ftrace、perf、bcc、bpftrace、ply的使用
参考
- https://www.brendangregg.com
- Linux Performance
- https://github.com/iovisor/bcc/blob/master/docs/tutorial.md
- https://github.com/iovisor/bpftrace/blob/master/docs/reference_guide.md
- 采用了eBPF技术的项目
- Linux Performance框图
- 影响程序性能的几个关键因素
- https://blog.csdn.net/rikeyone/category_10317059.html
- linux内核调试追踪技术20讲
- Dive into BPF: a list of reading material
- perf性能分析工具使用分享
- 深入字节版atop: 线上系统的性能监控实践
- Linux tracing/profiling 基础:符号表、调用栈、perf/bpftrace 示例等(2022)
- Linux tracing systems & how they fit together
- https://jvns.ca/#linux-debugging---tracing-tools
- trace专栏
- boot time tracing 和 bootconfig
Ftrace
- 参考
- Linux内核 eBPF基础:ftrace源码分析:过滤函数和开启追踪
- Linux内核 eBPF基础:ftrace基础-ftrace_init初始化
- Linux启动时追踪
- Debugging the kernel using Ftrace - part 1
- Debugging the kernel using Ftrace - part 2
- Secrets of the Ftrace function tracer
- openEuler kernel技术分享-第13期-ftrace框架及指令修改机制
- ftrace源码实现 —— 跟踪器的实现
经典用法
function_graph
-
获取某个进程调用sys_open的调用栈
运行要trace的程序,然后在调用open之前挺住,接着执行下面的命令,最后接着执行程序echo function_graph > /sys/kernel/debug/tracing/current_tracer echo *sys_open > /sys/kernel/debug/tracing/set_graph_function #echo 1 > /sys/kernel/debug/tracing/options/funcgraph-tail echo <pid> > /sys/kernel/debug/tracing/set_ftrace_pid echo 0 > /sys/kernel/debug/tracing/tracing_on echo > /sys/kernel/debug/tracing/trace echo 3 > /proc/sys/vm/drop_caches echo 1 > /sys/kernel/debug/tracing/tracing_on然后执行下面的命令导出trace:
echo 0 > /sys/kernel/debug/tracing/tracing_on cat /sys/kernel/debug/tracing/trace > trace.log对于function_graph抓到的调用栈,可以使用内核提供的vim插件来阅读:
Documentation/trace/function-graph-fold.vim
用法:vim trace.log -S Documentation/trace/function-graph-fold.vim -
查看不同进程在某个函数上消耗的时间
比如以rtnl_lock为例:
echo rtnl_lock > set_graph_function
echo rtnl_trylock >> set_graph_function
# 设置过滤
echo rtnl_lock > set_ftrace_filter
echo rtnl_trylock >> set_ftrace_filter
# 输出调用者的信息
echo 1 > options/funcgraph-proc # 或者 echo funcgraph-proc > trace_options
# 输出延迟标记(+ ! # * @ $)
echo 1 > options/funcgraph-overhead # 或者 echo funcgraph-overhead > trace_options
# 设置tracer
echo function_graph > current_tracer
# 启动
echo 1 > tracing_on
下面是输出:
root@ubuntu:/sys/kernel/debug/tracing# cat trace
# tracer: function_graph
#
# CPU TASK/PID DURATION FUNCTION CALLS
# | | | | | | | | |
4) kworker-3574 | + 53.651 us | rtnl_lock();
4) kworker-3574 | + 11.752 us | rtnl_lock();
4) kworker-3574 | 3.186 us | rtnl_lock();
4) kworker-3574 | 5.460 us | rtnl_lock();
4) kworker-3574 | 5.090 us | rtnl_lock();
4) kworker-3574 | 2.755 us | rtnl_lock();
4) kworker-3574 | 3.246 us | rtnl_lock();
4) kworker-3574 | 6.502 us | rtnl_lock();
4) kworker-3574 | 3.016 us | rtnl_lock();
4) kworker-3574 | 2.936 us | rtnl_lock();
4) kworker-3574 | 2.455 us | rtnl_lock();
4) kworker-3574 | + 42.089 us | rtnl_lock();
4) kworker-3574 | 2.495 us | rtnl_lock();
4) kworker-3574 | 8.997 us | rtnl_lock();
4) kworker-3574 | 3.166 us | rtnl_lock();
4) kworker-3574 | 3.908 us | rtnl_lock();
- 过滤影响分析的函数
echo *spin* >> set_graph_notrace
echo *rcu* >> set_graph_notrace
echo mutex* >> set_graph_notrace
echo *alloc* >> set_graph_notrace
echo security* >> set_graph_notrace
echo *might* >> set_graph_notrace
echo __cond* >> set_graph_notrace
echo preempt* >> set_graph_notrace
echo kfree* >> set_graph_notrace
- 不跟硬件中断
echo 0 > options/funcgraph-irqs
如果不希望跟踪流程里有硬件中断处理,那么可以设置这个。这样在硬件中断中的函数不会被跟踪,
这里判断是否在硬件中断,用的时in_hardirq,而设置hardirq标志是在irq_enter_rcu,所以
还是会看到irq_enter_rcu被跟踪到,但是再往下就不会被跟踪了。
trace_point
- Linux内核 eBPF基础:Tracepoint原理源码分析
- Linux ftrace 1.2、trace event
- Using the TRACE_EVENT() macro (Part 1)
- Using the TRACE_EVENT() macro (Part 2)
- Using the TRACE_EVENT() macro (Part 3)
时间延迟标志
| 标记 | 含义 |
|---|---|
| + | > 10us |
| ! | > 100us |
| # | > 1ms |
| * | > 10ms |
| @ | > 100ms |
| $ | > 1s |
hist
在事件上创建自定义的直方图。
- 使用hist触发器通过raw_syscalls:sys_enter跟踪点来计数系统调用数量,并提供按进程pid分类的直方图
echo 'hist:keys=common_pid' > events/raw_syscalls/sys_enter/trigger
sleep 10
cat events/raw_syscalls/sys_enter/hist
...
echo '!hist:keys=command_pid' > events/raw_syscalls/sys_enter/trigger
trace_option
参考: https://www.kernel.org/doc/html/latest/trace/ftrace.html#trace-options
- func_stack_trace: 输出函数的调用栈,配合function tracer使用,也可以用于trace-event
bash-840761 [006] .... 101123.681864: ldsem_down_read <-tty_ldisc_ref_wait
bash-840761 [006] .... 101123.681866: <stack trace>
=> 0xffffffffc09d6099
=> ldsem_down_read
=> tty_ldisc_ref_wait
=> tty_ioctl
=> __x64_sys_ioctl
=> do_syscall_64
=> entry_SYSCALL_64_after_hwframe
- stacktrace: 输出函数的调用栈,配合trace-event用
perf-tools
trace-cmd
是kernelshark的后端,可以用kernelshark解析trace-cmd生成的文件。
参考
事件列举
# 列出所有跟踪事件的来源和选项
trace-cmd list
# 列出Ftrace跟踪器
trace-cmd list -t
# 列出事件源
trace-cmd list -e
# 列出系统调用跟踪点
trace-cmd list -e syscalls
# 显示指定跟踪点的格式文件
trace-cmd list -e syscalls:sys_enter_nanosleep -F
函数图示跟踪
- 抓取某个进程调用sys_open的调用栈
sudo trace-cmd record -p function_graph -g *sys_open -P <pid>
可以先让进程在调用open之前停住,用sleep或者getchar,在脚本里可以用echo $$; read con; exec xxx,执行上面的命令后,再继续执行
此外,还可以直接跟命令,比如:
sudo trace-cmd record -p function_graph -g *sys_open -F ls
最后执行下面的命令导出trace:
trace-cmd report > trace.log
函数跟踪
trace-cmd record -p function -l function_name
比如:
# 为ls命令跟踪所有一个vfs_开头的内核函数
trace-cmd record -p function -l 'vfs_*' -F ls
# 跟踪以tcp_开头的所有内核函数,持续10秒
trace-cmd record -p function -l 'tcp_*' sleep 10
# 跟踪bash及其子程序的所有一个vfs_开头的内核函数
trace-cmd record -p function -l 'vfs_*' -F -c bash
# 跟踪PID为21124的所有一个vfs_开头的内核函数
trace-cmd record -p function -l 'vfs_*' -P 21124
事件跟踪
trace-cmd record -e sched:sched_process_exec
远程
# 在tcp 8081端口监听
trace-cmd listen -p 8081
# 连接到远程主机以运行记录子命令
trace-cmd record ... -N addr:port
kernelshark
kprobe
- kprobe 的 3 种使用
- 内核调试之kprobe
- Linux内核 eBPF基础:kprobe原理源码分析:源码分析
- Linux内核 eBPF基础:kprobe原理源码分析:基本介绍与使用示例
- 打印open时的文件名
echo 'p:myprobe do_sys_open file=+0(%si):string' > kprobe_events
可以通过format查看log的输出格式:
root@ubuntu:/sys/kernel/debug/tracing# cat events/kprobes/my_probe/format
可以通过filter设置过滤条件:name: my_probe ID: 2072 format: field:unsigned short common_type; offset:0; size:2; signed:0; field:unsigned char common_flags; offset:2; size:1; signed:0; field:unsigned char common_preempt_count; offset:3; size:1; signed:0; field:int common_pid; offset:4; size:4; signed:1; field:unsigned long __probe_ip; offset:8; size:8; signed:0; field:__data_loc char[] file; offset:16; size:4; signed:1; print fmt: "(%lx) file=\"%s\"", REC->__probe_ip, __get_str(file)
echo 'file=="setproxy.sh"' > events/kprobes/my_probe/filter
使能:
echo 1 > events/kprobes/my_probe/enable
下面是输出的log:
cat trace或者cat trace_pipe
可以在输出log的时候,打印open的调用栈:cat-753 [001] .... 3406.761327: my_probe: (do_sys_open+0x0/0x80) file="setproxy.sh"
echo 1 > options/stacktrace
可以从trace中看到如下的log:
对于不同的体系架构,进行函数调用时使用的传参规则并不相同,所以在使用kprobe提取函数参数时使用的方式也不cat-772 [000] .... 3650.530789: my_probe: (do_sys_open+0x0/0x80) file="setproxy.sh" cat-772 [000] .... 3650.530980: <stack trace> => do_sys_open => do_syscall_64 => entry_SYSCALL_64_after_hwframe
相同,为了解决这一问题,内核引入了一个patch:a1303af5d79eb13a658633a9fb0ce3aed0f7decf解决了这一问题,
使用argX来代表参数,比如上面的这个file=+0(%si):string可以替换为file=+0($arg2):string,因为
filename是第2个参数,这里参数编号 是从1开始的。关于参数的解析可以参考内核代码:
kernel\trace\trace_probe.c:parse_probe_arg
下面是常见的处理器的函数传参规则:
| 体系架构 | 参数1 | 参数2 | 参数3 | 参数4 | 参数5 | 参数6 | 参数7 | 参数8 | 参数9 |
|---|---|---|---|---|---|---|---|---|---|
| x86 | stack | ||||||||
| x86_64 | rdi | rsi | rdx | rcx | r8 | r9 | stack | ||
| arm | r0 | r1 | r2 | r3 | stack | ||||
| arm64 | x0 | x1 | x2 | x3 | x4 | x5 | x6 | x7 | stack |
下面是不同架构的处理器上执行系统调用时的传参规则:
| Architecture | Syscall instruction | Syscall number in | return value | arg0 | arg1 | arg2 | arg3 | arg4 | arg5 |
|---|---|---|---|---|---|---|---|---|---|
| x86_64 | syscall | rax | rax | rdi | rsi | rdx | rcx | r8 | r9 |
| x86 | int 0x80 | eax | eax | ebx | ecx | edx | esi | edi | ebp |
| arm | svc 0 | r7 | r0 | r0 | r1 | r2 | r3 | r4 | r5 |
| arm64 | svc 0 | x8 | x0 | x0 | x1 | x2 | x3 | x4 | x5 |
uprobe
eBPF
- https://ebpf.io/
- https://www.bolipi.com/ebpf/index
- BPF CO-RE reference guide
- BPF and XDP Reference Guide
bpftrace
-
下面是提前编译好可以直接使用的bpftrace可执行程序
-
bpftrace做完strip后无法执行BEGIN和END
使用strip过程的bpftrace遇到如下问题:
ERROR: Could not resolve symbol: /proc/self/exe:BEGIN_trigger
在bpftrace运行时会调用bcc的接口bcc_resolve_name来解析BEGIN_trigger和END_trigger,传入的文件路径是/proc/self/exe,即会从本身的elf文件中去解析,但是strip后,符号表被删除,自然无法解析到需要的符号。同理,如果bpftrace被upx加了壳也会出现这个问题,因为此时exe指向的是加过壳的可执行程序,自然无法找到需要的符号。解决办法:- 不strip
- 在strip的时候使用-K参数保留这两个符号:strip -K BEGIN_trigger -K END_trigger bpftrace
-
可以从ExtendedAndroidTools下载编译好的bpftrace可执行程序:
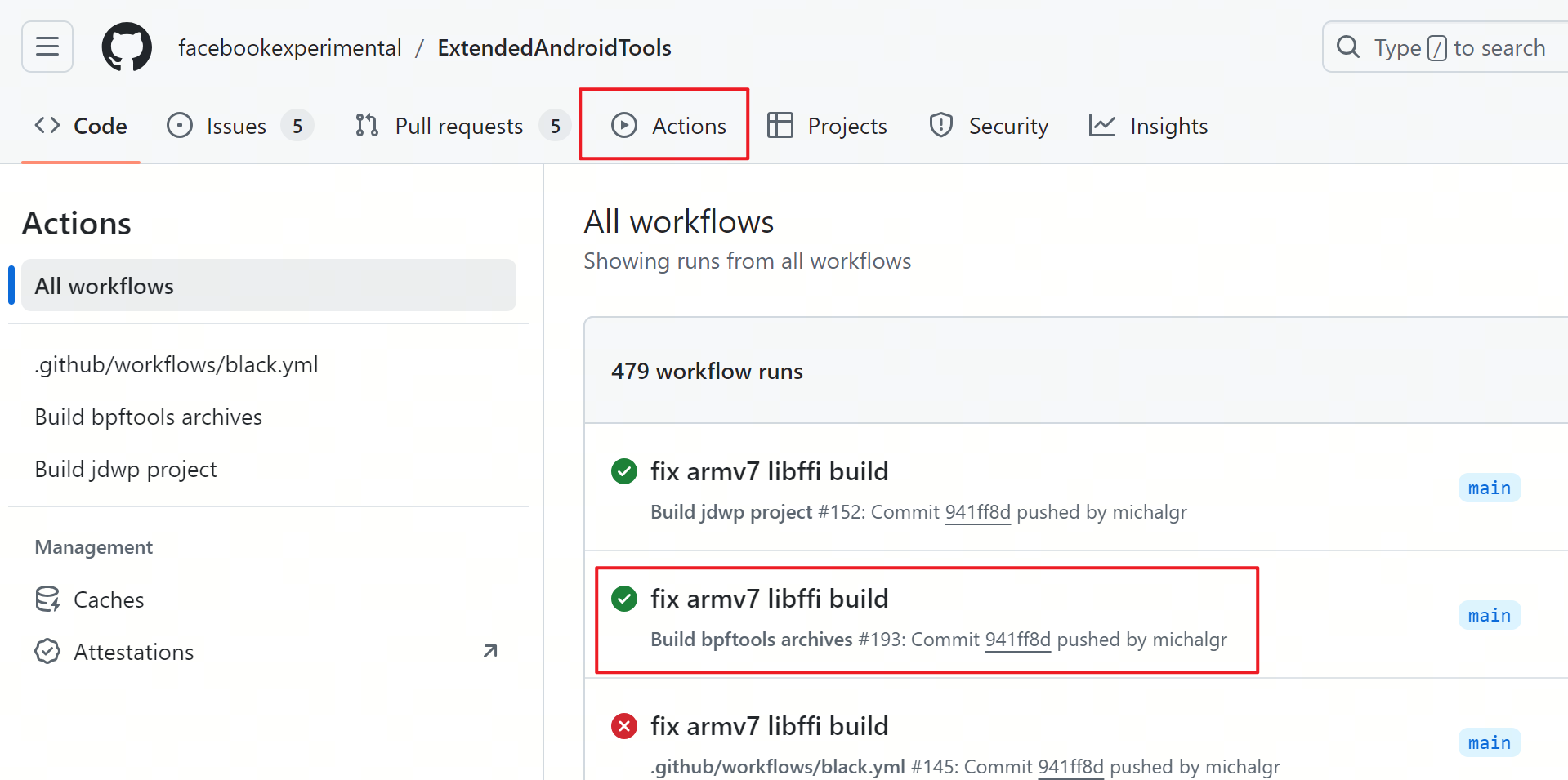
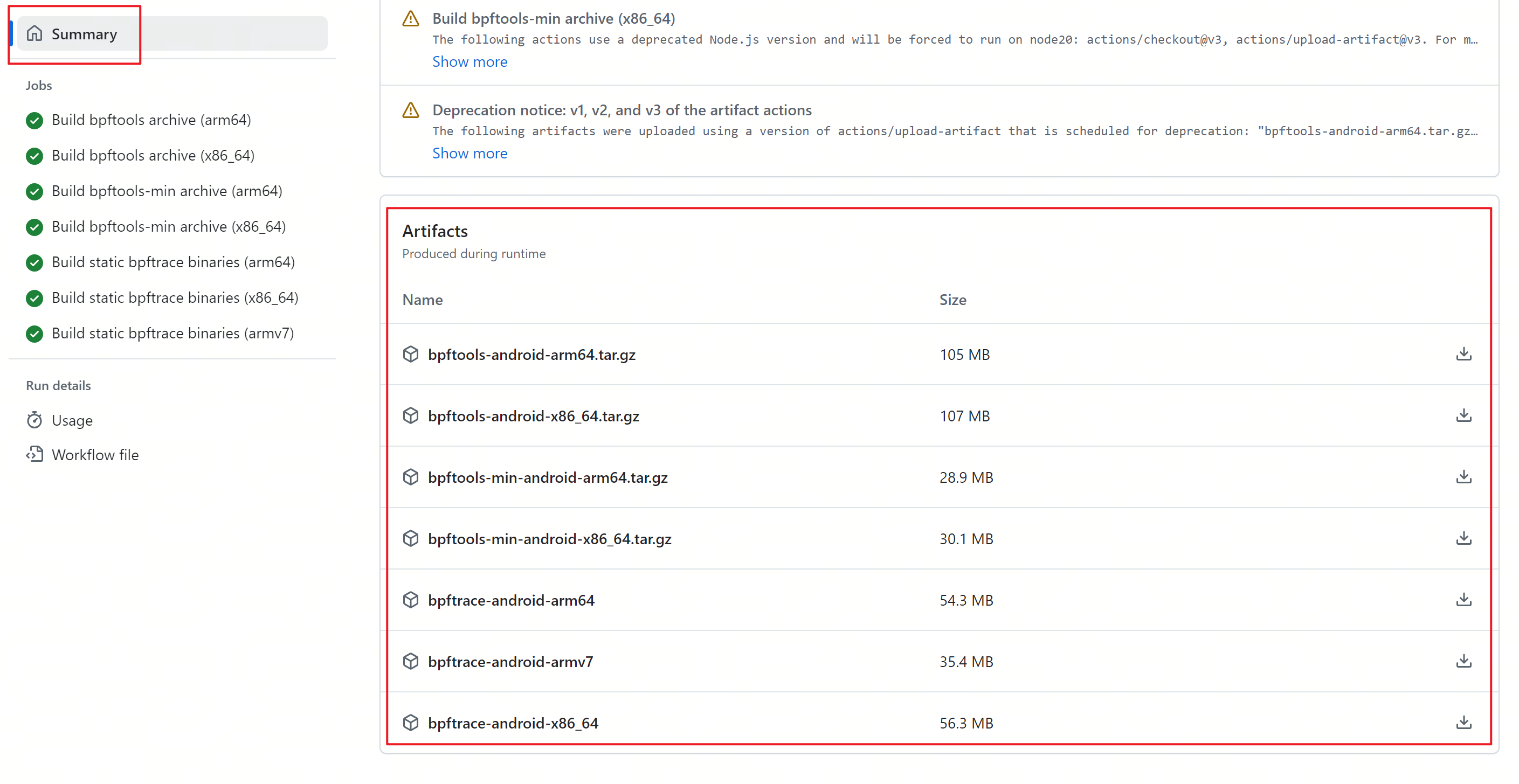
-
使用kprobe打印函数入口参数:
bpftrace -e 'kprobe:shmem_user_xattr_handler_set {printf("filename = %s, value = %s size = %d flag = %x\n", str(arg3), str(arg4), arg5, sarg0)}''
Attaching 1 probe...
filename = shmem_backend_file, value = ./memory_backend.img size = 20 flag = 1
filename = shmem_backend_file, value = size = 0 flag = 0
需要注意的是,arg从0开始,对于存放在栈里的参数,可以使用sarg来提取,函数原型:
static int shmem_user_xattr_handler_set(const struct xattr_handler *handler,
>------->------->------->------- struct dentry *unused, struct inode *inode,
>------->------->------->------- const char *name, const void *value,
>------->------->------->------- size_t size, int flags)
- 为bpfrace安装头文件
有时在bpftrace中需要解析一些内核结构体,比如page,此时就需要依赖内核头文件,可以参考下面的链接来安装:
https://github.com/iovisor/bpftrace/blob/master/INSTALL.md#kernel-headers-install
比如下面的bt文件:
#include <linux/mm.h>
kprobe:shmem_writepage
{
printf("Page: 0x%x, Index: 0x%x\n", arg0, ((struct page *)arg0)->index);
}
ply
BCC
perf

参考
- 在ubuntu上面的安装方法
- https://www.brendangregg.com/perf.html
- perf的基本使用方法
- Linux kernel profiling with perf
- linux性能分析工具:perf入门一页纸
- 2022最火的Linux性能分析工具--perf
- perf_event内核框架
- Linux Perf (目录)
- Linux内核性能架构:perf_event
- Linux内核 eBPF基础
- PERF EVENT API篇
- PERF EVENT 硬件篇
- PERF EVENT 内核篇
- PERF EVENT 硬件篇续 -- core/offcore/uncore
- man perf_event_open
- 内核文档 Performance monitor support
- 系统级性能分析工具perf的介绍与使用
- 在Linux下做性能分析3:perf
- 深入探索 perf CPU Profiling 实现原理
- Perf IPC以及CPU性能
- ARM SPE技术
perf_event_open学习
- perf_event_open 学习 —— 手册学习
- perf_event_open学习 —— mmap方式读取
- perf_event_open学习 —— 缓冲区管理
- perf_event_open 学习 —— 通过read的方式读取硬件技术器
火焰图
- Flame Graphs
- On-CPU火焰图
- Off-CPU火焰图
- 内存泄漏火焰图
- gitee镜像:https://gitee.com/mirrors/FlameGraph
perf stat
perf kvm
- perf kvm查看虚机热点调用
- 红帽的技术文档,其中介绍的guestmount的用法可以学习一下:
- perf-kvm(1) — Linux manual page
perf trace
perf ftrace
perf probe的使用
- https://man7.org/linux/man-pages/man1/perf-probe.1.html
- perf probe实例
- 查看一个内核函数中哪些位置可以插入事件
perf probe --line kernel_function -k <kernel_source_path>/vmlinux -s <kernel_source_path>
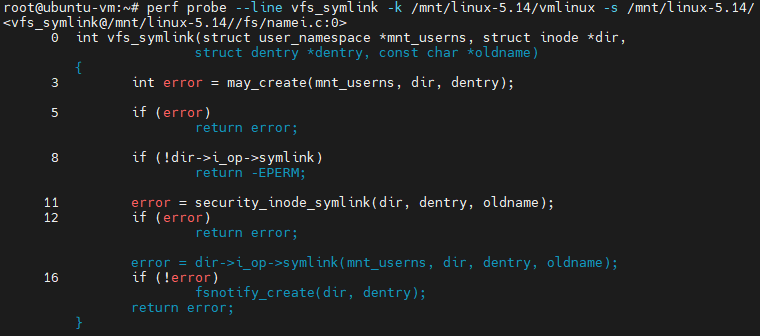
- 查看一个内核函数中指定行可以访问哪些变量
perf probe --var kernel_function:lineno -k <kernel_source_path>/vmlinux -s <kernel_source_path>

- 添加追踪事件
在上面第5行插入事件:

可以使用perf probe --list查看当前注册了哪些事件:

然后使用perf record -e probe:vfs_symlink_L5开启事件,再在另外一个窗口执行一个创建软连接的操作,然后
停止perf probe,最后用perf script查看事件:

- 删除事件

perf sched使用
- Linux perf sched Summary
- perf sched for Linux CPU scheduler analysis
- perf sched查看调度延迟与唤醒延迟
- Linux 的调度延迟 - 原理与观测
- perf之sched
getdelays
surftrace
这是是阿里云开发的,是对ftrace的二次封装。
https://github.com/aliyun/surftrace
Systemtap
- https://sourceware.org/systemtap/wiki/HomePage
- https://sourceware.org/systemtap/
- SystemTap使用指南
- Systemtap原理简介
- https://sourceware.org/systemtap/getinvolved.html
- https://gitlab.com/fche/systemtap
stapbpf
- stapstapbpfComparison
- Introducing stapbpf - SystemTap's new BPF backend
- SystemTap's BPF Backend Introduces Tracepoint Support
- What are BPF Maps and how are they used in stapbpf
Dtrace
uftrace
- https://uftrace.github.io/slide/#1
- https://github.com/namhyung/uftrace
- https://github.com/namhyung/uftrace/wiki/Tutorial
- 业务时延检测利器-uftrace
utrace
- https://github.com/Gui774ume/utrace
- UTrace is a tracing utility that leverages eBPF to trace both user space and kernel space functions
Systrace/Perfetto
LTTng
Trace Compass
- https://eclipse.dev/tracecompass/index.html
- 使用trace compass分析ftrace
- Linux Networking: How The Kernel Handles A TCP Connection
B站某UP主写的profile工具,可以学习一下
本文来自博客园,作者:摩斯电码,未经同意,禁止转载

