perf_event_open学习 —— mmap方式读取
示例程序2
在上一篇《Linux perf子系统的使用(一)——计数》已经讲解了如何使用perf_event_open、read和ioctl对perf子系统进行编程。但有时我们并不需要计数,而是要采样。比如这么一个需求:统计一个程序中哪些函数最耗时间。嗯,这个功能确实可以通过perf record命令来做,但是perf record内部又是如何做到的呢?自己实现又是怎样的呢?perf record是基于统计学原理的。假设以1000Hz的频率对某个进程采样,每次采样记录下该进程的IP寄存器的值(也就是下一条指令的地址)。通过分析该进程的可执行文件,是可以得知每次采样的IP值处于哪个函数内部。OK,那么我们相当于以1000Hz的频率获知进程当前所执行的函数。如果某个函数f()占用了30%的时间,那么所有采样中,该函数出现的频率也应该将近30%,只要采样数量足够多。这正是perf record的原理。所以,perf的采样模式很有用~
但是,采样比较复杂,主要表现在三点:1、采样需要设置触发源,也就是告诉kernel何时进行一次采样;2、采样需要设置信号,也就是告诉kernnel,采样完成后通知谁;3、采样值的读取需要使用mmap,因为采样有异步性,需要一个环形队列,另外也是出于性能的考虑。
直接上代码吧,对照着官方手册看,学习效率最高:
采集单个值
perf.c
//如果不加,则F_SETSIG未定义
#define _GNU_SOURCE 1
#include <stdio.h>
#include <fcntl.h>
#include <stdint.h>
#include <unistd.h>
#include <string.h>
#include <signal.h>
#include <sys/mman.h>
#include <sys/syscall.h>
#include <linux/perf_event.h>
//环形缓冲区大小,16页,即16*4kB
#define RING_BUFFER_PAGES 16
//目前perf_event_open在glibc中没有封装,需要手工封装一下
int perf_event_open(struct perf_event_attr *attr,pid_t pid,int cpu,int group_fd,unsigned long flags)
{
return syscall(__NR_perf_event_open,attr,pid,cpu,group_fd,flags);
}
//mmap共享内存的开始地址
void* rbuf;
//环形队列中每一项元素
struct perf_my_sample
{
struct perf_event_header header;
uint64_t ip;
};
//下一条采样记录的相对于环形缓冲区开头的偏移量
uint64_t next_offset=0;
//采样完成后的信号处理函数
void sample_handler(int sig_num,siginfo_t *sig_info,void *context)
{
//计算出最新的采样所在的位置(相对于rbuf的偏移量)
uint64_t offset=4096+next_offset;
//指向最新的采样
struct perf_my_sample* sample=(void*)((uint8_t*)rbuf+offset);
//过滤一下记录
if(sample->header.type==PERF_RECORD_SAMPLE)
{
//得到IP值
printf("%lx\n",sample->ip);
}
//共享内存开头是一个struct perf_event_mmap_page,提供环形缓冲区的信息
struct perf_event_mmap_page* rinfo=rbuf;
//手工wrap一下data_head值,得到下一个记录的偏移量
next_offset=rinfo->data_head%(RING_BUFFER_PAGES*4096);
}
//模拟的一个负载
void workload()
{
int i,c=0;
for(i=0;i<100000000;i++)
{
c+=i*i;
c-=i*100;
c+=i*i*i/100;
}
}
int main()
{
struct perf_event_attr attr;
memset(&attr,0,sizeof(struct perf_event_attr));
attr.size=sizeof(struct perf_event_attr);
//触发源为CPU时钟
attr.type=PERF_TYPE_SOFTWARE;
attr.config=PERF_COUNT_SW_CPU_CLOCK;
//每100000个CPU时钟采样一次
attr.sample_period=100000;
//采样目标是IP
attr.sample_type=PERF_SAMPLE_IP;
//初始化为禁用
attr.disabled=1;
int fd=perf_event_open(&attr,0,-1,-1,0);
if(fd<0)
{
perror("Cannot open perf fd!");
return 1;
}
//创建1+16页共享内存,应用程序只读,读取fd产生的内容
rbuf=mmap(0,(1+RING_BUFFER_PAGES)*4096,PROT_READ,MAP_SHARED,fd,0);
if(rbuf<0)
{
perror("Cannot mmap!");
return 1;
}
//这三个fcntl为何一定这么设置不明,但必须这样
fcntl(fd,F_SETFL,O_RDWR|O_NONBLOCK|O_ASYNC);
fcntl(fd,F_SETSIG,SIGIO);
fcntl(fd,F_SETOWN,getpid());
//开始设置采样完成后的信号通知
struct sigaction sig;
memset(&sig,0,sizeof(struct sigaction));
//由sample_handler来处理采样完成事件
sig.sa_sigaction=sample_handler;
//要带上siginfo_t参数(因为perf子系统会传入参数,包括fd)
sig.sa_flags=SA_SIGINFO;
if(sigaction(SIGIO,&sig,0)<0)
{
perror("Cannot sigaction");
return 1;
}
//开始监测
ioctl(fd,PERF_EVENT_IOC_RESET,0);
ioctl(fd,PERF_EVENT_IOC_ENABLE,0);
workload();
//停止监测
ioctl(fd,PERF_EVENT_IOC_DISABLE,0);
munmap(rbuf,(1+RING_BUFFER_PAGES)*4096);
close(fd);
return 0;
}
可以看到一下子比计数模式复杂多了。采样模式是要基于计数模式的——选择一个“参考计数器”,并设置一个阈值,每当这个“参考计数器”达到阈值时,触发一次采样。每次采样,kernel会把值放入队列的末尾。如何得知kernenl完成了一次最新的采样了呢?一种方法就是定时轮询,另一种就是响应信号。
如何读取mmap共享内存中的值呢?首先,共享内存开头是一个struct perf_event_mmap_page,提供环形缓冲区的信息,对我们最重要的字段就是data_head,官方手册的介绍是这样的:

注意,data_head一直递增,不回滚!!所以需要手动处理wrap。另外一个需要注意的地方是,每次事件响应中,得到的data_head是下一次采样的队列头部,所以需要自己保存一个副本next_offset,以供下次使用。
这个struct perf_event_mmap_page独占共享内存的第一页。后面必须跟2n页,n自己决定。这2n页用来存放采样记录。每一条记录的结构体如下:
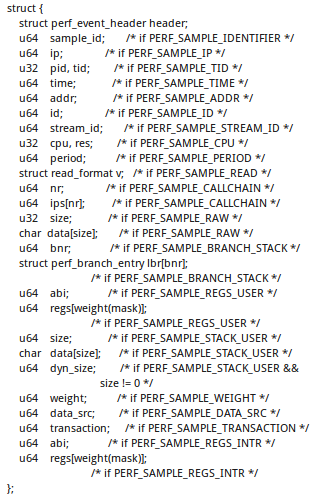
因为我只选择了采样IP,即PERF_SAMPLE_IP,所以这个结构体就退化为了:
struct perf_my_sample
{
struct perf_event_header header;
uint64_t ip;
};
另外一个需要注意的地方是mmap中的第三个参数,是PROT_READ,表示应用程序只读。如果设置为了PROT_READ|PROT_WRITE,那么读取的过程就不一样了:

这样相当于和kernel做一个同步操作,效率务必下降。而且由于SIGIO这个信号是不可靠信号,所以如果某次采样完成的通知没有被截获,那么就可能产生死锁。
gcc perf.c -o perf
sudo ./perf
运行上面的代码,产生如下输出:

为了验证采集到的IP值是否正确,可以反汇编一下:
objdump -d ./perf
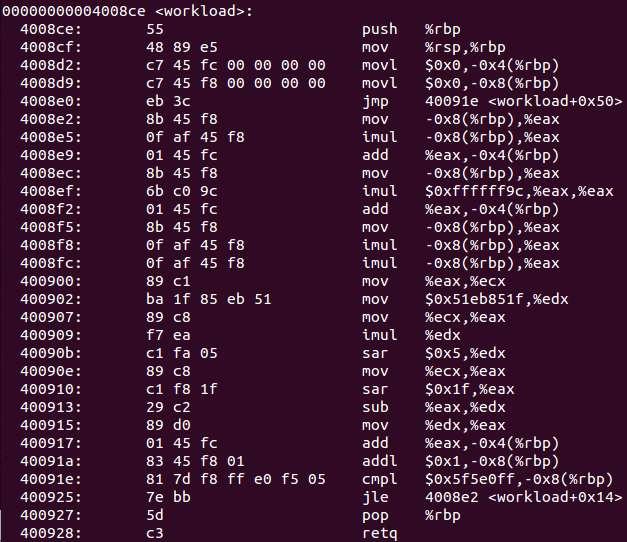
可以看到采集到的IP值全部落在workload这个函数的地址范围内。
采集多个值
要采多个值的话,也很方便:
//如果不加,则F_SETSIG未定义
#define _GNU_SOURCE 1
#include <stdio.h>
#include <fcntl.h>
#include <stdint.h>
#include <unistd.h>
#include <string.h>
#include <signal.h>
#include <sys/mman.h>
#include <sys/syscall.h>
#include <linux/perf_event.h>
//环形缓冲区大小,16页,即16*4kB
#define RING_BUFFER_PAGES 2
//目前perf_event_open在glibc中没有封装,需要手工封装一下
int perf_event_open(struct perf_event_attr *attr,pid_t pid,int cpu,int group_fd,unsigned long flags)
{
return syscall(__NR_perf_event_open,attr,pid,cpu,group_fd,flags);
}
//mmap共享内存的开始地址
void* rbuf;
//环形队列中每一项元素
struct perf_my_sample
{
struct perf_event_header header;
uint64_t ip;
uint64_t nr;
uint64_t ips[0];
};
//下一条采样记录的相对于环形缓冲区开头的偏移量
uint64_t next_offset=0;
//采样完成后的信号处理函数
void sample_handler(int sig_num,siginfo_t *sig_info,void *context)
{
//计算出最新的采样所在的位置(相对于rbuf的偏移量)
uint64_t offset=4096+next_offset;
//指向最新的采样
struct perf_my_sample* sample=(void*)((uint8_t*)rbuf+offset);
//过滤一下记录
if(sample->header.type==PERF_RECORD_SAMPLE)
{
//得到IP值
printf("IP: %lx\n",sample->ip);
if(sample->nr<1024)
{
//得到调用链长度
printf("Call Depth: %lu\n",sample->nr);
//遍历调用链
int i;
for(i=0;i<sample->nr;i++)
printf(" %lx\n",sample->ips[i]);
}
}
//共享内存开头是一个struct perf_event_mmap_page,提供环形缓冲区的信息
struct perf_event_mmap_page* rinfo=rbuf;
//手工wrap一下data_head值,得到下一个记录的偏移量
next_offset=rinfo->data_head%(RING_BUFFER_PAGES*4096);
}
//模拟的一个负载
void workload()
{
int i,c=0;
for(i=0;i<1000000000;i++)
{
c+=i*i;
c-=i*100;
c+=i*i*i/100;
}
}
int main()
{
struct perf_event_attr attr;
memset(&attr,0,sizeof(struct perf_event_attr));
attr.size=sizeof(struct perf_event_attr);
//触发源为CPU时钟
attr.type=PERF_TYPE_SOFTWARE;
attr.config=PERF_COUNT_SW_CPU_CLOCK;
//每100000个CPU时钟采样一次
attr.sample_period=100000;
//采样目标是IP
attr.sample_type=PERF_SAMPLE_IP|PERF_SAMPLE_CALLCHAIN;
//初始化为禁用
attr.disabled=1;
int fd=perf_event_open(&attr,0,-1,-1,0);
if(fd<0)
{
perror("Cannot open perf fd!");
return 1;
}
//创建1+16页共享内存,应用程序只读,读取fd产生的内容
rbuf=mmap(0,(1+RING_BUFFER_PAGES)*4096,PROT_READ,MAP_SHARED,fd,0);
if(rbuf<0)
{
perror("Cannot mmap!");
return 1;
}
//这三个fcntl为何一定这么设置不明,但必须这样
fcntl(fd,F_SETFL,O_RDWR|O_NONBLOCK|O_ASYNC);
fcntl(fd,F_SETSIG,SIGIO);
fcntl(fd,F_SETOWN,getpid());
//开始设置采样完成后的信号通知
struct sigaction sig;
memset(&sig,0,sizeof(struct sigaction));
//由sample_handler来处理采样完成事件
sig.sa_sigaction=sample_handler;
//要带上siginfo_t参数(因为perf子系统会传入参数,包括fd)
sig.sa_flags=SA_SIGINFO;
if(sigaction(SIGIO,&sig,0)<0)
{
perror("Cannot sigaction");
return 1;
}
//开始监测
ioctl(fd,PERF_EVENT_IOC_RESET,0);
ioctl(fd,PERF_EVENT_IOC_ENABLE,0);
workload();
//停止监测
ioctl(fd,PERF_EVENT_IOC_DISABLE,0);
munmap(rbuf,(1+RING_BUFFER_PAGES)*4096);
close(fd);
return 0;
}
示例程序2
在上一篇《Linux perf子系统的使用(二)——采样(signal方式)》中,我使用了信号来接收采样完成通知,并在回调函数中读取最新的采样值。虽说回调方式有很多优点,但是并不是太通用。更加糟糕的是,信号会打断几乎所有的系统调用,使得本来的程序逻辑被破坏。另一个很糟糕的点是,如果一个进程中需要开多个采样器,那么就要共享同一个事件回调函数,破坏了封装性。
因此,最好有一个阻塞式轮询的办法。嗯,这就是今天要讲的东西——通过poll()函数等待采样完成。
其实poll()轮询的实现比信号的方式简单,只要把perf_event_open()返回的文件描述符当做普通的文件描述符传入poll()就可以了。在创建perf文件描述附时,唯一需要注意的就是需要手动设置wakeup_events的值。wakeup_events决定了多少次采样以后进行一次通知(poll模式下就是让poll返回),一般设置为1。
直接上代码吧,和《Linux perf子系统的使用(二)——采样(signal方式)》中的代码比较一下就一目了然了。
perf_poll.cpp
#include <poll.h>
#include <errno.h>
#include <stdio.h>
#include <stdint.h>
#include <assert.h>
#include <signal.h>
#include <string.h>
#include <unistd.h>
#include <signal.h>
#include <sys/mman.h>
#include <sys/ioctl.h>
#include <sys/syscall.h>
#include <linux/perf_event.h>
// the number of pages to hold ring buffer
#define RING_BUFFER_PAGES 8
// a wrapper for perf_event_open()
static int perf_event_open(struct perf_event_attr *attr,
pid_t pid,int cpu,int group_fd,unsigned long flags)
{
return syscall(__NR_perf_event_open,attr,pid,cpu,group_fd,flags);
}
static bool sg_running=true;
// to receive SIGINT to stop sampling and exit
static void on_closing(int signum)
{
sg_running=false;
}
int main()
{
// 这里我强行指定了一个值
pid_t pid=6268;
// create a perf fd
struct perf_event_attr attr;
memset(&attr,0,sizeof(struct perf_event_attr));
attr.size=sizeof(struct perf_event_attr);
// disable at init time
attr.disabled=1;
// set what is the event
attr.type=PERF_TYPE_SOFTWARE;
attr.config=PERF_COUNT_SW_CPU_CLOCK;
// how many clocks to trigger sampling
attr.sample_period=1000000;
// what to sample is IP
attr.sample_type=PERF_SAMPLE_IP;
// notify every 1 overflow
attr.wakeup_events=1;
// open perf fd
int perf_fd=perf_event_open(&attr,pid,-1,-1,0);
if(perf_fd<0)
{
perror("perf_event_open() failed!");
return errno;
}
// create a shared memory to read samples from kernel
void* shared_mem=mmap(0,(1+RING_BUFFER_PAGES)*4096,PROT_READ,MAP_SHARED,perf_fd,0);
if(shared_mem==0)
{
perror("mmap() failed!");
return errno;
}
// reset and enable
ioctl(perf_fd,PERF_EVENT_IOC_RESET,0);
ioctl(perf_fd,PERF_EVENT_IOC_ENABLE,0);
// the offset from the head of ring-buffer where the next sample is
uint64_t next_offset=0;
// poll perf_fd
struct pollfd perf_poll;
perf_poll.fd=perf_fd;
perf_poll.events=POLLIN;
signal(SIGINT,on_closing);
while(sg_running)
{
if(poll(&perf_poll,1,-1)<0)
{
perror("poll() failed!");
break;
}
// the pointer to the completed sample
struct sample
{
struct perf_event_header header;
uint64_t ip;
}*
sample=(struct sample*)((uint8_t*)shared_mem+4096+next_offset);
// the pointer to the info structure of ring-buffer
struct perf_event_mmap_page* info=(struct perf_event_mmap_page*)shared_mem;
// update the offset, wrap the offset
next_offset=info->data_head%(RING_BUFFER_PAGES*4096);
// allow only the PERF_RECORD_SAMPLE
if(sample->header.type!=PERF_RECORD_SAMPLE)
continue;
printf("%lx\n",sample->ip);
}
printf("clean up\n");
// disable
ioctl(perf_fd,PERF_EVENT_IOC_DISABLE,0);
// unmap shared memory
munmap(shared_mem,(1+RING_BUFFER_PAGES)*4096);
// close perf fd
close(perf_fd);
return 0;
}
可以看到除了获取通知的部分由signal改为poll()以外,几乎没有改动。
g++ perf_poll.cpp -o perf_poll
sudo ./perf_poll
==2017年7月28日补充
首先,为了方便以后的使用,我把perf采样callchain的功能封装成了一个C++的类,它能够针对一个特定的pid进行采样,支持带有超时的轮询。接口声明如下:
CallChainSampler.h
#ifndef CALLCHAINSAMPLER_H
#define CALLCHAINSAMPLER_H
#include <stdint.h>
#include <unistd.h>
// a class to sample the callchain of a process
class CallChainSampler
{
public:
// the structure of a sampled callchain
struct callchain
{
// the timestamp when sampling
uint64_t time;
// the pid and tid
uint32_t pid,tid;
// the depth of callchain, or called the length
uint64_t depth;
// <depth>-array, each items is an IP register value
const uint64_t* ips;
};
// constructor
// pid: the process's id
// period: how many clocks to trigger a sample
// pages: how many pages (4K) allocated for the ring-buffer to hold samples
CallChainSampler(pid_t pid,uint64_t period,uint32_t pages);
// destructor
~CallChainSampler();
// start sampling
void start();
// stop sampling
void stop();
// wait and get the next sample
// timeout: the max milliseconds that will block
// max_depth: the max depth of the call chain
// callchain: the sampled callchain to be outputed
// return: if get before timeout, return 0,
// if timeout, return -1
// if an error occurs, return errno
// ATTENTION: the field [ips] in callchain should be used immediately,
// don't hold it for too long time
int sample(int32_t timeout,uint64_t max_depth,struct callchain* callchain);
private:
// the perf file descriptor
int fd;
// the mmap area
void* mem;
// how many pages to hold the ring-buffer
uint32_t pages;
// the offset in the ring-buffer where the next sample is
uint64_t offset;
};
#endif
实现基本就是把上面的C代码封装一下:
CallChainSampler.cpp
#include "CallChainSampler.h"
#include <poll.h>
#include <errno.h>
#include <assert.h>
#include <string.h>
#include <stdexcept>
#include <sys/time.h>
#include <sys/mman.h>
#include <sys/ioctl.h>
#include <sys/syscall.h>
#include <linux/perf_event.h>
// a wrapper for perf_event_open()
static int perf_event_open(struct perf_event_attr *attr,
pid_t pid,int cpu,int group_fd,unsigned long flags)
{
return syscall(__NR_perf_event_open,attr,pid,cpu,group_fd,flags);
}
// a tool function to get the time in ms
static uint64_t get_milliseconds()
{
struct timeval now;
assert(gettimeofday(&now,0)==0);
return now.tv_sec*1000+now.tv_usec/1000;
}
#define min(a,b) ((a)<(b)?(a):(b))
CallChainSampler::CallChainSampler(pid_t pid,uint64_t period,uint32_t pages)
{
// create a perf fd
struct perf_event_attr attr;
memset(&attr,0,sizeof(struct perf_event_attr));
attr.size=sizeof(struct perf_event_attr);
// disable at init time
attr.disabled=1;
// set what is the event
attr.type=PERF_TYPE_SOFTWARE;
attr.config=PERF_COUNT_SW_CPU_CLOCK;
// how many clocks to trigger sampling
attr.sample_period=period;
// what to sample is IP
attr.sample_type=PERF_SAMPLE_TIME|PERF_SAMPLE_TID|PERF_SAMPLE_CALLCHAIN;
// notify every 1 overflow
attr.wakeup_events=1;
// open perf fd
fd=perf_event_open(&attr,pid,-1,-1,0);
if(fd<0)
throw std::runtime_error("perf_event_open() failed!");
// create a shared memory to read samples from kernel
mem=mmap(0,(1+pages)*4096,PROT_READ,MAP_SHARED,fd,0);
if(mem==0)
throw std::runtime_error("mmap() failed!");
this->pages=pages;
// the offset of next sample
offset=0;
}
CallChainSampler::~CallChainSampler()
{
stop();
// unmap shared memory
munmap(mem,(1+pages)*4096);
// close perf fd
close(fd);
}
void CallChainSampler::start()
{
// enable
ioctl(fd,PERF_EVENT_IOC_ENABLE,0);
}
void CallChainSampler::stop()
{
// disable
ioctl(fd,PERF_EVENT_IOC_DISABLE,0);
}
int CallChainSampler::sample(int32_t timeout,uint64_t max_depth,struct callchain* callchain)
{
if(callchain==0)
throw std::runtime_error("arg <callchain> is NULL!");
// the poll sturct
struct pollfd pfd;
pfd.fd=fd;
pfd.events=POLLIN;
// the time when start
uint64_t start=get_milliseconds();
while(1)
{
// the current time
uint64_t now=get_milliseconds();
// the milliseconds to wait
int32_t to_wait;
if(timeout<0)
to_wait=-1;
else
{
to_wait=timeout-(int32_t)(now-start);
if(to_wait<0)
return -1;
}
// wait next sample
int ret=poll(&pfd,1,to_wait);
if(ret==0)
return -1;
else if(ret==-1)
return errno;
// the pointer to the completed sample
struct sample
{
struct perf_event_header header;
uint32_t pid,tid;
uint64_t time;
uint64_t nr;
uint64_t ips[0];
}*
sample=(struct sample*)((uint8_t*)mem+4096+offset);
// the pointer to the info structure of ring-buffer
struct perf_event_mmap_page* info=(struct perf_event_mmap_page*)mem;
// update the offset, wrap the offset
offset=info->data_head%(pages*4096);
// allow only the PERF_RECORD_SAMPLE
if(sample->header.type!=PERF_RECORD_SAMPLE)
continue;
// fill the result
callchain->time=sample->time;
callchain->pid=sample->pid;
callchain->tid=sample->tid;
callchain->depth=min(max_depth,sample->nr);
callchain->ips=sample->ips;
return 0;
}
}
最后要补充一个我最新的发现!perf_event_open()里面传入的pid,本质上是一个线程id,也就是tid。它只能监控一个线程,而无法监控一个进程中的所有线程。所以要用到实际项目中,肯定得配合使用epoll来监控所有的线程。
测试代码如下:
#include <stdio.h>
#include <signal.h>
#include <stdlib.h>
#include "CallChainSampler.h"
CallChainSampler* sampler;
// to receive SIGINT to stop sampling and exit
static void on_closing(int signum)
{
delete sampler;
exit(0);
}
int main()
{
// create a sampler, pid=5281, 10000 clocks trigger a sample
// and allocate 128 pages to hold the ring-buffer
sampler=new CallChainSampler(5281,10000,128);
signal(SIGINT,on_closing);
sampler->start();
for(int i=0;i<10000;i++)
{
CallChainSampler::callchain callchain;
// sample, max depth of callchain is 256
int ret=sampler->sample(-1,256,&callchain);
printf("%d\n",ret);
if(ret==0)
{
// successful sample, print it out
printf("time=%lu\n",callchain.time);
printf("pid,tid=%d,%d\n",callchain.pid,callchain.tid);
printf("stack:\n");
for(int j=0;j<callchain.depth;j++)
printf("[%d] %lx\n",j,callchain.ips[j]);
}
}
return 0;
}
示例程序3
#define _GNU_SOURCE
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/syscall.h>
#include <string.h>
#include <sys/ioctl.h>
#include <linux/perf_event.h>
#include <sys/mman.h>
#include <linux/hw_breakpoint.h>
#include <asm/unistd.h>
#include <errno.h>
#include <stdint.h>
#include <inttypes.h>
#ifndef MAP_FAILED
#define MAP_FAILED ((void *)-1)
#endif
struct perf_sample_event {
struct perf_event_header hdr;
uint64_t sample_id; // if PERF_SAMPLE_IDENTIFIER
uint64_t ip; // if PERF_SAMPLE_IP
uint32_t pid, tid; // if PERF_SAMPLE_TID
uint64_t time; // if PERF_SAMPLE_TIME
uint64_t addr; // if PERF_SAMPLE_ADDR
uint64_t id; // if PERF_SAMPLE_ID
uint64_t stream_id; // if PERF_SAMPLE_STREAM_ID
uint32_t cpu, res; // if PERF_SAMPLE_CPU
uint64_t period; // if PERF_SAMPLE_PERIOD
struct read_format *v; // if PERF_SAMPLE_READ
uint64_t nr; // if PERF_SAMPLE_CALLCHAIN
uint64_t *ips; // if PERF_SAMPLE_CALLCHAIN
uint32_t size_raw; // if PERF_SAMPLE_RAW
char *data_raw; // if PERF_SAMPLE_RAW
uint64_t bnr; // if PERF_SAMPLE_BRANCH_STACK
struct perf_branch_entry *lbr; // if PERF_SAMPLE_BRANCH_STACK
uint64_t abi; // if PERF_SAMPLE_REGS_USER
uint64_t *regs; // if PERF_SAMPLE_REGS_USER
uint64_t size_stack; // if PERF_SAMPLE_STACK_USER
char *data_stack; // if PERF_SAMPLE_STACK_USER
uint64_t dyn_size_stack; // if PERF_SAMPLE_STACK_USER
uint64_t weight; // if PERF_SAMPLE_WEIGHT
uint64_t data_src; // if PERF_SAMPLE_DATA_SRC
uint64_t transaction; // if PERF_SAMPLE_TRANSACTION
uint64_t abi_intr; // if PERF_SAMPLE_REGS_INTR
uint64_t *regs_intr; // if PERF_SAMPLE_REGS_INTR
};
int fib(int n) {
if (n == 0) {
return 0;
} else if (n == 1 || n == 2) {
return 1;
} else {
return fib(n-1) + fib(n-2);
}
}
void do_something() {
int i;
char* ptr;
ptr = malloc(100*1024*1024);
for (i = 0; i < 100*1024*1024; i++) {
ptr[i] = (char) (i & 0xff); // pagefault
}
free(ptr);
}
void insertion_sort(int *nums, size_t n) {
int i = 1;
while (i < n) {
int j = i;
while (j > 0 && nums[j-1] > nums[j]) {
int tmp = nums[j];
nums[j] = nums[j-1];
nums[j-1] = tmp;
j -= 1;
}
i += 1;
}
}
static void process_ring_buffer_events(struct perf_event_mmap_page *data, int page_size) {
struct perf_event_header *header = (uintptr_t) data + page_size + data->data_tail;
void *end = (uintptr_t) data + page_size + data->data_head;
while (header != end) {
if (header->type == PERF_RECORD_SAMPLE) {
struct perf_sample_event *event = (uintptr_t) header;
uint64_t ip = event->ip;
printf("PERF_RECORD_SAMPLE found with ip: %lld\n", ip);
uint64_t size_stack = event->size_stack;
char *data_stack = (uintptr_t) event->data_stack;
if (data_stack > 0) {
printf("PERF_RECORD_SAMPLE has size stack: %lld at location: %lld\n", size_stack, data_stack);
}
} else {
printf("other type %d found!", header->type);
}
header = (uintptr_t) header + header->size;
}
}
int main(int argc, char* argv[]) {
struct perf_event_attr pea;
int fd1, fd2;
uint64_t id1, id2;
uint64_t val1, val2;
char buf[4096];
const int NUM_MMAP_PAGES = (1U << 4) + 1;
// const int NUM_MMAP_PAGES = 17;
int i;
int some_nums[1000];
for (int i=0; i < 1000; i++) {
some_nums[i] = 1000-i;
}
memset(&pea, 0, sizeof(struct perf_event_attr));
pea.type = PERF_TYPE_SOFTWARE;
pea.size = sizeof(struct perf_event_attr);
pea.config = PERF_COUNT_SW_CPU_CLOCK;
pea.disabled = 1;
pea.exclude_kernel = 1;
pea.exclude_hv = 0;
pea.sample_period = 1;
pea.precise_ip = 3;
pea.sample_type = PERF_SAMPLE_IP | PERF_SAMPLE_STACK_USER;
// pea.sample_type = PERF_SAMPLE_IP;
pea.sample_stack_user = 10000;
fd1 = syscall(__NR_perf_event_open, &pea, 0, -1, -1, 0);
printf("size of perf_event_mmap_page struct is %d\n", sizeof(struct perf_event_mmap_page));
int page_size = (int) sysconf(_SC_PAGESIZE);
printf("page size in general is: %d\n", page_size);
// Map the ring buffer into memory
struct perf_event_mmap_page *pages = mmap(NULL, page_size * NUM_MMAP_PAGES, PROT_READ
| PROT_WRITE, MAP_SHARED, fd1, 0);
if (pages == MAP_FAILED) {
perror("Error mapping ring buffer");
return 1;
}
ioctl(fd1, PERF_EVENT_IOC_RESET, PERF_IOC_FLAG_GROUP);
ioctl(fd1, PERF_EVENT_IOC_ENABLE, PERF_IOC_FLAG_GROUP);
// do_something();
// fib(40);
size_t n = sizeof(some_nums)/sizeof(some_nums[0]);
insertion_sort(&some_nums, n);
ioctl(fd1, PERF_EVENT_IOC_DISABLE, PERF_IOC_FLAG_GROUP);
printf("head of perf ring buffer is at: %d", pages->data_head);
process_ring_buffer_events(pages, page_size);
munmap(pages, page_size * NUM_MMAP_PAGES);
return 0;
}
本文来自博客园,作者:dolinux,未经同意,禁止转载

