
python进程和线程(五)
python的进程
由于GIL的存在,python中的多线程其实并不是真正的多线程,如果想要充分地使用多核CPU的资源,在python中大部分情况需要使用多进程。Python提供了非常好用的多进程包multiprocessing,只需要定义一个函数,Python会完成其他所有事情。借助这个包,可以轻松完成从单进程到并发执行的转换。multiprocessing支持子进程、通信和共享数据、执行不同形式的同步,提供了Process、Queue、Pipe、Lock等组件。
multiprocessing包是Python中的多进程管理包。与threading.Thread类似,它可以利用multiprocessing.Process对象来创建一个进程。该进程可以运行在Python程序内部编写的函数。该Process对象与Thread对象的用法相同,也有start(), run(), join()的方法。此外multiprocessing包中也有Lock/Event/Semaphore/Condition类 (这些对象可以像多线程那样,通过参数传递给各个进程),用以同步进程,其用法与threading包中的同名类一致。所以,multiprocessing的很大一部份与threading使用同一套API,只不过换到了多进程的情境。
但在使用这些共享API的时候,我们要注意以下几点:
- 在UNIX平台上,当某个进程终结之后,该进程需要被其父进程调用wait,否则进程成为僵尸进程(Zombie)。所以,有必要对每个Process对象调用join()方法 (实际上等同于wait)。对于多线程来说,由于只有一个进程,所以不存在此必要性。
- multiprocessing提供了threading包中没有的IPC(比如Pipe和Queue),效率上更高。应优先考虑Pipe和Queue,避免使用Lock/Event/Semaphore/Condition等同步方式 (因为它们占据的不是用户进程的资源)。
- 多进程应该避免共享资源。在多线程中,我们可以比较容易地共享资源,比如使用全局变量或者传递参数。在多进程情况下,由于每个进程有自己独立的内存空间,以上方法并不合适。此时我们可以通过共享内存和Manager的方法来共享资源。但这样做提高了程序的复杂度,并因为同步的需要而降低了程序的效率。
Process.PID中保存有PID,如果进程还没有start(),则PID为None。
window系统下,需要注意的是要想启动一个子进程,必须加上那句if __name__ == "main",进程相关的要写在这句下面。
1.进程的调用
进程调用方式和线程一样,也分为直接调用和类方法调用:
直接调用:


from multiprocessing import Process import os def func(num): print ('我是%s'%num) print('我的进程号',os.getpid()) if __name__ == '__main__': L = [] for i in range(20): p = Process(target=func,args=(i,)) L.append(p) p.start() for l in L: l.join() print('ending...')
类方法调用:
from multiprocessing import Process import os class MyProcess(Process): def __init__(self,num): super(MyProcess,self).__init__() self.num = num def run(self): print('我是%s'%self.num) print('父进程PID号是',os.getppid()) print('我的pid号是',self.pid) if __name__ == '__main__': L = [] print('main',os.getpid()) for i in range(20): p = MyProcess(i) L.append(p) p.start() for l in L: l.join()
2.Process类
构造方法: Process([group [, target [, name [, args [, kwargs]]]]]) group: 线程组,目前还没有实现,库引用中提示必须是None; target: 要执行的方法; name: 进程名; args/kwargs: 要传入方法的参数。 实例方法: is_alive():返回进程是否在运行。 join([timeout]):阻塞当前上下文环境的进程程,直到调用此方法的进程终止或到达指定的timeout(可选参数)。 start():进程准备就绪,等待CPU调度 run():strat()调用run方法,如果实例进程时未制定传入target,这star执行t默认run()方法。 terminate():不管任务是否完成,立即停止工作进程 属性: authkey daemon:和线程的setDeamon功能一样 exitcode(进程在运行时为None、如果为–N,表示被信号N结束) name:进程名字。 pid:进程号。
3.进程通信
从一开始讲概念我们知道,线程之前是共享进程里面的数据集的,所以线程之间的通信是比较方便的,进程之前没有这个数据集,那应该怎么通信呢?回想之前的线程有线程队列,进程是不是也有进程的队列呢?那肯定是有的:
进程队列:
import multiprocessing def Foo(q): print(q.get()) print(q.get()) print(q.get()) if __name__ == '__main__': L = [] queue = multiprocessing.Queue() p = multiprocessing.Process(target=Foo,args=(queue,)) p.start() queue.put({'name:pengfy'}) queue.put([1,2,3,4,5]) queue.put('qaq') p.join() #注意join放的位置
这里主进程放置了3三元素到队列,子进程取到并打印出来了,这就是一次简单的进程间的通信,这里要注意join的位置。
进程管道:
管道Pipe()函数返回一个由管道连接的连接对象(类似socket通信里面的conn),默认情况下是双工(双向):
#管道,类似socket里面的conn # from multiprocessing import Process,Pipe def connect(conn): conn.send([12, {"name":"pengfy"}, 'hello']) print(conn.recv()) conn.close() print('son2', id(conn)) if __name__ == "__main__": parent_conn,child_conn = Pipe() #双向管道 print('son1',id(child_conn)) p = Process(target=connect,args=(child_conn,)) p.start() print(parent_conn.recv()) parent_conn.send('孩子你好') p.join()
看打印的id不一样,说明用的不是一份数据,是复制过去的。Pipe()返回的两个连接对象代表管道的两端。 每个连接对象都有send()和recv()方法(以及其他方法)。 请注意,如果两个进程(或线程)同时尝试读取或写入管道的同一端,则管道中的数据可能会损坏。 当然,同时使用管道的不同端的进程不存在损坏的风险。
Manages
上面两种类型,都是数据的传输,其实用的比较多的还是Manages(注意大小写)。Manager()返回的管理器对象控制一个服务器进程,该进程保存Python对象并允许其他进程使用代理操作它们
View Code 例子里面只列举了几种数据类型,总共支持的有list, dict, Namespace, Lock, RLock, Semaphore, BoundedSemaphore, Condition, Event, Barrier, Queue, Value 和Array.
4.进程同步
线程里面我们讲过线程同步,通过采用线程锁可以解决这个问题。那么进程有没有这个问题呢?肯定是有的,比如说:当进程共用一个资源时,需要同步,比如屏幕,不同步的话打印异常(用python2打印比较容易出现)
from multiprocessing import Process def func(i): print('hello',i) if __name__ == '__main__': L = [] for i in range(10): p = Process(target=func,args=(i,)) p.start() L.append(p) for l in L: l.join()
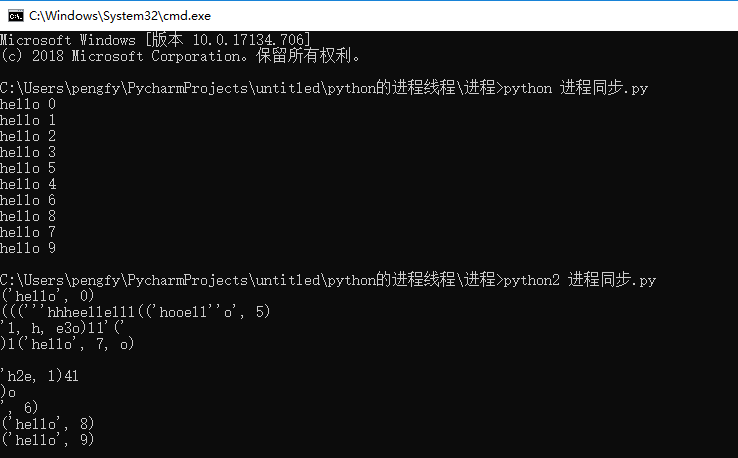
像这种情况,在进程里面也有一把锁来控制:
# from multiprocessing import Process,Lock # # def func(lock,i): # lock.acquire() # print('hello',i) # lock.release() # # # def func(lock,i): # # with lock: # # print('hello',i) # # if __name__ == '__main__': # lock = Lock() # L = [] # for i in range(10): # p = Process(target=func,args=(lock,i,)) # p.start() # L.append(p) # for l in L: # l.join()
这样怎么运行都不会出现上面那种情况了,不信可以试试。
5.进程池
进程池是什么?就是一个池子,因为开多个进程比较容易消耗资源,所以需要控制同时执行的进程时,就可以用进程池来控制,进程池内部维护一个进程序列,当使用时,则去进程池中获取一个进程,如果进程池序列中没有可供使用的进进程,那么程序就会等待,直到进程池中有可用进程为止。
进程池中有两个方法:
- apply(同步接口,一般用不上)
- apply_async
看个例子:
from multiprocessing import Process,Pool import time,os def func(i): time.sleep(1) print(i) print("son",os.getpid()) return "HELLO %s"%i def tag(arg): #默认带有一个参数,是上面那个子进程的返回值 print(arg) if __name__ == '__main__': pool = Pool(5) print("main pid", os.getpid()) for i in range(100): # pool.apply(func=Foo, args=(i,)) #同步接口 # pool.apply_async(func=Foo, args=(i,)) # 回调函数: 就是某个动作或者函数执行成功后再去执行的函数,比如子进程运行完后都要打印log,就可以统一在回调函数里面操作 pool.apply_async(func=func, args=(i,), callback=tag) pool.close() pool.join() # join与close调用顺序是固定的 print('end')
里面涉及到一个回调函数的概念,就是某个动作或者函数执行成功后再去执行的函数,这个例子里面看的不明显,就是在每个进程执行完,都会打印一个数,你完全可以加在你的子进程函数里面去打印嘛,为什么还有用进程函数?当你每个进程,要需要做同一件事情的时候,就可以用回调函数了,这样消耗更小。
进程的知识相对简单,线程和进程都说完了,还有内容吗?是的,还有一个协程的内容下一篇再说。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号