f0f3084f6f7d7a45789c4adfbdf99522c15197d3974f88666&scene=21#wechat_redirect》,整理发布。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号