MySQL高级SQL语句(2)
---- 别名 ----
栏位别名 表格别名
语法∶ SELECT "表别名"."栏位1" [AS] "栏位别名" FROM "表格名" [AS] "表别名";
#AS不输入也可以
SELECT A.Store_Name AS "name" FROM store_info AS A; #显示表别名为A以及字段Store_Name别名为name
SELECT A.Store_Name "name",SUM(A.Sales)"new" FROM store_info A GROUP BY A.Store_Name order by new desc; #将别名为A的store_info表的别名为name和new的字段进行分组并且new字段内容需要进行求和还要将new字段的结果进行降序排序

---- 子查询 ----
连接表格在WHERE子句或HAVING子句中插入另一个SQL语句,会先执行内查询的结果再将其交给外查询进一步处理
语法∶ SELECT "栏位1" FROM "表格1" WHERE "栏位2" [比较运算符] #外查询
(SELECT "栏位1" FROM "表格2" WHERE "条件"); #内查询
#可以是符号的运算符,例如 =、>、<、>=、<=;也可以是文字的运算符,例如LIKE、IN、BETWEEN
SELECT SUM(Sales) FROM store_info WHERE Store_Name IN(SELECT Store_Name FROM location WHERE Region = 'West');
#内查询得出location表中符合where条件的数据内容,这个结果作为外查询in()里的值再进行外查询,
#外查询判断store_info表中符合store_name字段有in里面的值的字段将其Sales字段内容相加求和显示
SELECT sum(A.Sales) FROM store_info A WHERE A.Store_Name IN
(SELECT B.Store_Name FROM location B WHERE B.Store_Name = A.Store_Name);
#内外查询加上别名使用显示更加清晰


--- EXISTS ----
用来测试内查询有没有产生任何结果,类似布尔值是否为真,如果没有也执行会占用服务器的资源,如果有的话,系统就会执行外查询中的SOL语句。若是没有的话,会返回null值,那整个SQL语句就不会产生任何结果。
exists(xxxxx)后面的子查询被称做相关子查询, 他是不返回列表的值的,只是返回一个ture或false的结果
not exists则是反过来,没有则执行外查询,有则返回null不执行外查询
语法∶ SELECT "栏位1" FROM "表格1" WHERE EXISTS (SELECT * FROM "表格2" WHERE "条件");
SELECT SUM(Sales) FROM store_info WHERE EXISTS
(SELECT * FROM location WHERE Region ='East'); #测试内查询是否有结果产生,如果有则继续执行

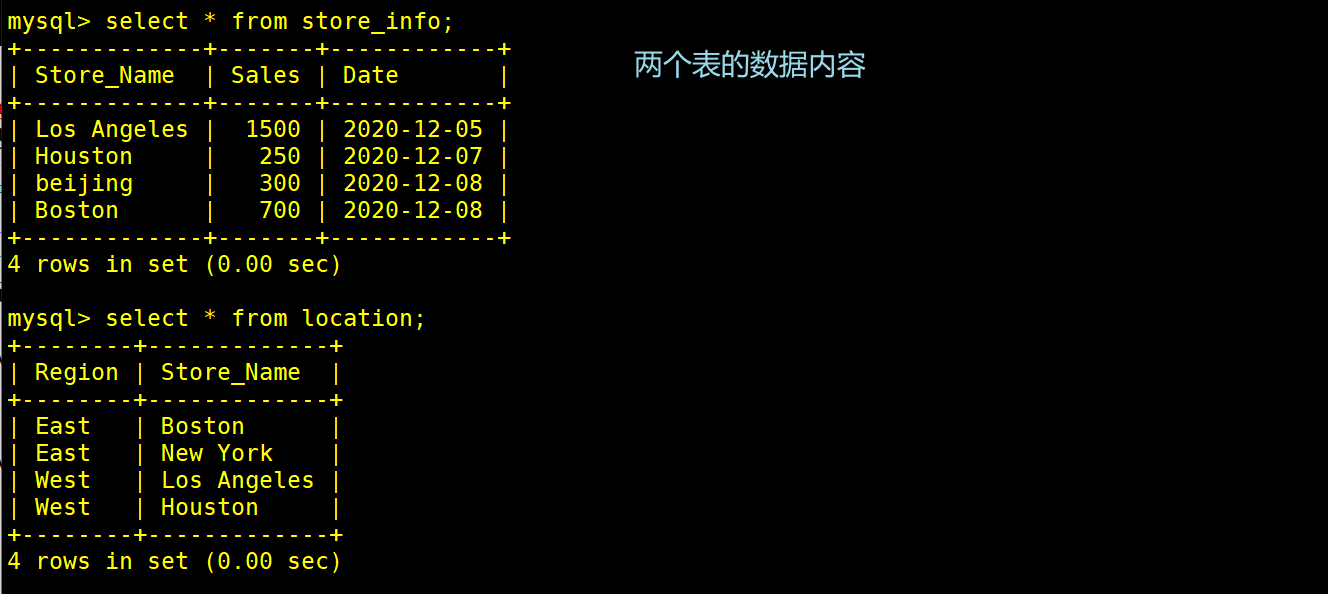
---- 连接查询 ----
将两个表的数据内容按照符合的规则进行匹配同时显示
update store_info set store_name='beijing' where sales=300; #修改表中数据
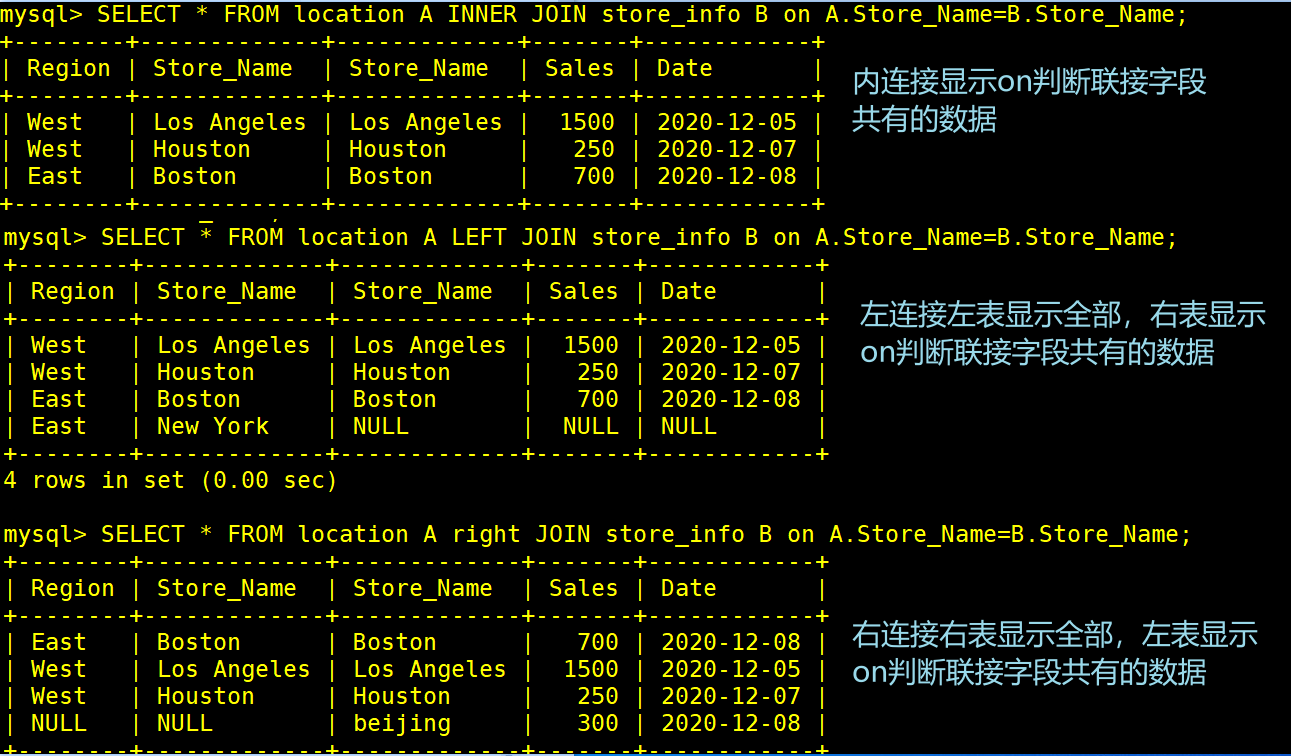
inner join(内连接)∶只返回两个表中联结字段相等的行
left join(左连接)∶返回包括左表中的所有记录和右表中联结字段相等的记录
right join(右连接)∶返回包括右表中的所有记录和左表中联结字段相等的记录
#左右连接显示全表没有交集的部分会有用null填充
#on用于在连接查询语句join中匹配条件,相当于where的作用
#使用连接查询联结字段相同的数据内容
SELECT * FROM location A INNER JOIN store_info B on A.Store_Name=B.Store_Name; #显示两个表联接字段交集的行
SELECT * FROM location A LEFT JOIN store_info B on A.Store_Name=B.Store_Name; #左表全文显示,右表只显示与左边相联字段有交集的行,其余null填充
SELECT * FROM location A RIGHT JOIN store_info B on A.Store_Name = B.Store_Name; #右表全文显示,左表只显示与右边相联字段有交集的行,其余null填充
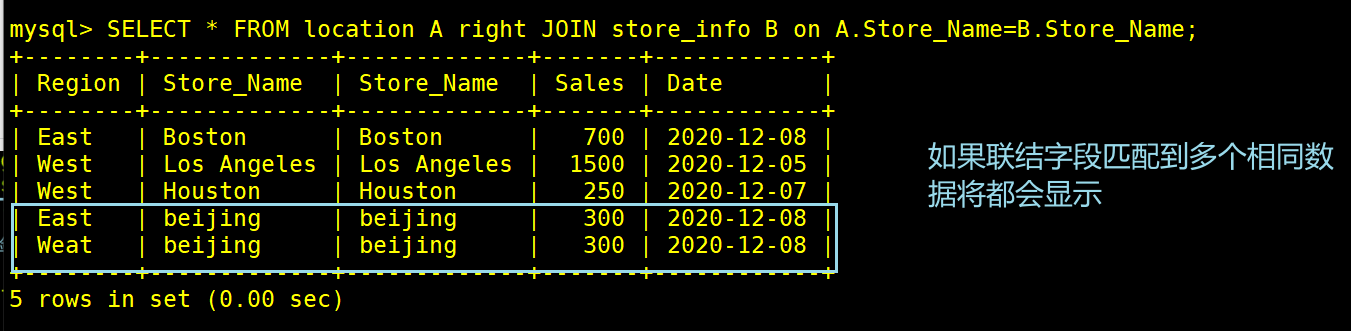
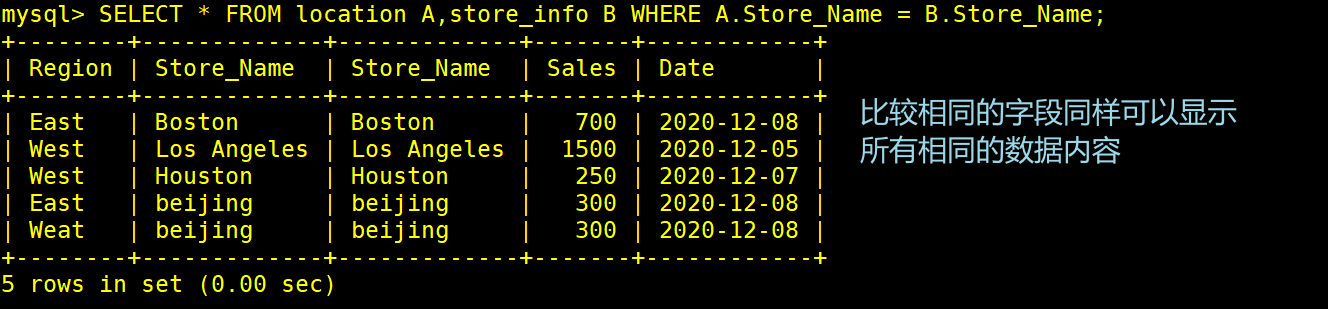
#如果是只显示两个表的交集值使用子查询的方法同样可以实现
SELECT * FROM location A,store_info B WHERE A.Store_Name = B.Store_Name; #显示where判断中A表和B表两个相同字段共有的值
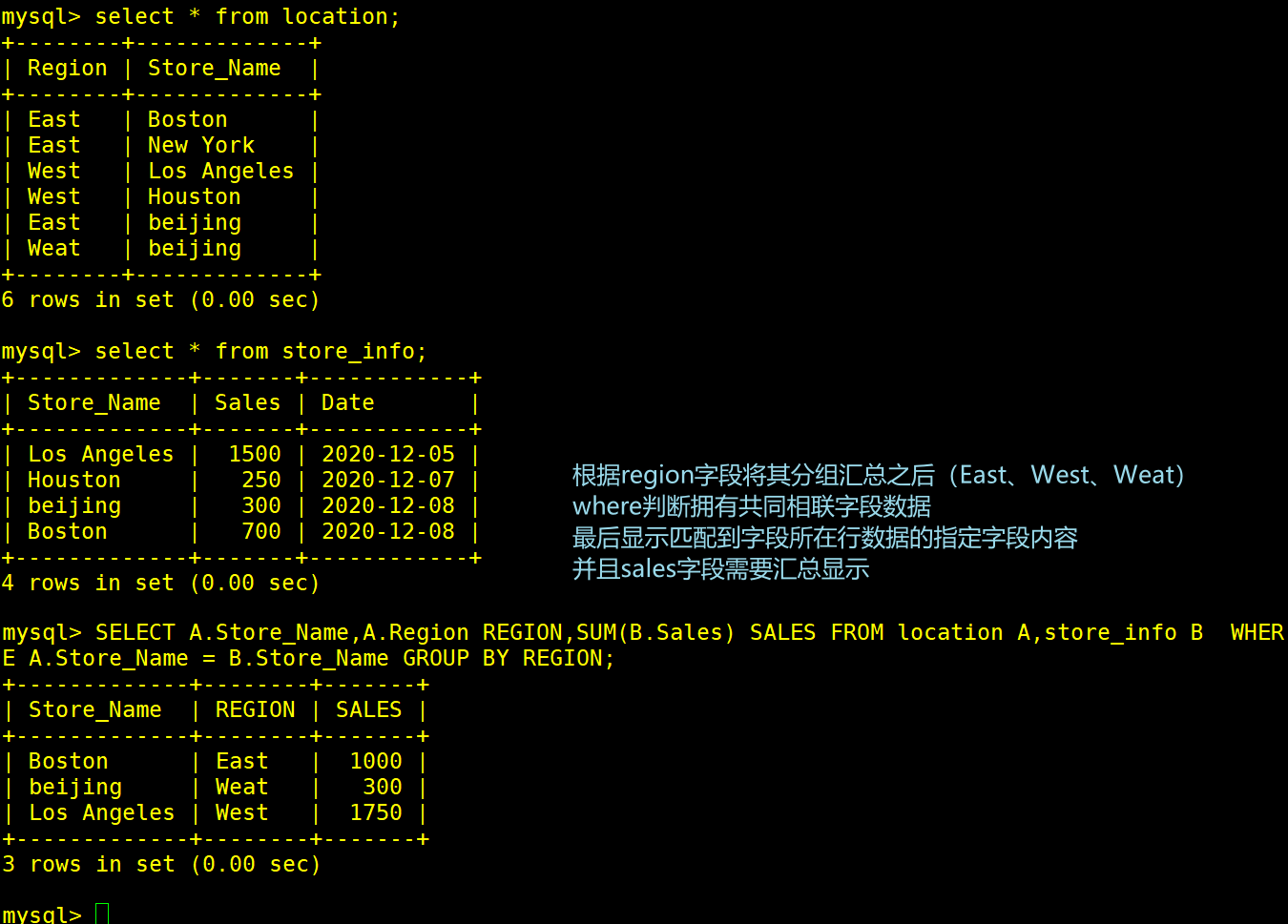
SELECT A.Store_Name,A.Region REGION,SUM(B.Sales) SALES FROM location A,store_info B WHERE A.Store_Name = B.Store_Name GROUP BY A.REGION;
#根据REGION字段分组(East、West、Weat)
#符合where的数据有Los Angeles、beijing、Bostion、houston
#将每个组里有符合的数据的sales的值进行相加就是最后显示的sales的和值
---- CREATE VIEW ----
视图,可以被当作是虚拟表或存储查询。
视图跟表格的不同是,表格中有实际储存资料,而视图是建立在表格之上的一个架构,它本身并不实际储存资料。临时表在用户退出或同数据库的连接断开后就自动消失了,而视图不会消失。
视图不含有数据,只存储它的定义,它的用途一般可以简化复杂的查询。 比如你要对几个表进行连接查询,而且还要进行统计排序等操作,写SQL语句会很麻烦的,用视图将几个表联结起来,然后对这个视图进行查询操作, 就和对一个表查询一样,很方便。
#视图定义的select语句显示的数据不能出现重复的字段
语法:CREATE VIEW"视图表名" AS "SELECT 语句";
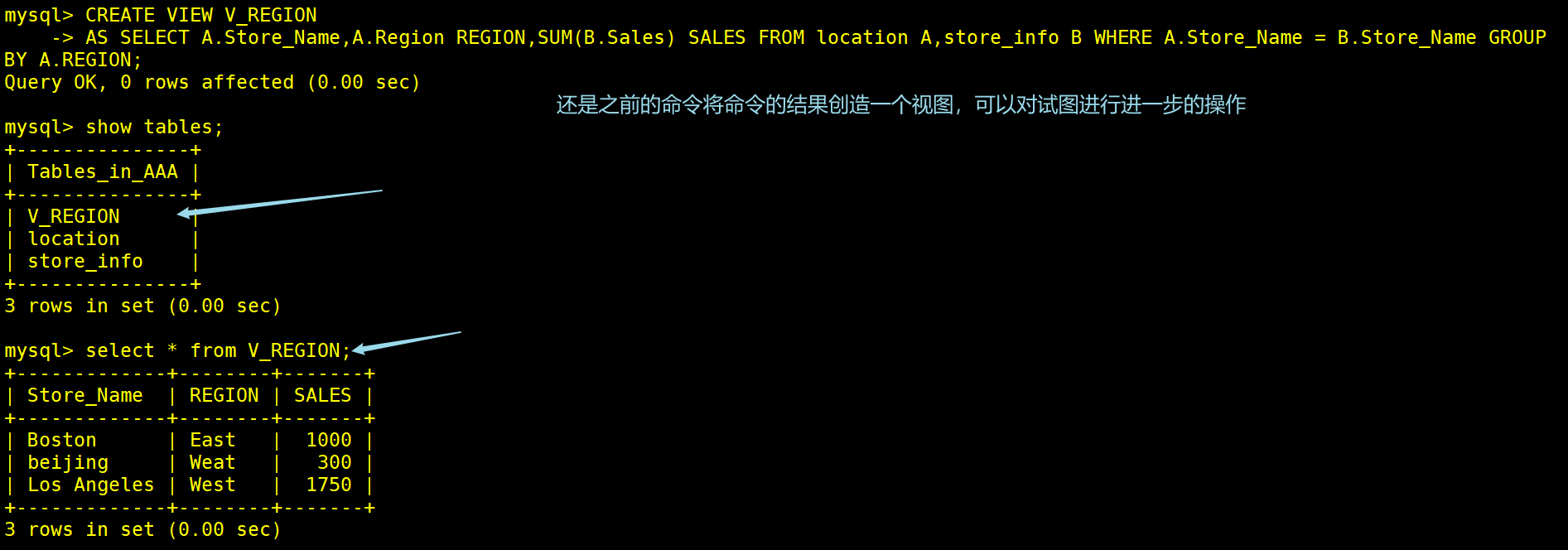
CREATE VIEW V_REGION
AS SELECT A.Store_Name,A.Region REGION,SUM(B.Sales) SALES FROM location A,store_info B WHERE A.Store_Name = B.Store_Name GROUP BY A.REGION;
SELECT * FROM V_REGION; #查看视图
DROP VIEW V_REGION_SALES; #删除视图表
#视图表不建议存储数据,因为视图表可能会涉及到多张表,不利于数据的存储,视图主要用于存储select语句执行后的结果,方便后面对select语句结果进行进一步的操作
#只涉及单张表结构没有使用过别名的视图可以插入数据,但如果涉及多张表或者使用了别名就会报错无法插入数据,所以视图表本身并不实际存储数据也不建议这么做


---- UNION ----
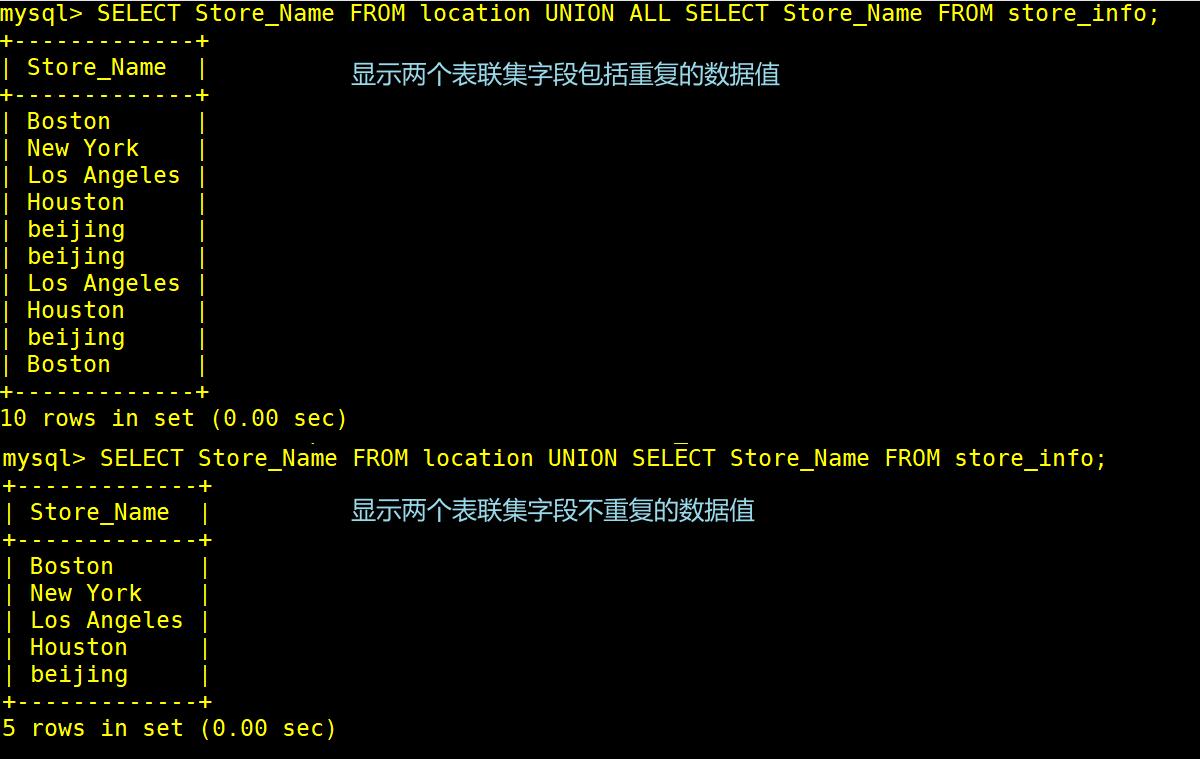
联集,将两个SQL语句的结果合并起来,两个SQL语句所产生的栏位最好是是同样的数据种类
UNION ∶ 生成结果的资料值将没有重复,且按照字段的顺序进行排序
语法∶[SELECT 语句 1] UNION [SELECT 语句 2];
UNION ALL ∶将生成结果的资料值都列出来,无论有无重复
语法∶[SELECT 语句 1] UNION ALL [SELECT 语句 2];
SELECT Store_Name FROM location UNION SELECT Store_Name FROM store_info;
SELECT Store Name FROM location UNION ALL SELECT Store Name FROM Store Info;
---- CASE ----
是SQL用来做为 IF-THEN-ELSE 之类逻辑的关键字
语法∶
SELECT CASE ("栏位名")
WHEN "条件1" THEN "结果1"
WHEN "条件2" THEN "结果2"·..
[ELSE "结果N"]
END
FROM "表名";
#"条件"可以是一个数值或是公式。ELSE子句则并不是必须的,但如果when条件没有该项,else也没有定义则会使用null值填充。
例如:
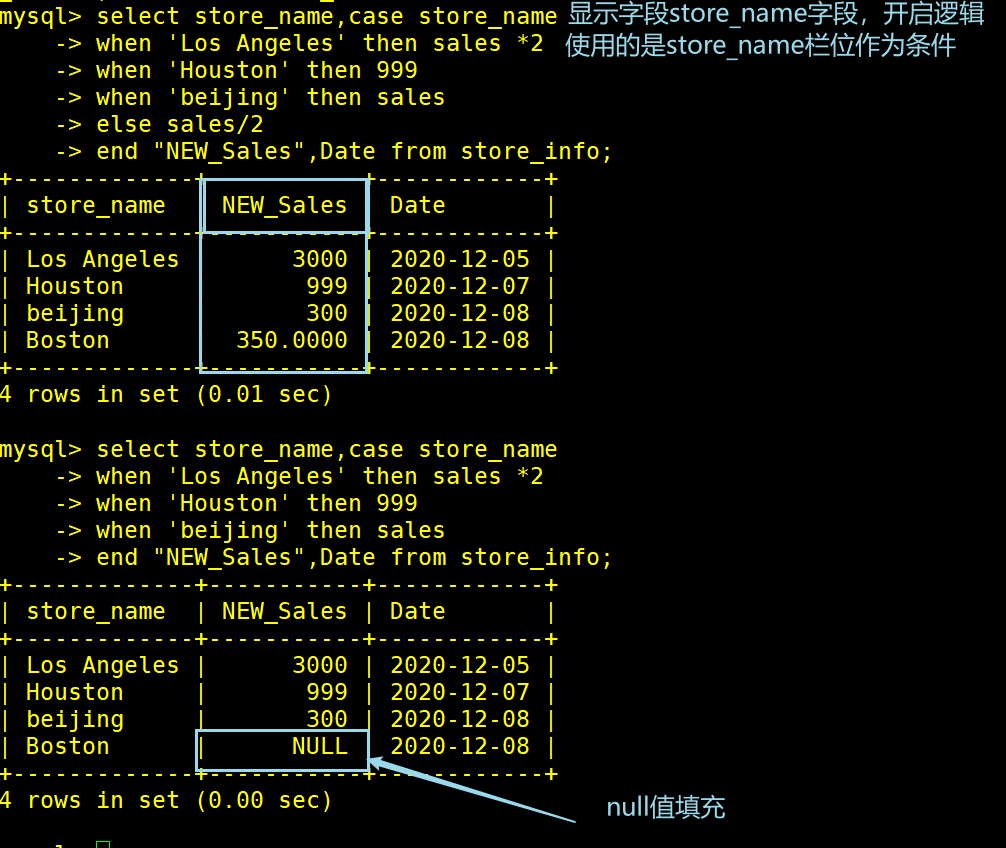
#显示store_name字段,开启一个逻辑判断以store_name字段作为条件
>select store_name,case store_name
-> when 'Los Angeles' then sales *2 #如果符合条件slaes字段值X2
-> when 'Houston' then 999 #如果符合条件slaes值直接赋予新的值999
-> when 'beijing' then sales #如果符合条件slaes值不变
-> else sales/2 #其余值/2
-> end "NEW_Sales",Date from store_info;
#"NEW_Sales"是该逻辑判断字段的别名。
#如果case字段没有定义到结果的数据会用null填充
---- 交集值 ----
取两个SQL语句结果的交集,使用时保证两个表有同名字段
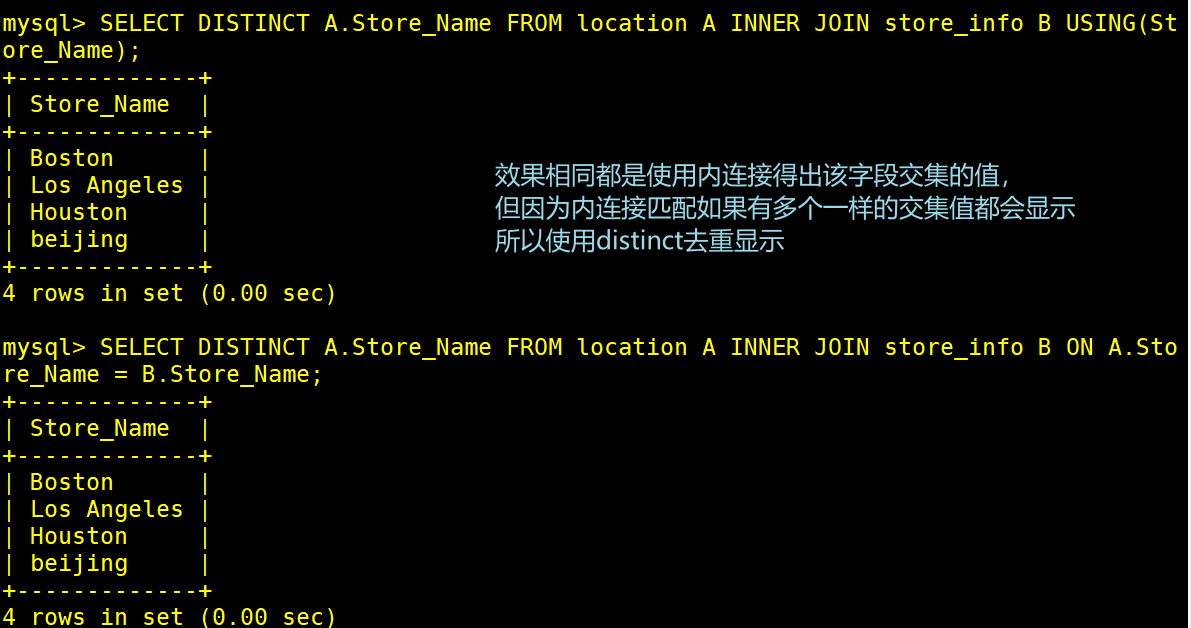
(1)使用内连接查询取交集值
SELECT DISTINCT A.Store_Name FROM location A INNER JOIN store_info B ON A.Store_Name = B.Store_Name;
SELECT DISTINCT A.Store_Name FROM location A INNER JOIN store_info B USING(Store_Name);
#DISTINCT去重为了该字段有重复数据会影响想要的结果
#using关键字来简化连接查询,但是只是在查询满足下面两个条件时,才能使用using关键字进行简化。
1.查询必须是等值连接。
2.等值连接中的列必须具有相同的名称和数据类型。
所以ON A.store_name = B.Store_name和USING(Store_name)效果一样
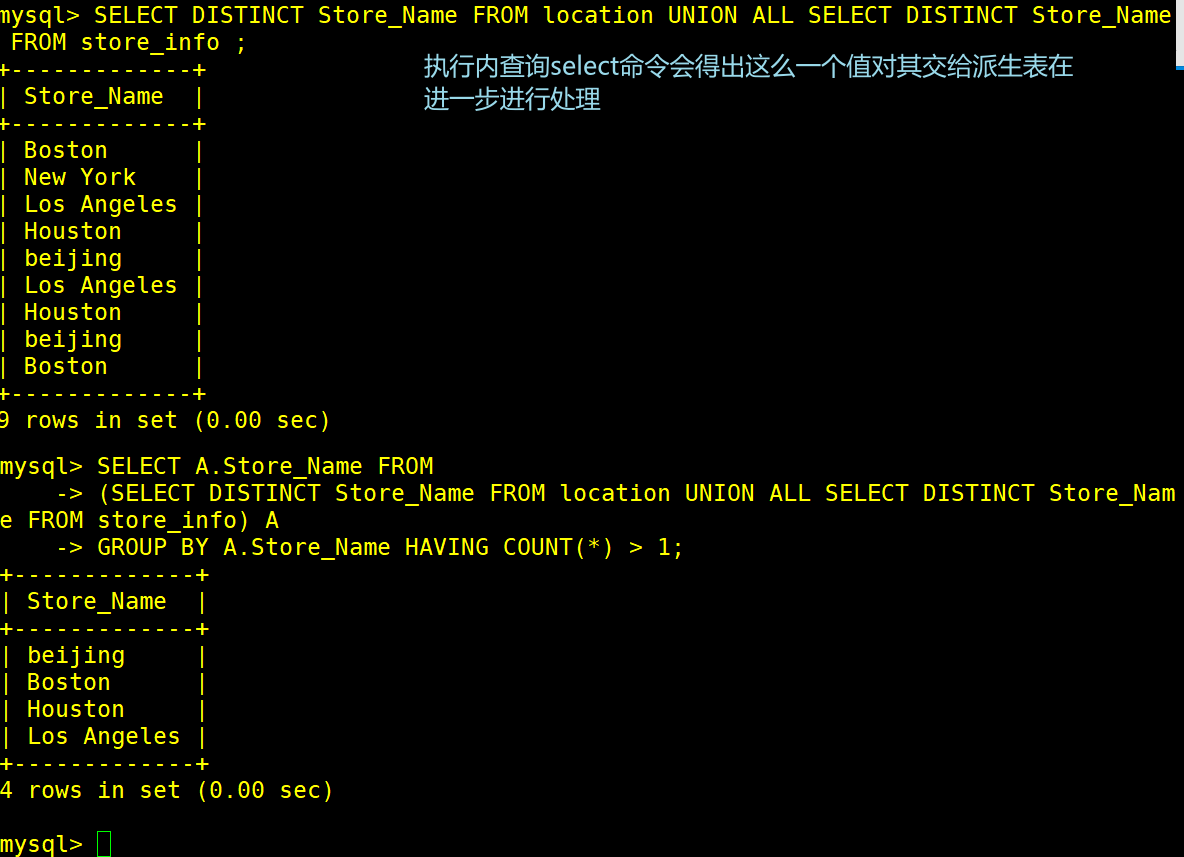
(2)使用派生表概念对汇总数据内容进行分组行数大于1则为交集的数据
SELECT A.Store_Name FROM
(SELECT DISTINCT Store_Name FROM location UNION ALL SELECT DISTINCT Store_Name FROM store_info) A
GROUP BY A.Store_Name HAVING COUNT(*) > 1;
#A为派生表,也是一个虚拟表和视图一样,存储着内查询SQL语句执行的结果,但是临时表,只在命令中不会创建出来
#数据进行分组后如果一个组里面有多行说明有多个数据,但是需要在执行内查询时就先对数据进行去重,否则一个表里有相同数据分组也会有多行,而该数据可能不一定是交集值
(3)使用外查询取两个SQL语句结果的交集,且没有重复
SELECT A.Store_Name FROM(SELECT B.Store_Name FROM location B INNER JOIN store_info C ON B.store_Name = C.Store_Name) A GROUP BY A.Store_Name;
SELECT DISTINCT A.Store_Name FROM location A INNER JOIN store_info B USING(Store_Name);
SELECT DISTINCT Store_Name FROM location WHERE Store_Name IN (SELECT Store_Name FROM store_info);
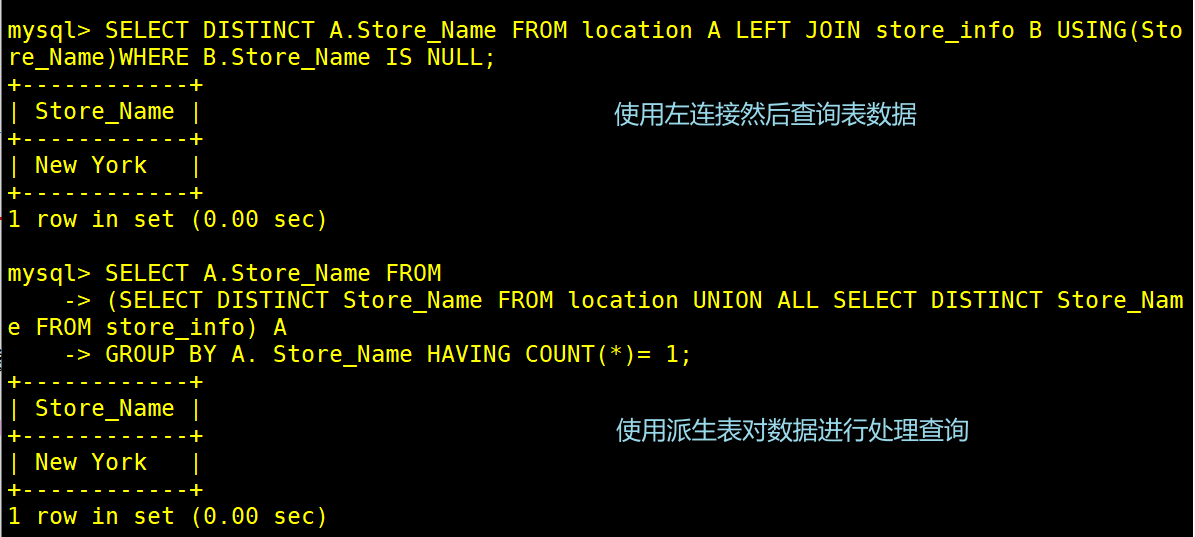
(4)使用左连接筛选没有右表没有null的数据得出交集值
SELECT DISTINCT A.Store_Name FROM location A LEFT JOIN store_info B USING(Store_Name) WHERE B.Store_Name IS NOT NULL;
---- 无交集值 ----
显示第一个SQL语句的结果,且与第二个SQL语句没有交集的结果,且没有重复
(1)使用外查询得出无交集值
SELECT DISTINCT Store_Name FROM location WHERE Store_Name NOT IN (SELECT store_Name FROM store_info);
#原本in是匹配()里面已知的值,not in则起到了取反的作用除了()已知的值
(2)使用左连接查询右表null值的数据为无交集
SELECT DISTINCT A.Store_Name FROM location A LEFT JOIN store_info B USING(Store_Name)WHERE B.Store_Name IS NULL;
#因为null值填充的都是无交集的数据
(3)使用派生表概念对汇总数据内容进行分组行数为1则为无交集的数据
SELECT A.Store_Name FROM
(SELECT DISTINCT Store_Name FROM location UNION ALL SELECT DISTINCT Store_Name FROM store_info) A
GROUP BY A. Store_Name HAVING COUNT(*)= 1;
#使用派生表来对数据分组

 浙公网安备 33010602011771号
浙公网安备 33010602011771号