perf_event_open 学习 —— 通过read的方式读取硬件技术器
示例程序1
刚刚入职的时候我就研究了perf_event_open()这个巨无霸级别的系统调用,还用Python封装了一层,非常便于获取计数器。然而之后由于工作上一直直接用perf命令来获取各种计数器的值,于是就有所淡忘。又后来自己的笔记本重装,代码也不见了。最近由于需要开发一款略有复杂性的工具,对性能要求很高,而且需要能够实时查询结果,所以必须使用C的接口自己开发,而不能再使用命令行。
其实关于perf_event_open()这个系统调用的一切用法,在官方手册《perf_event_open(2) - Linux manual page》上都有所涉及,虽然未提及有些编程的细节。
大致上讲,perf_event_open()有两个使用模式,一个叫做计数,一个叫做采样。所谓计数,就是测量一段时间内某个事件发生的次数,比如获取每1秒内运行的指令数。所谓采样,就是在某个时间点查看某个状态,比如我想每1秒记录下当前的IP寄存器的值。从编程的角度看,计数模式要容易理解地多,也容易实现地多。所以这篇博客先讲怎么使用perf的计数模式。
最简单的计数模式就是只监测一个计数器。比如我每一秒获取刚刚过去的那一秒内的指令数(instructions)。复杂的计数模式就是同时监测多个计数器。比如我每一秒获取刚刚过去的那一秒内的指令数(instructions)、时钟周期数(cycles)、分支指令数(branch instructions)等等。接下来就先讲单一计数器模式,而后讲多计数器模式。
单计数器
=阶段一:单计数器=
就以刚刚的例子作为需求,我们要每一秒输出刚刚一秒内运行的指令数。那么代码是这样的:
single.c
#include <stdio.h>
#include <string.h>
#include <stdint.h>
#include <unistd.h>
#include <sys/syscall.h>
#include <linux/perf_event.h>
//目前perf_event_open在glibc中没有封装,需要手工封装一下
int perf_event_open(struct perf_event_attr *attr,pid_t pid,int cpu,int group_fd,unsigned long flags)
{
return syscall(__NR_perf_event_open,attr,pid,cpu,group_fd,flags);
}
int main()
{
struct perf_event_attr attr;
memset(&attr,0,sizeof(struct perf_event_attr));
attr.size=sizeof(struct perf_event_attr);
//监测硬件
attr.type=PERF_TYPE_HARDWARE;
//监测指令数
attr.config=PERF_COUNT_HW_INSTRUCTIONS;
//初始状态为禁用
attr.disabled=1;
//创建perf文件描述符,其中pid=0,cpu=-1表示监测当前进程,不论运行在那个cpu上
int fd=perf_event_open(&attr,0,-1,-1,0);
if(fd<0)
{
perror("Cannot open perf fd!");
return 1;
}
//启用(开始计数)
ioctl(fd,PERF_EVENT_IOC_ENABLE,0);
while(1)
{
uint64_t instructions;
//读取最新的计数值
read(fd,&instructions,sizeof(instructions));
printf("instructions=%ld\n",instructions);
sleep(1);
}
}
不需要任何的编译选项,直接gcc,然后运行:
gcc single.c -o single
sudo ./single
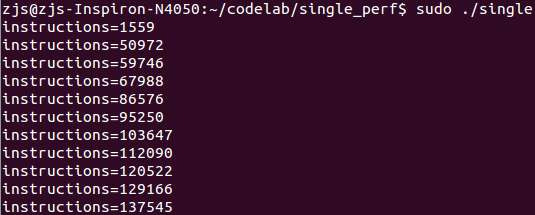
可以看到指令数不断增加。其实这个增速非常缓慢,因为循环里面除了printf什么事都没干。这个指令数是perf始能之后的累积值。那么如果想要获取每一秒内的指令数呢?一种办法就是自己在应用层计算前后两次的差分,另一种办法是告诉kernel把计数器清零:
#include <stdio.h>
#include <string.h>
#include <stdint.h>
#include <unistd.h>
#include <sys/syscall.h>
#include <linux/perf_event.h>
//目前perf_event_open在glibc中没有封装,需要手工封装一下
int perf_event_open(struct perf_event_attr *attr,pid_t pid,int cpu,int group_fd,unsigned long flags)
{
return syscall(__NR_perf_event_open,attr,pid,cpu,group_fd,flags);
}
int main()
{
struct perf_event_attr attr;
memset(&attr,0,sizeof(struct perf_event_attr));
attr.size=sizeof(struct perf_event_attr);
//监测硬件
attr.type=PERF_TYPE_HARDWARE;
//监测指令数
attr.config=PERF_COUNT_HW_INSTRUCTIONS;
//初始状态为禁用
attr.disabled=1;
//创建perf文件描述符,其中pid=0,cpu=-1表示监测当前进程,不论运行在那个cpu上
int fd=perf_event_open(&attr,0,-1,-1,0);
if(fd<0)
{
perror("Cannot open perf fd!");
return 1;
}
//启用(开始计数)
ioctl(fd,PERF_EVENT_IOC_ENABLE,0);
while(1)
{
uint64_t instructions;
//读取最新的计数值
read(fd,&instructions,sizeof(instructions));
//读取后清零
ioctl(fd,PERF_EVENT_IOC_RESET,0);
printf("instructions=%ld\n",instructions);
sleep(1);
}
}
每个计数器本身是有很多选项的,比如可以指定监测的进程号(pid)、cpu号,也可以设置只监测用户态的事件,或只监测内核态的事件等等,具体可以查看手册。另外,计数器可以监测的事件也有很多,有硬件的,有软件的。这里截取了手册上一些常用的:


多计数器
===阶段二:多计数器
如果你说多个计数器简单,创建多个perf文件描述符,然后每个都用read去读嘛。额,确实可以!但是呢,当监测的事件很多,而且读取频率很高时,那么read()调用的开销就不可再忽略了。那么如果能够把多个计数器的值通过一次read()调用获取,性能上能够提高不少。perf提供了“组”的概念,这也是多计数器perf的核心内容。
读读手册的这一段:

所以呢,第一个perf fd还是和本来一样的方法创建(除了要多设置一个read_format),而后面的perf_event_open()中的参数group_fd就传入第一个perf fd。这样他们就成为了一个组,并且用第一个perf fd代表整个组。
下面代码演示了如何同时监测指令数和时钟周期数。
multi.c
#include <stdio.h>
#include <string.h>
#include <stdint.h>
#include <unistd.h>
#include <sys/syscall.h>
#include <linux/perf_event.h>
//目前perf_event_open在glibc中没有封装,需要手工封装一下
int perf_event_open(struct perf_event_attr *attr,pid_t pid,int cpu,int group_fd,unsigned long flags)
{
return syscall(__NR_perf_event_open,attr,pid,cpu,group_fd,flags);
}
//每次read()得到的结构体
struct read_format
{
//计数器数量(为2)
uint64_t nr;
//两个计数器的值
uint64_t values[2];
};
int main()
{
struct perf_event_attr attr;
memset(&attr,0,sizeof(struct perf_event_attr));
attr.size=sizeof(struct perf_event_attr);
//监测硬件
attr.type=PERF_TYPE_HARDWARE;
//监测指令数
attr.config=PERF_COUNT_HW_INSTRUCTIONS;
//初始状态为禁用
attr.disabled=1;
//每次读取一个组
attr.read_format=PERF_FORMAT_GROUP;
//创建perf文件描述符,其中pid=0,cpu=-1表示监测当前进程,不论运行在那个cpu上
int fd=perf_event_open(&attr,0,-1,-1,0);
if(fd<0)
{
perror("Cannot open perf fd!");
return 1;
}
//接下来创建第二个计数器
memset(&attr,0,sizeof(struct perf_event_attr));
attr.size=sizeof(struct perf_event_attr);
//监测
attr.type=PERF_TYPE_HARDWARE;
//监测时钟周期数
attr.config=PERF_COUNT_HW_CPU_CYCLES;
//初始状态为禁用
attr.disabled=1;
//创建perf文件描述符
int fd2=perf_event_open(&attr,0,-1,fd,0);
if(fd2<0)
{
perror("Cannot open perf fd2!");
return 1;
}
//启用(开始计数),注意PERF_IOC_FLAG_GROUP标志
ioctl(fd,PERF_EVENT_IOC_ENABLE,PERF_IOC_FLAG_GROUP);
while(1)
{
struct read_format aread;
//读取最新的计数值,每次读取一个结构体
read(fd,&aread,sizeof(struct read_format));
printf("instructions=%ld,cycles=%ld\n",aread.values[0],aread.values[1]);
sleep(1);
}
}
可以注意到,最大的变化就是数据的读取。当使用了“组”的形式之后,那么每次read()就是读取一个特定的结构体。这个结构体struct read_format不是固定的,会根据组内计数器数量和struct perf_event_attr的read_format字段的设置而变化。上面的代码用了最简单的方法,把struct perf_event_attr的read_format设置为PERF_FORMAT_GROUP,那么每次读取的结构体其实就是1+nr个64位整数,其中第一个整数nr就是计数器数量,后面nr个整数就是每一个计数器的值,顺序和加入组的顺序相同。
第二大变化就是ioctl()的第三个参数由0变为了PERF_IOC_FLAG_GROUP。这个标志表明操作是对组进行的,可以理解为kernel帮我们把ioctl依次作用在了组的每一个计数器上。所以呢,如果每次读取后,要把组内所有计数器都清空,需要使用:
ioctl(fd,PERF_EVENT_IOC_RESET,PERF_IOC_FLAG_GROUP);
示例程序2
The perf_event_open Linux system call can be used to read hardware counters. In this section, two examples are provided. The first example shows how to read a single counter, the second example shows how to read a group of counters without multiplexing. perf_event_open does not support multiplexing.
Configure a single counter
The example below shows how to use the perf_event_open system call to read a single counter.
Use a text editor to create a file named perf_event_example1.c and paste the code below into the file:
#include <linux/perf_event.h> /* Definition of PERF_* constants */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/ioctl.h>
#include <sys/syscall.h> /* Definition of SYS_* constants */
#include <unistd.h>
#include <inttypes.h>
// The function to counting through (called in main)
void code_to_measure(){
int sum = 0;
for(int i = 0; i < 1000000000; ++i){
sum += 1;
}
}
// Executes perf_event_open syscall and makes sure it is succesful or exit
static long perf_event_open(struct perf_event_attr *hw_event, pid_t pid, int cpu, int group_fd, unsigned long flags){
int fd;
fd = syscall(SYS_perf_event_open, hw_event, pid, cpu, group_fd, flags);
if (fd == -1) {
fprintf(stderr, "Error creating event");
exit(EXIT_FAILURE);
}
return fd;
}
int main() {
int fd;
uint64_t val;
struct perf_event_attr pe;
// Configure the event to count
memset(&pe, 0, sizeof(struct perf_event_attr));
pe.type = PERF_TYPE_HARDWARE;
pe.size = sizeof(struct perf_event_attr);
pe.config = PERF_COUNT_HW_INSTRUCTIONS;
pe.disabled = 1;
pe.exclude_kernel = 1; // Do not measure instructions executed in the kernel
pe.exclude_hv = 1; // Do not measure instructions executed in a hypervisor
// Create the event
fd = perf_event_open(&pe, 0, -1, -1, 0);
//Reset counters and start counting
ioctl(fd, PERF_EVENT_IOC_RESET, 0);
ioctl(fd, PERF_EVENT_IOC_ENABLE, 0);
// Example code to count through
code_to_measure();
// Stop counting
ioctl(fd, PERF_EVENT_IOC_DISABLE, 0);
// Read and print result
read(fd, &val, sizeof(val));
printf("Instructions retired: %"PRIu64"\n", val);
// Clean up file descriptor
close(fd);
return 0;
}
The example counts the number of instructions executed in the code_to_measure function.
Just as with PAPI, the counter is started right before the call to code_to_measure and the counter is stopped and read just after the call to code_to_measure.
The event being counted is PERF_COUNT_HW_INSTRUCTIONS which maps to the Arm PMU INST_RETIRED (ID: 0x08) event.
The perf_event_open documentation lists the preset events that can be used.
It is also possible to use a raw event code if a preset doesn’t exist. The data structure perf_event_attr is how the event to count is configured. This data structure has numerous fields. In the example above, the data structure is setup so that instructions executed in the kernel (or Arm exception level EL1) and instructions executed in the hypervisor (or Arm exception level EL2) are not counted. This means the example is only counting user space instructions executed (or Arm exception level EL0).
You can review the manual page to understand the configuration options for event counting.
Compile the example using the GNU compiler:
gcc perf_event_example1.c -o perf_event_example1
Run the application as root (or using sudo):
sudo ./perf_event_example1
The output will be similar to:

Your counter value may be different from what is shown above. There are many variables that change the count including the CPU design and the compiler.
Configure multiple counters (no multiplexing)
Counting a group of events makes it possible to calculate ratios like Instructions Per Cycle (IPC). Below is an example of counting multiple events.
Use a text editor to create a file named perf_event_example2.c and paste the code below into the file:
#include <linux/perf_event.h> /* Definition of PERF_* constants */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/ioctl.h>
#include <sys/syscall.h> /* Definition of SYS_* constants */
#include <unistd.h>
#include <inttypes.h>
#define TOTAL_EVENTS 6
// The function to counting through (called in main)
void code_to_measure(){
int sum = 0;
for(int i = 0; i < 1000000000; ++i){
sum += 1;
}
}
// Executes perf_event_open syscall and makes sure it is succesful or exit
static long perf_event_open(struct perf_event_attr *hw_event, pid_t pid, int cpu, int group_fd, unsigned long flags){
int fd;
fd = syscall(SYS_perf_event_open, hw_event, pid, cpu, group_fd, flags);
if (fd == -1) {
fprintf(stderr, "Error creating event");
exit(EXIT_FAILURE);
}
return fd;
}
// Helper function to setup a perf event structure (perf_event_attr; see man perf_open_event)
void configure_event(struct perf_event_attr *pe, uint32_t type, uint64_t config){
memset(pe, 0, sizeof(struct perf_event_attr));
pe->type = type;
pe->size = sizeof(struct perf_event_attr);
pe->config = config;
pe->read_format = PERF_FORMAT_GROUP | PERF_FORMAT_ID;
pe->disabled = 1;
pe->exclude_kernel = 1;
pe->exclude_hv = 1;
}
// Format of event data to read
// Note: This format changes depending on perf_event_attr.read_format
// See `man perf_event_open` to understand how this structure can be different depending on event config
// This read_format structure corresponds to when PERF_FORMAT_GROUP & PERF_FORMAT_ID are set
struct read_format {
uint64_t nr;
struct {
uint64_t value;
uint64_t id;
} values[TOTAL_EVENTS];
};
int main() {
int fd[TOTAL_EVENTS]; // fd[0] will be the group leader file descriptor
int id[TOTAL_EVENTS]; // event ids for file descriptors
uint64_t pe_val[TOTAL_EVENTS]; // Counter value array corresponding to fd/id array.
struct perf_event_attr pe[TOTAL_EVENTS]; // Configuration structure for perf events (see man perf_event_open)
struct read_format counter_results;
// Configure the group of PMUs to count
configure_event(&pe[0], PERF_TYPE_HARDWARE, PERF_COUNT_HW_CPU_CYCLES);
configure_event(&pe[1], PERF_TYPE_HARDWARE, PERF_COUNT_HW_INSTRUCTIONS);
configure_event(&pe[2], PERF_TYPE_HARDWARE, PERF_COUNT_HW_STALLED_CYCLES_FRONTEND);
configure_event(&pe[3], PERF_TYPE_HARDWARE, PERF_COUNT_HW_STALLED_CYCLES_BACKEND);
configure_event(&pe[4], PERF_TYPE_RAW, 0x70); // Count of speculative loads (see Arm PMU docs)
configure_event(&pe[5], PERF_TYPE_RAW, 0x71); // Count of speculative stores (see Arm PMU docs)
// Create event group leader
fd[0] = perf_event_open(&pe[0], 0, -1, -1, 0);
ioctl(fd[0], PERF_EVENT_IOC_ID, &id[0]);
// Let's create the rest of the events while using fd[0] as the group leader
for(int i = 1; i < TOTAL_EVENTS; i++){
fd[i] = perf_event_open(&pe[i], 0, -1, fd[0], 0);
ioctl(fd[i], PERF_EVENT_IOC_ID, &id[i]);
}
// Reset counters and start counting; Since fd[0] is leader, this resets and enables all counters
// PERF_IOC_FLAG_GROUP required for the ioctl to act on the group of file descriptors
ioctl(fd[0], PERF_EVENT_IOC_RESET, PERF_IOC_FLAG_GROUP);
ioctl(fd[0], PERF_EVENT_IOC_ENABLE, PERF_IOC_FLAG_GROUP);
// Example code to count through
code_to_measure();
// Stop all counters
ioctl(fd[0], PERF_EVENT_IOC_DISABLE, PERF_IOC_FLAG_GROUP);
// Read the group of counters and print result
read(fd[0], &counter_results, sizeof(struct read_format));
printf("Num events captured: %"PRIu64"\n", counter_results.nr);
for(int i = 0; i < counter_results.nr; i++) {
for(int j = 0; j < TOTAL_EVENTS ;j++){
if(counter_results.values[i].id == id[j]){
pe_val[i] = counter_results.values[i].value;
}
}
}
printf("CPU cycles: %"PRIu64"\n", pe_val[0]);
printf("Instructions retired: %"PRIu64"\n", pe_val[1]);
printf("Frontend stall cycles: %"PRIu64"\n", pe_val[2]);
printf("Backend stall cycles: %"PRIu64"\n", pe_val[3]);
printf("Loads executed speculatively: %"PRIu64"\n", pe_val[4]);
printf("Stores executed speculatively: %"PRIu64"\n", pe_val[5]);
// Close counter file descriptors
for(int i = 0; i < TOTAL_EVENTS; i++){
close(fd[i]);
}
return 0;
}
Near the top of the code there is a data structure called read_format. It is setup to contain TOTAL_EVENTS (6 in this case) of an inner structure called values. This structure is populated when the group of 6 counters is read.
- Note1
The read_format structure can take different forms depending on how the perf_event_attr structure is configured. Refer to the man page for more information.
In addition to read_format, there is also the perf_event_attr structure which allows configuration of each of the 6 events. This is why the perf_event_attr structure array called pe is a size of TOTAL_EVENTS (or 6 in this case). This means there is 1 perf_event_attr structure per event to count.
- Note2
It is possible to reuse one perf_event_attr structure for setting up all events but this is not done here.
The events to count are configured using the configure_event function. In this example, there are 6 events to count, 4 are the preset events of PERF_COUNT_HW_CPU_CYCLES, PERF_COUNT_HW_INSTRUCTIONS, PERF_COUNT_HW_STALLED_CYCLES_FRONTEND and PERF_COUNT_HW_STALLED_CYCLES_BACKEND.
The last two are raw events 0x70 and 0x71 which correspond to loads executed speculatively (LD_SPEC) and stores executed speculatively (ST_SPEC).
Remember that these event codes (0x70 and 0x71) can be found in the TRM for the CPU.
These last two events are examples of how an event that might not have a preset can be counted. Of these 6 events, one needs to be selected as the group leader. When this is done, whenever an action on the group leader is taken (such as start counting), that action is taken on all of the counters in the group.
The last thing that is different in this example is the ioctl calls that reset, start and stop the group of counters. There is an additional flag called PERF_IOC_FLAG_GROUP. This is required to trigger the entire group to count. If this is missing then only the group leader will be counted.
Compile the example using the GNU compiler:
gcc perf_event_example2.c -o perf_event_example2
Run the application as root (or using sudo):
sudo ./perf_event_example2
The output will be similar to:
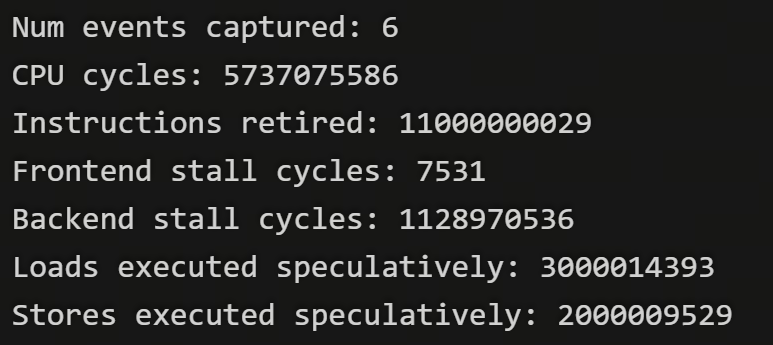
Your counter values may be different from the output above.
If you want to measure more counters than is supported by the CPU, you will need to implement multiplexing yourself.
If you choose to do this, be sure to set the PERF_FORMAT_TOTAL_TIME_ENABLED and PERF_FORMAT_TOTAL_TIME_RUNNING fields in the perf_event_attr.read_format structure. This is done by ORing these flags into the same line you see PERF_FORMAT_GROUP and PERF_FORMAT_ID above. If this is done, the read_format structure will need to be changed to include the time enabled and time running fields. If this multiplexing is implemented, the resulting counts should be taken as an estimate.
本文来自博客园,作者:dolinux,未经同意,禁止转载

