
SQL执行计划之sql_trace
一,sql_trace的作用:用以描述SQL的执行过程的trace输出。
- SQL是如何操作数据的
- SQL执行过程中产生了哪些等待事件
- SQL执行中消耗了多少资源
- SQL的实际执行计划
- SQL产生的递归语句
二,set autotrace 与 sql_trace的区别
set autotrace用于输出优化器产生的执行计划,执行计划展示的资源消耗情况是CBO的估算值,并不一定是SQL实际执行时资源消耗情况。比如,向表t中插入10万条数据,执行查询的时候发现只返回少量数据,这可能就是表t还没有被Oracle重分析,它并不知道表的数据已更新。
sql_trace是SQL实际的执行情况。
三,何时使用set autotrace 与 sql_trace
当需要分析执行计划及CBO行为时,使用set autotrace;当要看一条SQL的真实运行效果时,使用sql_trace。
四,sql_trace的使用
(1)收集本回话的SQL执行过程
SQL>alter session set sql_trace=true
SQL>alter session set statistics_level =all;
SQL>alter session set timed_statistics = true;
SQL>alter session set max_dump_file_size = unlimited;
SQL>alter session set tracefile_identifier = liangjian
SQL>alter session set max_dump_file_size = unlimited;
SQL>alter session set tracefile_identifier = liangjian
SQL>sql.....
SQL>alter session set sql_trace=false
SQL>exit
(2)收集其它会话的SQL执行过程
SQL1>select sid, serial# from v$session;
SQL2>execute dbms_system.set_sql_trace_in_session(sid, serial#, true);
SQL2>sql....
SQL2>execute dbms_system.set_sql_trace_in_session(sid, serial#, false);
五,trace文件内容
生成的trace文件的目录由参数文件指定,可以通过v$diag_info视图来查看,name=Default Trace File的值就是trace文件的默认路径。下面是一个实际生成的trace文件:

trace文件内容:
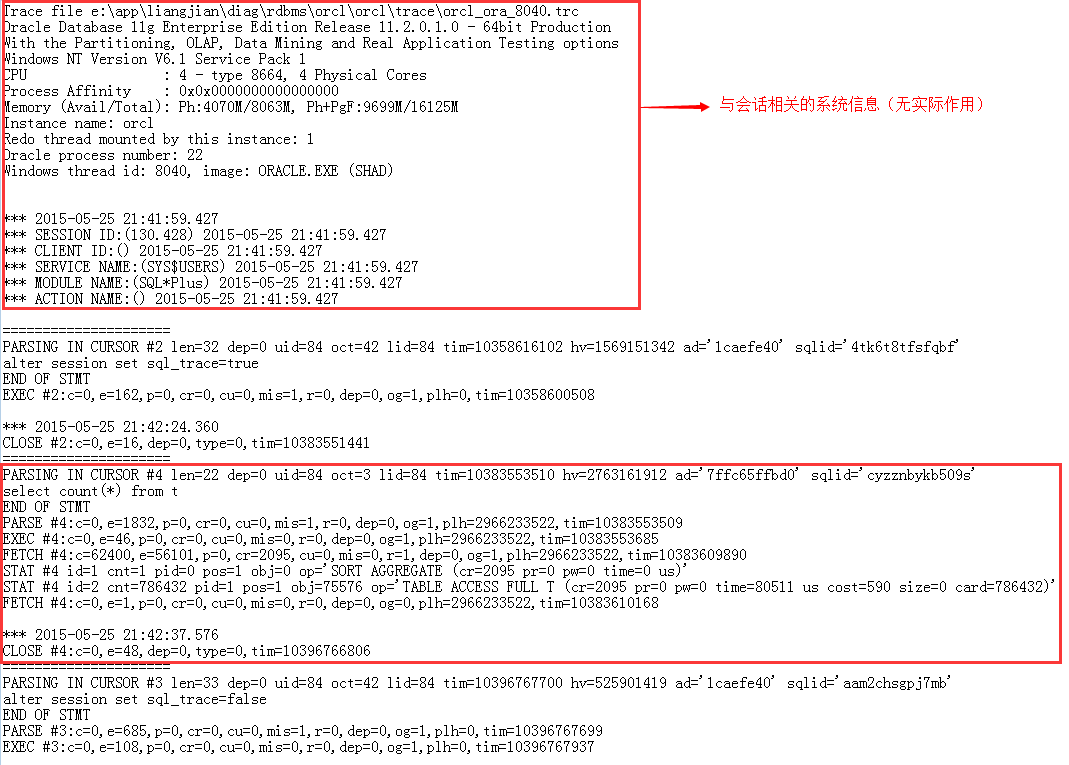
trace文件中记录的是Oracle按照时间先后顺序来输出的,它是Oracle执行SQL最底层的过程。上面第二个红色方框中体现的就是我们所发出SQL执行的过程,其意思是:首先打开一个标号为4的游标,关联这条SQL语句,然后解析这条SQL语句(PARSE #4),其中mis=1表示共享区中没有可共享已解析SQL,故它执行的是一次硬解析,然后执行SQL语句,再然后获取数据,最后关闭游标。有时候游标标号相同的输出并不在一起,因为trace文件是按照时间的先后顺序输出的,这也最能反映Oracle内部的执行顺序。
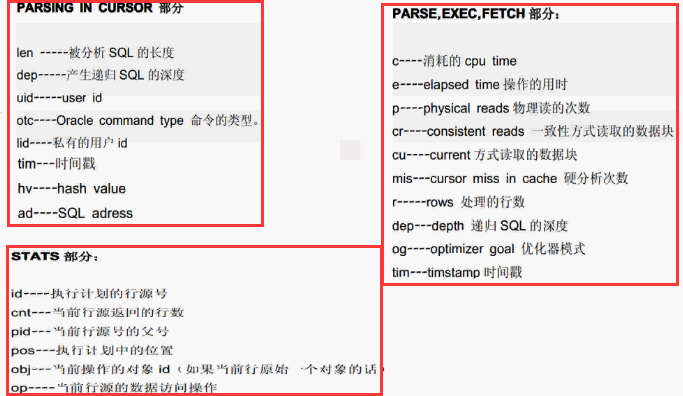
trace文件中有很多键值对信息,初次看trace文件也一定是看不懂的,下面介绍一下各个键所代表的含义:
六,tkprof格式化工具
trace文件并不直观,为了让读者一目了然,Oracle提供了格式化trace文件的工具:tkprof
(1)tkprof命令
Usage: tkprof tracefile outputfile [explain= ] [table= ] [print= ] [insert= ] [sys= ] [sort= ]
参数说明
tracefile:你要分析的trace文件的绝对路径
outputfile:格式化后的文件绝对路径
explain=user/password@connectstring,对每条SQL 语句确定其执行规划,并将执行规划写到输出文件中。如果不是有explain,在trace文件中我们看到的是SQL实际的执行路径,不会有sql的执行计划(可以对比实际执行规划和执行计划的差别)
table=schema.tablename,在输出到输出文件前,用于存放临时表的用户名和表名。
PRINT:只列出输出文件的最初N个SQL语句。默认为所有的SQL语句。
AGGREGATE:如果= NO,则不对多个相同的SQL进行汇总。如果为yes则对trace文件中的相同sql进行合并。
INSERT:SQL 语句的一种,用于将跟踪文件的统计信息存储到数据库中。在TKPROF创建脚本后,在将结果输入到数据库中。
SYS:如果设置为yes,则所有sys用户的操作(也包含用户sql语句引发的递归sql),这样可以减少分析出来的文件的复杂度,便于查看。
sort:对trace文件的sql语句根据需要排序,其中比较有用的一个排序选项是fchela,即按照elapsed time fetching来对分析的结果排序(记住要设置初始化参数timed_statistics=true),生成的文件将把最消耗时间的sql放在最前面显示。

执行计划分为两部分,第一部分称为行源操作(Row Source Operation ),是游标关闭且开启跟踪情况下写到跟踪文件中的执行计划。这意味着如果应用程序不关闭游标而重用它们的话,不会有新的针对重用游标的执行计划写入到跟踪文件中。第二部分,叫做执行计划 (Execution Plan),是由指定了explain参数的TKPROF生成的。既然这是随后生成的,所以和第一部分不一定完全匹配。万一看到两者不一致,前者是正确的。两个执行计划都通过Rows列提供执行计划中每个操作返回的行数(不是处理的--要注意)。 对于每个行源操作来说,可能还会提供如下的运行时统计:
cr是一致性模式下逻辑读出的数据块数。
pr是从磁盘物理读出的数据块数。
pw是物理写入磁盘的数据块数。
time是以微秒表示的总的消逝时间。要注意根据统计得到的值不总是精确的。实际上,为了减少开销,可能用了采样。
cost是操作的评估开销。这个值只有在Oracle 11g才提供。
size是操作返回的预估数据量(字节数)。这个值只有在Oracle 11g才提供。
card是操作返回的预估行数。这个值只有在Oracle 11g才提供。
输出文件的结尾给出了所有关于跟踪文件的信息。首先可以看到跟踪文件名称、版本号、用于这个分析所使用的参数sort的值。然后,给出了所有会话数量与SQL语句数量。
Optimizer mode: ALL_ROWS表示优化器采用的是all_rows的模式
Parsing user id: 55 表示用户id为55
(2)格式化后输出文件的解释
首先解释输出文件中列的含义:
CALL:每次SQL语句的处理都分成三个部分
Parse:这步将SQL语句转换成执行计划,包括检查是否有正确的授权和所需要用到的表、列以及其他引用到的对象是否存在。
Execute:这步是真正的由Oracle来执行语句。对于insert、update、delete操作,这步会修改数据,对于select操作,这步就只是确定选择的记录。
Fetch:返回查询语句中所获得的记录,这步只有select语句会被执行。
COUNT:这个语句被parse、execute、fetch的次数。
CPU:这个语句对于所有的parse、execute、fetch所消耗的cpu的时间,以秒为单位。
ELAPSED:这个语句所有消耗在parse、execute、fetch的总的时间。
DISK:从磁盘上的数据文件中物理读取的块的数量。
QUERY:在一致性读模式下,所有parse、execute、fetch所获得的buffer的数量。一致性模式的buffer是用于给一个长时间运行的事务提供一个一致性读的快照,缓存实际上在头部存储了状态。
CURRENT:在current模式下所获得的buffer的数量。一般在current模式下执行insert、update、delete操作都会获取buffer。在current模式下如果在高速缓存区发现有新的缓存足够给当前的事务使用,则这些buffer都会被读入了缓存区中。
ROWS: 所有SQL语句返回的记录数目,但是不包括子查询中返回的记录数目。对于select语句,返回记录是在fetch这步,对于insert、update、delete操作,返回记录则是在execute这步。
(3)trace文件中的性能分析
1、如果分析数与执行数之比为1,说明每次执行这个查询都要进行sql解析。如果分析数与执行数之比接近0,则意味着查询执行了很多次软解析,降低了系统的可伸缩性。
2、如果trace文件中显示对所有或者几乎所有的sql都执行一次,那有可能是因为没有正确使用绑定变量。
3、如果一个(Fetch Count)/所获得行数的比值接近1,且行数大于1,则应用程序不执行大批量取数操作,每种语言/API都有能力完成这个功能,即一次取多行。如果没有利用这个功能进行批量去,将有可能花费多得多的时间在客户端与服务器端之间来回往返。这个过多的来回转换出了产生很拥挤的网络状况之外,也会比一次调用获得很多行要慢得多,如何指示应用程序进行批量获取将随语言/API而定。
4、如果CPU时间与elasped时间有巨大差异,意味着有可能花了大量时间在等待某些事情上。如果花了一个CPU时间来执行,但它却总共花了10秒的时间,这就意味着90%的运行时间在等待一个资源。例如被一个会话等待,或者大量查询时的物理IO等待等
5、较长的CPU或经过时间往往是最消耗资源的sql,需要我们关注
6、可以通过磁盘IO所占逻辑IO的比例,disk/query+current来判断磁盘IO的情况,太大的话有可能是db_buffer_size过小,当然这也跟SQL的具体特性有关
7、query+current/rows 平均每行所需的block数,太大的话(超过20)SQL语句效率太低,数据过于分散,可以考虑重组对象

 浙公网安备 33010602011771号
浙公网安备 33010602011771号