



oracle分区表原理学习
1.创建普通表
create table normal_shp(id number,day date,city_number number,note varchar2(100)) tablespace p;
插入10000条记录
insert into normal_shp(id,day,city_number,note) select rownum,to_date(to_char(sysdate-180,'J')+trunc(dbms_random.value(0,180)),'J'),ceil(dbms_random.value(1,7)),rpad('a',100,'a') from dual connect by rownum <=100000;
2.创建范围分区表
create table range_shp(id number,day date,city_number number,note varchar2(100))
partition by range(day)
(
partition p1 values less than (to_date('2019-02-01','YYYY-MM-DD')) tablespace p1,
partition p2 values less than (to_date('2019-03-01','YYYY-MM-DD')) tablespace p2,
partition p3 values less than (to_date('2019-04-01','YYYY-MM-DD')) tablespace p3,
partition p4 values less than (to_date('2019-05-01','YYYY-MM-DD')) tablespace p4,
partition p5 values less than (to_date('2019-06-01','YYYY-MM-DD')) tablespace p5,
partition p6 values less than (to_date('2019-07-01','YYYY-MM-DD')) tablespace p6,
partition p_max values less than (maxvalue) tablespace p
)
;
插入100000条记录
insert into range_shp(id,day,city_number,note)
select rownum,to_date(to_char(sysdate-180,'J')+trunc(dbms_random.value(0,180)),'J'),
ceil(dbms_random.value(1,7)),
rpad('a',100,'a')
from dual
connect by rownum <=100000;
3.性能对比
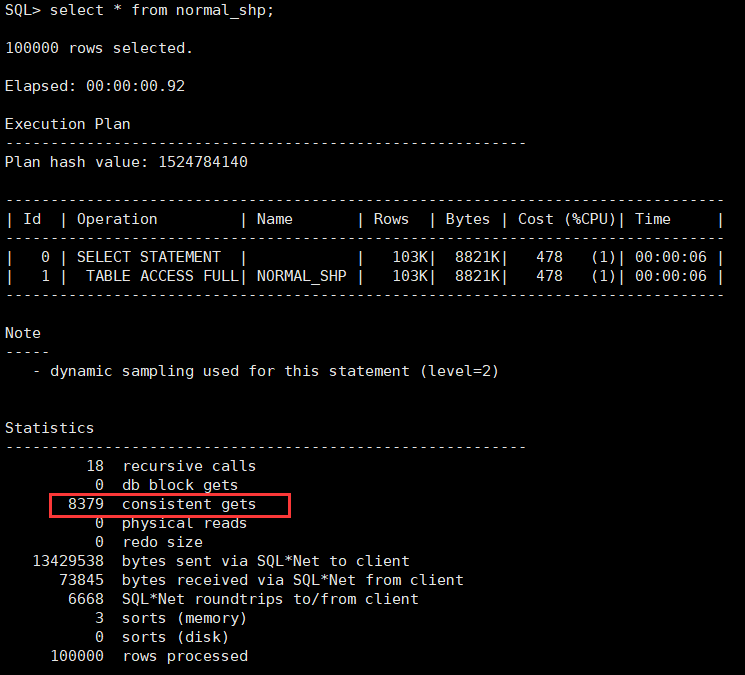
select * from normal_shp; --普通表
select * from range_shp; --范围分区表
|
普通表 |
范围分区表 |
 |
|
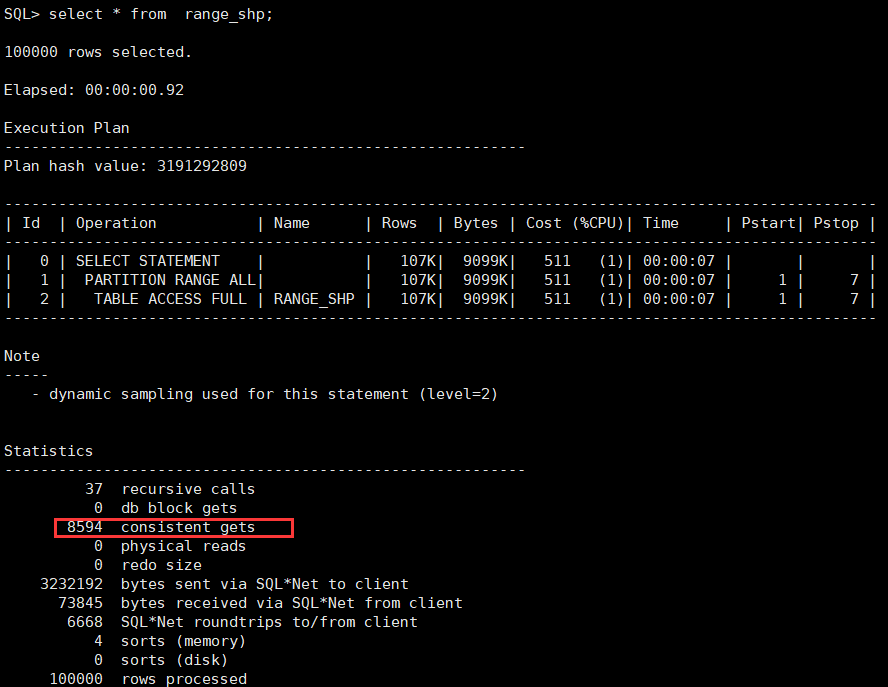
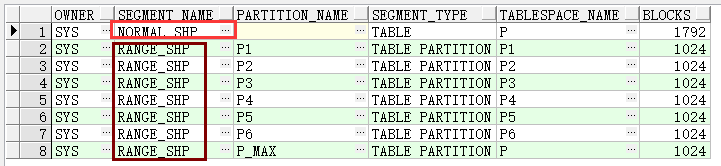
在不加任何条件时,进行查询发现,两者的逻辑读数量大致相同,花费大致相同;其中范围分区表的逻辑读和花费甚至略高于范围分区表。这是因为分区数量较多,oracle需要管理的段更多(见下图),在进行操作时会引发大量内部的递归调用(recursive calls),因而小表不建议建分区。
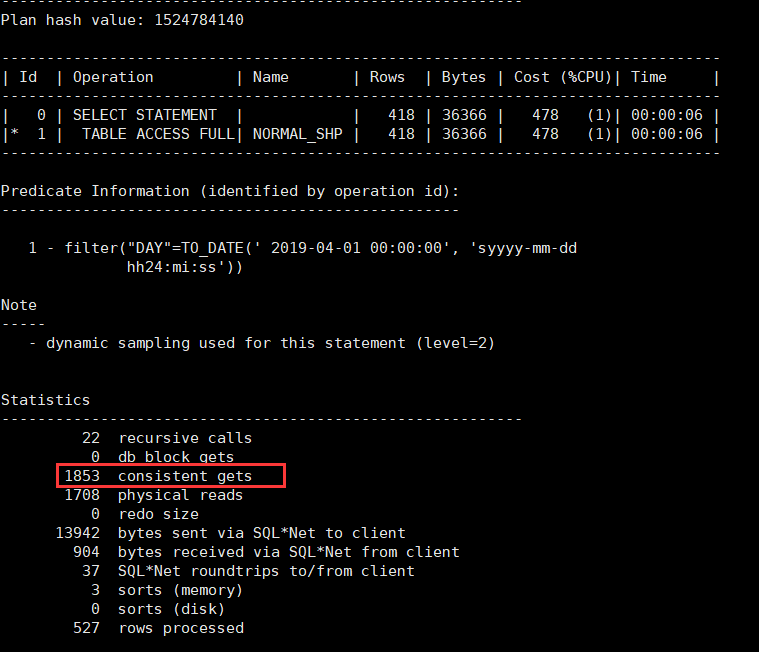
对指定时间进行查询:
select * from normal_shp where day=to_date(‘2019-04-01’,’YYYY-MM-DD’);
select * from range_shp where day=to_date(‘2019-04-01’,’YYYY-MM-DD’);
|
普通表 |
范围分区表 |
 |
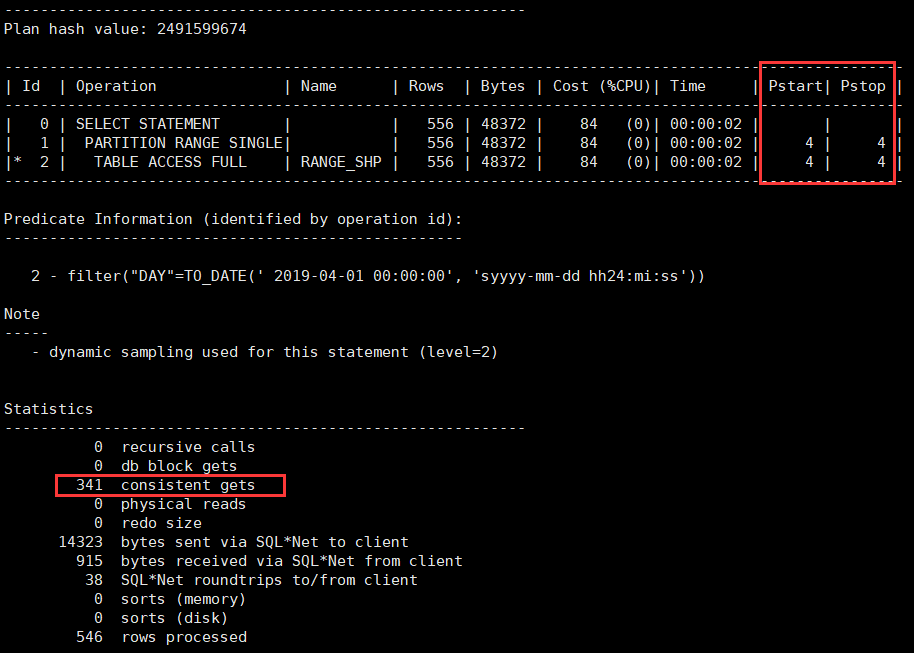 |
由上图可知,在对指定时间做查询时,对时间做范围分区表的查询更加高效,逻辑读从1853降到了341,花费也更加低。由执行计划仔细观察得,pstart和pstop均为4,代表范围分区表进行查询时,只对于第4个分区进行了全表扫描。
4.创建列表分区表
create table list_shp(id number,day date,city_number number,note varchar2(100))
partition by list(city_number)
(
partition p1 values (1) tablespace p1,
partition p2 values (2) tablespace p2,
partition p3 values (3) tablespace p3,
partition p4 values (4) tablespace p4,
partition p5 values (5) tablespace p5,
partition p6 values (6) tablespace p6,
partition p_other values (default) tablespace p
)
;
5.创建hash分区表
create table hash_shp(id number,day date,city_number number,note varchar2(100))
partition by hash(day)
partitions 6
store in (p1,p2,p3,p4,p5,p6)
;
注:如果表空间数量大于分区数量,则会采用前几个;如果表空间数量小于分区数量,表空间按序循环使用。散列分区的个数尽量使用偶数个。
或者:
-- Create table
create table SYS.HASH_SHP
(
id NUMBER,
day DATE,
city_number NUMBER,
note VARCHAR2(100)
)
partition by hash (DAY)
(
partition SYS_P41 tablespace P1,
partition SYS_P42 tablespace P2,
partition SYS_P43 tablespace P3,
partition SYS_P44 tablespace P4,
partition SYS_P45 tablespace P5,
partition SYS_P46 tablespace P6
);
6.创建组合分区表
常用的:范围-列表分区
create table range_list_shp(id number,day date,city_number number,note varchar2(100))
partition by range(day)
subpartition by list(city_number)
subpartition template
(
subpartition p1 values (1) tablespace p1,
subpartition p2 values (2) tablespace p2,
subpartition p3 values (3) tablespace p3,
subpartition p4 values (4) tablespace p4,
subpartition p5 values (5) tablespace p5,
subpartition p6 values (6) tablespace p6,
subpartition p_other values (default) tablespace p)
(
partition p1 values less than (to_date('2019-02-01','YYYY-MM-DD')) tablespace p1,
partition p2 values less than (to_date('2019-03-01','YYYY-MM-DD')) tablespace p2,
partition p3 values less than (to_date('2019-04-01','YYYY-MM-DD')) tablespace p3,
partition p4 values less than (to_date('2019-05-01','YYYY-MM-DD')) tablespace p4,
partition p5 values less than (to_date('2019-06-01','YYYY-MM-DD')) tablespace p5,
partition p6 values less than (to_date('2019-07-01','YYYY-MM-DD')) tablespace p6,
partition p_max values less than (maxvalue) tablespace p
)
;
7.分区数据交换
分区表的某个分区与普通表进行分区数据交换
alter table range_shp exchange partition p1 with table normal_shp1;
alter table range_list_shp subpartition p1_p1 with table normal_shp1;
(普通表的表结构要和分区一致)
8.分区表的管理
(1)清理分区
alter table range_shp truncate partition p1;
alter table range_list_shp truncate subpartition p1_p1;
(2) 增加表分区
当分区表存在默认条件分区,range中的maxvalue分区,list分区表中的default分区:
① 先删除原默认分区,增加分区后再添加默认分区
alter table range_shp drop partition p_max; --删除maxvalue分区
alter table range_shp add partition p_7 values less than (to_date('2019-08-01','YYYY-MM-DD')) tablespace p7; --增加分区
alter table range_shp add partition p_max values less than (maxvalue) tablespace p; --增加maxvalue分区
尤其注意,删除默认分区会将数据一并删除,不会分布到其他分区!!!
② 使用拆分分区split的方式进行增加
在目标分区拆分后,被拆分的分区会按照拆分规则将数据重新分布
alter table list_shp split partition p_other values(7) into (partition p_7 tablespace p7,partition p_other);
alter table range_shp split partition p_max at(to_date('2019-08-01','YYYY-MM-DD')) into (partition p_7 tablespace p6,partition p_other);
对于不存在默认条件分区的分区表,直接增加即可;
(3)合并表分区
对于列表分区,合并的分区无要求;
对于范围分区,合并的分区需相邻;
对于散列分区,无法合并
语法:alter table range_shp merge partitions p1,p2 into partition p0;
(4)收缩分区
只能在散列分区或者组合分区的hash子分区上进行使用
alter table hash_shp coalesce partition;
9.分区表索引的维护
全局索引:create index index1 on list_shp(day);
局部索引:create index index2 on range_shp(day) local;
N/A表示局部索引
截断一个分区会将全局索引失效,而局部索引不会失效
加参数可以避免全局索引失效:update global indexes;
Alter table range_shp truncate p1 update global indexes;

