运行时锁定正确性验证器 【ChatGPT】
锁类
该验证器操作的基本对象是“锁”的“类”。
“锁”的“类”是一组逻辑上相同的锁,即使这些锁可能有多个(可能有成千上万个)实例化。例如,inode结构中的锁是一个类,而每个inode都有自己的该锁类的实例化。
验证器跟踪锁类的“使用状态”,并跟踪不同锁类之间的依赖关系。锁的使用状态指示锁在IRQ上下文中的使用方式,而锁的依赖关系可以理解为锁的顺序,其中L1 -> L2表示任务在持有L1的同时尝试获取L2。从lockdep的角度来看,这两个锁(L1和L2)不一定相关;这种依赖只是表示顺序曾经发生过。验证器不断努力证明锁的使用和依赖关系是正确的,否则验证器将在不正确时发出警告。
锁类的行为是由其实例共同构成的:当锁类的第一个实例在启动后被使用时,该类被注册,然后所有(随后的)实例将被映射到该类,因此它们的使用和依赖将有助于该类的使用和依赖。锁类不会在锁实例消失时消失,但如果锁类的内存空间(静态或动态)被回收,它可以被移除,例如当模块被卸载或工作队列被销毁时。
STATE
验证器跟踪锁类的使用历史,并将使用分为(4个使用 * n个STATE + 1)类别:
其中4个使用可以是:
- '在STATE上曾经持有'
- '在STATE上曾经以读锁持有'
- '在启用STATE下曾经持有'
- '在启用STATE下曾经以读锁持有'
n个STATE编码在kernel/locking/lockdep_states.h中,目前包括:
- hardirq
- softirq
最后1个类别是:
- '曾经使用' [ == !未使用 ]
当违反锁定规则时,这些使用位将显示在锁定错误消息中,用大括号括起来,共有2 * n个STATE位。一个人为的例子:
modprobe/2287 正在尝试获取锁:
(&sio_locks[i].lock){-.-.}, at: [<c02867fd>] mutex_lock+0x21/0x24
但任务已经持有锁:
(&sio_locks[i].lock){-.-.}, at: [<c02867fd>] mutex_lock+0x21/0x24
对于给定的锁,从左到右的位位置指示了锁和读锁(如果存在)在上述每个n个STATE中的使用情况,每个位位置显示的字符表示:
- '.': 在禁用IRQ且不在IRQ上下文中获取
- '-': 在IRQ上下文中获取
- '+': 在启用IRQ的情况下获取
- '?': 在启用IRQ的情况下在IRQ上下文中获取
示例:
(&sio_locks[i].lock){-.-.}, at: [<c02867fd>] mutex_lock+0x21/0x24
||||
||| \-> softirq disabled and not in softirq context
|| \--> acquired in softirq context
| \---> hardirq disabled and not in hardirq context
\----> acquired in hardirq context
对于给定的状态,锁是否在该状态上曾经被获取以及该状态是否已启用会产生四种可能的情况,如下表所示。位字符能够指示在报告时间点上锁的确切情况。
| irq已启用 | irq已禁用 | |
|---|---|---|
| 曾在irq中 | '?' | '-' |
| 从未在irq中 | '+' | '.' |
字符'-'表示irq已禁用,因为否则将显示字符'?'。对于'+'也可以应用类似的推断。
未使用的锁(例如互斥锁)不会成为错误的原因。
单锁状态规则:
锁是irq安全的意味着它曾在irq上下文中使用,而锁是irq不安全的意味着它曾在启用irq的情况下被获取。
一个softirq不安全的锁类也自动是hardirq不安全的。以下状态必须是互斥的:对于任何锁类,基于其使用情况只允许设置其中的一个:
<hardirq安全> 或 <hardirq不安全>
<softirq安全> 或 <softirq不安全>
这是因为如果一个锁可以在irq上下文中使用(irq安全),那么它就不能在启用irq的情况下被获取(irq不安全)。否则,可能会发生死锁。例如,在获取此锁后但在释放之前,如果上下文被中断,这个锁将被尝试获取两次,这会导致死锁,称为锁递归死锁。
验证器检测并报告违反这些单锁状态规则的锁使用。
多锁依赖规则:
同一锁类不得被获取两次,因为这可能导致锁递归死锁。
此外,两个锁不得以相反的顺序获取:
<L1> -> <L2>
<L2> -> <L1>
因为这可能导致死锁,称为锁倒置死锁,尝试获取这两个锁形成一个循环,这可能导致两个上下文永久等待对方。验证器将在任意复杂度中找到这样的依赖循环,即在获取锁的操作之间可能存在任何其他锁定序列;验证器仍然会找出这些锁是否可以以循环方式获取。
此外,以下基于使用的锁依赖关系在任何两个锁类之间都是不允许的:
<hardirq安全> -> <hardirq不安全>
<softirq安全> -> <softirq不安全>
第一个规则来自于这样一个事实:一个hardirq安全的锁可以被hardirq上下文获取,中断一个hardirq不安全的锁,因此可能导致锁倒置死锁。同样,一个softirq安全的锁可以被softirq上下文获取,中断一个softirq不安全的锁。
以上规则适用于内核中发生的任何锁定序列:在获取新锁时,验证器会检查新锁与任何已持有锁之间是否存在违反规则的情况。
当锁类改变其状态时,上述依赖规则的以下方面将被强制执行:
- 如果发现一个新的hardirq安全锁,我们将检查它是否在过去获取过任何hardirq不安全的锁。
- 如果发现一个新的softirq安全锁,我们将检查它是否在过去获取过任何softirq不安全的锁。
- 如果发现一个新的hardirq不安全锁,我们将检查是否有任何hardirq安全锁在过去获取过它。
- 如果发现一个新的softirq不安全锁,我们将检查是否有任何softirq安全锁在过去获取过它。
(同样,我们也会在这些检查中假设中断上下文可能中断任何irq不安全或hardirq不安全的锁,这可能导致锁倒置死锁,即使该锁情景在实践中尚未触发。)
例外:导致嵌套锁定的嵌套数据依赖
在一些情况下,Linux内核会获取同一锁类的多个实例。这种情况通常发生在同一类型的对象中存在某种层次结构时。在这些情况下,两个对象之间存在固有的“自然”顺序(由层次结构的属性定义),内核在每个对象上以固定的顺序获取锁。
导致“嵌套锁定”的对象层次结构的一个例子是“整个磁盘”块设备对象和“分区”块设备对象;分区是整个设备的一部分,只要始终将整个磁盘锁作为高级锁获取分区锁,锁定顺序就是完全正确的。验证器不会自动检测到这种自然顺序,因为顺序背后的锁定规则是不固定的。
为了向验证器介绍这种正确的使用模型,添加了各种锁定原语的新版本,允许您指定“嵌套级别”。例如,对于块设备互斥锁的调用如下所示:
enum bdev_bd_mutex_lock_class
{
BD_MUTEX_NORMAL,
BD_MUTEX_WHOLE,
BD_MUTEX_PARTITION
};
mutex_lock_nested(&bdev->bd_contains->bd_mutex, BD_MUTEX_PARTITION);
在这种情况下,对已知是分区的bdev对象进行锁定。验证器将以嵌套方式获取的锁视为验证目的的一个单独(子)类。
注意:在更改代码以使用_nested()原语时,务必小心并仔细检查层次结构是否正确映射;否则可能会出现错误的阳性或阴性结果。
注释
有两种结构可用于注释和检查是否必须持有某些锁:lockdep_assert_held*(&lock) 和 lockdep_*pin_lock(&lock)。
顾名思义,lockdep_assert_held*宏系列断言在某个时间点持有特定锁(否则会生成WARN())。这种注释在整个内核中广泛使用,例如kernel/sched/core.c:
void update_rq_clock(struct rq *rq)
{
s64 delta;
lockdep_assert_held(&rq->lock);
[...]
}
在这里,持有rq->lock是安全地更新rq的时钟所必需的。
另一组宏是lockdep_*pin_lock(),目前只用于rq->lock。尽管这些注释的采用范围有限,但如果感兴趣的锁“意外”解锁,这些注释会生成WARN()。这对于具有回调代码的调试非常有帮助,其中一个上层层次认为锁仍然被持有,而下层层次认为它可能会释放并重新获取锁(“无意”引入竞争)。lockdep_pin_lock()返回一个“struct pin_cookie”,然后lockdep_unpin_lock()使用它来检查没有人篡改锁,例如kernel/sched/sched.h:
static inline void rq_pin_lock(struct rq *rq, struct rq_flags *rf)
{
rf->cookie = lockdep_pin_lock(&rq->lock);
[...]
}
static inline void rq_unpin_lock(struct rq *rq, struct rq_flags *rf)
{
[...]
lockdep_unpin_lock(&rq->lock, rf->cookie);
}
尽管关于锁定要求的注释可能提供有用的信息,但注释执行的运行时检查在调试锁定问题时是非常宝贵的,并且在检查代码时具有相同的详细信息级别。在怀疑时,始终优先使用注释!
100%正确性的证明
验证器在数学上实现了完美的“闭合”(锁定正确性的证明),对于内核生命周期中至少发生一次的每个简单的、独立的单任务锁定序列,验证器都能以100%的确定性证明,这些锁定序列的任何组合和时机都不会导致任何锁相关的死锁1。
即使复杂的多CPU和多任务锁定场景在实践中不必发生,也可以证明死锁:只需至少一次触发“简单”单任务锁定依赖即可(在任何时间、在任何任务/上下文中),验证器就能够证明正确性。(例如,通常需要超过3个CPU和非常不太可能的任务、irq上下文和时机组合才能发生的复杂死锁,在普通、轻负载的单CPU系统上也可以检测到!)
这极大地简化了内核锁定相关的质量保证工作:在质量保证期间需要做的是尽可能触发内核中尽可能多的“简单”单任务锁定依赖,至少一次,以证明锁定正确性 - 而不是必须触发每个可能的CPU之间的所有可能的锁定交互组合,再加上每种可能的hardirq和softirq嵌套场景(这在实践中是不可能的)。
性能:
上述规则需要大量的运行时检查。如果我们对每个锁的获取和每个irqs-enable事件都进行检查,那么系统几乎无法使用,因为检查的复杂度是O(N^2),所以即使只有几百个锁类,我们每个事件都需要进行数万次的检查。
这个问题通过仅对任何给定的“锁定场景”(相继获取的唯一锁序列)进行一次检查来解决。维护一个简单的持有锁的堆栈,并计算一个轻量级的64位哈希值,该哈希对于每个锁链是唯一的。当第一次验证链时,哈希值被放入哈希表中,该哈希表可以以无锁的方式进行检查。如果以后再次出现锁链,哈希表会告诉我们不需要再次验证该链。
故障排除:
验证器跟踪最多MAX_LOCKDEP_KEYS个锁类。超过这个数字将触发以下lockdep警告:
(DEBUG_LOCKS_WARN_ON(id >= MAX_LOCKDEP_KEYS))
默认情况下,MAX_LOCKDEP_KEYS目前设置为8191,典型的桌面系统锁类少于1000个,因此这个警告通常是由于锁类泄漏或未正确初始化锁引起的。以下两个问题进行了说明:
-
在运行验证器时重复加载和卸载模块会导致锁类泄漏。问题在于每次加载模块都会为该模块的锁创建一组新的锁类,但卸载模块不会删除旧的类(请参见下面关于为什么重用锁类的讨论)。因此,如果该模块反复加载和卸载,锁类的数量最终会达到最大值。
-
使用诸如数组之类的结构,其中包含大量未显式初始化的锁。例如,一个具有8192个桶的哈希表,其中每个桶都有自己的spinlock_t,将消耗8192个锁类,除非每个自旋锁在运行时显式初始化,例如使用run-time spin_lock_init(),而不是使用编译时初始化器,如__SPIN_LOCK_UNLOCKED()。未正确初始化每个桶的自旋锁将导致锁类溢出。相比之下,调用spin_lock_init()对每个锁的循环将把所有8192个锁放入单个锁类中。
这个故事的寓意是,你应该始终显式初始化你的锁。
有人可能会认为验证器应该被修改以允许锁类的重用。然而,如果你有这种想法,首先审查代码并仔细考虑所需的更改,要记住要删除的锁类可能已经链接到锁依赖图中。这样做比说起来更难。
当然,如果你的锁类用完了,下一步要做的就是找到有问题的锁类。首先,以下命令可以给出当前使用的锁类数量以及最大值:
grep "lock-classes" /proc/lockdep_stats
这个命令在一台普通系统上产生以下输出:
lock-classes: 748 [max: 8191]
如果分配的数量(上面的748)随着时间的推移不断增加,那么很可能存在泄漏。以下命令可用于识别泄漏的锁类:
grep "BD" /proc/lockdep
运行该命令并保存输出,然后与稍后运行该命令的输出进行比较,以识别泄漏者。这个输出也可以帮助你找到遗漏运行时锁初始化的情况。
递归读锁:
整个文档的其余部分试图证明某种类型的循环等价于死锁可能性。
有三种类型的锁定器:写入者(即独占锁定器,如spin_lock()或write_lock())、非递归读取者(即共享锁定器,如down_read())和递归读取者(递归共享锁定器,如rcu_read_lock())。在文档的其余部分,我们使用这些锁定器的以下符号:
- W或E:代表写入者(独占锁定器)。r:代表非递归读取者。R:代表递归读取者。S:代表所有读取者(非递归+递归),因为两者都是共享锁定器。N:代表写入者和非递归读取者,因为两者都不是递归的。
显然,N是“r或W”,S是“r或R”。
递归读取者,正如其名称所示,是允许在另一个相同锁实例的读取者的临界区内获取锁的锁定器,换句话说,允许同一锁实例的嵌套读取端临界区。
而非递归读取者在尝试在另一个相同锁实例的读取者的临界区内获取锁时会导致自死锁。
递归读取者和非递归读取者之间的区别在于:递归读取者只会被当前的写入锁持有者阻塞,而非递归读取者可能会被写入锁的等待者阻塞。考虑以下例子:
任务A: 任务B:
read_lock(X);
write_lock(X);
read_lock_2(X);
任务A通过read_lock()首先在X上获取读取者(无论是递归的还是非递归的)。当任务B尝试在X上获取写入者时,它将被阻塞并成为X的写入者的等待者。现在如果read_lock_2()是递归读取者,任务A将会取得进展,因为写入者的等待者不会阻塞递归读取者,因此不会发生死锁。然而,如果read_lock_2()是非递归读取者,它将被写入者的等待者B阻塞,并导致自死锁。
相同锁实例的读取者/写入者的阻塞条件:
简单来说,有四种阻塞条件:
-
写入者阻塞其他写入者。
-
读取者阻塞写入者。
-
写入者阻塞递归读取者和非递归读取者。
-
读取者(递归或非递归)不会阻塞其他递归读取者,但可能会阻塞非递归读取者(因为可能存在共存的写入者等待者)
阻塞条件矩阵,Y表示行阻塞列,N表示相反。
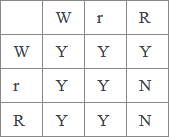
(W:写入者,r:非递归读取者,R:递归读取者)
递归读锁不会被递归地获取。与非递归读锁不同,递归读锁只会被当前写入锁持有者阻塞,而不会被写入锁的等待者阻塞,例如:
任务A: 任务B:
read_lock(X);
write_lock(X);
read_lock(X);
对于递归读锁来说,上述情况不会导致死锁,因为当任务B等待锁X时,第二个read_lock()不需要等待,因为它是递归读锁。然而,如果read_lock()是非递归读锁,那么上述情况就会导致死锁,因为即使任务B无法获取锁,但它可以阻塞任务A中的第二个read_lock()。
请注意,一个锁可以是写锁(独占锁)、非递归读锁(非递归共享锁)或递归读锁(递归共享锁),具体取决于用于获取它的锁操作(更具体地说,是lock_acquire()的“read”参数的值)。换句话说,单个锁实例具有三种不同的获取方式:独占、非递归读和递归读。
简而言之,我们将写锁和非递归读锁称为“非递归”锁,将递归读锁称为“递归”锁。
递归锁不会相互阻塞,而非递归锁会(即使是两个非递归读锁也是如此)。非递归锁可以阻塞相应的递归锁,反之亦然。
涉及递归锁的死锁案例如下:
任务A: 任务B:
read_lock(X);
read_lock(Y);
write_lock(Y);
write_lock(X);
任务A正在等待任务B对Y进行read_unlock(),而任务B正在等待任务A对X进行read_unlock()。
依赖类型和强依赖路径:
锁依赖记录了一对锁的获取顺序,由于有3种类型的锁,理论上有9种锁依赖类型,但我们可以证明只有4种锁依赖类型足以用于死锁检测。
对于每种锁依赖:
L1 -> L2
这意味着在运行时,lockdep看到了L1在同一上下文中先于L2被持有。在死锁检测中,我们关心的是当L1被持有时是否会被L2阻塞,换句话说,是否存在一个锁L3,L1阻塞L3并且L2被L3阻塞。因此,我们只关心1)L1阻塞了什么以及2)什么阻塞了L2。因此,我们可以将递归读者和非递归读者合并为L1(因为它们阻塞相同类型),并且我们可以将写者和非递归读者合并为L2(因为它们被相同类型阻塞)。
通过上述简化组合,锁依赖图中有4种依赖边的类型:
-
-(ER)->:
独占写者到递归读者的依赖,"X -(ER)-> Y"表示X -> Y,X是写者,Y是递归读者。 -
-(EN)->:
独占写者到非递归锁的依赖,"X -(EN)-> Y"表示X -> Y,X是写者,Y要么是写者要么是非递归读者。 -
-(SR)->:
共享读者到递归读者的依赖,"X -(SR)-> Y"表示X -> Y,X是读者(递归或非递归),Y是递归读者。 -
-(SN)->:
共享读者到非递归锁的依赖,"X -(SN)-> Y"表示X -> Y,X是读者(递归或非递归),Y要么是写者要么是非递归读者。
需要注意的是,给定两个锁,它们之间可能存在多个依赖关系,例如:
任务A:
read_lock(X);
write_lock(Y);
...
任务B:
write_lock(X);
write_lock(Y);
在依赖图中,我们既有X -(SN)-> Y,又有X -(EN)-> Y。
我们使用-(xN)->表示既是-(EN)->又是-(SN)->的边,对于-(Ex)->、-(xR)->和-(Sx)->同理。
“路径”是图中一系列连接的依赖边。我们定义“强”路径,表示路径中每个依赖都是强依赖,即路径中不存在两个相邻的依赖边是-(xR)->和-(Sx)->。换句话说,“强”路径是指通过锁依赖从一个锁到另一个锁的路径,如果路径中存在X -> Y -> Z(其中X、Y、Z是锁),并且从X到Y的路径是通过-(SR)->或-(ER)->依赖,那么从Y到Z的路径就不能是通过-(SN)->或-(SR)->依赖。
我们将在下一节看到为什么路径被称为“强”。
递归读者死锁检测:
我们现在证明两个结论:
引理1:
如果存在一个封闭的强路径(即强环路),那么存在一组锁定序列会导致死锁。也就是说,强环路足以用于死锁检测。
引理2:
如果不存在封闭的强路径(即强环路),那么不存在一组锁定序列会导致死锁。也就是说,强环路是死锁检测的必要条件。
有了这两个引理,我们可以轻松地说,封闭的强路径既是足够的也是必要的死锁条件,因此封闭的强路径等同于死锁可能性。由于封闭的强路径代表了可能导致死锁的依赖链,所以我们称之为“强”,考虑到存在不会导致死锁的依赖环。
充分性的证明(引理1):
假设我们有一个强环路:
L1 -> L2 ... -> Ln -> L1
这意味着我们有依赖关系:
L1 -> L2
L2 -> L3
...
Ln-1 -> Ln
Ln -> L1
我们现在可以构造一组导致死锁的锁定序列:
首先让一个CPU/任务获取L1在L1 -> L2中,然后另一个获取L2在L2 -> L3中,依此类推。这样,所有Lx在Lx -> Lx+1中都被不同的CPU/任务持有。
然后因为我们有L1 -> L2,所以持有者将在L1 -> L2中获取L2,然而由于L2已经被另一个CPU/任务持有,再加上L1 -> L2和L2 -> L3不是-(xR)->和-(Sx)->(强依赖的定义),这意味着要么L1 -> L2中的L2是非递归锁(被任何人阻塞),要么L2 -> L3中的L2是写者(阻塞任何人),因此L1的持有者无法获取L2,必须等待L2的持有者释放。
此外,我们可以得出类似的结论:L2的持有者必须等待L3的持有者释放,依此类推。我们现在可以证明Lx的持有者必须等待Lx+1的持有者释放,注意到Ln+1是L1,所以我们有一个循环等待的情景,没有人能够取得进展,因此发生了死锁。
必要性的证明(引理2):
引理2等价于:如果存在死锁情景,那么依赖图中必定存在一个强环路。
根据维基百科1,如果存在死锁,那么必定存在循环等待的情景,意味着有N个CPU/任务,其中CPU/任务P1正在等待被P2持有的锁,P2正在等待被P3持有的锁,...,Pn正在等待被P1持有的锁。让我们将Px正在等待的锁命名为Lx,因此由于P1正在等待L1并持有Ln,所以我们在依赖图中会有Ln -> L1。类似地,我们有L1 -> L2,L2 -> L3,...,Ln-1 -> Ln,这意味着我们有一个环路:
Ln -> L1 -> L2 -> ... -> Ln
现在让我们证明这个环路是强的:
对于锁Lx,Px贡献了依赖Lx-1 -> Lx,Px+1贡献了依赖Lx -> Lx+1,由于Px正在等待Px+1释放Lx,因此不可能出现Px+1上的Lx是读者且Px上的Lx是递归读者,因为读者(无论递归或非递归)不会阻塞递归读者,因此Lx-1 -> Lx和Lx -> Lx+1不可能是-(xR)-> -(Sx)->对,对于环路中的任何锁来说都是如此,因此这个环路是强的。
参考资料:
1: https://en.wikipedia.org/wiki/Deadlock [2]: Shibu, K. (2009). Intro To Embedded Systems (1st ed.). Tata McGraw-Hill
本文来自博客园,作者:摩斯电码,未经同意,禁止转载

