MySQL高级SQL语句(3)

---- 算排名 ----
表格自我连结(Self Join),然后将结果依序列出,算出每一行之前(包含那一行本身)有多少行数
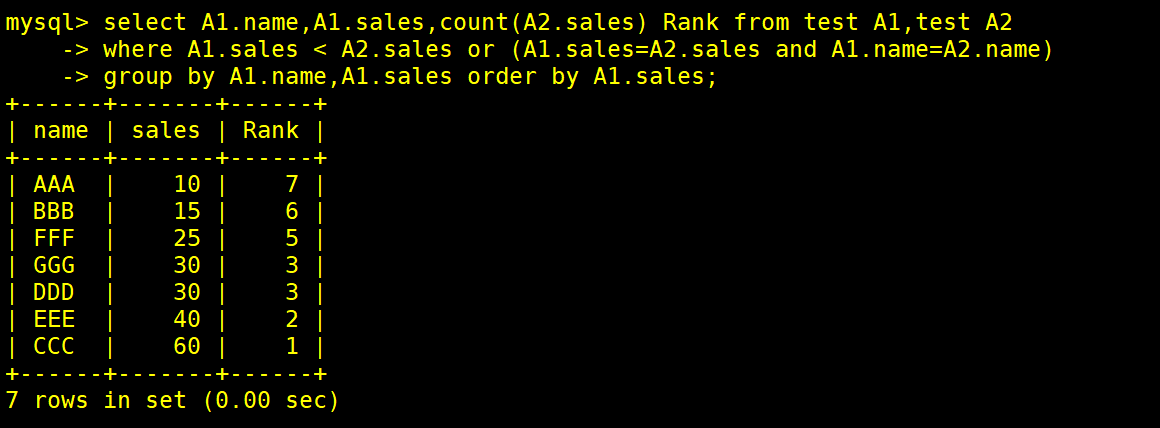
select A1.name,A1.sales,count(A2.sales) Rank from test A1,test A2
where A1.sales < A2.sales or (A1.sales=A2.sales and A1.name=A2.name)
group by A1.name,A1.sales order by A1.sales desc;
解析:
当A1sales字段比A2sales字段小,或者两表字段名相等时,显示A1name字段和sales字段和A2sales字段别名rank非空的值,并为A1name字段和sales字段分组降序显示A1sales字段
##A1sales为10,A2sales可为10,15,25,30,30,40,60则count(A2.sales)值为7
##A1sales为15,A2sales可为15,25,30,30,40,60则count(A2.sales)值为6
##A1sales为25,A2sales可为25,30,30,40,60则count(A2.sales)值为5
。。。。。。。。。。。。。。

---- 算中位数 ----
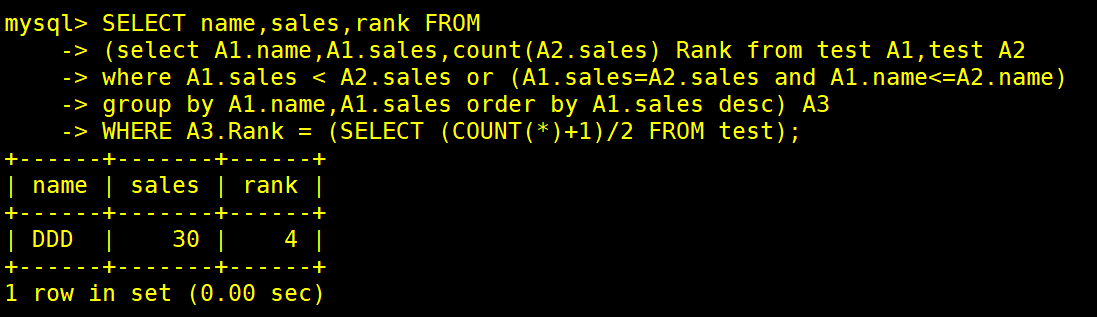
SELECT name,sales,rank FROM
(select A1.name,A1.sales,count(A2.sales) Rank from test A1,test A2
where A1.sales < A2.sales or (A1.sales=A2.sales and A1.name<=A2.name)
group by A1.name,A1.sales order by A1.sales desc) A3
WHERE A3.Rank = (SELECT (COUNT(*)+1) DIV 2 FROM test);
解析:
#每个派生表必须有自己的别名,所以别名A3必须要有
#DIV是在MySQL中算出商的方式符号/也可以
#SELECT name,sales,rank FROM里面这些字段都没加表名默认用的是from后面的表名也就是A3
#先执行内查询的语句也就是排名,因为防止中位数的序号在并列排名中跳过所以就取消了并列排名
#将内查询的结果也就是排名后的表定义给派生表A3
#where语句A3表的rank字段值为内查询取(原表test的列数+1)/2为4即中间列,count(*)会显示所有列的行数,不论是否存在null即总行数,但是奇数行得出的商会是一个X.5,所以需要+1
#最后显示的就是rank=4字段的数据内容
CREATE VIEW V_1 AS select A1.name,A1.sales,count(A2.sales) Rank from test A1,test A2 where A1.sales < A2.sales or (A1.sales=A2.sales and 1.name<=A2.name)
group by A1.name,A1.sales order by A1.sales desc;
SELECT Name, Sales Middle FROM V_1 WHERE Rank = (SELECT (CoUNT(*)+1) DIV 2 FROM V_1);
#也可以先将统计的排名值创建一个视图,再在视图进行进一步的操作

---- 算累积总计 ----
表格自我连结(Self Join),然后将结果依序列出,算出每一行之前 (包含那一行本身)的总和
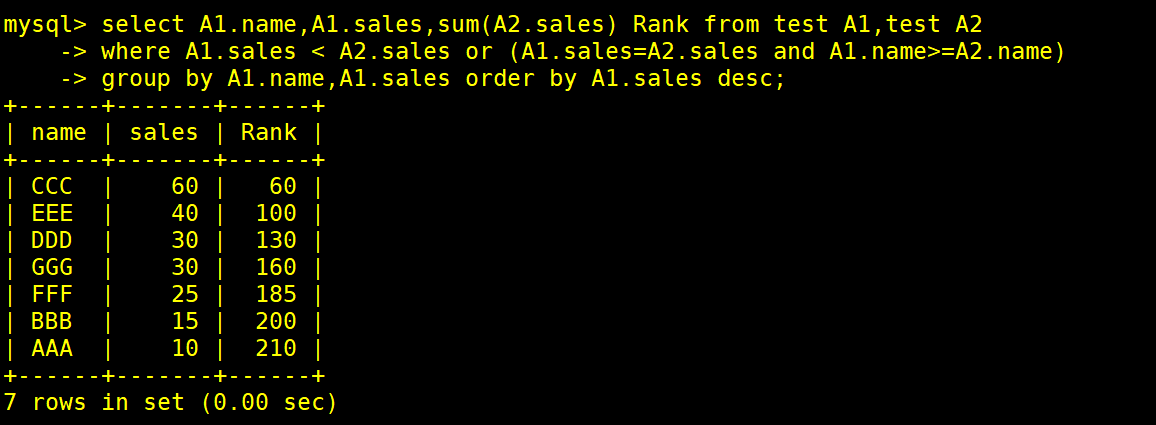
select A1.name,A1.sales,sum(A2.sales) Rank from test A1,test A2
where A1.sales < A2.sales or (A1.sales=A2.sales and A1.name>=A2.name)
group by A1.name,A1.sales order by A1.sales desc;
解析:
当A1sales字段比A2sales字段小,或者两表sales字段相对,name值不等时=时,显示A1name字段和sales字段和A2sales字段别名rank非空的值,并为A1name字段和sales字段分组降序显示A1sales字段
##A1sales为60,A2sales可为60则sum(A2.sales)值为60
##A1sales为40,A2sales可为40,60则sum(A2.sales)值为100
##A1sales为30,A2sales可为30,40,60则sum(A2.sales)值为130
。。。。。。。。。。。。。。
---- 算总合百分比 ----
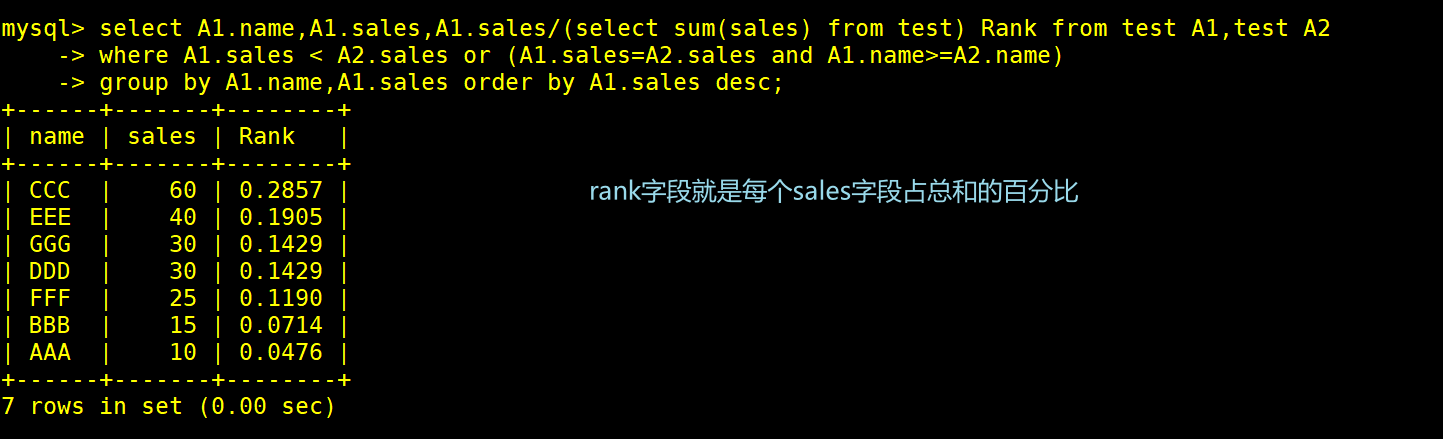
select A1.name,A1.sales,A1.sales/(select sum(sales) from test) Rank from test A1,test A2
where A1.sales < A2.sales or (A1.sales=A2.sales and A1.name>=A2.name)
group by A1.name,A1.sales order by A1.sales desc;
解析:
#select sum(sales) from test这一段子查询是用来算出总合
#总合算出后,我们就能够将每一行除以总合来求出每一行的总合百分比
####进一步优化显示
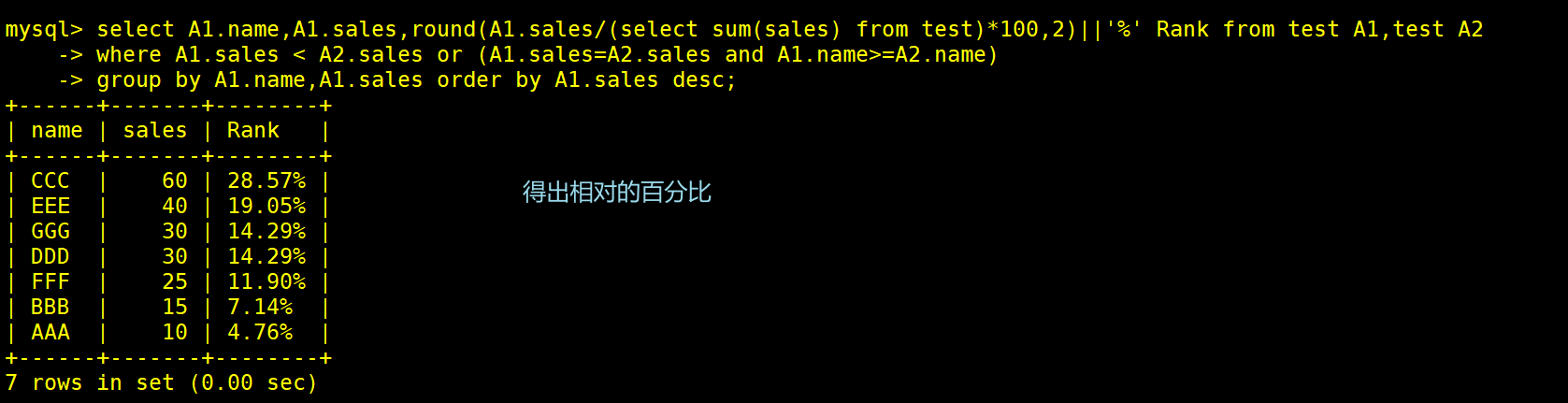
select A1.name,A1.sales,round(A1.sales/(select sum(sales) from test)*100,2)||'%' Rank from test A1,test A2
where A1.sales < A2.sales or (A1.sales=A2.sales and A1.name>=A2.name)
group by A1.name,A1.sales order by A1.sales desc;
解析:
#round(A1.sales/(select sum(sales) from test)*100,2)||'%':里面子查询得出之前的值例如(0.2857)将这个值X100就说28.57
#ronnd(28.57,2):取小数点后两位也就是28.57,可以根据需求设置
#28.57 || '%':拼接符,将两个数据拼接在一起,因为%在SQL语句有特殊含义,所以要用单引号括起来
---- 空值(NULL)和无值('')的区别 ----
1.无值的长度为 0,不占用空间的; 而NULL值的长度是 NULL,是占用空间的。
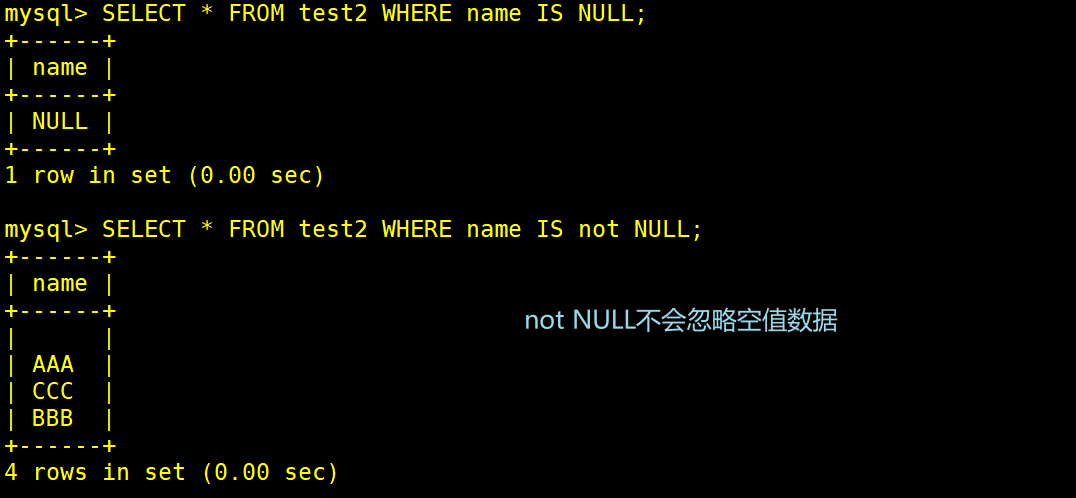
2. IS NULL或者IS NOT NULL,是用来判断字段是不是为 NULL 或者不是 NULL,不能查出是不是无值的。
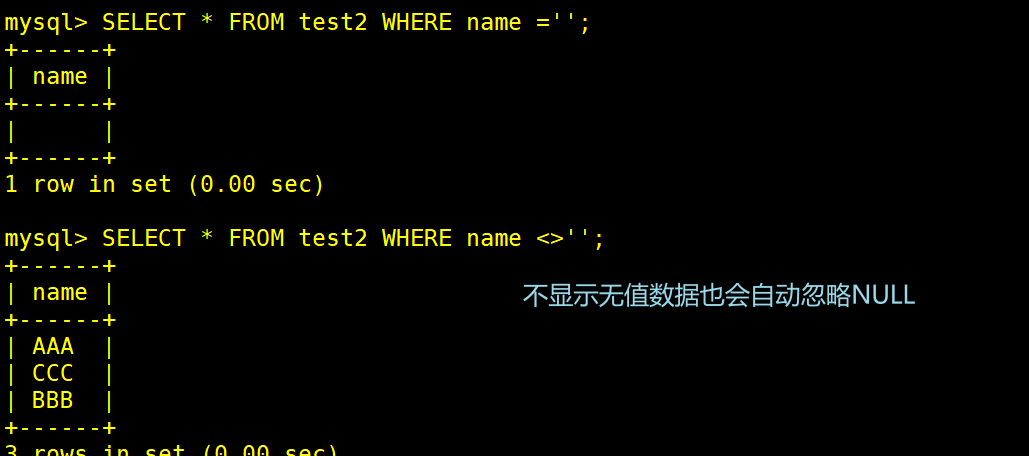
3.无值的判断使用=''或者<>''来处理。<> 代表不等于,会自动会略NULL。
4.在通过 count()指定字段统计有多少行数时,如果遇到 NUL 值会自动忽略掉,遇到无值会加入到记录中进行计算。

SELECT length (NULL),length(''),length('1');

SELECT * FROM test2 WHERE name IS NULL;
SELECT * FROM test2 WHERE name IS NOT NUL;
SELECT * FROM test2 WHERE name = '';
SELECT * FROM test2 WHERE name <> '';
SELECT COUNT(*) FROM test2;
SELECT COUNT(name) FROM test2;

---- 正则表达式 ----
|
匹配模式 |
描述 |
实例 |
|
^ |
匹配文本的开始字符 |
`^bd′匹配以 bd 开头的字符串 |
|
$ |
匹配文本的结束字符 |
`qn$'匹配以 qn 结尾的字符串 |
|
. |
匹配任何单个字符 |
's.t'匹配任何s和t之间有一个字符的字符串 |
|
* |
匹配零个或多个在它前面的字符 |
'fo*t'匹配 t前面有任意个o |
|
+ |
匹配前面的字符 1 次或多次 |
'hom+'匹配以ho开头,后面至少一个m的字符串 |
|
字符串
|
匹配包含指定的字符串 |
'clo'匹配含有clo的字符串 |
|
p1|p2 |
匹配 p1 或 p2 |
'bg|fg'匹配bg或者fg |
|
[....] |
匹配字符集合中的任意一个字符一次 |
'[abc]'匹配a或者b或者c |
|
[^....] |
匹配不在括号中的任何字符 |
'[^ab]'匹配不包含a或者b的字符串 |
|
{n} |
匹配前面的字符串n次 |
'g{2}'匹配含有2个g的字符串 |
|
{n,m} |
匹配前面的字符串至少 n 次,至多m 次 |
'f{1,3}'匹配f最少1次,最多3次
|
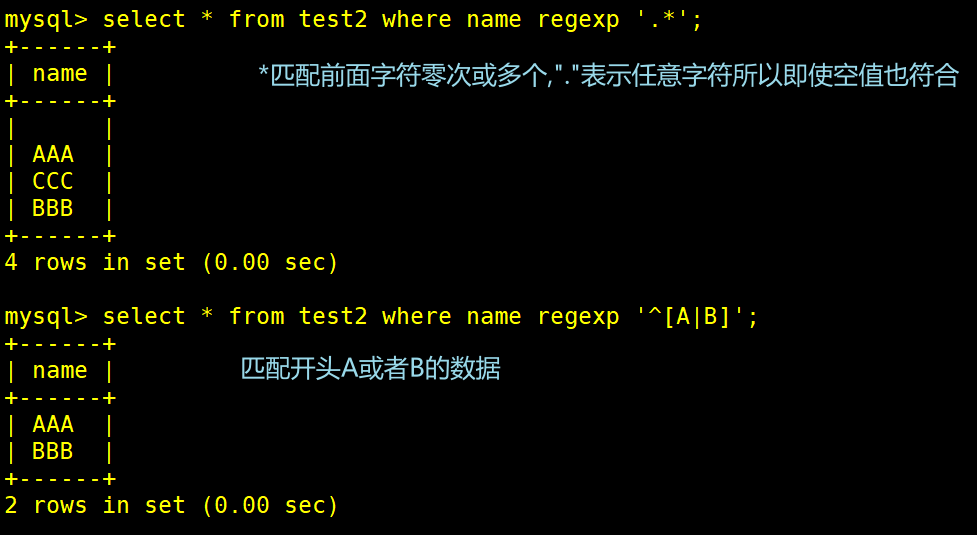
语法∶ SELECT "字段" FROM "表名"WHERE "字段" REGEXP '模式';
SELECT* FROM Store Info WHERE Store Name REGEXP '.*';
SELECT * FROM Store Info WHERE Store Name REGEXP '^[A-B]';
---- 存储过程 ----
存储过程是一组为了完成特定功能的SOL语句集合。
存储过程在使用过程中是将常用或者复杂的工作预先使用SQL语句写好并用一个指定的名称存储起来,这个过程经编译和优化后存储在数据库服务器中。 当需要使用该存储过程时,只需要调用它即可。存储过程在执行上比传统SQL速度更快、执行效率更高。
存储过程的优点∶
1、执行一次后,会将生成的二进制代码驻留缓冲区,提高执行效率
2、SOL语句加上控制语句的集合,灵活性高
3、在服务器端存储,客户端调用时,降低网络负载
4、可多次重复被调用,可随时修改,不影响客户端调用
5、可完成所有的数据库操作,也可控制数据库的信息访问权限
##创建存储过程##
DELIMITER ## #将语句的结束符号从分号;临时改为两个##(可以是自定义)
CREATE PROCEDURE NO1() #创建存储过程,过程名为NO1,不带参数
-> BEGIN #过程体以关键字BEGIN开始
-> select * from test2; #过程体语句
-> END $$ #过程体以关键字END结束
DELIMITER ; #将语句的结束符号恢复为分号
##调用存储过程##
CALL NO1;

##查看存储过程排##
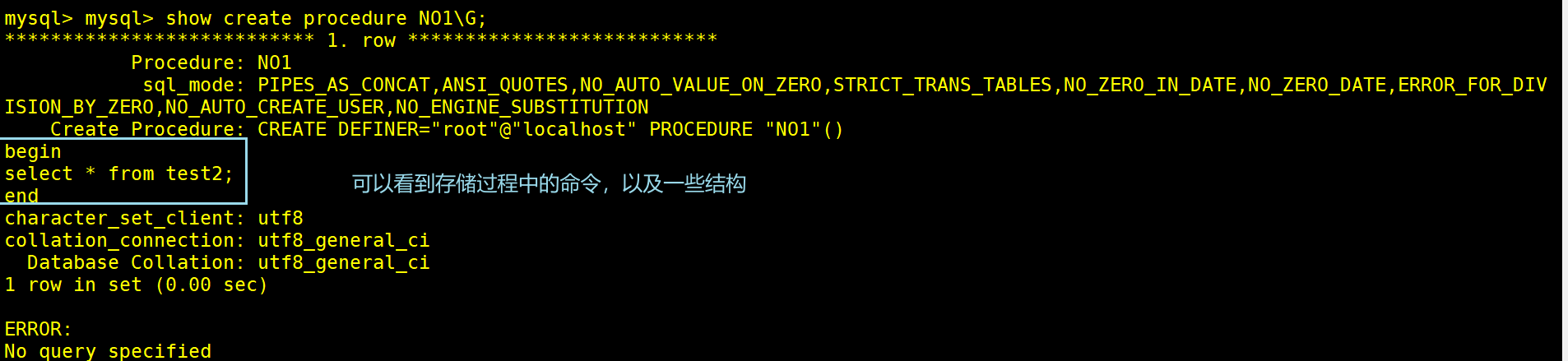
SHOW CREATE PROCEDURE [数据库.]存储过程名; #查看某个存储过程的具体信息
SHOW CREATE PROCEDURE TEST2\G;
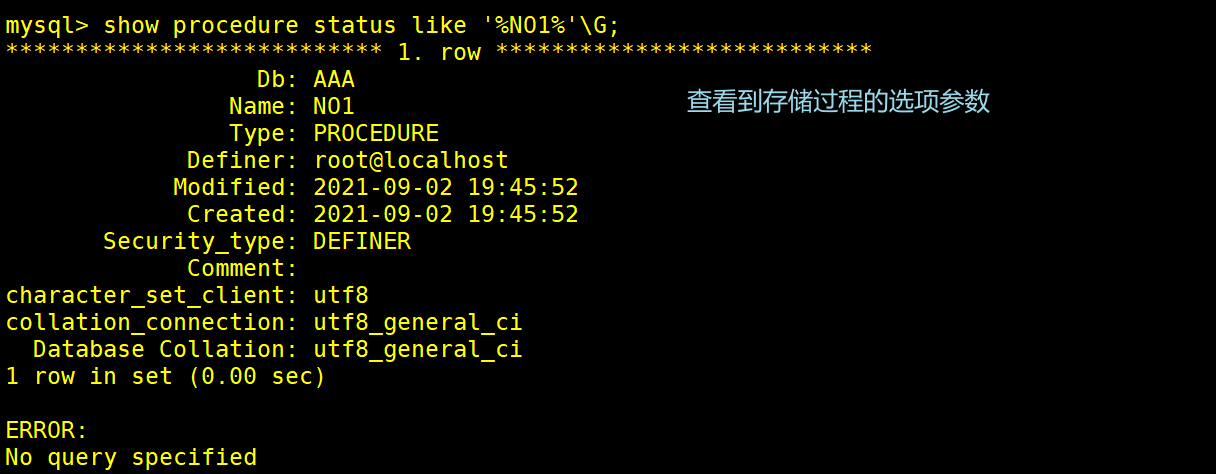
show procedure status like '%NO1%'\G; #like查询存储过程的选项信息,%代表任意字符
##存储过程的参数##
IN 输入参数∶表示调用者向过程传入值(传入值可以是字面量或变量,但必须是自定义的数据类型)
OUT 输出参数∶表示过程向调用者传出值(可以返回多个值)(传出值只能是变量)(调试使用,传入时需要加上@符号)
INOUT 输入输出参数∶既表示调用者向过程传入值,又表示过程向调用者传出值(值只能是变量)
#传入参数
DELIMITER ##
create procedure NO2(in Aname char(10),in Bname char(5)) #char数据类型,Aname为自定义的参数名,这里同时设置传入两个参数
-> begin
-> select * from test2 where name=Aname;
-> select * from test2 where name=Bname;
-> end ##
DELIMITER ;
CALL NO2('AAA','BBB '); #执行存储过程同时传入两个参数

#输出参数
mysql> DELIMITER ##
mysql> DELIMITER ##
mysql> create procedure NO4(in a int,in b int,out c int)
-> begin
-> set c=a+b;
-> end ##
mysql> delimiter ;
mysql> call NO4(1,2,@CC); #变量传入需要加上@符号
mysql> select @CC

##删除存储过程##
存储过程内容的修改方法是通过删除原有存储过程,之后再以相同的名称创建新的存储过程。
DROP PROCEDURE IF EXISTS NO4; #仅当存在时删除,不添加IF EXISTS 时,如果指定的过程不存在,则产生一个错误

##存储过程的控制语句##
create table test(name char(10),id int(10));
insert into test values('zhangsan',10);
insert into test values('zhangsan',5);

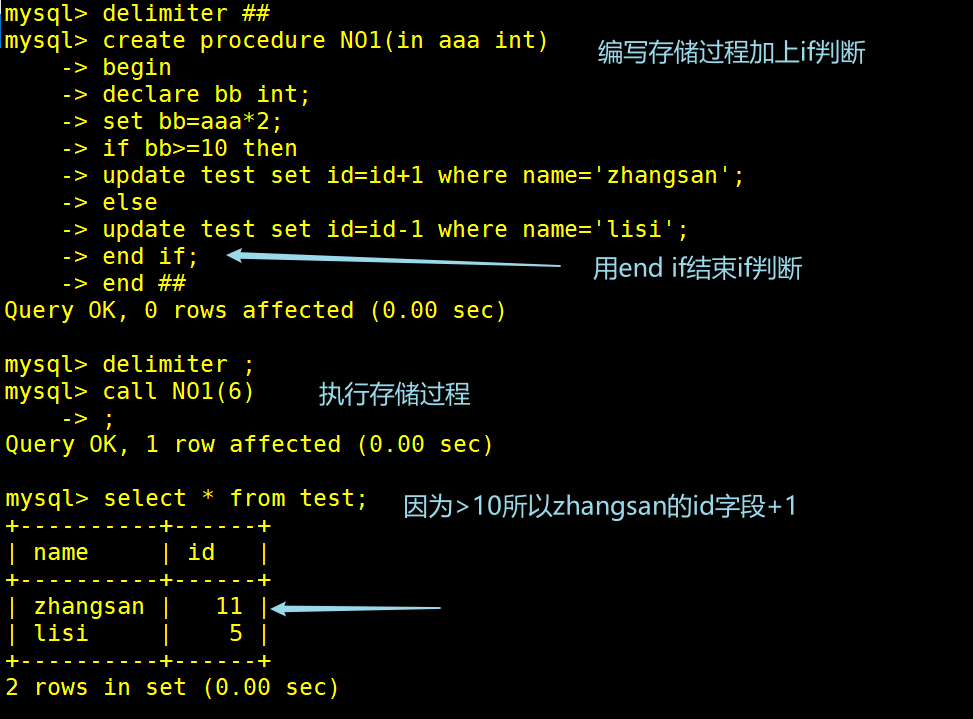
(1)条件语句if-then-else...end if
DELIMITER ##
CREATE PROCEDURE NO1(IN aaa int)
-> begin
-> declare bb int; #declare定义一个bb的变量类型为int
-> set bb=aaa*2; #设置变量bb的值为变量aaaX2
-> if bb>=10 then #如果bb值大于10
-> update test set id=id+1 where name='zhangsan'; #则将zhangsan的id+1
-> else
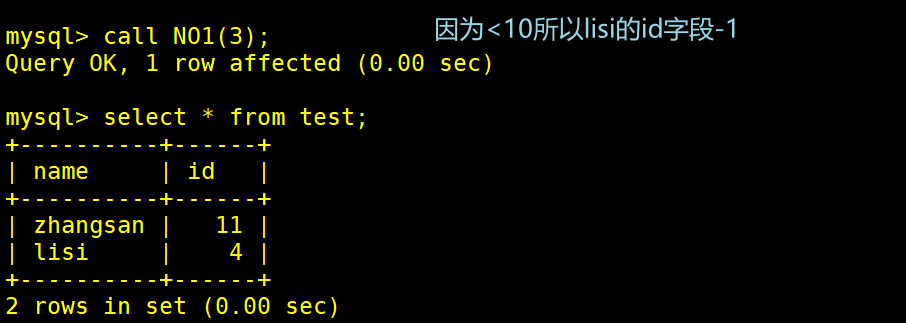
-> update test set id=id-1 where name='lisi'; #否则则将lisi的id-1
->end if;
-> end ##
DELIMITER ;
CALL NO1(6);
(2)循环语句while...end while
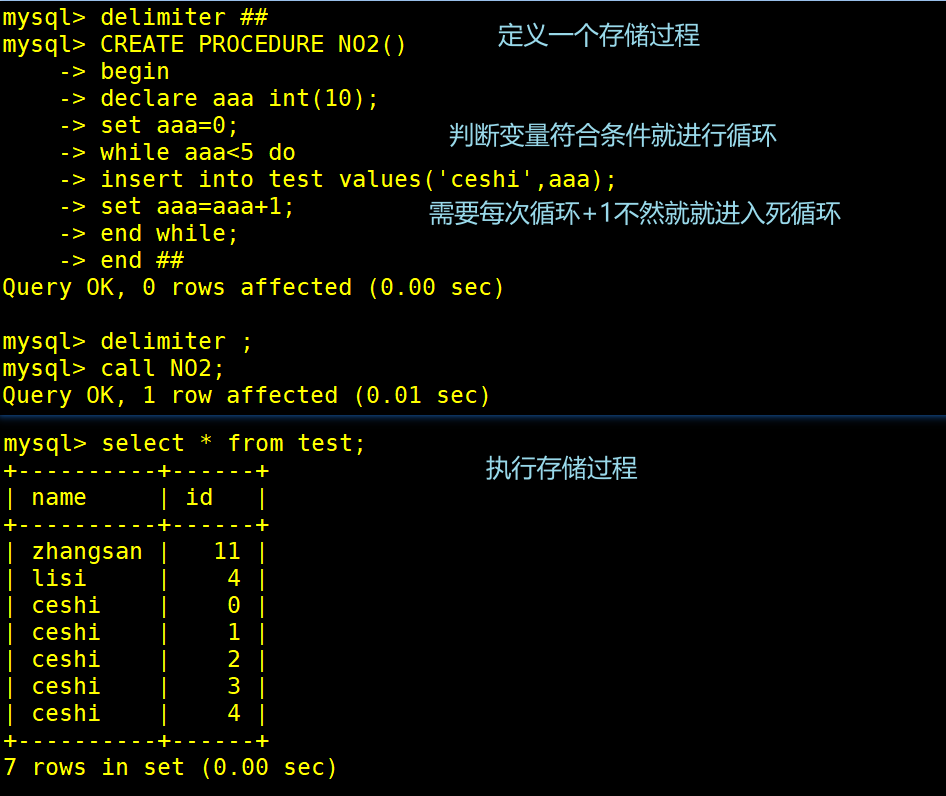
mysql> delimiter ##
mysql> CREATE PROCEDURE NO2()
-> begin
-> declare aaa int(10); #定义一个aaa的变量
-> set aaa=0; #变量aaa赋值为0
-> while aaa<5 do #如果变量aaa小于5则执行while循环语句
-> insert into test values('ceshi',aaa);
-> set aaa=aaa+1; #aaa每次+1,相当于函数的a++,为了防止死循环
-> end while; #结束循环
-> end ##
mysql> delimiter ;
mysql> call NO2;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号