为什么通过clear_refs可以使进程触发缺页?
平台
ARM64
Linux 6.10
作者
pengdonglin137@163.com
背景
最近在学习Linux的缺页异常时突然奇想,在不进行内存换出的情况下,如何让进程再次触发缺页?
基于对ARMv8的理解,它的MMU的页表项中有个AF位,当AF为0时,当访问到对应的虚拟页时,会触发缺页。
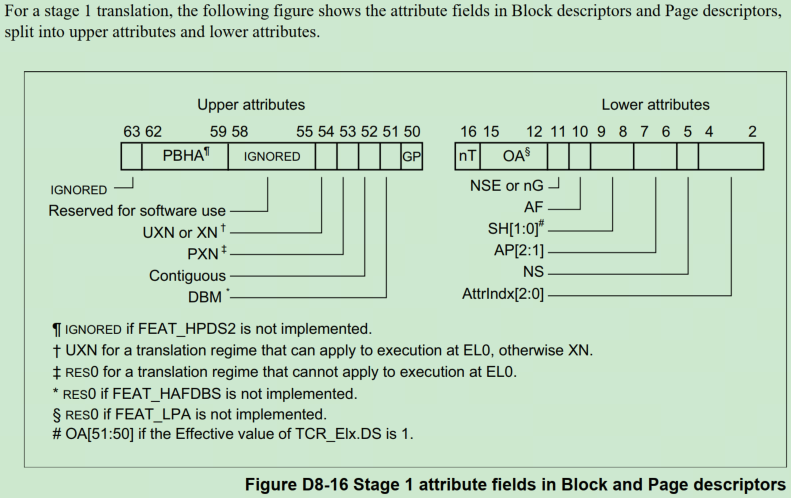


如果AF位为0,当访问到对应的虚拟页时,会触发MMU的Access flags fault。然后软件需要将这个AF位置1,之后再次访问时就不会触发这个异常了,而Linux中会使用下面的接口来清除和设置AF位:
// 清除
pmdp_test_and_clear_young
ptep_test_and_clear_young
// 设置
pte_mkyoung
以ptep_test_and_clear_young为例:
static inline int ptep_test_and_clear_young(struct vm_area_struct *vma,
unsigned long address,
pte_t *ptep)
{
pte_t pte = ptep_get(ptep);
int r = 1;
if (!pte_young(pte))
r = 0;
else
set_pte_at(vma->vm_mm, address, ptep, pte_mkold(pte));
return r;
}
#define pte_young(pte) (!!(pte_val(pte) & PTE_AF))
static inline pte_t pte_mkold(pte_t pte)
{
return clear_pte_bit(pte, __pgprot(PTE_AF));
}
这个接口用于清除PTE页表项的AF位,当再次访问时,会在缺页处理中设置AF位:
static vm_fault_t handle_pte_fault(struct vm_fault *vmf)
{
pte_t entry;
if (unlikely(pmd_none(*vmf->pmd))) {
/*
* Leave __pte_alloc() until later: because vm_ops->fault may
* want to allocate huge page, and if we expose page table
* for an instant, it will be difficult to retract from
* concurrent faults and from rmap lookups.
*/
vmf->pte = NULL;
vmf->flags &= ~FAULT_FLAG_ORIG_PTE_VALID;
} else {
/*
* A regular pmd is established and it can't morph into a huge
* pmd by anon khugepaged, since that takes mmap_lock in write
* mode; but shmem or file collapse to THP could still morph
* it into a huge pmd: just retry later if so.
*/
vmf->pte = pte_offset_map_nolock(vmf->vma->vm_mm, vmf->pmd,
vmf->address, &vmf->ptl);
if (unlikely(!vmf->pte))
return 0;
vmf->orig_pte = ptep_get_lockless(vmf->pte);
vmf->flags |= FAULT_FLAG_ORIG_PTE_VALID;
if (pte_none(vmf->orig_pte)) {
pte_unmap(vmf->pte);
vmf->pte = NULL;
}
}
// 如果还没有映射物理页,其中在填充页表的时候会设置AF位,可以参考vm_get_page_prot
if (!vmf->pte)
return do_pte_missing(vmf);
// 如果已经被交换出去
if (!pte_present(vmf->orig_pte))
return do_swap_page(vmf);
// 用于执行NUMA平衡,实现内存迁移。它会周期地把部分虚拟页对应PTE设置位PROT_NONE,读和写都会触发异常
// 然后在处理缺页的时候处理内存迁移
if (pte_protnone(vmf->orig_pte) && vma_is_accessible(vmf->vma))
return do_numa_page(vmf);
spin_lock(vmf->ptl);
entry = vmf->orig_pte;
// 通过其他路径已经设置了页表项
if (unlikely(!pte_same(ptep_get(vmf->pte), entry))) {
update_mmu_tlb(vmf->vma, vmf->address, vmf->pte);
goto unlock;
}
if (vmf->flags & (FAULT_FLAG_WRITE|FAULT_FLAG_UNSHARE)) {
if (!pte_write(entry)) // 写时复制
return do_wp_page(vmf);
else if (likely(vmf->flags & FAULT_FLAG_WRITE))
entry = pte_mkdirty(entry);
}
// 对于AF位触发的缺页,上面的条件不会满足,会走这里,设置AF位
entry = pte_mkyoung(entry);
if (ptep_set_access_flags(vmf->vma, vmf->address, vmf->pte, entry,
vmf->flags & FAULT_FLAG_WRITE)) {
update_mmu_cache_range(vmf, vmf->vma, vmf->address,
vmf->pte, 1);
} else {
/* Skip spurious TLB flush for retried page fault */
if (vmf->flags & FAULT_FLAG_TRIED)
goto unlock;
/*
* This is needed only for protection faults but the arch code
* is not yet telling us if this is a protection fault or not.
* This still avoids useless tlb flushes for .text page faults
* with threads.
*/
if (vmf->flags & FAULT_FLAG_WRITE)
flush_tlb_fix_spurious_fault(vmf->vma, vmf->address,
vmf->pte);
}
unlock:
pte_unmap_unlock(vmf->pte, vmf->ptl);
return 0;
}
而clear_refs的实现就利用了这一点,这里是关于这个节点的用法:/proc/pid/clear_refs
# 清除进程所有虚拟区域的 Access/PG_reference
# DEFINE: CLEAR_REFS_ALL 1
echo 1 > /proc/PID/clear_refs
# 清除进程所有匿名映射区域的 Access/PG_reference
# DEFINE: CLEAR_REFS_ANON 2
echo 2 > /proc/PID/clear_refs
# 清除进程所有文件映射区域的 Access/PG_reference
# DEFINE: CLEAR_REFS_MAPPED 3
echo 3 > /proc/PID/clear_refs
# 清除进程所有软脏页标志
# DEFINE: CLEAR_REFS_SOFT_DIRTY 4
echo 4 > /proc/PID/clear_refs
# 重置进程的 Hiwater_rss
# DEFINE: CLEAR_REFS_MM_HIWATER_RSS 5
echo 5 > /proc/PID/clear_refs
实现
当向clear_refs写入数值时,函数clear_refs_write被回调,这个函数中会调用:
walk_page_range(mm, 0, -1, &clear_refs_walk_ops, &cp);
其中walk_page_range负责遍历页表,在遍历的过程中会回调clear_refs_walk_ops中的函数:
static const struct mm_walk_ops clear_refs_walk_ops = {
.pmd_entry = clear_refs_pte_range,
.test_walk = clear_refs_test_walk,
.walk_lock = PGWALK_WRLOCK,
};
- test_walk回调:用于判断是否跳过当前vma,返回0表示需要遍历当前vma,返回-1表示结束遍历,返回1表示跳过当前vma
- pmd_entry回调:处理一个非空的PMD entry
先看一下如何判断是否遍历当前vma的实现:
static int clear_refs_test_walk(unsigned long start, unsigned long end,
struct mm_walk *walk)
{
struct clear_refs_private *cp = walk->private;
struct vm_area_struct *vma = walk->vma;
// 不是通过struct page来映射的
if (vma->vm_flags & VM_PFNMAP)
return 1;
/*
* Writing 1 to /proc/pid/clear_refs affects all pages.
* Writing 2 to /proc/pid/clear_refs only affects anonymous pages.
* Writing 3 to /proc/pid/clear_refs only affects file mapped pages.
* Writing 4 to /proc/pid/clear_refs affects all pages.
*/
// 如果要清除的是匿名页,但是当前vma映射到的是文件,那么跳过当前vma
if (cp->type == CLEAR_REFS_ANON && vma->vm_file)
return 1;
// 如果要清除的是文件页,但是当前vma是匿名的,那么跳过当前vma
if (cp->type == CLEAR_REFS_MAPPED && !vma->vm_file)
return 1;
// 处理当前vma
return 0;
}
接下来看看如何清除页表项的AF位:
static int clear_refs_pte_range(pmd_t *pmd, unsigned long addr,
unsigned long end, struct mm_walk *walk)
{
struct clear_refs_private *cp = walk->private;
struct vm_area_struct *vma = walk->vma;
pte_t *pte, ptent;
spinlock_t *ptl;
struct folio *folio;
ptl = pmd_trans_huge_lock(pmd, vma);
if (ptl) { // 如果是PMD映射的巨型页
if (cp->type == CLEAR_REFS_SOFT_DIRTY) {
clear_soft_dirty_pmd(vma, addr, pmd);
goto out;
}
if (!pmd_present(*pmd)) // 如果被swap出去了,跳过
goto out;
folio = pmd_folio(*pmd);
/* Clear accessed and referenced bits. */
pmdp_test_and_clear_young(vma, addr, pmd); // 清除PMD页表项的AF位
folio_test_clear_young(folio);
folio_clear_referenced(folio);
out:
spin_unlock(ptl);
return 0;
}
pte = pte_offset_map_lock(vma->vm_mm, pmd, addr, &ptl);
if (!pte) {
walk->action = ACTION_AGAIN;
return 0;
}
for (; addr != end; pte++, addr += PAGE_SIZE) {
ptent = ptep_get(pte);
if (cp->type == CLEAR_REFS_SOFT_DIRTY) {
clear_soft_dirty(vma, addr, pte);
continue;
}
if (!pte_present(ptent)) // 如果被swap出去了,跳过
continue;
folio = vm_normal_folio(vma, addr, ptent);
if (!folio)
continue;
/* Clear accessed and referenced bits. */
ptep_test_and_clear_young(vma, addr, pte); // 清除PTE页表项的AF位
folio_test_clear_young(folio);
folio_clear_referenced(folio);
}
pte_unmap_unlock(pte - 1, ptl);
cond_resched();
return 0;
}
实验
下面通过实验来观察和学习:
思路是:
- 进程通过malloc申请一块匿名内存,然后通过memset或者mlock等接口事先分配好物理页。接着反复去访问这段内存
- 通过向clear_refs写入2来清除匿名页的AF位
- 通过各种工具来观察缺页
测试程序
leak2.c
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/mman.h>
char *addr;
// 16MB
int size = 0x1000*0x1000;
int func3(void)
{
static int i = 0;
char *access;
int ret = 0;
printf("%s enter.\n", __func__);
access = addr + 0x1000*i;
printf("p: %d, s: %p, e: %p, %s access addr: %p\n",
getpid(), addr, addr + size,
i&0x1 ? "write" : "read",
access);
if (i & 0x1)
*access = 0x5a; // 触发写访问缺页
else
ret = *access; // 触发读访问缺页
sleep(1);
i++;
if (i >= 0x1000)
i = 0;
return ret;
}
int func2(void)
{
printf("%s enter.\n", __func__);
return func3();
}
int func1(void)
{
printf("%s enter.\n", __func__);
return func2();
}
int main(void)
{
int ret;
printf("%s enter.\n", __func__);
addr = malloc(size);
if (!addr) {
printf("alloc buf failed\n");
return -1;
}
/*
为了测试方便,使更容易观察到缺页,不使用THP,即不使用透明巨型页映射。
需要注意的是,不能把将THP的策略配置为always,否则总是会按照2MB的巨型页去映射
root@arm64:/sys/kernel/mm/transparent_hugepage# cat enabled
always [madvise] never
*/
ret = madvise((void *)((unsigned long)addr & ~(0x1000 - 1)), size, MADV_NOHUGEPAGE);
if (ret < 0) {
perror("set nohugepage failed");
return -1;
}
// 这个区域如果发生缺页的话,一次只映射一个page,由于下面用了mlockall,这步可以不做
ret = madvise((void *)((unsigned long)addr & ~(0x1000 - 1)), size, MADV_RANDOM);
if (ret < 0) {
perror("set random failed\n");
return -1;
}
// 预先给这片区域映射物理页
// memset(addr, 0, size);
if (mlockall(MCL_CURRENT | MCL_FUTURE) < 0) {
perror("mlockall failed");
return -1;
}
while (1)
func1();
return 0;
}
开始运行后,可以看到如下日志:
func1 enter.
func2 enter.
func3 enter.
p: 2058, s: 0xffff9a600010, e: 0xffff9b600010, write access addr: 0xffff9a611010
func1 enter.
func2 enter.
func3 enter.
p: 2058, s: 0xffff9a600010, e: 0xffff9b600010, read access addr: 0xffff9a612010
查看映射
root@arm64:/sys/kernel/mm/transparent_hugepage# pmap -x `pidof leak2`
2058: ./leak2
Address Kbytes RSS Dirty Mode Mapping
0000aaaab9690000 4 4 0 r-x-- leak2
0000aaaab96a1000 4 4 4 r---- leak2
0000aaaab96a2000 4 4 4 rw--- leak2
0000aaaae9238000 132 132 132 rw--- [ anon ]
> 0000ffff9a600000 16384 16384 16384 rw--- [ anon ]
0000ffff9b600000 4 4 4 rw--- [ anon ]
0000ffff9b796000 1388 1388 0 r-x-- libc-2.31.so
0000ffff9b8f1000 60 0 0 ----- libc-2.31.so
0000ffff9b900000 16 16 16 r---- libc-2.31.so
0000ffff9b904000 8 8 8 rw--- libc-2.31.so
0000ffff9b906000 12 12 12 rw--- [ anon ]
0000ffff9b909000 132 132 0 r-x-- ld-2.31.so
0000ffff9b92b000 8 8 8 rw--- [ anon ]
0000ffff9b937000 8 0 0 r---- [ anon ]
0000ffff9b939000 4 4 0 r-x-- [ anon ]
0000ffff9b93a000 4 4 4 r---- ld-2.31.so
0000ffff9b93b000 8 8 8 rw--- ld-2.31.so
0000ffffd0312000 132 132 132 rw--- [ stack ]
---------------- ------- ------- -------
total kB 18312 18244 16716
使用crash的vtop命令确认一下是否为按4KB的物理页映射的:
crash> vtop ffff9a600000
VIRTUAL PHYSICAL
ffff9a600000 138ae7000
PAGE DIRECTORY: ffff0000d719b000
PGD: ffff0000d719bff8 => 800000116e70003
PUD: ffff0000d6e70ff0 => 800000116f6d003
PMD: ffff0000d6f6d698 => 800000116b4d003
PTE: ffff0000d6b4d000 => e8000138ae7f43
PAGE: 138ae7000
PTE PHYSICAL FLAGS
e8000138ae7f43 138ae7000 (VALID|USER|SHARED|AF|NG|PXN|UXN|DIRTY)
VMA START END FLAGS FILE
ffff0000d739d768 ffff9a600000 ffff9b600000 40112073
PAGE PHYSICAL MAPPING INDEX CNT FLAGS
fffffdffc3e2b9c0 138ae7000 ffff0000cc765cc9 ffff9a600 1 bfffe00001d0028 uptodate,lru,mappedtodisk,swapbacked,unevictable,mlocked
上面PTE这行就是虚拟地址ffff9a600000对用的PTE页表项的内容的解析。
上面指示的区域就是malloc申请的16MB的匿名页内存区域,RSS大小也是16MB,意味着这块虚拟内存已经全部映射到了物理页。
缺页次数
top - 14:59:55 up 28 min, 4 users, load average: 0.08, 0.33, 0.50
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 2.3 sy, 0.0 ni, 97.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 3658.2 total, 2607.2 free, 612.3 used, 438.7 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 2904.3 avail Mem
nMaj nMin PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
0 4271 2058 pengdl 20 0 18312 18100 1460 S 0.0 0.5 0:01.67 leak2
通过top命令统计leak2进程的发生的缺页次数,主要是nMin(次缺页)。
正常情况下,nMin是恒定的,当执行下面的命令后:
echo 2 > /proc/`pidof leak2`/clear_refs
然后可以看到nMin会每秒增加1。用pidstat也可以佐证:
root@arm64:~# pidstat -r 1 -p `pidof leak2`
Linux 6.10.0+ (arm64) 08/23/24 _aarch64_ (4 CPU)
15:16:33 UID PID minflt/s majflt/s VSZ RSS %MEM Command
15:16:34 1000 2058 0.99 0.00 18312 18100 0.48 leak2
15:16:35 1000 2058 1.00 0.00 18312 18100 0.48 leak2
15:16:36 1000 2058 1.00 0.00 18312 18100 0.48 leak2
15:16:37 1000 2058 0.99 0.00 18312 18100 0.48 leak2
15:16:38 1000 2058 1.00 0.00 18312 18100 0.48 leak2
15:16:39 1000 2058 1.00 0.00 18312 18100 0.48 leak2
15:16:40 1000 2058 1.00 0.00 18312 18100 0.48 leak2
内核是如何统计nMaj和nMin的呢?可以参考mm_account_fault。nMaj表示在处理缺页的时候需要从后备存储(如文件、swap设备、块设备等)读取数据到page,然后进行映射。而nMin表示数据已经在内存里了,只需要修改一下页表映射,相比之下nMin的开销要比nMaj小很多。
上面写完clear_refs,可以用crash再次查看一下第一个虚拟页的PTE映射属性:
VIRTUAL PHYSICAL
ffff9a600000 138ae7000
PAGE DIRECTORY: ffff0000d719b000
PGD: ffff0000d719bff8 => 800000116e70003
PUD: ffff0000d6e70ff0 => 800000116f6d003
PMD: ffff0000d6f6d698 => 800000116b4d003
PTE: ffff0000d6b4d000 => e8000138ae7b43
PAGE: 138ae7000
PTE PHYSICAL FLAGS
e8000138ae7b43 138ae7000 (VALID|USER|SHARED|NG|PXN|UXN|DIRTY)
VMA START END FLAGS FILE
ffff0000d739d768 ffff9a600000 ffff9b600000 40112073
PAGE PHYSICAL MAPPING INDEX CNT FLAGS
fffffdffc3e2b9c0 138ae7000 ffff0000cc765cc9 ffff9a600 1 bfffe00001d0028 uptodate,lru,mappedtodisk,swapbacked,unevictable,mlocked
可以看到,AF位已经已经清除了。
使用perf观察缺页,并且记录调用栈
perf支持缺页事件:
# perf list
...
major-faults [Software event]
minor-faults [Software event]
page-faults OR faults [Software event]
...
可以参考内核代码,其实上面两个事件也是在mm_account_fault中进行记录的:
/**
* mm_account_fault - Do page fault accounting
* @mm: mm from which memcg should be extracted. It can be NULL.
* @regs: the pt_regs struct pointer. When set to NULL, will skip accounting
* of perf event counters, but we'll still do the per-task accounting to
* the task who triggered this page fault.
* @address: the faulted address.
* @flags: the fault flags.
* @ret: the fault retcode.
*
* This will take care of most of the page fault accounting. Meanwhile, it
* will also include the PERF_COUNT_SW_PAGE_FAULTS_[MAJ|MIN] perf counter
* updates. However, note that the handling of PERF_COUNT_SW_PAGE_FAULTS should
* still be in per-arch page fault handlers at the entry of page fault.
*/
static inline void mm_account_fault(struct mm_struct *mm, struct pt_regs *regs,
unsigned long address, unsigned int flags,
vm_fault_t ret)
{
bool major;
/* Incomplete faults will be accounted upon completion. */
if (ret & VM_FAULT_RETRY)
return;
/*
* To preserve the behavior of older kernels, PGFAULT counters record
* both successful and failed faults, as opposed to perf counters,
* which ignore failed cases.
*/
count_vm_event(PGFAULT);
count_memcg_event_mm(mm, PGFAULT);
/*
* Do not account for unsuccessful faults (e.g. when the address wasn't
* valid). That includes arch_vma_access_permitted() failing before
* reaching here. So this is not a "this many hardware page faults"
* counter. We should use the hw profiling for that.
*/
if (ret & VM_FAULT_ERROR)
return;
/*
* We define the fault as a major fault when the final successful fault
* is VM_FAULT_MAJOR, or if it retried (which implies that we couldn't
* handle it immediately previously).
*/
major = (ret & VM_FAULT_MAJOR) || (flags & FAULT_FLAG_TRIED);
if (major)
current->maj_flt++;
else
current->min_flt++;
/*
* If the fault is done for GUP, regs will be NULL. We only do the
* accounting for the per thread fault counters who triggered the
* fault, and we skip the perf event updates.
*/
if (!regs)
return;
if (major)
perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS_MAJ, 1, regs, address);
else
perf_sw_event(PERF_COUNT_SW_PAGE_FAULTS_MIN, 1, regs, address);
}
执行如下命令:
# perf record -e minor-faults -g -p `pidof leak2`
# perf script
root@arm64:~# perf script
leak2 2058 4140.293988: 1 minor-faults:
aaaab9690a60 func3+0xe4 (/home/pengdl/demo/kmemleak/leak2)
aaaab9690ae4 func2+0x20 (/home/pengdl/demo/kmemleak/leak2)
aaaab9690b0c func1+0x20 (/home/pengdl/demo/kmemleak/leak2)
aaaab9690c54 main+0x140 (/home/pengdl/demo/kmemleak/leak2)
ffff9b7b6e10 __libc_start_main+0xe8 (/usr/lib/aarch64-linux-gnu/libc-2.31.so)
aaaab96908a4 _start+0x34 (/home/pengdl/demo/kmemleak/leak2)
leak2 2058 4141.307048: 1 minor-faults:
aaaab9690a6c func3+0xf0 (/home/pengdl/demo/kmemleak/leak2)
aaaab9690ae4 func2+0x20 (/home/pengdl/demo/kmemleak/leak2)
aaaab9690b0c func1+0x20 (/home/pengdl/demo/kmemleak/leak2)
aaaab9690c54 main+0x140 (/home/pengdl/demo/kmemleak/leak2)
ffff9b7b6e10 __libc_start_main+0xe8 (/usr/lib/aarch64-linux-gnu/libc-2.31.so)
aaaab96908a4 _start+0x34 (/home/pengdl/demo/kmemleak/leak2)
...
使用mem_abort事件
trace_event
内核导出了下面的trace point:
root@arm64:/sys/kernel/debug/tracing/events/exceptions# ls -l
total 0
-rw-r----- 1 root root 0 Aug 23 15:43 enable
-rw-r----- 1 root root 0 Aug 23 15:43 filter
drwxr-xr-x 1 root root 0 Aug 23 15:36 mem_abort_kernel
drwxr-xr-x 1 root root 0 Aug 23 15:36 mem_abort_user
从名字可以看到,当进程在用户态触发了mem abort,那么会触发mem_abort_user事件:
root@arm64:/sys/kernel/debug/tracing/events/exceptions/mem_abort_user# cat format
name: mem_abort_user
ID: 32
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:unsigned long address; offset:8; size:8; signed:0;
field:unsigned long ip; offset:16; size:8; signed:0;
field:unsigned long error_code; offset:24; size:8; signed:0;
print fmt: "address=%ps ip=%ps error_code=0x%lx", (void *)REC->address, (void *)REC->ip, REC->error_code
可以使用这个事件进行测试:
# cd /sys/kernel/debug/tracing/events/exceptions/mem_abort_user
# echo 'comm ~ "leak2"' > filter
# echo 1 > enable
# echo 1 > /sys/kernel/tracing/tracing_on
可以看到如下日志:
root@arm64:/sys/kernel/debug/tracing/events/exceptions/mem_abort_user# cat /sys/kernel/tracing/trace_pipe
leak2-2058 [001] ..... 5312.321453: mem_abort_user: address=0xffff9a71e010 ip=0xaaaab9690a6c error_code=0x9200000b
leak2-2058 [001] ..... 5313.327391: mem_abort_user: address=0xffff9a71f010 ip=0xaaaab9690a60 error_code=0x9200004b
leak2-2058 [001] ..... 5314.331440: mem_abort_user: address=0xffff9a720010 ip=0xaaaab9690a6c error_code=0x9200000b
leak2-2058 [001] ..... 5315.337957: mem_abort_user: address=0xffff9a721010 ip=0xaaaab9690a60 error_code=0x9200004b
此外,也可以对trace event进行配置,当记录事件的时候把内核栈和用户栈也一并记录下来:
# cd /sys/kernel/debug/tracing/options
# echo 1 > userstacktrace
# echo 1 > stacktrace
# echo 1 > sym-userobj
此时看到的日志如下:
leak2-2058 [001] ..... 5537.394169: mem_abort_user: address=0xffff9a7fe010 ip=0xaaaab9690a6c error_code=0x9200000b
leak2-2058 [001] ..... 5537.394650: <stack trace>
=> do_mem_abort
=> el0_da
=> el0t_64_sync_handler
=> el0t_64_sync
leak2-2058 [001] ..... 5537.394672: <user stack trace>
=> /home/pengdl/demo/kmemleak/leak2[+0xa6c]
=> /home/pengdl/demo/kmemleak/leak2[+0xae4]
=> /home/pengdl/demo/kmemleak/leak2[+0xb0c]
=> /home/pengdl/demo/kmemleak/leak2[+0xc54]
=> /usr/lib/aarch64-linux-gnu/libc-2.31.so[+0x20e10]
=> /home/pengdl/demo/kmemleak/leak2[+0x8a4]
leak2-2058 [001] ..... 5538.399253: mem_abort_user: address=0xffff9a7ff010 ip=0xaaaab9690a60 error_code=0x9200004b
leak2-2058 [001] ..... 5538.401479: <stack trace>
=> do_mem_abort
=> el0_da
=> el0t_64_sync_handler
=> el0t_64_sync
leak2-2058 [001] ..... 5538.401545: <user stack trace>
=> /home/pengdl/demo/kmemleak/leak2[+0xa60]
=> /home/pengdl/demo/kmemleak/leak2[+0xae4]
=> /home/pengdl/demo/kmemleak/leak2[+0xb0c]
=> /home/pengdl/demo/kmemleak/leak2[+0xc54]
=> /usr/lib/aarch64-linux-gnu/libc-2.31.so[+0x20e10]
=> /home/pengdl/demo/kmemleak/leak2[+0x8a4]
使用perf
内核导出了mem_abort事件:
root@arm64:~# perf list | grep mem_abort
exceptions:mem_abort_kernel [Tracepoint event]
exceptions:mem_abort_user [Tracepoint event]
然后使用下面的命令记录:
# perf record -e exceptions:mem_abort_user -g -p `pidof leak2`
解析抓到的数据:
root@arm64:~# perf script
leak2 2058 [000] 4855.336563: exceptions:mem_abort_user: address=0xffff9b557010 ip=0xaaaab9690a60 error_code=0x9200004b
ffff80008002aae0 do_mem_abort+0xc8 ([kernel.kallsyms])
ffff80008002aae0 do_mem_abort+0xc8 ([kernel.kallsyms])
ffff800080c73380 el0_da+0x38 ([kernel.kallsyms])
ffff800080c74504 el0t_64_sync_handler+0xe4 ([kernel.kallsyms])
ffff80008001150c el0t_64_sync+0x14c ([kernel.kallsyms])
aaaab9690a60 func3+0xe4 (/home/pengdl/demo/kmemleak/leak2)
aaaab9690ae4 func2+0x20 (/home/pengdl/demo/kmemleak/leak2)
aaaab9690b0c func1+0x20 (/home/pengdl/demo/kmemleak/leak2)
aaaab9690c54 main+0x140 (/home/pengdl/demo/kmemleak/leak2)
ffff9b7b6e10 __libc_start_main+0xe8 (/usr/lib/aarch64-linux-gnu/libc-2.31.so)
aaaab96908a4 _start+0x34 (/home/pengdl/demo/kmemleak/leak2)
此外,因为是基于trace point,所以还可以对数据进行筛选和过滤,比如:
root@arm64:~# perf record -e exceptions:mem_abort_user -g --filter 'address <= 0xffff9b600010 && address >= 0xffff9a600010 && common_pid == 2058 && comm ~ "leak2"'
完。
本文来自博客园,作者:dolinux,未经同意,禁止转载
