【算法】赫夫曼树(Huffman)的构建和应用(编码、译码)
我的博客即将入驻“云栖社区”,诚邀技术同仁一同入驻。
参考资料
《算法(java)》 — — Robert Sedgewick, Kevin Wayne
《数据结构》 — — 严蔚敏
赫夫曼树的概念
要了解赫夫曼树,我们要首先从扩充二叉树说起
二叉树结点的度
结点的度指的是二叉树结点的分支数目, 如果某个结点没有孩子结点,即没有分支,那么它的度是0;如果有一个孩子结点, 那么它的度数是1;如果既有左孩子也有右孩子, 那么这个结点的度是2.
扩充二叉树
对于一颗已有的二叉树, 如果我们为它添加一系列新结点, 使得它原有的所有结点的度都为2,那么我们就得到了一颗扩充二叉树, 如下图所示:

其中原有的结点叫做内结点(非叶子结点), 新增的结点叫做外结点(叶子结点)
我们可以得出: 外结点数 = 内结点数 + 1
并进一步得出: 总结点数 = 2 × 外结点数 -1
扩充二叉树,构成了赫夫曼树的基本形态,而上面的公式,也是我们构建赫夫曼树的依据之一
赫夫曼树的外结点和内结点
赫夫曼树的外结点和内结点的性质区别:外节点是携带了关键数据的结点, 而内部结点没有携带这种数据, 只作为导向最终的外结点所走的路径而使用
正因如此,我们的关注点最后是落在赫夫曼树的外结点上, 而不是内结点。
带权路径长度WPL
让我们思考一下: 在一颗在外结点上存储了数据的扩充二叉树中进行查找时,数据结点怎么分布才能尽可能减少查找的开销呢? 这里我们再加上一个前提:不同的数据结点搜索的频率(或概率)是不一致的。
显然, 我们大致的思路是: 如果一个数据结点搜索频率越高,就让它分布在离根结点越近的地方,也即从根结点走到该结点经过的路径长度越短。 这样就能从整体上优化整颗树的性能。
频率是个细化的量,这里我们用一个更加标准的一个词描述它——“权值”。
综上, 我们为扩充二叉树的外结点(叶子结点)定义两条属性: 权值(w)和路径长度(l)。同时规定带权路径长度(WPL)为扩充二叉树的外结点的权值和路径长度乘积之和:
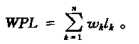
(注意只是外结点!)
赫夫曼树(最优二叉树)
由n个权值构造一颗有n个叶子结点的二叉树, 则其中带权路径长度WPL最小的二叉树, 就是赫夫曼树,或者叫做最优二叉树。
例如下图中对a, b, c
对a: WPL = 7×2 + 5×2 + 2×2 + 4×2 = 36;
对b: WPL = 7×3 + 5×3 + 2×1 + 4×2 = 46;
对c: WPL = 7×1 + 5×2 + 2×3 + 4×3 = 35;
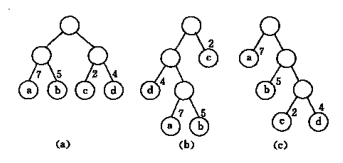
c中WPL最小, 可以验证, 它就是赫夫曼树, 而a和b都不是赫夫曼树
对于同一组权值的叶结点, 构成的赫夫曼树可以有多种形态, 但是最小WPL值是唯一的。
赫夫曼树的构建
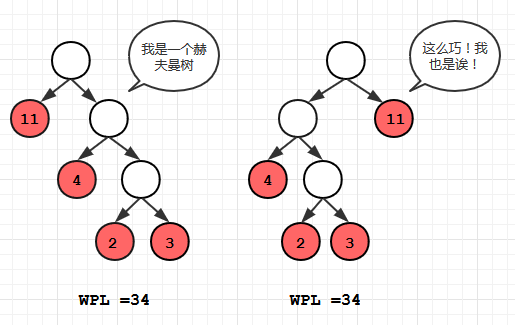
构建过程分四步:
1. 根据给定的n个权值{w1, w2, w3 ... wn }构成n棵二叉树的集合, 每棵二叉树都只包含一个结点
2. 在上面的二叉树中选出两颗根结点权值最小的树, 同时另外取一个新的结点作为这两颗树的根结点, 设新节点的权值为两颗权值最小的树的权值和, 将得到的这颗树也加入到树的集合中
3. 在2操作后, 从集合中删除权值最小的那两颗树
4. 重复2和3,直到集合中的树只剩下一棵为止, 剩下的这颗树就是我们要求得的赫夫曼树。
如下图所示:
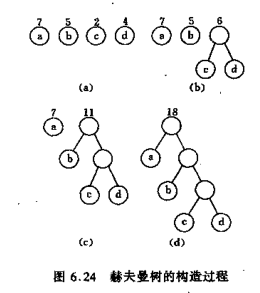
(注意a和b的分界线在4和7中间,图中画的不是很清晰)
我们上面提到过WPL相同的情况下, 赫夫曼树不止一种,在我们介绍的算法中,人为要求某个内结点的左儿子的权值要比右儿子大, 这样一来, 就将我们算法中的赫夫曼树变为唯一一种了。
构建赫夫曼树的的方法有多种,但基于实际应用的考虑(赫夫曼编码和译码), 下面我给出基于数组存储实现的赫夫曼树:
Node类的设计
我们首先需要一个编写一个结点类, 结点类里有5种实例变量: weight表示权值, data表示外结点存储的字符,data属性在下面的编码/解码中会用到。 而同样因为赫夫曼编码,解码的需求,这里我们使用三叉链实现二叉树,,即在left和right属性的基础上,为结点增加了parent属性,目的是能够从叶子结点上溯到根结点,从而实现赫夫曼编码。
/** * @Author: HuWan Peng * @Date Created in 23:21 2018/1/14 */ public class Node { char data; // 数据 int weight; // 权值 int left, right, parent; // 三条链接 public Node (char data, int weight) { this.data = data; this.weight = weight; } public Node (int weight) { this.weight = weight; } }
buildTree方法的设计
输入参数和返回值
输入参数: 一个由外结点对象组成的Node数组, 假设其为nodes
返回值: 一个由内、外结点共同组成,且建立了链接关系的Node数组, 假设其为HT(HuffmanTree)
具体操作
首先要做的事情是: 获取输入的nodes数组的长度 n , 创建一个长度为 2n - 1的数组——HT,在数组HT中, 前n个元素用来存放外结点, 后n个元素用来存放内结点, 如下图所示:
图A

图B
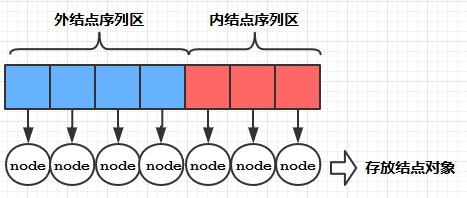
接下来要做的是:
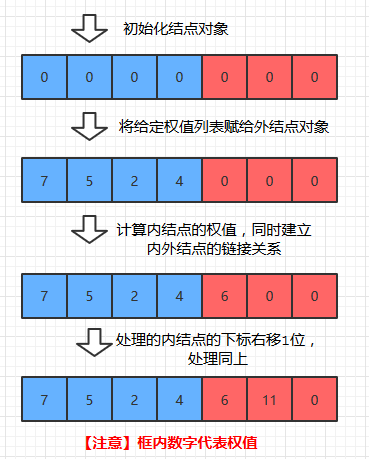
1. 初始化HT中的结点对象,此时各个结点对象的weight都被置为0
2. 将输入的nodes数组中的各结点对象的权值赋给HT[0]~ HT[n-1], 如上图所示
3.通过循环, 依次计算各个内结点的权值,同时建立该内结点和作为它左右孩子的两个外结点的链接关系。
易知:当最后一个内结点的权值也计算完毕后, 整颗赫夫曼树也就构建完毕了。
如图 (方框内数字表示结点对象的权值)
注意要点
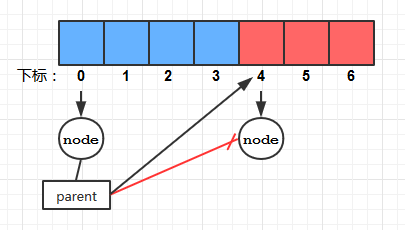
要注意的是: 我们为Node设置的链接变量left/right/parent是整型的, 它指向的是某个结点对象在HT中的下标, 而不是结点对象本身! 这种实现方式和一般的树是有区别的
具体代码
下面是buildTre方法的代码:
(select方法尚未给出)
/** * @description: 构建赫夫曼树 */ public Node[] buildTree (Node [] nodes) { int s1, s2,p; int n = nodes.length; // 外结点的数量 int m = 2*n - 1; // 内结点 + 外结点的总数量 Node [] HT = new Node [m]; // 存储结点对象的HT数组 for (int i=0;i<m;i++) HT[i] = new Node(0); // 初始化HT数组元素 for (int i=0;i<n;i++) { HT[i].data = nodes[i].data; HT[i].weight = nodes[i].weight; //将给定的权值列表赋给外结点对象 } for (int i=n;i<m;i++) { s1 = select(HT,i,0); // 取得HT数组中权值最小的结点对象的下标 s2 = select(HT,i,1); // 取得HT数组中权值次小的结点对象的下标 HT[i].left = s1; // 建立链接 HT[i].right = s2; HT[s1].parent = i; HT[s2].parent = i; HT[i].weight = HT[s1].weight + HT[s2].weight;// 计算当前外结点的权值 selectStart+=2; // 这个变量表示之前“被删除”的最小结点的数量和 } return HT; // 将处理后的HT数组返回 }
buildTree方法的用例:
/** * @description: buildTree方法的用例 */ public static void main (String [] args) { Node [] nodes = new Node[4]; nodes[0] = new Node('a',7); nodes[1] = new Node('b',5); nodes[2] = new Node('c',2); nodes[3] = new Node('d',4); HuffmanTree ht = new HuffmanTree(); Node [] n = ht.buildTree(nodes); // n是构建完毕的赫夫曼树 } }
select方法的设计
buildTree方法的实现依赖于select方法:
private int select (Node[] HT,int range, int rank)
上面代码中调用select的部分为:
s1 = select(HT,i,0); // 取得HT数组中权值最小的结点对象的下标 s2 = select(HT,i,1); // 取得HT数组中权值次小的结点对象的下标
思考3个问题:
1. 求给定权值排名的结点,可以先对数组进行从小到大的快速排序, 然后就可以取得给定排名的结点对象了, 但是如果直接对输入的HT数组进行排序的话, 会改变HT数组元素的排列顺序, 这将不利于我们下面要介绍的赫夫曼编码的方法的实现。 所以这里我们先将HT数组拷贝到一个辅助数组copyNodes中, 对copyNodes进行快排,并取得给定权值排名的结点对象。然后通过遍历HT数组,比较得到该结点对象在HT中的下标
2. 在上面我们提到过, 在构建一颗新二叉树后, 要把原来的两颗权值最小的树从集合中 ”删除“,这里我们通过类内的selectStart实例变量实现, selectStart初始值为0, 每次构建一棵新二叉树后都通过 selectStart+=2; 增加它的值。(见上文buildTree代码) 这样, 在select方法中就可以通过copyNodes[selectStart + rank],去取得 "删除" 后权值排名为rank的结点对象了。
3. 引入range这一参数是为了排除那些weight仍为0,即尚未使用到的内结点, 防止排序后取到它们。注意, 随着循环中 i 的增长, range也是不断增长的:
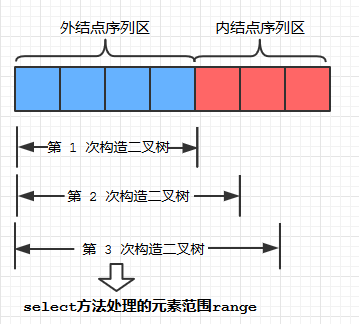
具体代码
(QuickSort的代码文末将给出)
/** * @description: 返回权值排名为rank的结点对象在HT中的下标(按权值从小到大排) */ private int select (Node[] HT,int range, int rank) { Node [] copyNodes = Arrays.copyOf(HT, range);// 将HT[0]~HT[range]拷贝到copyNodes中 QuickSort.sort(copyNodes); // 对copyNodes进行从小到大的快速排序 Node target = copyNodes[rank + selectStart]; // 取得“删除”后权值排名为rank的结点对象 for (int j=0;j<HT.length;j++) { if (target == HT[j]) return j; // 返回该结点对象在数组HT中的下标 } return -1; }
过程图解
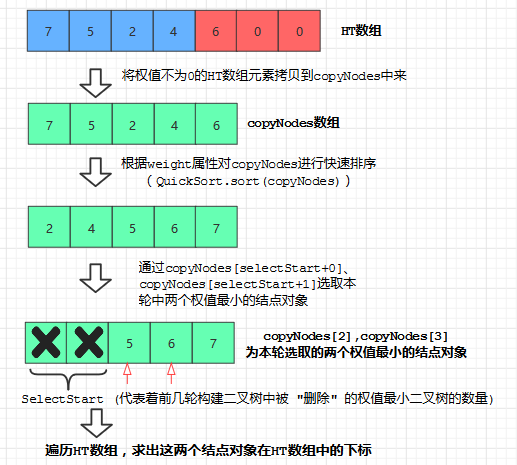
这样,通过调用buildTree方法, 我们的赫夫曼树就构造好了。
赫夫曼树的应用
赫夫曼树可以用于优化编码, 在这之前, 先让我们了解下什么是等长编码和不等长编码。
等长编码和不等长编码
等长编码
例如一段电文为 'A B A C C D A', 它只有4种字符,只需要两个字符的串就可以分辨, 所以我们可以按等长编码的设计原则, 将A,B,C,D表示为00、01、10、11, 'A B A C C D A'就被编码为‘00010010101100’, 共14位。 它的优点是: 因为间隔相同, 译码时不存在二义性的问题。 但缺点在于, 有些字符本可以被设计为更短的编码, 也就是说,设计为等长编码, 我们实际上浪费了一部分编码的空间(长度)
不等长编码
同上, 如果采用不等长编码, 可以把A,B,C,D表示为0、00、1、01, 那么 'A B A C C D A'就可以被编码为‘000011010’, 总长只要9就够了! 比起等长编码我们节约了5位的长度。 但问题是: 由于长度间隔不一致, 译码时可能存在二义性,这导致无法翻译,例如 ‘00‘,到底是看成'00'还是’0‘ + ’0‘呢? 前者被翻译为B,而后者被翻译为A。

前缀编码
所以,要设计长短不等的编码, 则必须保证: 任意一个字符的编码都不是另一个字符的编码的前缀,这种编码就叫做前缀编码
赫夫曼编码的作用
赫夫曼编码就是一种前缀编码, 它能解决不等长编码时的译码问题, 通过它,我们既能尽可能减少编码的长度, 同时还能够避免二义性, 实现正确译码。
赫夫曼编码是如何实现前缀编码的 ?
假设有一棵如下图所示的二叉树, 其4个叶结点分别表示A,B,C,D这4个字符,且约定左分支表示字符'0', 右分支代表字符'1', 则可以从根结点到叶子结点的路径上的各分支字符组成的字符串作为该叶子结点字符的编码。 从而得到A,B,C,D的二进制编码分别为0, 10, 110, 111。
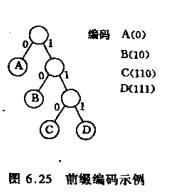
具体如下图所示:

赫夫曼编码和解码都要调用上文讲述的buildTree方法
实现赫夫曼编码(encode)
根据给定的字符和权值, 输出字符和对应的赫夫曼编码
注意要点
1. 我们编写一个HuffmanCode内部类用于存放字符(data实例变量)和它对应的二进制字符串(bit实例变量)
2. 要求所有字符对应的编码时,如果采用从根结点下行到叶结点的思路处理,逻辑会相对复杂一些, 所以我们用逆向的方式获取: 按照从叶子结点到根结点的路径累加二进制字符串

3. 因为 2 的原因, 累加二进制字符串的时候也必须反向累加,例如写成bit= "0" + bit; 而不是写成bit= bit+ "0";
4. 上溯时候要做的工作是: 判断当前经过的是 0 还是 1, 判断的方法如下图所示:
假设P是X的父节点:
- 如果P.left==X在HT中的下标,则说明X是P的左分支,说明经过的是 0
- 如果P.right==X在HT中的下标,则说明X是P的右分支,说明经过的是 1
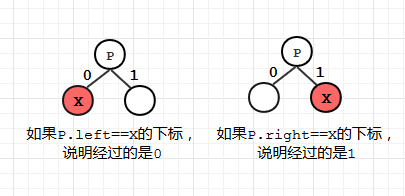
代码如下:
import java.util.Arrays; /** * @Author: HuWan Peng * @Date Created in 22:54 2018/1/14 */ public class HuffmanTree { private class HuffmanCode { char data; // 存放字符,例如 'C' String bit; // 存放编码后的字符串, 例如"111" public HuffmanCode (char data, String bit) { this.data = data; this.bit = bit; } } /** * @description: 构建赫夫曼树 */ public Node[] buildTree (Node [] nodes) { // 具体代码见上文 } /** * @description: 进行赫夫曼编码 */ public HuffmanCode [] encode(Node [] nodes) { Node [] HT = buildTree(nodes); // 根据输入的nodes数组构造赫夫曼树 int n = nodes.length; HuffmanCode [] HC = new HuffmanCode [n]; String bit; for (int i=0;i<n;i++) { // 遍历各个叶子结点 bit = ""; for (int c=i,f=HT[i].parent;f!=0;c=f,f=HT[f].parent) { // 从叶子结点上溯到根结点 if(HT[f].left == c) bit= "0" + bit; // 反向编码 else bit= "1" + bit; } HC[i] = new HuffmanCode(HT[i].data,bit); // 将字符和对应的编码存储起来 } return HC; } /** * @description: encode方法的用例 */ public static void main (String [] args) { Node [] nodes = new Node[4]; nodes[0] = new Node('A',7); nodes[1] = new Node('B',5); nodes[2] = new Node('C',2); nodes[3] = new Node('D',4); HuffmanTree ht = new HuffmanTree(); HuffmanCode[] hc = ht.encode(nodes); // 对A,B,C,D进行编码 for (int i=0;i<hc.length;i++) { // 将赫夫曼编码打印出来 System.out.println(hc[i].data + ":" +hc[i].bit); } } }
输出结果:
A:0 B:10 C:110 D:111
赫夫曼译码(decode)
根据给定的字符和权值, 将输入的赫夫曼编码翻译回原字符串
译码的时候,从根结点HT[HT.length -1] 开始, 向下行走, 通过charAt方法取得字符串当前的字符, 如果为 '0'则向左走, 为'1'则向右走, 当下行到叶子结点时候,取得叶子结点包含的字符, 添加到当前的译码字符串中,同时有回到根结点,继续循环。
代码如下:
import java.util.Arrays;
/** * @Author: HuWan Peng * @Date Created in 22:54 2018/1/14 */ public class HuffmanTree { int selectStart = 0; private class HuffmanCode { char data; // 存放字符,例如 'C' String bit; // 存放编码后的字符串, 例如"111" public HuffmanCode (char data, String bit) { this.data = data; this.bit = bit; } } /** * @description: 构建赫夫曼树 */ public Node[] buildTree (Node [] nodes) { // 代码见上文 } /** * @description: 进行赫夫曼译码 */ public String decode (Node [] nodes, String code) { String str=""; Node [] HT = buildTree(nodes); int n =HT.length -1; for (int i=0;i<code.length();i++) { char c = code.charAt(i); if(c == '1') { n = HT[n].right; } else { n = HT[n].left; } if(HT[n].left == 0) { str+= HT[n].data; n =HT.length -1; } } return str; } /** * @description: decode方法的用例 */ public static void main (String [] args) { Node [] nodes = new Node[4]; nodes[0] = new Node('A',7); nodes[1] = new Node('B',5); nodes[2] = new Node('C',2); nodes[3] = new Node('D',4); HuffmanTree ht = new HuffmanTree(); // 对 010110111 进行译码 System.out.println(ht.decode(nodes,"010110111")); } }
输出:
ABCD
全部代码:
代码共三份:
1.HuffmanTree.java
2.Node.java
3.QuickSort.java
Node.java
/** * @Author: HuWan Peng * @Date Created in 23:21 2018/1/14 */ public class Node { char data; int weight; int left, right, parent; public Node (char data, int weight) { this.data = data; this.weight = weight; } public Node (int weight) { this.weight = weight; } }
HuffmanTree.java
import java.util.Arrays; /** * @Author: HuWan Peng * @Date Created in 22:54 2018/1/14 */ public class HuffmanTree { int selectStart = 0; private class HuffmanCode { char data; // 存放字符,例如 'C' String bit; // 存放编码后的字符串, 例如"111" public HuffmanCode (char data, String bit) { this.data = data; this.bit = bit; } } /** * @description: 返回权值排名为rank的结点对象在nodes中的下标(按权值从小到大排) */ private int select (Node[] HT,int range, int rank) { Node [] copyNodes = Arrays.copyOf(HT, range);// 将HT[0]~HT[range]拷贝到copyNodes中 QuickSort.sort(copyNodes); // 对copyNodes进行从小到大的快速排序 Node target = copyNodes[rank + selectStart]; // 取得“删除”后权值排名为rank的结点对象 for (int j=0;j<HT.length;j++) { if (target == HT[j]) return j; // 返回该结点对象在数组HT中的下标 } return -1; } /** * @description: 构建赫夫曼树 */ public Node[] buildTree (Node [] nodes) { int s1, s2,p; int n = nodes.length; // 外结点的数量 int m = 2*n - 1; // 内结点 + 外结点的总数量 Node [] HT = new Node [m]; // 存储结点对象的HT数组 for (int i=0;i<m;i++) HT[i] = new Node(0); // 初始化HT数组元素 for (int i=0;i<n;i++) { HT[i].data = nodes[i].data; HT[i].weight = nodes[i].weight; //将给定的权值列表赋给外结点对象 } for (int i=n;i<m;i++) { s1 = select(HT,i,0); // 取得HT数组中权值最小的结点对象的下标 s2 = select(HT,i,1); // 取得HT数组中权值次小的结点对象的下标 HT[i].left = s1; // 建立链接 HT[i].right = s2; HT[s1].parent = i; HT[s2].parent = i; HT[i].weight = HT[s1].weight + HT[s2].weight;// 计算当前外结点的权值 selectStart+=2; // 这个变量表示之前“被删除”的最小结点的数量和 } return HT; // 将处理后的HT数组返回 } /** * @description: 进行赫夫曼编码 */ public HuffmanCode [] encode(Node [] nodes) { Node [] HT = buildTree(nodes); // 根据输入的nodes数组构造赫夫曼树 int n = nodes.length; HuffmanCode [] HC = new HuffmanCode [n]; String bit; for (int i=0;i<n;i++) { // 遍历各个叶子结点 bit = ""; for (int c=i,f=HT[i].parent;f!=0;c=f,f=HT[f].parent) { // 从叶子结点上溯到根结点 if(HT[f].left == c) bit= "0" + bit; // 反向编码 else bit= "1" + bit; } HC[i] = new HuffmanCode(HT[i].data,bit); // 将字符和对应的编码存储起来 } return HC; } /** * @description: 进行赫夫曼译码 */ public String decode (Node [] nodes, String code) { String str=""; Node [] HT = buildTree(nodes); int n =HT.length -1; for (int i=0;i<code.length();i++) { char c = code.charAt(i); if(c == '1') { n = HT[n].right; } else { n = HT[n].left; } if(HT[n].left == 0) { str+= HT[n].data; n =HT.length -1; } } return str; } /** * @description: buildTree方法的用例 */ public static void main (String [] args) { Node [] nodes = new Node[4]; nodes[0] = new Node('A',7); nodes[1] = new Node('B',5); nodes[2] = new Node('C',2); nodes[3] = new Node('D',4); HuffmanTree ht = new HuffmanTree(); System.out.println(ht.decode(nodes,"010110111")); } }
QuickSort.java
/** * @Author: HuWan Peng * @Date Created in 22:56 2018/1/14 */ public class QuickSort { /** * @description: 交换两个数组元素 */ private static void exchange(Node [] a , int i, int j) { Node temp = a[i]; a[i] = a[j]; a[j] = temp; } /** * @description: 切分函数 */ private static int partition (Node [] a, int low, int high) { int i = low, j = high+1; // i, j为左右扫描指针 int pivotkey = a[low].weight; // pivotkey 为选取的基准元素(头元素) while(true) { while (a[--j].weight>pivotkey) { if(j == low) break; } // 右游标左移 while(a[++i].weight<pivotkey) { if(i == high) break; } // 左游标右移 if(i>=j) break; // 左右游标相遇时候停止, 所以跳出外部while循环 else exchange(a,i, j) ; // 左右游标未相遇时停止, 交换各自所指元素,循环继续 } exchange(a, low, j); // 基准元素和游标相遇时所指元素交换,为最后一次交换 return j; // 一趟排序完成, 返回基准元素位置 } /** * @description: 根据给定的权值对数组进行排序 */ private static void sort (Node [] a, int low, int high) { if(high<= low) { return; } // 当high == low, 此时已是单元素子数组,自然有序, 故终止递归 int j = partition(a, low, high); // 调用partition进行切分 sort(a, low, j-1); // 对上一轮排序(切分)时,基准元素左边的子数组进行递归 sort(a, j+1, high); // 对上一轮排序(切分)时,基准元素右边的子数组进行递归 } public static void sort (Node [] a){ //sort函数重载, 只向外暴露一个数组参数 sort(a, 0, a.length-1); } }

我叫彭湖湾,请叫我胖湾

 浙公网安备 33010602011771号
浙公网安备 33010602011771号