
基于不同采集频率的数据科学研究过程案例
导读:
在过去的几个月里,很多人要求我写出一个数据科学项目端到端所需要做的工作,即从业务问题定义阶段到建模阶段及其最终部署。我仔细考虑过这个需求,而且认为这是有道理的。数据科学文献充满了关于具体算法或确定方法的文章以及如何处理问题的代码。然而,对于针对特定业务用例进行数据科学项目所需要的端到端视图很难找到。从本周起,我们将开始一个名为应用数据科学系列的新系列。在本系列中,我将给出数据科学框架下的解决业务用例或社会问题的观点。在应用数据科学系列的第一篇文章中,我们将讨论预测性维护业务用例。涉及的用例是预测大型工业电池的使用寿命,这种电池属于用例,称为预防性维护用例。
在深入研究商业问题以及如何从数据科学的角度解决问题之前,我们来看一下数据科学项目生命周期的全局。
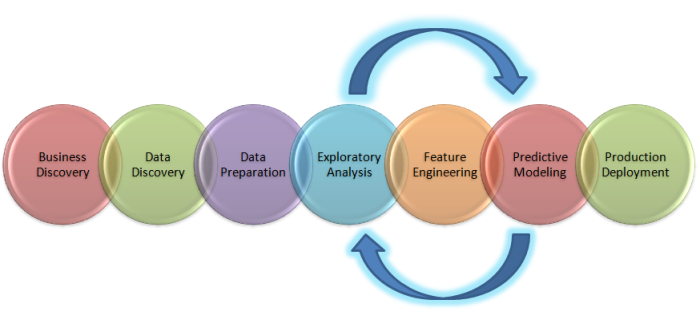
上图是从数据科学的角度描绘出需要解决业务问题的全局视图。 让我们来端到端的解析每个组件。
1. 业务发现
任何数据科学项目都是从一个业务问题开始。我们现有的问题是尝试预测大型工业电池的使用寿命。当遇到这个特定的商业问题时,首先应该考虑的事情就是能发挥作用的关键变量。对于电池的这个具体例子,确定电池健康状况的一些关键变量是电导,放电,电压,电流和温度。
我们需要提出的下一个问题是这些变量中的主要指标或趋势,这有助于解决业务问题。我们必须从业务方那里得到的基础知识。对于电池的情况,结果证明表明故障倾向的关键趋势是电导值的下降。电池的电导率会随着时间的推移而下降,但是电导值下降的速度将在故障点之前加速。这是一个重要的线索,我们必须认识到我们何时应该对变量进行详细的探索性分析。
另一个关键变量是放电。当允许电池放电时,电压将最初降至最低水平,然后重新获得电压。这被称为“Coup de Fouet”效应。每个电池制造商都将规定标准和控制图表,说明电压可能下降多少以及恢复过程如何。任何偏离这些标准和控制图将意味着异常行为。这是另一个我们探索数据时,不得不注意的指标。
除了上述两个指标之外,还有许多其他因素,数据科学家必须意识到哪些将预示失败。在业务探索阶段,我们必须确定与我们要解决的商业问题有关的所有这些因素,并制定关于它们的假设。一旦我们制定了我们的假设,我们必须在关于这些假设的数据中寻找证据/趋势。关于我们上面讨论的两个变量,我们可以制定一些假设如下。
1.电导系数随着时间逐渐下降,意味着正常行为,突然下降将意味着异常行为
2.制造商规定的“Coup de Fouet”的偏差效应将表示异常行为
当我们探索数据时,如上所述的假设将是我们将要关注的变量的趋势的参考点。我们根据行业专业知识制定的假设越多,探索阶段就越好。现在,我们已经看到了业务发现阶段的内容,让我们在业务发现阶段中将重点考虑的内容作为以后讨论的重点。
1.了解我们要解决的业务问题
2.确定与业务问题相关的所有关键变量
3.确定这些变量中的牵头指标,有助于解决业务问题。
4.制定牵头指标的假设
一旦我们从业务和领域的角度掌握了关于这个问题的足够的知识,现在看看我们手头上的数据。
2. 数据发现
在数据发现阶段,我们必须尝试了解数据捕获的一些关键方面,以及变量如何在数据集中进行表示。
有一些经典的统计分析方法可以使用,比如:
1. 直方图
2. 聚类分析
3.PCA analysis 主成分分析 (主要用于特征相关性和降维)
数据发现阶段的一些重要考虑因素如下:
*我们是否有关于业务发现阶段中定义的所有变量和指标的数据?
*数据捕获的机制是什么?数据采集机制是否根据变量而有所不同?
*数据采集的频率是多少?变量有变化吗?
*捕获的数据量是否根据所涉及的频率和变量而有所不同?
在电池预测问题的情况下,有三种不同的数据集。这些数据集属于不同的变量集合。数据采集的频率和捕获的数据量也不尽相同。涉及的一些关键数据集如下
*电导数据集:与电池电导有关的数据。每2-3天收集一次。与电导数据一起收集的一些关键数据点包括
*采集电导数据时的时间戳
*每个电池的唯一标识符
*其他相关信息,如制造商,安装位置,型号,连接到的字符串等
*端子电压数据:有关电池电压和温度的数据。这是每天收集的。关键数据点包括
*电池电压
*温度
*其他相关信息,如电池标识,制造商,安装位置,型号,字符串数据等
*放电数据:每3个月收集一次放电数据。关键变量包括
*放电电压
*电压放电时的电流
*其他相关信息,如电池标识,制造商,安装位置,型号,字符串数据等
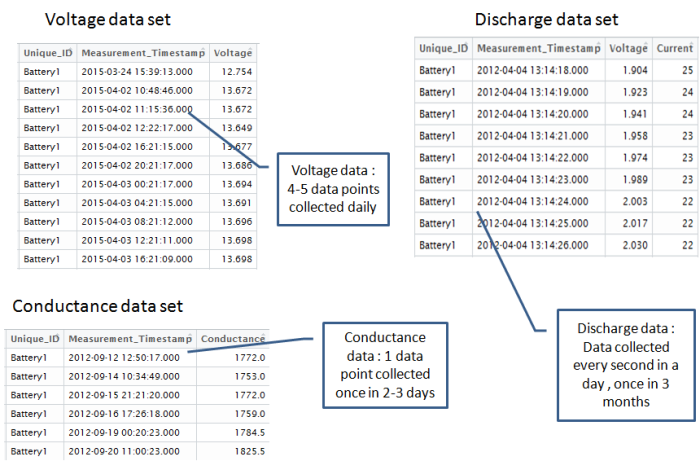
如图所示,我们必须使用不同的变量集合,数据点到达时的不同时间频率和涉及的每个变量的不同数据量来播放三个非常不同的数据集。 人们会遇到的一个关键挑战是将所有这些变量连接成一个连贯的数据集,这将有助于预测任务。 如果我们可以通过连接可用于我们正在尝试解决的业务问题的数据集来制定预测性问题,那么这样做会更容易。 我们先试图制定预测问题。
3. 设计预测问题
为了帮助制定预测性问题,让我们回顾一下我们现有的业务问题,然后将其与我们现有的数据点相连接。预测性问题需要我们预测两件事情。
- 哪个电池会失败
- 电池未来会在哪段时间内出现故障。
由于预测是电池电量,因此我们制定预测问题的参考单位是个别电池。这意味着在多个数据集中存在的所有变量必须在单个电池级别进行整合。
接下来的一个问题是,在什么时候我们要巩固每个电池的变量?为了回答这个问题,我们将要看每个变量的数据收集频率。在我们的电池数据集的情况下,每个变量的数据点以不同的间隔进行捕获。此外,在这些时间段,为每个这些变量收集的数据量也显着变化。
电导率:每3天捕获一次电池一次。
电压和温度:每个电池每天捕获4-5个读数。
放电:每3个月一次不同时间间隔(每天收集约4500 - 5000个数据点)每秒捕获一组读数。
由于我们必须在将来的一段时间内预测失败的可能性,所以我们必须让我们的模型在时间段内学习这些变量的行为。但是,我们必须选择一个时间段,我们将为每个变量提供足够的数据点。在这种情况下,我们应该选择的理想时间是每3个月一次,因为每3个月可以得到一次放电数据。这意味着每个变量的每个电池的所有数据点必须每3个月合并为单个记录。因此,如果每个电池有大约3年的数据,那么电池将需要12条记录。
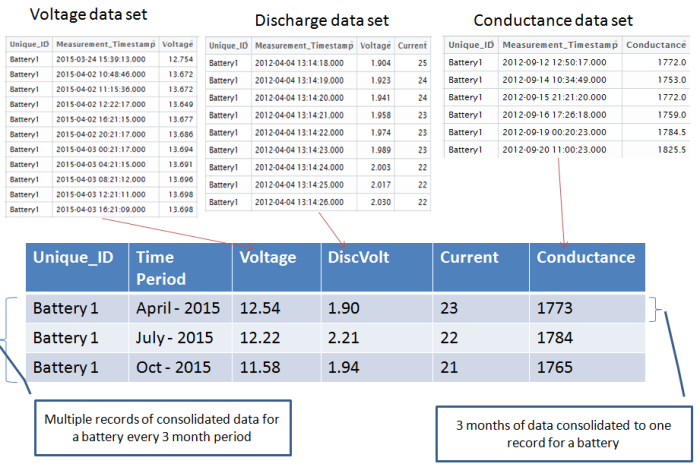
我们要看的另一个方面是如何整合电池的3个月的数据点,以便对每个变量做出一个记录。为此,我们必须为每个变量采用一些合适的合并形式。在探索性分析和特征工程之后,可以确定哪个合并度量值。当我们谈论探索性分析和特征工程阶段时,我们将详细讨论这些方面。
我们必须处理的下一个重点是响应变量的标签。由于业务问题是预测哪个电池出现故障,因此响应变量将分类电池的记录是否属于故障类别。然而,这种方法有一个缺点。我们想要的是提前预测电池可能会失败,因此我们也必须将“何时”部分纳入分类任务。这将需要查看实际失败的电池样本,并确定发生故障时的时间点。我们将该点标记为“故障点”,然后从故障点回溯到分类导致故障的时间段。数据点合并期限为三个月,我们可以将“回头看”期限定为3个月。这意味着,对于那些我们知道故障点的电池样本,我们将查看故障前一个时间段(3个月)的记录,并将数据标记为故障前1个时间段,对应于6个月的数据记录在故障前将被标记为2个故障前的时期等等。我们可以根据失败前的时间段继续对数据进行标注,直到我们在失败前达到舒适的时间点(比如1年)。如果我们考虑的舒适时期是1年,我们将有4个故障类别,即故障前1个时期,故障前2个时期,故障前3个时期和故障前4个时期。 1年以前的所有记录可以标注为“正常期间”。这种标签策略将意味着我们的预测问题是一个多项式分类问题,有5个类(4个故障期类和1个正常周期类)。

上述讨论的标签策略是我们的数据集中的电池样品,其实际上是失败的,而在发生故障的时候我们知道。但是,如果我们没有关于电池列表中没有出现故障并没有失败的信息,那么我们不得不采取强力的探索性分析来首先确定已经失败的电池样品,然后根据上述标签策略进行标记。在下一篇文章中,我们可以讨论如何使用探索性分析来识别已经失败的电池。不用说,没有失败的所有电池的记录将被标记为“正常周期”。
现在我们已经看到了预测性问题的制定部分,让我们回顾一下我们迄今为止的讨论。预测性问题的制定步骤涉及如下
1.了解业务问题并制定响应变量。
2.确定应用业务问题的参考单位(我们的情况下是每个电池)
3.查看与参考单位相关的关键变量以及生成这些变量的数据的体积和速度
4.根据数据速度,决定数据合并期间,并确定参考单位将存在的记录数。
5.从数据集中,确定那些失败的单元,哪些没有失败。这些信息通常可从以前每个单位的维护合同中获得。
6.对故障单位和正常单位采用标签策略。确定将应用于所有单位记录的课程数。对于失败的单位,将记录标记为失败的类别,直到方便的时间段(在这种情况下为1年)。该期间之前的所有记录将标记为与未失败的单位相同(“正常期间”)
到目前为止,我们已经讨论了数据科学项目的初始阶段。 第一阶段需要定义业务问题并进行业务发现。 在下一阶段,即数据发现阶段,我们将可用数据点与业务问题对齐,然后制定预测问题。 一旦我们清楚地了解了如何制定预测性问题,我们的下一个任务将是进行探索性分析和特征工程阶段。 这些阶段和后续阶段将在本系列的下一篇文章中详细介绍。 注意这个空间更多。
