perf_event_open学习 —— 缓冲区管理
参考
- perf_event内核框架
- tracepoint events
- software events
- hardware events
- perf_event_open系统调用内核源码分析
- perf_event_open 简介
内核版本
Linux 6.5
作者
pengdonglin137@163.com
正文
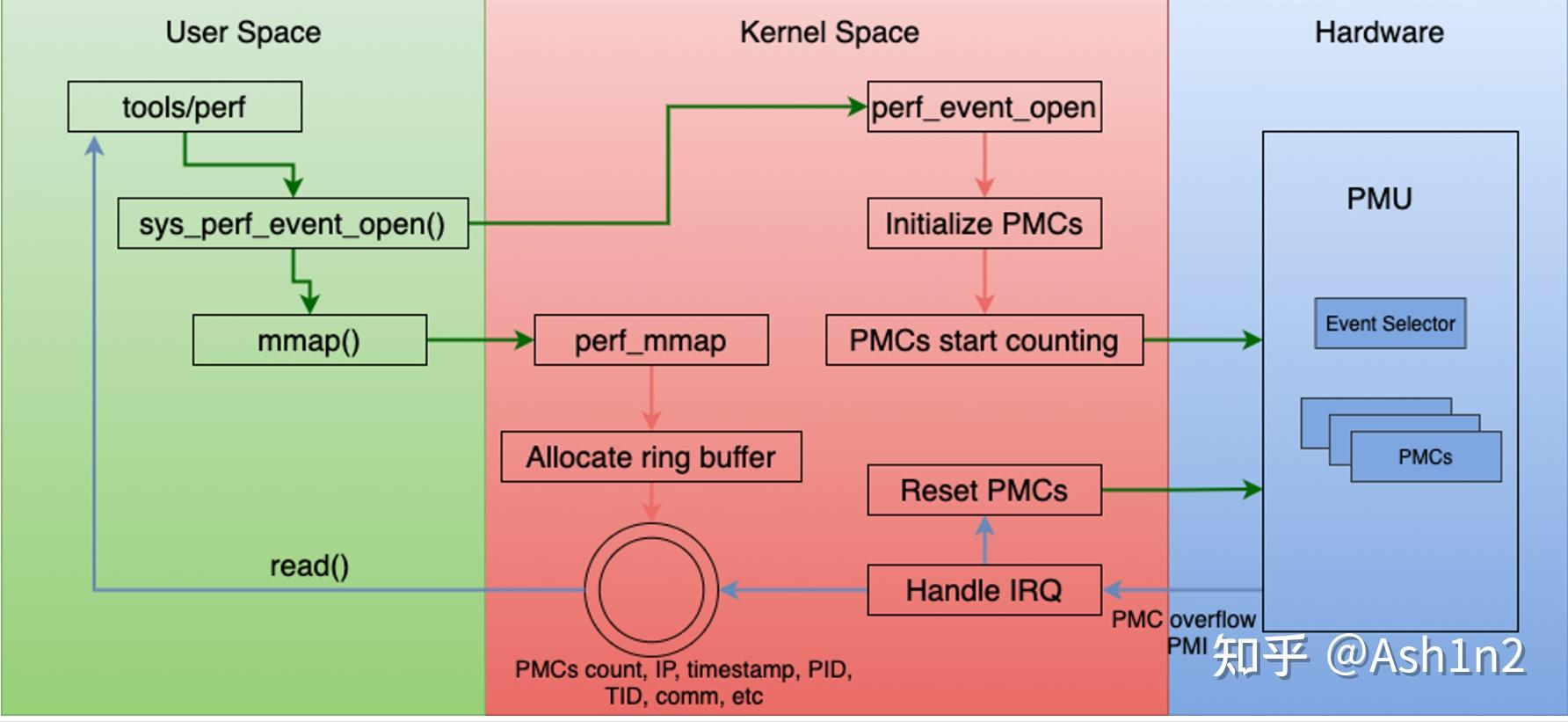
初始化
应用调用perf_event_open系统调用让内核创建perf_event时,内核创建了一个匿名文件,这个文件的file结构体的fops是perf_fops:
static const struct file_operations perf_fops = {
.llseek = no_llseek,
.release = perf_release,
.read = perf_read,
.poll = perf_poll,
.unlocked_ioctl = perf_ioctl,
.compat_ioctl = perf_compat_ioctl,
.mmap = perf_mmap,
.fasync = perf_fasync,
};
应用在得到fd后,通过调用mmap来让内核分配ring buffer,用perf_buffer结构体表示,并且将ring buffer也映射给用户,后续应用和内核就可以通过共享内存的方式实现数据共享。跟这段缓冲区对应的vma的vm_ops是perf_mmap_vmops.
内核对mmap的长度的规定是必须满足1+2^n个页,其中第1个页只是用来存放结构体perf_event_mmap_page,其中存放的是元信息,后面的2^n个页用来存放具体的采样数据。
如果应用在mmap时设置了可写,那么perf_buffer的overwrite为0,表示内核在向缓冲区写数据时与需要跟应用进行同步,防止出现内容被覆盖的情况,当然如果应用读取不及时,会造成缓冲区满的情况,此时新数据将无法写入,发生overflow。
在perf_mmap中分配ring buffer的实现如下:
struct perf_buffer *rb;
rb = rb_alloc(nr_pages,
event->attr.watermark ? event->attr.wakeup_watermark : 0,
event->cpu, flags);
ring_buffer_attach(event, rb);
perf_event_update_time(event);
perf_event_init_userpage(event);
perf_event_update_userpage(event);
调用rb_alloc分配出perf_buffer后,在ring_buffer_attach中会将rb赋值给perf_event的rb成员,分配缓冲区有两种实现方法,在编译时决定,一种是一页一页分配,这种方式会出现页之间的虚拟地址不连续,所以需要通过data_pages[]数组来记录每个页的地址,页的数量记录在rb->nr_pages中;第二种是调用vmalloc一次分配完毕,这样所有这些页的虚拟地址是连续的,此时nr_pages固定设置为1,即只需要data_pages[0],记录首地址即可,下图这种是连续的情况:
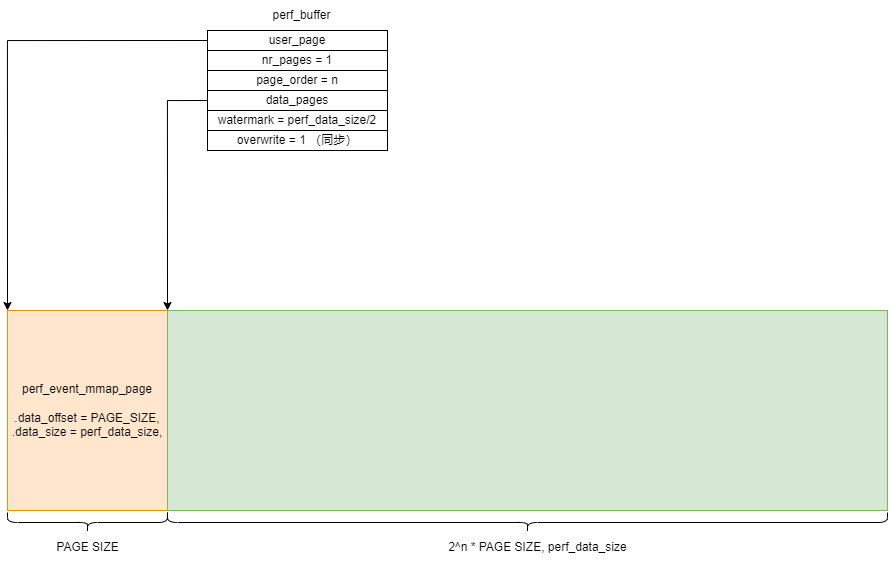
此外,内核调用perf_event_alloc来分配perf_event时,如果没有指定overflow_handler处理函数,那么内核会根据应用传递的参数设置默认的handler,假如应用没有要求按backwrite的写方向,那么handler就是perf_event_output_forward。
内核写
void
perf_event_output_forward(struct perf_event *event,
struct perf_sample_data *data,
struct pt_regs *regs)
{
__perf_event_output(event, data, regs, perf_output_begin_forward);
}
__perf_event_output
static __always_inline int
__perf_event_output(struct perf_event *event,
struct perf_sample_data *data,
struct pt_regs *regs,
int (*output_begin)(struct perf_output_handle *,
struct perf_sample_data *,
struct perf_event *,
unsigned int))
{
struct perf_output_handle handle;
struct perf_event_header header;
int err;
/* protect the callchain buffers */
rcu_read_lock();
// 根据perf_event的设置以及当前的上下文来填充perf_sample_data,此时还没进ring buffer缓冲区
perf_prepare_sample(data, event, regs);
// 填充perf_event_header,在缓冲区里内容是通过一个个以perf_event_header为首的结构体组成
perf_prepare_header(&header, data, event, regs);
// perf_output_begin_forward,更新handle,其中记录的是要写入的地址
err = output_begin(&handle, data, event, header.size);
if (err)
goto exit;
// 根据handle中记录的位置信息,将header、data等写入到缓冲区
perf_output_sample(&handle, &header, data, event);
// 更新data_head,同时处理唤醒
perf_output_end(&handle);
exit:
rcu_read_unlock();
return err;
}
perf_output_begin_forward
这个函数的作用是更新handle中操作缓冲区的成员,如addr表示要写入的位置,size表示剩余空间大小,page表示要写入的page的数组索引号。
- perf_output_begin_forward
int perf_output_begin_forward(struct perf_output_handle *handle,
struct perf_sample_data *data,
struct perf_event *event, unsigned int size)
{
return __perf_output_begin(handle, data, event, size, false);
}
__perf_output_begin
static __always_inline int
__perf_output_begin(struct perf_output_handle *handle,
struct perf_sample_data *data,
struct perf_event *event, unsigned int size,
bool backward)
{
struct perf_buffer *rb;
unsigned long tail, offset, head;
int have_lost, page_shift;
struct {
struct perf_event_header header;
u64 id;
u64 lost;
} lost_event;
rcu_read_lock();
/*
* For inherited events we send all the output towards the parent.
*/
if (event->parent)
event = event->parent;
rb = rcu_dereference(event->rb);
if (unlikely(!rb))
goto out;
if (unlikely(rb->paused)) {
if (rb->nr_pages) {
local_inc(&rb->lost);
atomic64_inc(&event->lost_samples);
}
goto out;
}
handle->rb = rb;
handle->event = event;
have_lost = local_read(&rb->lost);
if (unlikely(have_lost)) {
size += sizeof(lost_event);
if (event->attr.sample_id_all)
size += event->id_header_size;
}
// 关闭抢占,同时将rb->nest加1,同时记录rb->wakeup到handle中,用于处理是否需要唤醒应用
perf_output_get_handle(handle);
do {
/* 这里data_tail在内核这边是只读,由应用负责更新,初始值为0 */
tail = READ_ONCE(rb->user_page->data_tail);
// head表示要写入的位置对应的偏移量,初始值为0
// 在这个循环中,offset记录head推进之间的值,用来检查在此期间rb->head是否有更新
offset = head = local_read(&rb->head);
// 如果overwrite是0,那么表示内核在写入之前需要检查应用是否已经读走,防止数据被覆盖
// 当应用在mmap时设置了可写权限,那么overwrite就是0,如果是只读的话,即overwrite是1,
// 内核可以放心地覆盖缓冲区的数据,不关心应用是否已经读走
// 下面ring_buffer_has_space就是用来判断是否有足够的空间容纳size字节数据:
// (tail - head + 1)& (perf_data_size(rb) - 1)>= size
// 如果空间无法容纳,返回0,否则返回1
if (!rb->overwrite) {
if (unlikely(!ring_buffer_has_space(head, tail,
perf_data_size(rb),
size, backward)))
goto fail; // 空间不足
}
/*
* The above forms a control dependency barrier separating the
* @tail load above from the data stores below. Since the @tail
* load is required to compute the branch to fail below.
*
* A, matches D; the full memory barrier userspace SHOULD issue
* after reading the data and before storing the new tail
* position.
*
* See perf_output_put_handle().
*/
if (!backward)
head += size;
else
head -= size;
// 这里判断rb->head是否跟offset相等,如果相等,那么将head赋值给rb->head,返回offset
// 据此判断在计算head期间rb->head是否发生了更新
// 这个while循环退出后,rb->head以及head指向下一个可写的位置,offset表示head推进之前的值
} while (local_cmpxchg(&rb->head, offset, head) != offset);
// 到这里,rb->head表示下一个要写入的位置,而offset表示当前要写入的位置
if (backward) {
offset = head;
head = (u64)(-head);
}
/*
* We rely on the implied barrier() by local_cmpxchg() to ensure
* none of the data stores below can be lifted up by the compiler.
*/
if (unlikely(head - local_read(&rb->wakeup) > rb->watermark))
local_add(rb->watermark, &rb->wakeup);
// page_shift用于表示ring buffer的data区的大小,即2^n * PAGE_SIZE
page_shift = PAGE_SHIFT + page_order(rb);
// 计算data区的page索引号,data区有2^n个page组成,这里会计算offset对应的是哪个page
// 这里可以看到,head都是单调递增,导致offset此时可能已经超过缓冲区大小,需要处理wrap
handle->page = (offset >> page_shift) & (rb->nr_pages - 1);
// 计算页内偏移,同时处理了回绕
offset &= (1UL << page_shift) - 1;
// 这里会兼容两种缓冲区分配方式,一种是一页一页分配,这种方式会出现页之间的虚拟地址不连续,
// 通过data_pages[]数组记录每个页的地址,页的数量记录在rb->nr_pages中;第二种是调用vmalloc
// 一次分配完毕,这样所有这些页的虚拟地址是连续的,此时nr_pages固定设置为1,即只需要data_pages[0]
// 记录首地址即可,具体参考rb_alloc
// 如果是虚拟地址连续的情况,因为nr_pages是1,所以上面计算得到的handle->page是0,所以下面
// 下面就是rb->data_pages[0] + offset,从而得到要写入的地址
// 如果是不连续的情况,上面handle->page计算得到offset所在的page的索引,下面再得到要写入的位置
handle->addr = rb->data_pages[handle->page] + offset;
// 计算缓冲区剩余空空间大小,offset记录的是当前要写入的偏移量,尚未写入,这里只是计算写入位置信息
handle->size = (1UL << page_shift) - offset;
// 如果发生过因为缓冲区空间不足导致无法写入,上面会把have_lost设置为发生lost的次数
// 下面会往ring buffer中写入一个PERF_RECORD_LOST的记录
if (unlikely(have_lost)) {
lost_event.header.size = sizeof(lost_event);
lost_event.header.type = PERF_RECORD_LOST;
lost_event.header.misc = 0;
lost_event.id = event->id; // 发生lost的事件的perf_event的id
lost_event.lost = local_xchg(&rb->lost, 0); // lost的次数
/* XXX mostly redundant; @data is already fully initializes */
perf_event_header__init_id(&lost_event.header, data, event);
perf_output_put(handle, lost_event);
perf_event__output_id_sample(event, handle, data);
}
return 0;
fail:
// 空间不足导致写入失败,记录这种情况发生的次数
local_inc(&rb->lost);
// perf_event之间可以共享perf buffer,还需要单独再记录每个perf event发生lost的次数
atomic64_inc(&event->lost_samples);
perf_output_put_handle(handle);
out:
rcu_read_unlock();
return -ENOSPC;
}
perf_output_sample
这个函数用来根据传入的header、data等来填充缓冲区。这里暂时不打算分析,只是关心其中具体写缓冲区的函数:perf_output_put
以下面的调用为例:
perf_output_put(handle, data->time);
这个函数的作用是将data->time成员的内容写入到handle描述的缓冲区中。
展开后得到:
perf_output_copy(handle, &data->time, sizeof(data->time));
这样看上去会更加清楚。
perf_output_copy的定义如下:
unsigned int perf_output_copy(struct perf_output_handle *handle,
const void *buf, unsigned int len)
{
return __output_copy(handle, buf, len);
}
其中__output_copy进一步展开后得到:
static inline unsigned long memcpy_common(void *dst, const void *src, unsigned long n)
{
memcpy(dst, src, n);
return 0;
}
static inline unsigned long __output_copy(struct perf_output_handle *handle, const void *buf, unsigned long len)
{
unsigned long size, written;
do {
// 保证不越界
size = min(handle->size, len);
// 将buf中的内容拷贝到handle->addr指向的缓冲区中,参考上面对__perf_output_begin的分析,拷贝的字节数是size
written = memcpy_common(handle->addr, buf, size);
written = size - written;
// 如果成功写完
len -= written;
// 向前推进地址
handle->addr += written;
if (true)
buf += written;
// 写完后,更新缓冲区空闲空间字节数
handle->size -= written;
// 如果size为0,表示缓冲区用完,此时需要回绕到开头,从而实现ring buffer的功能
if (!handle->size) {
struct perf_buffer *rb = handle->rb;
// 更新要写入的page的数组索引
handle->page++;
// 对于连续缓冲区的情况,nr_pages是0,所以会将handle->page设置为0,因为此时只有data_pages[0]
handle->page &= rb->nr_pages - 1;
// 重新得到下一个要写入的位置
handle->addr = rb->data_pages[handle->page];
// data区的大小,即2^n * PAGE_SIZE
handle->size = ((1UL) << 12) << page_order(rb);
}
} while (len && written == size);
return len;
}
在perf_output_sample函数的最后有下面的逻辑:
if (!event->attr.watermark) {
int wakeup_events = event->attr.wakeup_events;
if (wakeup_events) {
struct perf_buffer *rb = handle->rb;
int events = local_inc_return(&rb->events);
if (events >= wakeup_events) {
local_sub(wakeup_events, &rb->events);
local_inc(&rb->wakeup);
}
}
}
其中wakeup_events表示每累计多少次event就唤醒一次,上面的逻辑比较简单,当次数累计够了,其中会对rb->wakeup递增,在perf_output_put_handle中会根据这个值是否有变化来判断是否需要唤醒应用。
perf_output_put_handle
- perf_output_end
void perf_output_end(struct perf_output_handle *handle)
{
perf_output_put_handle(handle);
rcu_read_unlock();
}
- perf_output_put_handle
static void perf_output_put_handle(struct perf_output_handle *handle)
{
struct perf_buffer *rb = handle->rb;
unsigned long head;
unsigned int nest;
/*
* If this isn't the outermost nesting, we don't have to update
* @rb->user_page->data_head.
*/
nest = READ_ONCE(rb->nest);
if (nest > 1) {
WRITE_ONCE(rb->nest, nest - 1);
goto out;
}
again:
/*
* In order to avoid publishing a head value that goes backwards,
* we must ensure the load of @rb->head happens after we've
* incremented @rb->nest.
*
* Otherwise we can observe a @rb->head value before one published
* by an IRQ/NMI happening between the load and the increment.
*/
barrier();
head = local_read(&rb->head);
/*
* IRQ/NMI can happen here and advance @rb->head, causing our
* load above to be stale.
*/
/*
* Since the mmap() consumer (userspace) can run on a different CPU:
*
* kernel user
*
* if (LOAD ->data_tail) { LOAD ->data_head
* (A) smp_rmb() (C)
* STORE $data LOAD $data
* smp_wmb() (B) smp_mb() (D)
* STORE ->data_head STORE ->data_tail
* }
*
* Where A pairs with D, and B pairs with C.
*
* In our case (A) is a control dependency that separates the load of
* the ->data_tail and the stores of $data. In case ->data_tail
* indicates there is no room in the buffer to store $data we do not.
*
* D needs to be a full barrier since it separates the data READ
* from the tail WRITE.
*
* For B a WMB is sufficient since it separates two WRITEs, and for C
* an RMB is sufficient since it separates two READs.
*
* See perf_output_begin().
*/
smp_wmb(); /* B, matches C */
// 将head更新到perf_event_mmap_page中,需要注意的是,这个值是单调递增,需要应用
// 自己处理回绕的问题,此外,这个值表示下一个要写入的位置,而不是刚刚写入的记录的
// 位置,所以需要应用自己备份
WRITE_ONCE(rb->user_page->data_head, head);
/*
* We must publish the head before decrementing the nest count,
* otherwise an IRQ/NMI can publish a more recent head value and our
* write will (temporarily) publish a stale value.
*/
barrier();
WRITE_ONCE(rb->nest, 0);
/*
* Ensure we decrement @rb->nest before we validate the @rb->head.
* Otherwise we cannot be sure we caught the 'last' nested update.
*/
barrier();
if (unlikely(head != local_read(&rb->head))) {
WRITE_ONCE(rb->nest, 1);
goto again;
}
if (handle->wakeup != local_read(&rb->wakeup))
perf_output_wakeup(handle);
out:
preempt_enable();
}
唤醒应用
在内核写完一个事件后,最后在调用perf_output_put_handle时,如果发现需要唤醒应用,那么会调用perf_output_wakeup。
static void perf_output_wakeup(struct perf_output_handle *handle)
{
atomic_set(&handle->rb->poll, EPOLLIN);
handle->event->pending_wakeup = 1;
irq_work_queue(&handle->event->pending_irq);
}
在分配perf_event时,给pending_irq设置的是perf_pending_irq:
static void perf_pending_irq(struct irq_work *entry)
{
struct perf_event *event = container_of(entry, struct perf_event, pending_irq);
int rctx;
/*
* If we 'fail' here, that's OK, it means recursion is already disabled
* and we won't recurse 'further'.
*/
rctx = perf_swevent_get_recursion_context();
/*
* The wakeup isn't bound to the context of the event -- it can happen
* irrespective of where the event is.
*/
if (event->pending_wakeup) {
event->pending_wakeup = 0;
// 应用如果在poll的话,会被唤醒
perf_event_wakeup(event);
}
__perf_pending_irq(event);
if (rctx >= 0)
perf_swevent_put_recursion_context(rctx);
}
应用读
参考: https://www.cnblogs.com/pengdonglin137/p/17989602
下面两个参考链接中给出了data_tail如何使用。
完。
本文来自博客园,作者:dolinux,未经同意,禁止转载

