Unwinding a Stack by Hand with Frame Pointers and ORC 翻译 (By ChatGPT)
原文:https://blogs.oracle.com/linux/post/unwinding-stack-frame-pointers-and-orc
The Oracle Linux Sustaining team is tasked with identifying and fixing bugs in the Linux kernel. We rely on a rich ecosystem of debugging tools like crash and pykdump to help us pick up the remnants of a crashed kernel and figure out what led to its demise. But operating systems are complex, and sometimes our tools fail us. In these cases, we have to fall back on our understanding of the kernel subsystems and the target CPU architecture, since we find ourselves diving deep into hex dumps and assembly listings.
Oracle Linux Sustaining 团队的任务是识别和修复 Linux 内核中的 bug。我们依赖于像 crash 和 pykdump 这样的丰富调试工具生态系统,以帮助我们捡起崩溃内核的残留物,并找出导致其崩溃的原因。但操作系统是复杂的,有时我们的工具会失效。在这些情况下,我们不得不依靠对内核子系统和目标 CPU 架构的理解,因为我们发现自己深入到十六进制转储和汇编列表中。
Take something as simple as a stack trace. Many developers view these as a given, since computers are quite good at automatically unwinding a stack, looking up symbols, and producing the pretty trace we know and love. But in some exceptional cases (for example, interrupts occurring precisely on entry to a function call) an automatic unwinder can be led astray, producing an incorrect trace. In other cases, a debugging tool may not even recognize a portion of memory as a stack, leaving us without the option to unwind it.
以堆栈跟踪为例。许多开发人员认为这是一个给定的事实,因为计算机非常擅长自动展开堆栈,查找符号,并生成我们所知道和喜爱的漂亮跟踪。但在某些特殊情况下(例如,在函数调用的入口处恰好发生中断),自动展开程序可能会被引入歧途,产生错误的跟踪。在其他情况下,调试工具甚至可能无法将内存的某个部分识别为堆栈,使我们无法展开它。
Until recently, Linux Sustaining engineers have taken comfort in the knowledge that, when code is compiled with frame pointers, they are able to manually unwind the stack with relative ease. But the kernel community (at least, the x86_64 kernel community) is moving away from frame pointers. Increasingly, the community is migrating to an in-kernel debug information format called ORC, which enables the kernel to unwind stacks without relying on the frame pointer. As a result, manually unwinding a stack is no longer a simple matter of following a chain of frame pointers.
直到最近,Linux Sustaining 工程师一直对编译时启用帧指针的代码感到满意,因为他们能够相对容易地手动展开堆栈。但内核社区(至少是 x86_64 内核社区)正在逐渐放弃帧指针。越来越多的社区正在迁移到一种称为 ORC 的内核调试信息格式,它使内核能够在不依赖帧指针的情况下展开堆栈。因此,手动展开堆栈不再是简单地跟随帧指针链的问题。
This blog post will first review the use of frame pointers for unwinding a stack on x86_64. Then, we will introduce the ORC format and describe its benefits. Finally, we’ll discuss how stack unwinding works for code built without frame pointers, and with ORC unwind info.
本文首先回顾了在 x86_64 上使用帧指针展开堆栈的方法。然后,我们将介绍 ORC 格式并描述其优点。最后,我们将讨论如何展开没有帧指针和使用 ORC 展开信息的代码的堆栈。
Frame Pointer Unwinds
When C code calls another function, the call instruction pushes the return address (that is, the address of the next instruction) onto the stack, before branching into the callee function’s code. In order to create a “stack trace” that’s human readable, you need to find each return address, lookup the name of the function associated with each one, and print each function name in sequence. However, functions use stack space for other purposes, most commonly to store the previous value of a callee-save register, or to store the value of a local variable. Each function’s stack space (“stack frame”) can have variable length, so there’s no way of knowing how many bytes are between each return address.
当 C 代码调用另一个函数时,调用指令会将返回地址(即下一条指令的地址)推入堆栈,然后跳转到被调用函数的代码中。为了创建一个可读的“堆栈跟踪”,需要找到每个返回地址,查找与每个地址相关联的函数名称,并按顺序打印每个函数名称。但是,函数使用堆栈空间来存储其他目的,最常见的是存储被调用者保存寄存器的先前值,或者存储本地变量的值。每个函数的堆栈空间(“堆栈帧”)可以具有可变长度,因此无法知道每个返回地址之间有多少字节。
This is where frame pointers have historically come in. A frame pointer is a register which always contains the previous value of the stack pointer. On x86_64, the register in question is usually RBP. At the start of every function, a compiler with frame pointers enabled will generate code like this:
这就是历史上帧指针的作用。帧指针是一个寄存器,它始终包含堆栈指针的先前值。在 x86_64 上,相关的寄存器通常是 RBP。在每个函数的开头,启用帧指针的编译器将生成以下代码:
some_function:
push %rbp // #1
mov %rsp, %rbp // #2
push %r14 // #3
push %r13
push %r12
sub 0x8, %rsp // #4
At instruction #1, the old frame pointer is pushed to the stack. Next, the old value of the stack pointer is copied into the RBP register (#2). After this, some callee-save registers are saved (#3), and then the function may allocate some stack space for local variables by subtracting the number of bytes from RSP (#4).
在指令 #1 中,旧的帧指针被推入堆栈。接下来,堆栈指针的旧值被复制到 RBP 寄存器中(#2)。在此之后,一些被调用者保存的寄存器被保存(#3),然后函数可能通过从 RSP 中减去字节数来分配一些堆栈空间用于本地变量(#4)。
Thanks to this frame pointer register, the stack is now a linked list of “stack frames” which we can walk all the way to the beginning. At any point, we can just look at the current frame pointer register to get the previous value of RSP. And since the previous value of RSP happens to be the location where the previous frame pointer was stored, it’s just a chain of pointers crawling their way up the stack. Here’s an illustration:
由于这个帧指针寄存器,堆栈现在是一个“堆栈帧”的链表,我们可以一直遍历到开头。在任何时候,我们只需查看当前帧指针寄存器即可获取 RSP 的前一个值。由于 RSP 的前一个值恰好是存储前一个帧指针的位置,因此它只是一系列指针在堆栈上爬行的链。下面是一个示例图:
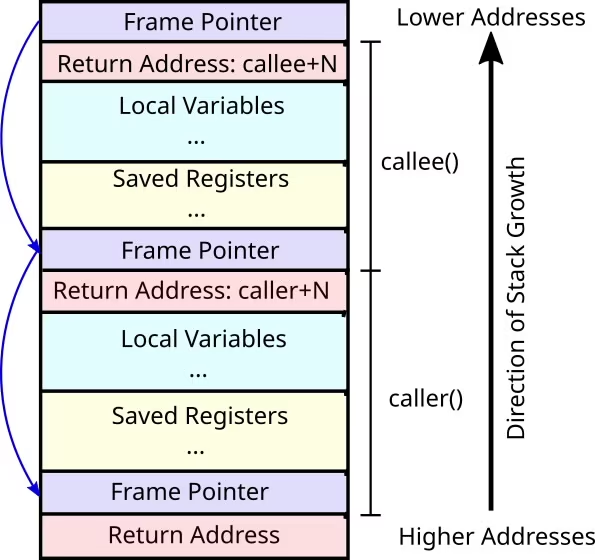
Each blue box is a frame pointer. The most recent stack frame is at the top of this image. If you follow its frame pointer, you see it points at the frame pointer from the older frame, which points at the next older frame, etc. Let’s look at an example of this, taken from the Linux kernel.
每个蓝色框都是一个帧指针。最近的堆栈帧在此图像的顶部。如果您跟随它的帧指针,您会看到它指向旧帧的帧指针,后者指向下一个旧帧,以此类推。让我们看一个来自 Linux 内核的例子。
I deliberately corrupted a filesystem data structure with a NULL pointer, which caused the kernel to crash and take a core dump. Then, I used the crash utility to get the register state and a hex dump of the stack that crashed the kernel. It’s worth saying that crash is perfectly capable of computing and displaying the stack trace in this case, but the point of this exercise is to do it ourselves. Below are the relevant register values (RIP, the instruction pointer, and RBP, the frame pointer), along with the relevant stack data.
我故意使用 NULL 指针破坏了一个文件系统数据结构,导致内核崩溃并生成了一个核心转储。然后,我使用 crash 实用程序获取了寄存器状态和崩溃内核的堆栈的十六进制转储。值得一提的是,在这种情况下,crash 完全能够计算和显示堆栈跟踪,但这个练习的重点是我们自己来做。下面是相关的寄存器值(RIP,指令指针,和 RBP,帧指针),以及相关的堆栈数据。
RIP: ffffffff9910d178
RBP: ffff9b4e8057bb98
Stack Memory Dump:
ffff9b4e8057bb90: ffff8ce89eea71a0 ffff9b4e8057bbf8 <--
ffff9b4e8057bba0: ffffffff990fb393 ffffffff991da4b5
ffff9b4e8057bbb0: ffff8ce89eef4dc8 ffff9b4e8057bc14
ffff9b4e8057bbc0: 0000000000000081 3a7fa5a2654d8f00
ffff9b4e8057bbd0: ffff9b4e8057bcd0 0000000000000000
ffff9b4e8057bbe0: 0000000000000000 0000000000000000
ffff9b4e8057bbf0: 0000000000000002 ffff9b4e8057bc60 <--
ffff9b4e8057bc00: ffffffff990fc1c9 ffff9b4e8057bc60
ffff9b4e8057bc10: ffffffff990fcc42 0000000000000000
ffff9b4e8057bc20: 0000000000000000 ffff8ce89eea7680
ffff9b4e8057bc30: 3a7fa5a2654d8f00 ffff9b4e8057bcd0
ffff9b4e8057bc40: ffff9b4e8057be30 ffff8ce88ec7e020
ffff9b4e8057bc50: 0000000000000000 0000000000000002
ffff9b4e8057bc60: ffff9b4e8057bcc0 ffffffff990fd20d <--
ffff9b4e8057bc70: ffff9b4e8057bc80 ffffffff9910b4be
ffff9b4e8057bc80: ffff9b4e8057bce0 ffffffff991d7146
ffff9b4e8057bc90: 0000000000000018 3a7fa5a2654d8f00
ffff9b4e8057bca0: 0000000000000004 ffff8ce88ec7e000
ffff9b4e8057bcb0: 0000000000000004 ffff9b4e8057be30
ffff9b4e8057bcc0: ffff9b4e8057bde8 ffffffff99101a80 <--
ffff9b4e8057bcd0: ffff8ce801711060 ffff8ce89eea71a0
ffff9b4e8057bce0: 0000000bbcc22e4a ffff8ce88ec7e020
ffff9b4e8057bcf0: 0000000000000000 ffff8ce89eea7680
ffff9b4e8057bd00: ffff8ce89eef4dc8 0000000200000044
ffff9b4e8057bd10: 000007f2000016a4 0000000000000000
ffff9b4e8057bd20: ffffffff00000000 ffff9b4e8057bd30
ffff9b4e8057bd30: ffff9b4e8057bd88 0000000000000018
ffff9b4e8057bd40: ffff9b4e8057bd70 ffffffff990e72fb
ffff9b4e8057bd50: 00007fff8d4e1360 0000000000000fe0
ffff9b4e8057bd60: 0000000000000fe0 ffff8ce88ec7e020
ffff9b4e8057bd70: ffff9b4e8057bda8 ffffffff992aa3cc
ffff9b4e8057bd80: ffff8ce88ec7e000 00007fff8d4e1360
ffff9b4e8057bd90: ffff8ce88ec7e000 0000000000000000
ffff9b4e8057bda0: 0000000000000002 ffffff9c8057bde8
ffff9b4e8057bdb0: ffffffff99100ccf 3a7fa5a2654d8f00
ffff9b4e8057bdc0: 0000000000000004 0000000000000004
ffff9b4e8057bdd0: 00000000ffffff9c ffff9b4e8057be30
ffff9b4e8057bde0: 00007fff8d4e1360 ffff9b4e8057be10 <--
ffff9b4e8057bdf0: ffffffff99101c3e 0000000000000004
ffff9b4e8057be00: 0000000000000100 00000000ffffff9c
ffff9b4e8057be10: ffff9b4e8057be70 ffffffff990f4437 <--
ffff9b4e8057be20: ffff9b4e8057be80 ffff8ce88ec7e000
ffff9b4e8057be30: 00007fff8d4e1360 0000000000000000
ffff9b4e8057be40: 3a7fa5a2654d8f00 00007fff8d4e1240
ffff9b4e8057be50: ffff9b4e8057bf58 0000000000000000
ffff9b4e8057be60: 0000000000000000 0000000000000000
ffff9b4e8057be70: ffff9b4e8057bf18 ffffffff990f55e4 <--
ffff9b4e8057be80: ffffffffffffffc3 00007f81166f86a4
ffff9b4e8057be90: ffff9b4e8057bf58 00000000c000003e
ffff9b4e8057bea0: 0000000000000000 ffff9b4e8057bf28
ffff9b4e8057beb0: ffffffff98e03c6a 0000000000000000
ffff9b4e8057bec0: ffff9b4e8057bef8 ffffffff98f851aa
ffff9b4e8057bed0: 0000000000000080 ffff9b4e8057bf58
ffff9b4e8057bee0: ffff9b4e8057bf58 0000000000000000
ffff9b4e8057bef0: 0000000000000000 3a7fa5a2654d8f00
ffff9b4e8057bf00: 000000000000014c 3a7fa5a2654d8f00
ffff9b4e8057bf10: 000000000000014c ffff9b4e8057bf28 <--
ffff9b4e8057bf20: ffffffff990f5644 ffff9b4e8057bf48 <--
ffff9b4e8057bf30: ffffffff98e044f0 0000000000000000
ffff9b4e8057bf40: 0000000000000000 0000000000000000 <--
ffff9b4e8057bf50: ffffffff998001b8 000056020a7ff458
This is a pretty large chunk of memory to show on screen. The memory dump is formatted with 2 64-bit words per line. The address of the first word is printed before the colon, and memory addresses increase left to right, top to bottom. On x86_64, the stack grows toward the lower addresses, so the most recent stack frame is at the top of this listing (just like the diagram). To help you read it, I’ve bolded each frame pointer (RBP). Let’s go ahead and unwind this stack by hand:
这是一个相当大的内存块,可以在屏幕上显示。内存转储以每行 2 个 64 位字的格式进行格式化。冒号前打印第一个字的地址,内存地址从左到右,从上到下增加。在 x86_64 上,堆栈向较低地址增长,因此最近的堆栈帧位于此列表的顶部(就像图表一样)。为了帮助您阅读它,我已经加粗了每个帧指针(RBP)。让我们手动展开这个堆栈:
We start with the current RBP value, ffff9b4e8057bb98. This points at the second word of memory in the dump, which is the first bolded word. That word itself contains the value ffff9b4e8057bbf8, which is the previous value for RBP. We can look that address up a few lines down, finding the next prior RBP value of ffff9b4e8057bc60. If we continue this chain of pointers all the way down the stack, we will get the following values (all of the bolded values from the listing above):
我们从当前的 RBP 值 ffff9b4e8057bb98 开始。这指向转储中的第二个内存字,即第一个加粗的字。该字本身包含值 ffff9b4e8057bbf8,这是 RBP 的前一个值。我们可以在几行下面查找该地址,找到下一个先前的 RBP 值 ffff9b4e8057bc60。如果我们继续沿着指针链一直到堆栈底部,我们将得到以下值(上面列表中所有加粗的值):
ffff9b4e8057bb98 (starting RBP value)
ffff9b4e8057bbf8
ffff9b4e8057bc60
ffff9b4e8057bcc0
ffff9b4e8057bde8
ffff9b4e8057be10
ffff9b4e8057be70
ffff9b4e8057bf18
ffff9b4e8057bf28
ffff9b4e8057bf48
0000000000000000
Notice that only the last few digits of these addresses change, because they are pointers to within the stack, and the stack is a contiguous block of memory. Once you notice this pattern, it can be quite easy to pick out stack frames in a hex dump. Frequently, I like to paste the hex data into a text editor with a highlighting search function, like vim. You can search the prefix (in this case, ffff9b4e8057b) to highlight these addresses on the stack. However, your eyes may deceive you! Not all addresses on the stack starting with these digits are necessarily frame pointer values. Since the stack is constantly getting reused (and not re-initialized) between function calls, it’s very common to see stale data, like old frame pointers, or maybe pointers to stack variables. So while the search method is better than nothing, you’re better off manually following the frame pointer list.
请注意,这些地址的最后几位数字发生变化,因为它们是指向堆栈内部的指针,而堆栈是一块连续的内存块。一旦您注意到这种模式,就可以很容易地在十六进制转储中挑选出堆栈帧。通常,我喜欢将十六进制数据粘贴到具有高亮搜索功能的文本编辑器中,例如 vim。您可以搜索前缀(在本例中为 ffff9b4e8057b)以突出显示堆栈上的这些地址。但是,您的眼睛可能会欺骗您!并非以这些数字开头的堆栈上的所有地址都必须是帧指针值。由于堆栈在函数调用之间不断被重用(而不是重新初始化),因此很常见看到过时的数据,例如旧的帧指针或指向堆栈变量的指针。因此,虽然搜索方法比没有好,但最好手动跟随帧指针列表。
The last address in this list is all zeros. It seems to indicate that the value RBP had before the first function call was zero. I’m not sure whether it’s guaranteed that this value is always zero. In general, the first RBP value you see which doesn’t obviously point within the stack, is where you should stop unwinding.
此列表中的最后一个地址全部为零。它似乎表明第一个函数调用之前的 RBP 值为零。我不确定这个值是否总是为零。通常,您看到的第一个 RBP 值不明显指向堆栈内部的值就是您应该停止展开的位置。
At this point, we have a list of frame pointers, but what we really need is a list of return addresses. On x86_64, the call instruction pushes the return address to the stack, jumps to the beginning of the called function, and the called function then pushes RBP to the stack one word address “below” the return address (since the stack grows to lower addresses). We can read these values by looking at the stack words which are at the next address after each bolded RBP value on the memory dump, since the memory dump is in ascending order of memory addresses.
此时,我们有一个帧指针列表,但我们真正需要的是返回地址列表。在 x86_64 上,调用指令将返回地址推入堆栈,跳转到被调用函数的开头,然后被调用函数将 RBP 推入堆栈,地址比返回地址“低”一个字(因为堆栈向较低地址增长)。我们可以通过查看内存转储中每个加粗的 RBP 值之后的下一个地址处的堆栈字来读取这些值,因为内存转储按内存地址升序排列。
ffffffff9910d178 (starting RIP value)
ffffffff990fb393
ffffffff990fc1c9
ffffffff990fd20d
ffffffff99101a80
ffffffff99101c3e
ffffffff990f4437
ffffffff990f55e4
ffffffff990f5644
ffffffff98e044f0
ffffffff998001b8
First, notice that at the top of the list I prepended the current RIP value. This is the currently executing instruction, so it is the absolute most recent function call. The remaining addresses come directly from the values pushed to the stack.
首先,请注意在列表顶部我添加了当前的 RIP 值。这是当前正在执行的指令,因此它是绝对最近的函数调用。其余的地址直接来自推送到堆栈中的值。
Second, notice how all of these addresses start with ffffffff9. This prefix has to do with the location that the kernel image got mapped at. Due to KASLR (kernel address space layout randomization), this location will be different each time the kernel boots. However, once you determine this prefix, you can easily locate code addresses on the stack using the same highlighting method in your text editor. These code addresses could be return addresses, but they could also be function pointers that got pushed to the stack.
其次,请注意所有这些地址都以 ffffffff9 开头。这个前缀与内核映像的映射位置有关。由于 KASLR(内核地址空间布局随机化),每次内核启动时,这个位置都会不同。但是,一旦您确定了这个前缀,您就可以使用文本编辑器中的相同突出显示方法轻松定位堆栈上的代码地址。这些代码地址可能是返回地址,但它们也可能是推送到堆栈上的函数指针。
Third, recall that these are all return addresses: that is, they are the instruction that the CPU should begin executing after the function call completes. For the purpose of a stack trace, you typically want to see the address of the currently executing instruction. So technically, it would be a good idea to subtract one from each address here, to ensure that we’re looking at the correct instruction. But I’m going to skip this step for simplicity.
第三,回想一下,这些都是返回地址:也就是说,它们是 CPU 在函数调用完成后应该开始执行的指令。为了进行堆栈跟踪,您通常希望看到当前执行指令的地址。因此,从这里的每个地址中减去一个是一个好主意,以确保我们正在查看正确的指令。但是为了简单起见,我将跳过此步骤。
With these observations out of the way, we now need to take the final step: mapping these return addresses to function names, to get the pretty stack trace we’re hoping for. Unfortunately, KASLR makes this difficult, since these addresses don’t correspond to the ones which the linker assigned when the kernel was compiled! However, currently Linux’s KASLR does not randomize the order of functions within the kernel image (so-called “Function Granular KASLR”). So, assuming we know the mapping offset, we’ll be able to subtract it from each code address, and lookup the resulting offset in the kernel’s symbol table.
有了这些观察结果,我们现在需要进行最后一步:将这些返回地址映射到函数名称,以获得我们希望看到的漂亮堆栈跟踪。不幸的是,KASLR 使这很困难,因为这些地址不对应于链接器在内核编译时分配的地址!但是,目前 Linux 的 KASLR 不会随机化内核映像中函数的顺序(所谓的“函数粒度 KASLR”)。因此,假设我们知道映射偏移量,我们将能够从每个代码地址中减去它,并在内核符号表中查找结果偏移量。
Thankfully, just before it finished crashing, the kernel printed the following line to the log:
值得庆幸的是,在崩溃结束之前,内核向日志打印了以下行:
[ 136.773552] Kernel Offset: 0x17e00000 from 0xffffffff81000000 (relocation range: 0xffffffff80000000-0xffffffffbfffffff)
This tells us that the kernel text section is offset 0x17e00000 from the memory address 0xffffffff81000000. Taken together, if we subtract the value 0xffffffff98e00000 from each address, we will arrive at the true offset of each function in the kernel’s text (i.e. code) section. I’ve taken the liberty of doing that math for each of the return addresses above:
这告诉我们内核文本部分从内存地址 0xffffffff81000000 偏移了 0x17e00000。综合起来,如果我们从每个地址中减去值 0xffffffff98e00000,我们将到达内核文本(即代码)部分中每个函数的真实偏移量。我已经为上面的每个返回地址进行了这个计算:
0x79ea3
0x161132
0xa75b0
0x5b8cc5
0x5b9141
0x5b964f
0x390d0e
0x2ec97b
0x2ef56b
0x2ef841
0x2ef8da
0x44f0
0xa001b8
Now, we can use the addr2line tool, along with the vmlinux file found in the kernel-uek-debuginfo package, to format these offsets as functions and line numbers:
现在,我们可以使用 addr2line 工具以及 kernel-uek-debuginfo 包中找到的 vmlinux 文件,将这些偏移量格式化为函数和行号:这是我们漂亮格式化的堆栈跟踪!请注意,addr2line 甚至显示了被 __d_lookup_rcu() 内联的函数,这将帮助我们定位崩溃的确切部分。
$ addr2line -e /usr/lib/debug/lib/modules/5.4.17-2136.304.4.1.el8uek.x86_64/vmlinux \
-j .text -ipfas \
0x30d178 0x2fb393 0x2fc1c9 0x2fd20d 0x301a80 0x301c3e 0x2f4437 0x2f55e4 \
0x2f5644 0x44f0 0xa001b8
0x000000000030d178: read_word_at_a_time at compiler.h:350
(inlined by) dentry_string_cmp at dcache.c:252
(inlined by) dentry_cmp at dcache.c:406
(inlined by) __d_lookup_rcu at dcache.c:2672
0x00000000002fb393: lookup_fast at namei.c:1659
0x00000000002fc1c9: walk_component at namei.c:1909
0x00000000002fd20d: path_lookupat at namei.c:2433
0x0000000000301a80: filename_lookup at namei.c:2463
0x0000000000301c3e: user_path_at_empty at namei.c:2725
0x00000000002f4437: vfs_statx at stat.c:198
0x00000000002f55e4: do_statx at stat.c:582
0x00000000002f5644: __x64_sys_statx at stat.c:599
0x00000000000044f0: do_syscall_64 at common.c:296
0x0000000000a001b8: entry_SYSCALL_64_after_hwframe at entry_64.S:188
This is our nicely formatted stack trace! Notice that addr2line even took the liberty of showing the functions which got inlined by __d_lookup_rcu(), which would help us locate the exact part of the function where we crashed.
这是我们漂亮格式化的堆栈跟踪!请注意,addr2line 甚至显示了被 __d_lookup_rcu() 内联的函数,这将帮助我们定位崩溃的确切部分。
As I mentioned already, I inserted a NULL pointer into a filesystem data structure, so this stack simply shows the kernel crashing as it attempted to read a corrupted structure. Thankfully, it’s not a real bug in the kernel!
正如我已经提到的,我在文件系统数据结构中插入了一个空指针,因此此堆栈仅显示内核在尝试读取已损坏的结构时崩溃。值得庆幸的是,这不是内核中的真正错误!
Why Ditch the Frame Pointer?
This article is supposed to be about ORC, but thus far we’ve focused on frame pointers. So how does ORC tie in? The frame pointer was a really great tool for us to unwind the stack, but the fact of the matter is that it’s inefficient. The compiler absolutely does not need to use a frame pointer. Since the compiler generates the assembly code for each function, it knows exactly how many saved registers and local variables every function uses. Thus, it knows the size of each function’s stack frame without even consulting the frame pointer. An entire CPU register is being wasted, at all times, just for the rather rare times that we may want to examine the stack and unwind it. Beyond just wasting the register slot, we also have to insert instructions to push and pop the frame pointer from the stack.
这篇文章本应讨论 ORC,但到目前为止,我们已经集中讨论了帧指针。那么 ORC 是如何联系起来的呢?帧指针是我们展开堆栈的一个非常好的工具,但事实是它效率低下。编译器绝对不需要使用帧指针。由于编译器为每个函数生成汇编代码,它知道每个函数使用的保存寄存器和本地变量的数量。因此,它甚至不需要查看帧指针就知道每个函数的堆栈帧大小。一个完整的 CPU 寄存器一直被浪费,仅用于我们可能想要检查堆栈并展开它的相当罕见的情况。除了浪费寄存器槽之外,我们还必须插入指令将帧指针从堆栈中推入和弹出。
CPU registers are a limited resource – every free register is a variable we could potentially avoid storing in memory. Similarly, cache space is also limited. If we use fewer instructions to create stack frames, and we also use less stack memory, we’ll have more cache space available for critical data, resulting in fewer cache misses. While the difference sounds small, when you’re talking about nearly every function in the Linux kernel, the performance benefit adds up! According to an analysis by Mel Gorman, using frame pointers added overhead of up to 5-10% in some memory management related benchmarks.
CPU 寄存器是有限的资源 - 每个空闲寄存器都是我们可能避免存储在内存中的变量。同样,缓存空间也是有限的。如果我们使用更少的指令创建堆栈帧,并且使用更少的堆栈内存,我们将有更多的缓存空间可用于关键数据,从而减少缓存未命中。虽然差异听起来很小,但当您谈论 Linux 内核中的几乎每个函数时,性能优势会累加!根据 Mel Gorman 的分析,在某些与内存管理相关的基准测试中,使用帧指针会增加 5-10% 的开销。
So if frame pointers are expensive, how can we get rid of them while maintaining the ability to unwind the stack? Well, the compiler itself knows the state of the stack at every point in a function. It actually can output some of that information into debuginfo, such as the DWARF format (the name stands for nothing except a cheeky play on ELF, either an Executable Linkable Format, or a creature found in Middle Earth). Most debugging tools, like crash and GDB, can read this DWARF information and use it to unwind stacks without relying on the frame pointer. But the kernel itself doesn’t have access to this data for use unwinding stacks at runtime, so it has historically relied on frame pointers. Normally, kernels have debuginfo stripped because it is quite large. And even if the information were available to the kernel, it would be quite complex to use properly. This LWN article goes into detail on this issue, which motivated the creation of ORC.
那么,如果帧指针很昂贵,我们如何在保持展开堆栈的能力的同时摆脱它们?好吧,编译器本身知道函数中每个点的堆栈状态。它实际上可以将其中一些信息输出到调试信息中,例如 DWARF 格式(该名称除了一个俏皮的 ELF 玩笑外没有任何含义,ELF 是可执行可链接格式,或者是中土世界中的一种生物)。大多数调试工具,如 crash 和 GDB,可以读取此 DWARF 信息并使用它展开堆栈,而无需依赖帧指针。但是内核本身无法访问此数据以在运行时展开堆栈,因此它历史上一直依赖于帧指针。通常,内核已剥离调试信息,因为它非常大。即使内核可以访问此信息,正确使用它也会非常复杂。这篇 LWN 文章详细介绍了这个问题,这促使了 ORC 的创建。
ORC (whose name was another play on Middle Earth, but has since been dubbed the “Oops Replay Capability”) is a simplified debug information format which contains only the information necessary to unwind the stack. Essentially, the kernel stores a large array of records, each of which is associated with one or more instructions. Given an instruction, its ORC entry can tell you how to compute the stack pointer value from before the current function call. The kernel’s unwinding routines reference this information to print stack traces, but we can also use it manually if necessary.
ORC(其名称是中土世界的另一个玩笑,但现在被称为“Oops Replay Capability”)是一个简化的调试信息格式,其中仅包含展开堆栈所需的信息。实际上,内核存储了一个大型的记录数组,每个记录与一个或多个指令相关联。给定一个指令,它的 ORC 条目可以告诉您如何从当前函数调用之前计算堆栈指针值。内核的展开例程引用此信息以打印堆栈跟踪,但如果必要,我们也可以手动使用它。
ORC Records and Unwind Algorithm
In order to actually get the ORC information out of the kernel, we first need to get a kernel compiled with ORC information. Upstream, this is now the default for x86_64. You’ll want to make sure you configure your source tree with CONFIG_UNWINDER_ORC=y, and you’ll also want to disable CONFIG_UNWINDER_FRAME_POINTER and CONFIG_FRAME_POINTER to get rid of those pesky frame pointers. Once you have a kernel built with ORC, you need to extract the ORC data from the kernel image. Thankfully, the kernel’s objtool program has the ability to do that, with the command objtool orc dump. To start using this program, with a clean Linux source tree you can run:
为了实际从内核中获取 ORC 信息,我们首先需要使用 ORC 信息编译内核。在 x86_64 上,这现在是默认设置。您需要确保使用 CONFIG_UNWINDER_ORC=y 配置源代码树,并且还需要禁用 CONFIG_UNWINDER_FRAME_POINTER 和 CONFIG_FRAME_POINTER 以摆脱那些讨厌的帧指针。一旦您使用 ORC 构建了内核,您需要从内核映像中提取 ORC 数据。幸运的是,内核的 objtool 程序具有执行此操作的能力,使用命令 objtool orc dump。要开始使用此程序,请使用干净的 Linux 源代码树运行:
$ make -C tools objtool
$ tools/objtool/objtool -h
Using the vmlinux file from your kernel build (or from a kernel debuginfo RPM), we can extract the ORC information:
使用您的内核构建(或内核 debuginfo RPM)中的 vmlinux 文件,我们可以提取 ORC 信息:
$ tools/objtool/objtool orc dump path/to/vmlinux >orc-dump.txt
This is a textual format which looks something like this:
这是一个文本格式,类似于这样:
.text+325d: sp:(und) bp:(und) type:call end:0
.text+3260: sp:sp+8 bp:(und) type:call end:0
.text+3262: sp:sp+16 bp:(und) type:call end:0
.text+3267: sp:sp+24 bp:(und) type:call end:0
.text+326b: sp:sp+32 bp:prevsp-32 type:call end:0
.text+326f: sp:sp+40 bp:prevsp-32 type:call end:0
.text+3273: sp:sp+96 bp:prevsp-32 type:call end:0
.text+331d: sp:sp+40 bp:prevsp-32 type:call end:0
.text+331e: sp:sp+32 bp:prevsp-32 type:call end:0
.text+331f: sp:sp+24 bp:(und) type:call end:0
.text+3321: sp:sp+16 bp:(und) type:call end:0
.text+3323: sp:sp+8 bp:(und) type:call end:0
These fields contain information necessary to compute the values of RSP, RBP, and RIP from before the current function call. For simplicity, we’ll call those PREV_RSP, PREV_RBP and PREV_RIP respectively. The “sp” field gives information on how to compute PREV_RSP, and the “bp” field gives information on how to compute PREV_RBP. We can compute PREV_RIP based on the PREV_RSP value, which I’ll get to in a moment.
这些字段包含计算当前函数调用之前 RSP、RBP 和 RIP 值所需的信息。为简单起见,我们分别称它们为 PREV_RSP、PREV_RBP 和 PREV_RIP。"sp" 字段提供了计算 PREV_RSP 的信息,"bp" 字段提供了计算 PREV_RBP 的信息。我们可以根据 PREV_RSP 值计算 PREV_RIP,稍后我会讲到。
To better understand how to use these records, let’s consider the unwinding algorithm. For frame pointer unwinds, it is simple: start at the top stack frame (i.e. the deepest). Dereference the RBP value to find the next RBP value, etc, until you find one which doesn’t fit – then you’re done. For the ORC algorithm, we also start at the top of the stack, with the current register values. The unwinder follows these steps at each frame, which can be found in the kernel’s unwinder implementation:
为了更好地理解如何使用这些记录,让我们考虑展开算法。对于帧指针展开,它很简单:从顶部堆栈帧(即最深处)开始。解引用 RBP 值以查找下一个 RBP 值,以此类推,直到找到一个不适合的值为止,然后完成。对于 ORC 算法,我们也从堆栈顶部开始,使用当前寄存器值。展开器在每个帧中执行以下步骤,可以在内核的展开器实现中找到:
Lookup the ORC record corresponding to the instruction in question. Each of the lines above corresponds to one ORC record. Each record is associated with an instruction offset, and the records are kept in sorted order. A record is valid starting from the instruction offset listed, until the next record.
查找与所讨论的指令对应的 ORC 记录。上面的每一行对应一个 ORC 记录。每个记录与一个指令偏移量相关联,并且记录按排序顺序保留。记录从所列出的指令偏移量开始有效,直到下一个记录。
Compute the PREV_RSP value using the sp field, which will specify a starting register and an offset. Simply add the register value and offset to get the PREV_RSP value.
使用 sp 字段计算 PREV_RSP 值,该字段将指定起始寄存器和偏移量。只需将寄存器值和偏移量相加即可获得 PREV_RSP 值.
During normal function calls, RIP is pushed to the stack, which means it is written to RSP - 8. Thus, we can find the value for PREV_RIP by looking at whatever value was stored in the stack at address PREV_RSP - 8. I’ll use the notation of *(PREV_RSP - 8) to show that we’re actually reading the value out of the stack, like dereferencing a pointer in C.
在正常的函数调用期间,RIP 被推送到堆栈中,这意味着它被写入 RSP - 8。因此,我们可以通过查看存储在地址 PREV_RSP - 8 处的堆栈中的任何值来找到 PREV_RIP 的值。我将使用 *(PREV_RSP - 8) 的符号表示我们实际上正在从堆栈中读取值,就像在 C 中解引用指针一样。
Finally, we also compute PREV_RBP by using the bp field. When RBP is not being used as a frame pointer, the x86_64 ABI requires that it be preserved across functions (this is, it is callee-saved). Thus, the bp field tells us the location that RBP was pushed to, so it requires reading a value out of the stack (just like PREV_RIP, but different from computing PREV_RSP). So, if the bp field says bp:prevsp-32, then we would compute PREV_RBP = *(PREV_RSP - 32). It’s also possible for the bp field to be undefined, in which case the register was not pushed to the stack and it stayed the same during the function call.
最后,我们还使用 bp 字段计算 PREV_RBP。当 RBP 不被用作帧指针时,x86_64 ABI 要求它在函数之间保留(即它是被调用者保存的)。因此,bp 字段告诉我们 RBP 被推到的位置,因此需要从堆栈中读取一个值(与计算 PREV_RSP 不同,但与计算 PREV_RIP 不同)。因此,如果 bp 字段说 bp:prevsp-32,则我们将计算 PREV_RBP = *(PREV_RSP - 32)。bp 字段也可能未定义,在这种情况下,寄存器未被推入堆栈并且在函数调用期间保持不变。
It may seem a bit odd that we’re computing the previous value of RBP. It turns out that some stack frames still use frame pointers. There are likely several reasons for this. One may be that they are useful for the compiler when a function has many local variables. But another crucial reason is that the kernel just-in-time compiles code (for instance, eBPF code) which uses frame pointers. It would be a pain for these just-in-time compilers to also emit ORC entries for these functions.
我们计算 RBP 的上一个值可能看起来有点奇怪。事实证明,一些堆栈帧仍然使用帧指针。可能有几个原因。一个可能是当函数有许多本地变量时,它们对编译器很有用。但是另一个关键原因是内核 JIT 编译代码(例如,eBPF 代码)使用帧指针。这些 JIT 编译器也为这些函数发出 ORC 条目会很麻烦。
Unwinding an ORC Stack
Let’s now use this algorithm to unwind another example stack. For this example, I crashed a kernel in the same way as before, except this kernel, while based on UEK6, had frame pointers disabled, and ORC unwinder enabled. As it crashed, the kernel log contained the following information about the KASLR offset:
让我们现在使用这个算法来展开另一个示例堆栈。对于这个示例,我以与之前相同的方式崩溃了一个基于UEK6的内核,但是这个内核禁用了帧指针,并启用了ORC展开器。当它崩溃时,内核日志包含有关KASLR偏移量的以下信息:
[80253.572504] Kernel Offset: 0x2d000000 from 0xffffffff81000000 (relocation range: 0xffffffff80000000-0xffffffffbfffffff)
Since we need to lookup instruction offsets within orc-dump.txt, we’ll need to use this offset at each step to convert KASLR addresses to the .text offset. In this case, we got really lucky. The offset is 0xffffffffae000000, and you may notice that the last 6 digits are all 0. Since all the code offsets are 6 digits or less, we can actually just examine the last 6 digits of any RIP value in order to get the .text offset, which saves us some subtraction. Note that this was just by chance: you might not get this lucky every time.
由于我们需要在orc-dump.txt中查找指令偏移量,因此我们需要在每个步骤中使用此偏移量将KASLR地址转换为.text偏移量。在这种情况下,我们非常幸运。偏移量为0xffffffffae000000,您可能会注意到最后6位数字都是0。由于所有代码偏移量都小于6位数字,因此我们实际上只需检查任何RIP值的最后6位数字即可获得.text偏移量,这样可以节省一些减法。请注意,这只是偶然的:您可能不会每次都这么幸运。
Without further ado, here’s the stack and starting register values for this crash:
话不多说,这是此崩溃的堆栈和起始寄存器值:
RIP: ffffffffae2f1da3
RSP: ffffa764404a3bb8
RBP: 0000000000000002
Stack Memory Dump:
ffffa764404a3bd0: ffffa764404a3d20 0000000000000000
ffffa764404a3be0: ffffa764404a3c70 ffffa764404a3c68
ffffa764404a3bf0: ffff9b6618da0160 ffff9b65324539c0
ffffa764404a3c00: ffffffffae2e07d2 ffffa764404a3c64
ffffa764404a3c10: ffff9b652eb9da88 0000000000000081
ffffa764404a3c20: 6a3cd98592691a00 ffffa764404a3d20
ffffa764404a3c30: 0000000000000000 0000000000000000
ffffa764404a3c40: ffff9b662fd5c020 0000000000000000
ffffa764404a3c50: 0000000000000002 ffffffffae2e15a8
ffffa764404a3c60: ffffffffc08b9521 0000000000000000
ffffa764404a3c70: 0000000000000000 6a3cd98592691a00
ffffa764404a3c80: 6a3cd98592691a00 ffffa764404a3d20
ffffa764404a3c90: ffffa764404a3d10 ffffa764404a3e48
ffffa764404a3ca0: ffff9b662fd5c020 0000000000000000
ffffa764404a3cb0: 0000000000000002 ffffffffae2e259d
ffffa764404a3cc0: ffffffffffffffc3 ffffffffae3b5256
ffffa764404a3cd0: ffffa764404a3da8 ffffa764404a3d58
ffffa764404a3ce0: 0000000000000000 6a3cd98592691a00
ffffa764404a3cf0: 0000000000000004 ffff9b662fd5c000
ffffa764404a3d00: 0000000000000004 ffffa764404a3e48
ffffa764404a3d10: ffffa764404a3e30 ffffffffae2e6bc0
ffffa764404a3d20: ffff9b6618da0160 ffff9b65324539c0
ffffa764404a3d30: 0000000b60e803be ffff9b662fd5c020
ffffa764404a3d40: 0000000000000000 0000000000000018
ffffa764404a3d50: ffff9b652eb9da88 0000000200000044
ffffa764404a3d60: 0000e5500000191a 0000000000000000
ffffa764404a3d70: ffffa76400000000 ffffa764404a3d80
ffffa764404a3d80: 0000000000000018 ffffffffae2cd3a2
ffffa764404a3d90: 00007fffc52f6fd0 0000000000000fe0
ffffa764404a3da0: 0000000000000fe0 ffff9b662fd5c020
ffffa764404a3db0: ffffffffae480db7 ffff9b662fd5c000
ffffa764404a3dc0: 00007fffc52f6fd0 0000000000000000
ffffa764404a3dd0: 0000000000000004 ffffa764404a3e98
ffffa764404a3de0: ffff9b662fd5c000 0000000000000000
ffffa764404a3df0: 0000000000000004 ffffff9cffffff9c
ffffa764404a3e00: ffffa764404a3e48 6a3cd98592691a00
ffffa764404a3e10: 0000000000000004 00000000ffffff9c
ffffa764404a3e20: 00007fffc52f6fd0 ffffa764404a3e98
ffffa764404a3e30: 0000000000000100 ffffffffae2d9d34
ffffa764404a3e40: 0000000000000fe0 0000000000000fe0
ffffa764404a3e50: ffff9b662fd5c020 6a3cd98592691a00
ffffa764404a3e60: 00007fffc52f6eb0 ffffa764404a3f58
ffffa764404a3e70: 0000000000000000 0000000000000000
ffffa764404a3e80: 0000000000000000 0000000000000000
ffffa764404a3e90: ffffffffae2dadb0 ffffa764404a3e98
ffffa764404a3ea0: ffffa764404a3e98 ffffa764404a3f58
ffffa764404a3eb0: 00000000c000003e 0000000000000000
ffffa764404a3ec0: ffffffffae003b78 0000000000000000
ffffa764404a3ed0: 0000000000000000 ffffffffae175c29
ffffa764404a3ee0: 0000000000000080 ffffa764404a3f58
ffffa764404a3ef0: ffffa764404a3f58 0000000000000000
ffffa764404a3f00: 0000000000000000 6a3cd98592691a00
ffffa764404a3f10: 000000000000014c ffffa764404a3f58
ffffa764404a3f20: 6a3cd98592691a00 000000000000014c
ffffa764404a3f30: ffffffffae2dae10 ffffffffae0043bb
ffffa764404a3f40: 0000000000000000 0000000000000000
ffffa764404a3f50: ffffffffaea001b8 000055ceb29f9778
Let’s follow the steps of the ORC unwinder. We know the RSP, RIP, and RBP values. To unwind one frame, we need to compute the previous values of each. And in order to do that, we need the ORC record corresponding with RIP=ffffffffae2f1da3. We know that this is .text offset 0x2f1da3, and when we search for the matching ORC entry, we find this one:
让我们按照ORC展开器的步骤进行操作。我们知道RSP、RIP和RBP的值。为了展开一个帧,我们需要计算每个值的前一个值。为了做到这一点,我们需要与RIP=ffffffffae2f1da3相对应的ORC记录。我们知道这是.text偏移量0x2f1da3,当我们搜索匹配的ORC条目时,我们找到了这个:
.text+2f1d03: sp:sp+80 bp:prevsp-48 type:call end:0
Notice that this record is for .text+2f1d03, but we were looking for offset 2f1da3. As I mentioned earlier, ORC records are valid starting from the offset they contain, up until the next ORC entry. This is the last record with offset less than or equal to the RIP value, so it is the one we should use. Now, we can compute PREV_RSP:
请注意,此记录是针对.text+2f1d03的,但我们正在寻找偏移量2f1da3。正如我之前提到的,ORC记录从它们包含的偏移量开始有效,一直到下一个ORC条目。这是最后一个偏移量小于或等于RIP值的记录,因此它是我们应该使用的记录。现在,我们可以计算PREV_RSP:
PREV_RSP = RSP + 80
= 0xffffa764404a3bb8 + 80 = 0xffffa764404a3c08
Now that we know PREV_RSP, we know that PREV_RIP is stored on the stack 8 bytes below it:
既然我们知道了PREV_RSP,我们知道PREV_RIP存储在它下面8个字节的堆栈中:
PREV_RIP = *(PREV_RSP - 8)
= *(0xffffa764404a3c08 - 8)
= *(0xffffa764404a3c00) = 0xffffffffae2e07d2
And finally, the ORC entry says that PREV_RBP was pushed to an address 48 bytes below PREV_RSP, so we can compute it:
最后,ORC条目表示PREV_RBP被推到PREV_RSP下面48个字节的地址,因此我们可以计算它:
PREV_RBP = *(PREV_RSP - 48)
= *(0xffffa764404a3c08 - 48)
= *(0xffffa764404a3c08 - 48)
= *(0xffffa764404a3bd8) = 0x0000000000000000
And that’s it! We have unwound one stack frame. We computed PREV_RSP, PREV_RIP, and PREV_RBP. These will now become RSP, RIP, and RBP, respectively, and we’ll continue the unwind. I’ll summarize the register state and the computations for the each of the next unwind steps below:
就是这样!我们展开了一个堆栈帧。我们计算了PREV_RSP、PREV_RIP和PREV_RBP。它们现在将分别成为RSP、RIP和RBP,并且我们将继续展开。我将在下面总结每个下一步展开的寄存器状态和计算:
RSP: ffffa764404a3c08 RIP: ffffffffae2e07d2
RBP: 0000000000000000
.text offset: 0x2e07d2
.text+2e07a0: sp:sp+88 bp:prevsp-48 type:call end:0
PREV_RSP = RSP + 88
= 0xffffa764404a3c08 + 88 = 0xffffa764404a3c60
PREV_RIP = *(PREV_RSP - 8)
= *(0xffffa764404a3c60 - 8)
= *(0xffffa764404a3c58) = 0xffffffffae2e15a8
PREV_RBP = *(PREV_RSP - 48)
= *(0xffffa764404a3c60 - 48)
= *(0xffffa764404a3c30) = 0x0000000000000000
RSP: ffffa764404a3c60 RIP: ffffffffae2e15a8
RBP: 0000000000000000
.text offset: 0x2e15a8
.text+2e1579: sp:sp+96 bp:prevsp-48 type:call end:0
PREV_RSP = RSP + 96
= 0xffffa764404a3c60 + 96 = 0xffffa764404a3cc0
PREV_RIP = *(PREV_RSP - 8)
= *(0xffffa764404a3cc0 - 8)
= *(0xffffa764404a3cb8) = 0xffffffffae2e259d
PREV_RBP = *(PREV_RSP - 48)
= *(0xffffa764404a3cc0 - 48)
= *(0xffffa764404a3c90) = 0xffffa764404a3d10
RSP: ffffa764404a3cc0 RIP: ffffffffae2e259d
RBP: ffffa764404a3d10
.text offset: 0x2e259d
.text+2e2539: sp:bp+16 bp:prevsp-16 type:call end:0
PREV_RSP = RBP + 16
= 0xffffa764404a3d10 + 16 = 0xffffa764404a3d20
PREV_RIP = *(PREV_RSP - 8)
= *(0xffffa764404a3d20 - 8)
= *(0xffffa764404a3d18) = 0xffffffffae2e6bc0
PREV_RBP = *(PREV_RSP - 16)
= *(0xffffa764404a3d20 - 16)
= *(0xffffa764404a3d10) = 0xffffa764404a3e30
Let me pause here to point out something interesting. For the first several frames, we were simply subtracting offsets from RSP to compute PREV_RSP. But in this most recent stack frame, the ORC entry read sp:bp+16, so we actually used RBP to help us compute the next stack frame. What’s more, bp:prevsp-16 means that we computed PREV_RBP = *(PREV_RSP - 16) = *(RBP + 16 - 16) = *RBP. And also, to get PREV_RIP, we computed *(PREV_RSP - 8) = *(RBP + 16 - 8) = *(RBP + 8).
让我在这里暂停一下,指出一些有趣的事情。在前几个帧中,我们只是从RSP中减去偏移量来计算PREV_RSP。但是在最近的堆栈帧中,ORC条目读取sp:bp+16,因此我们实际上使用了RBP来帮助我们计算下一个堆栈帧。更重要的是,bp:prevsp-16意味着我们计算PREV_RBP = *(PREV_RSP - 16) = *(RBP + 16 - 16) = RBP。而且,为了获得PREV_RIP,我们计算(PREV_RSP - 8) = *(RBP + 16 - 8) = *(RBP + 8)。
If you think back to the frame-pointer based unwind, we simply dereferenced each RBP value to get the previous RBP, and we looked at the value one word higher on the stack to find the corresponding RIP value. The computations we did in this stack frame are the exact same. In other words, this stack frame actually uses a frame pointer! And the ORC entry sp:bp+16 bp:prevsp-16 is a shorthand for doing a frame-pointer based unwind using the ORC algorithm. The kernel’s unwinder even defines a helper variable containing this entry, for use in code which it knows was compiled with frame pointers.
如果您回想一下基于帧指针的展开,我们只需解引用每个RBP值即可获得前一个RBP,并查看堆栈上更高的一个字来找到相应的RIP值。我们在这个堆栈帧中所做的计算是完全相同的。换句话说,这个堆栈帧实际上使用了帧指针!而ORC条目sp:bp+16 bp:prevsp-16是使用ORC算法进行基于帧指针的展开的简写。内核的展开器甚至定义了一个包含此条目的帮助变量,供它知道使用帧指针编译的代码使用。
The unwind continues:
展开继续:
RSP: ffffa764404a3d20 RIP: ffffffffae2e6bc0
RBP: 0xffffa764404a3e30
.text offset: 0x2e6bc0
sp:bp+16 bp:prevsp-16 type:call end:0
PREV_RSP = RBP + 16
= 0xffffa764404a3e30 + 16 = 0xffffa764404a3e40
PREV_RIP = *(PREV_RSP - 8)
= *(0xffffa764404a3e40 - 8)
= *(0xffffa764404a3e38) = 0xffffffffae2d9d34
PREV_RBP = *(PREV_RSP - 16)
= *(0xffffa764404a3e40 - 16)
= *(0xffffa764404a3e30) = 0x0000000000000100
RSP: ffffa764404a3e40 RIP: ffffffffae2d9d34
RBP: 000000000000100
.text offset: 0x2d9d34
.text+2d9cd3: sp:sp+88 bp:prevsp-48 type:call end:0
PREV_RSP = RSP + 88
= 0xffffa764404a3e40 + 88 = 0xffffa764404a3e98
PREV_RIP = *(PREV_RSP - 8)
= *(0xffffa764404a3e98 - 8)
= *0xffffa764404a3e90 = 0xffffffffae2dadb0
PREV_RBP = *(PREV_RSP - 48)
= *(0xffffa764404a3e98 - 48)
= *(0xffffa764404a3e68) = 0xffffa764404a3f58
RSP: ffffa764404a3e98 RIP: ffffffffae2dadb0
RBP: ffffa764404a3f58
.text offset: 0x2dadb0
.text+2dad7d: sp:sp+160 bp:(und) type:call end:0
PREV_RSP = RSP + 160
= 0xffffa764404a3e98 + 160
= 0xffffa764404a3f38
PREV_RBP = 0xffffa764404a3f58
PREV_RIP = *(PREV_RSP - 8)
= *(0xffffa764404a3f38 - 8)
= *(0xffffa764404a3f30) = 0xffffffffae2dae10
Here we encounter the entry bp:(und). This “undefined” value actually means that the frame pointer was not pushed to the stack or changed since the previous stack frame, so we continue with PREV_RBP = RBP.
在这里,我们遇到了bp:(und)条目。这个“未定义”的值实际上意味着帧指针自上一个堆栈帧以来没有被推到堆栈上或更改,因此我们继续使用PREV_RBP = RBP。
RSP: ffffa764404a3f38 RIP: ffffffffae2dae10
RBP: ffffa764404a3f58
.text offset: 0x2dae10
.text+2dadf0: sp:sp+8 bp:(und) type:call end:0
PREV_RSP = RSP + 8
= 0xffffa764404a3f38 + 8
= 0xffffa764404a3f40
PREV_RBP = 0xffffa764404a3f58
PREV_RIP = *(PREV_RSP - 8)
= *(0xffffa764404a3f40 - 8)
= *0xffffa764404a3f38 = 0xffffffffae0043bb
RSP: ffffa764404a3f40 RIP: ffffffffae0043bb
.text offset: 0x43bb
.text+436a: sp:sp+24 bp:prevsp-16 type:call end:0
PREV_RSP = RSP + 24
= 0xffffa764404a3f40 + 24
= 0xffffa764404a3f58
PREV_RBP = *(PREV_RSP - 16)
= *(ffffa764404a3f58 - 16)
= *(ffffa764404a3f48) = 0x0000000000000000
PREV_RIP = *(PREV_RSP - 8)
= *(0xffffa764404a3f58 - 8)
= *(0xffffa764404a3f50) = 0xffffffffaea001b8
RSP: ffffa764404a3f58 RIP: ffffffffaea001b8
RBP: 0000000000000000
.text offset: 0xa001b8
.text+a001a8: sp:sp+0 bp:(und) type:regs end:0
The is the last stack frame: the ORC entry shows, rather than type:call, that it is of type:regs. This means that the entry corresponds to a register dump (a struct pt_regs in the kernel). Since our stack corresponds to a system call, we’ve reached the part of the stack where the kernel dumped the userspace registers, and there is no further for us to unwind.
这是最后一个堆栈帧:ORC条目显示,而不是type:call,它是type:regs。这意味着该条目对应于一个寄存器转储(内核中的struct pt_regs)。由于我们的堆栈对应于系统调用,因此我们已经到达了内核转储用户空间寄存器的部分,我们没有进一步展开的必要。
Now, we can go ahead and gather all of the RIP values from the unwind. Since we ended up removing the KASLR offset from them as part of the unwind, I’ll just list the .text offsets here:
现在,我们可以继续收集展开中的所有RIP值。由于我们在展开过程中从中删除了KASLR偏移量,因此我在这里只列出.text偏移量:
0x2f1da3
0x2e07d2
0x2e15a8
0x2e259d
0x2e6bc0
0x2d9d34
0x2dadb0
0x2dae10
0x43bb
0xa001b8
Using a similar addr2line command as above, we can convert this list of addresses into a real stack trace:
使用与上面类似的addr2line命令,我们可以将这个地址列表转换为真正的堆栈跟踪:
$ addr2line -e vmlinux-5.4.17-2136.304.4.1.OLB3_133.el8uek.dev.x86_64 \
-j .text -ipfas \
0x2f1da3 0x2e07d2 0x2e15a8 0x2e259d 0x2e6bc0 0x2d9d34 \
0x2dadb0 0x2dae10 0x43bb 0xa001b8
0x00000000002f1da3: read_word_at_a_time at compiler.h:350
(inlined by) dentry_string_cmp at dcache.c:252
(inlined by) dentry_cmp at dcache.c:406
(inlined by) __d_lookup_rcu at dcache.c:2672
0x00000000002e07d2: lookup_fast at namei.c:1659
0x00000000002e15a8: walk_component at namei.c:1909
0x00000000002e259d: path_lookupat at namei.c:2433
0x00000000002e6bc0: filename_lookup at namei.c:2463
0x00000000002d9d34: vfs_statx at stat.c:198
0x00000000002dadb0: do_statx at stat.c:582
0x00000000002dae10: __do_sys_statx at stat.c:604
(inlined by) __se_sys_statx at stat.c:599
(inlined by) __x64_sys_statx at stat.c:599
0x00000000000043bb: do_syscall_64 at common.c:296
0x0000000000a001b8: entry_SYSCALL_64_after_hwframe at entry_64.S:188
As expected, this got us pretty much the same call stack! The only difference being that addr2line found some inline functions to unwind which it didn’t before.
正如预期的那样,这几乎得到了相同的调用堆栈!唯一的区别是addr2line找到了一些内联函数来展开,而之前没有找到。
This example definitely doesn’t explore all of the possibilities of a stack unwinder using ORC. ORC entries can reference more than just RBP and RSP registers, and have more types than the regs and call illustrated here. This simple example just serves to illustrate the overall idea of ORC, and should serve as a reference if you decide to unwind your own ORC stack. The unwinder implementation within the kernel is well written and, with some study, shouldn’t be too difficult to understand. You can find it below:
这个例子肯定没有探索ORC使用堆栈展开器的所有可能性。ORC条目可以引用不止RBP和RSP寄存器,并且具有比这里所示的regs和call更多的类型。这个简单的例子只是为了说明ORC的总体思想,并应作为参考,如果您决定展开自己的ORC堆栈,它应该是一个很好的参考。内核中的展开器实现编写得很好,经过一些学习,应该不难理解。您可以在以下位置找到它:
arch/x86/include/asm/orc_types.h contains the definition of struct orc_entry, which corresponds to one line from the objtool orc dump output.
arch/x86/include/asm/orc_types.h 包含struct orc_entry的定义,它对应于objtool orc dump输出的一行。
arch/x86/kernel/unwind_orc.c contains the code that implements the ORC unwind.
arch/x86/kernel/unwind_orc.c 包含实现ORC展开的代码。
Quantifying the Benefits
Now that we’ve seen ORC in action, let’s reexamine some of the claimed benefits of removing frame pointers. While unwinding the ORC stack, we saw that two functions still ended up using frame pointers (their ORC entries were sp:bp+16 bp:prevsp-16). These happened to be the functions path_lookupat() and filename_lookup(). I’m not certain why this happened! It does make you wonder, why bother disabling frame pointers, if the compiler might still decide to add them in? Is there really any benefit? So I decided to compare the two kernel examples, to answer two questions:
既然我们已经看到了ORC的实际应用,让我们重新审视一些去除帧指针的声称好处。在展开ORC堆栈时,我们发现两个函数仍然使用帧指针(它们的ORC条目是sp:bp+16 bp:prevsp-16)。这恰好是函数path_lookupat()和filename_lookup()。我不确定为什么会这样!这确实让你想知道,如果编译器可能仍然决定添加它们,为什么要禁用帧指针?真的有什么好处吗?因此,我决定比较这两个内核示例,以回答两个问题:
-
Did eliminating frame pointers really reduce stack usage?
去除帧指针是否真的减少了堆栈使用? -
Did eliminating frame pointers reduce the number of instructions in the kernel?
去除帧指针是否减少了内核中的指令数?
For the first question, I compared the stack pointers of both crashing stacks. These stacks should end on a page boundary, so I computed the difference between the stack pointer and the end of the page, to determine how many bytes of stack were in use at the time of the crash:
对于第一个问题,我比较了两个崩溃堆栈的堆栈指针。这些堆栈应该以页面边界结束,因此我计算了堆栈指针与页面末尾之间的差异,以确定在崩溃时使用了多少字节的堆栈:
Kernel with Frame Pointers: ffff9b4e8057bb50 (end of page: 0xffff9b4e8057c000)
1200 bytes stack
Kernel with ORC : ffffa764404a3bb8 (end of page: 0xffffa764404a4000)
1096 bytes stack
In our example, the ORC kernel was using 104 fewer bytes of stack at the time of the crash. This is actually a fairly impressive decrease of around 8.7%. A typical cache line is 64 bytes, so the stack already used one fewer cache line. For more complex and CPU intensive operations, the improvement would likely be more noticeable.
在我们的例子中,ORC内核在崩溃时使用的堆栈少了104个字节。这实际上是一个相当令人印象深刻的减少,约为8.7%。一个典型的缓存行是64字节,因此堆栈已经使用了一个较少的缓存行。对于更复杂和CPU密集型的操作,改进可能会更加明显。
For the second question, one way to answer this subjectively is to compare function disassembly. Let’s compare the first few lines of code for the same function:
对于第二个问题,一个主观的回答方法是比较函数反汇编的前几行。让我们比较同一个函数的前几行代码:
Kernel with Frame Pointers:
crash> dis lookup_fast | head -n 5
0xffffffff990fb340 <lookup_fast>: nopl 0x0(%rax,%rax,1) [FTRACE NOP]
0xffffffff990fb345 <lookup_fast+5>: push %rbp
0xffffffff990fb346 <lookup_fast+6>: mov %rsp,%rbp
0xffffffff990fb349 <lookup_fast+9>: push %r15
0xffffffff990fb34b <lookup_fast+11>: push %r14
Kernel with ORC:
crash> dis lookup_fast | head -n 5
0xffffffffae2e0780 <lookup_fast>: nopl 0x0(%rax,%rax,1) [FTRACE NOP]
0xffffffffae2e0785 <lookup_fast+5>: push %r15
0xffffffffae2e0787 <lookup_fast+7>: push %r14
0xffffffffae2e0789 <lookup_fast+9>: push %r13
0xffffffffae2e078b <lookup_fast+11>: mov %rdx,%r13
We can see plain as day that the instructions push %rbp; mov %rsp, %rbp are missing in the ORC kernel. The ORC version uses fewer instructions because it is not managing the frame pointer. But some other functions do still use frame pointers. To get a sense for the overall change in code size, we can use the tool scripts/bloat-o-meter which comes with the kernel. I get the following result:
我们可以清楚地看到,在ORC内核中缺少指令push %rbp; mov %rsp, %rbp。ORC版本使用的指令更少,因为它不管理帧指针。但是其他一些函数仍然使用帧指针。为了了解代码大小的总体变化,我们可以使用内核附带的工具scripts/bloat-o-meter。我得到以下结果:
$ scripts/bloat-o-meter vmlinux-fp vmlinux-orc
add/remove: 21/11 grow/shrink: 3826/42026 up/down: 37651/-398389 (-360738)
Function old new delta
unwind_next_frame 25 1480 +1455
orc_find.part - 461 +461
fbcon_bmove_rec - 457 +457
unwind_init - 387 +387
hidinput_configure_usage 15166 15540 +374
... around 45,800 lines of output ...
process_measurement 2781 2276 -505
load_image_lzo 3502 2992 -510
unwind_next_frame.part 519 - -519
usb_get_configuration.cold 2944 2421 -523
usb_get_configuration 7887 7058 -829
Total: Before=32225110, After=31864372, chg -1.12%
The script shows some overall statistics, and also lists out every function’s size change. 3826 functions increased in size, and 42k decreased. The overall net decrease in code size was 360,738 bytes, or about 1.12%.
该脚本显示了一些总体统计信息,并列出了每个函数的大小变化。3826个函数的大小增加了,而42k个函数的大小减小了。代码大小的总体净减少量为360,738字节,约为1.12%。
Of course, to be fair, this decrease was achieved by adding just under 4MiB of ORC records to the kernel image, an addition which dwarfs the roughly 360KiB code size decrease. But the major benefit to this decrease is not overall memory size, but a decrease in instruction cache footprint. ORC data is rarely used, and does not need to remain in the instruction cache, while these functions do.
当然,为了公平起见,这种减少是通过向内核映像添加将近4MiB的ORC记录来实现的,这种添加使大约360KiB的代码大小减少相形见绌。但是这种减少的主要好处不是总体内存大小,而是指令缓存占用的减少。ORC数据很少使用,不需要保留在指令缓存中,而这些函数需要保留在指令缓存中。
Conclusion
In this article we manually unwound two nearly identical x86_64 kernel stacks using two different algorithms: a frame-pointer unwind and ORC unwind. While the ORC unwind is more complex, it is still feasible to do by hand. It is this simplicity which allows the kernel to include builtin ORC unwind capabilities, and thus to eliminate frame pointers. And, as we’ve seen, removing frame pointers means code that uses fewer registers and instructions, resulting in a smaller cache footprint and runtime speedups.
在本文中,我们使用两种不同的算法手动展开了两个几乎相同的x86_64内核堆栈:帧指针展开和ORC展开。虽然ORC展开更复杂,但仍然可以手动完成。正是这种简单性使得内核可以包含内置的ORC展开功能,从而消除帧指针。正如我们所看到的,去除帧指针意味着使用更少的寄存器和指令的代码,从而导致更小的缓存占用和运行时加速。
Thankfully, many kernel debugging tools (e.g. crash, and the kernel itself) have builtin support for unwinding with ORC, or its older sibling DWARF, so it would be an exceptional circumstance if you needed to perform this manual process for yourself. But sometimes kernel debugging produces just these sort of exceptional circumstances, so it’s good to be aware of the possibilities. If nothing else, I hope this example sheds light on what ORC does and how it does it, without dwelling on the drier details.
值得庆幸的是,许多内核调试工具(例如crash和内核本身)都内置了对ORC或其较老的兄弟DWARF的展开支持,因此如果您需要为自己执行此手动过程,那将是一个特殊情况。但有时内核调试会产生这种特殊情况,因此了解可能性是很好的。如果没有其他的,我希望这个例子能够阐明ORC的作用及其工作原理,而不是过多地关注干燥的细节。
本文来自博客园,作者:摩斯电码,未经同意,禁止转载

