sort、uniq、tr、cut、eval命令及正则表达式
sort命令
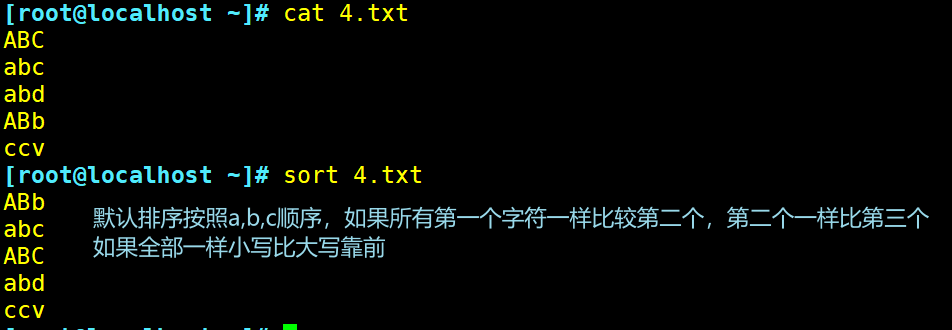
以行为单位对文件内容进行排序,也可以根据不同的数据类型进行排序
格式:
sort [选项] 参数
cat 1.txt | sort 参数
常用选项:
-f:忽略大小写,会将小写字母都转换为大写字母来进行比较
-b:忽略每行前面的空格
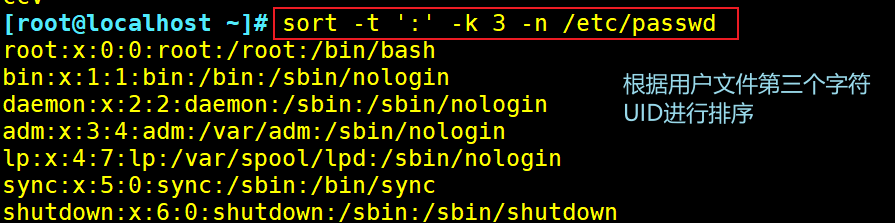
-n:按照数字进行排序
-r:反向排序
-u:等同于unip,表示相同的数据仅显示一行
-t:指定字段分隔符,默认使用[Tab]键分隔
-k:指定排序字段
-o<输出文件>:将排序后的结果转存至指定文件
默认情况排序:
根据文件中某个字段排序
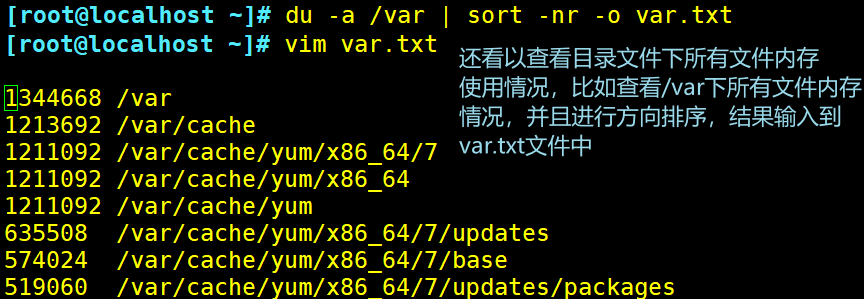
使用排序的方法查看目录下所有子文件使用内存情况
uniq命令
用于报告或者忽略文件中连续的重复行,常于sort命令结合使用
格式:
uniq [选项]参数
cat 1.txt | uniq 选项
常用选项
-c:进行计数,并删除文件重复出现的行
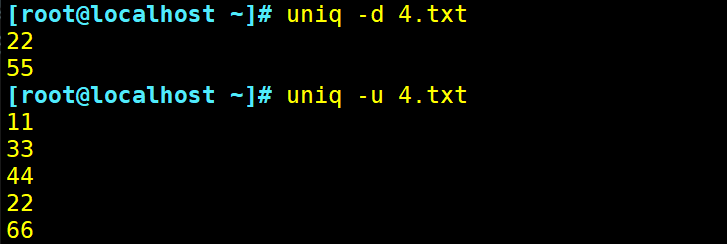
-d:仅显示连续的重复行
-u:仅显示出现一次的行
默认情况

结合sort命令将混乱的重复行一并处理
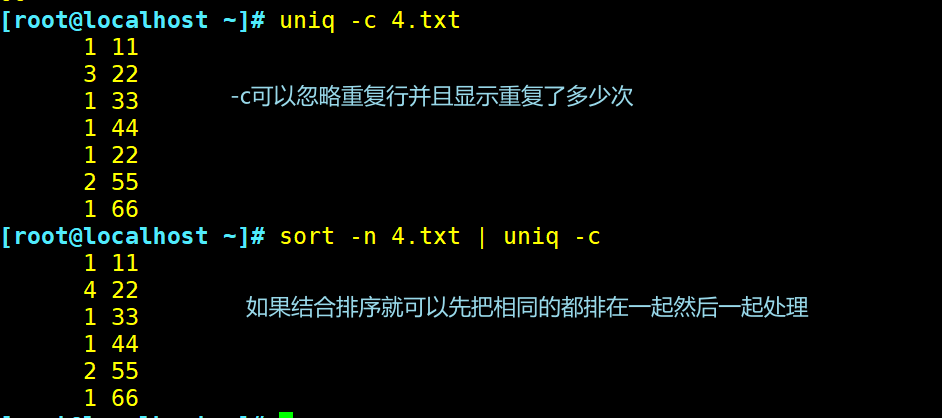
显示出现过多次的字符或者显示只出现过一次的字符
tr命令
常用来对来自标准输入的字符进行替换、压缩和删除
格式:
tr [选项] [参数]
常用选项:
-c:保留字符集1的字符,其他的字符(包括换行符\n)用字符集2替换
-d:删除所有属于字符集1的字符
-s:将重复出现的字符串压缩为一个字符串;也同时可以用字符集2替换字符集1
-t:字符集2 替换字符集1,不加选项同结果
参数:
字符集1:指定要转换或删除的原字符集。当执行转换操作时,必须使用参数“字符集2”指定转换的目标字符集,但执行删除操作时,不需要参数“字符集2”
字符集2:指定要转换成的目标字符集
默认情况和-t一样

使用-c进行保留替换

删除操作

指定某个重复出现的字符进行压缩并且也可以同时进行替换

删除windows 文件"造成"的"^M"字符∶
Linux中遇到换行符("\n")会进行回车+换行的操作,回车符反而只会作为控制字符("^M")显示,不发生回车的操作。而windows中要回车符+换行符("\r\n")才会回车+换行,缺少一个控制符或者顺序不对都不能正确的另起一行
首先我们在windows系统中写一个脚本并且传到linux系统中
这可能会影响我们执行脚本产生未知的错误,所以我们需要处理好文件的特殊字符


也可以安装dos2unix
这款服务插件可以将外拉进来的文件转换为linux或unix原生的格式

cut命令
显示行中的指定部分,删除文件中指定字段
格式∶
cut 选项 参数
cat 1.txt | cut 选项
常用选项∶
-f∶通过指定哪一个字段进行提取。cut命令使用"TAB"作为默认的字段分隔符,常与-d一起使用
-d∶"TAB"是默认的分隔符,使用此选项可以更改为其他的分隔符
-c∶以字符单位进行分割
-b∶以字节为单位进行分割,这些字节位置将忽略多字节字符边界,除法也指定了-n标准
-n∶取消分割多字节字符。仅和-b标志一起使用。如果字符的最后一个字节落在由 -b 标志的List参数指示的范围之内,该字符将被写出;否则,该字符将被排除
--complement∶此选项用于排除所指定的字段
--output-delimiter=∶ 更改输出内容的分隔符
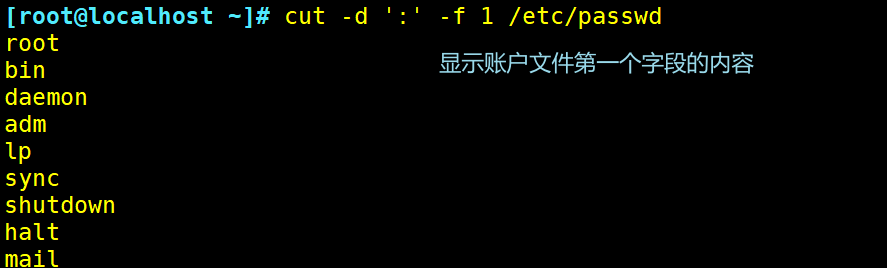
显示存放账号信息文件每行第一个字段的内容
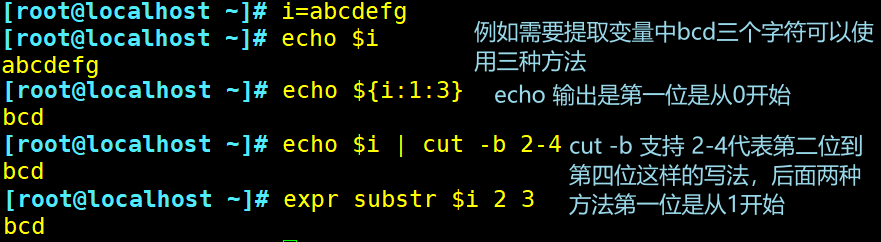
显示指定部分内容的几种方法
-c与-bn的区别应用

混合运用

eval命令
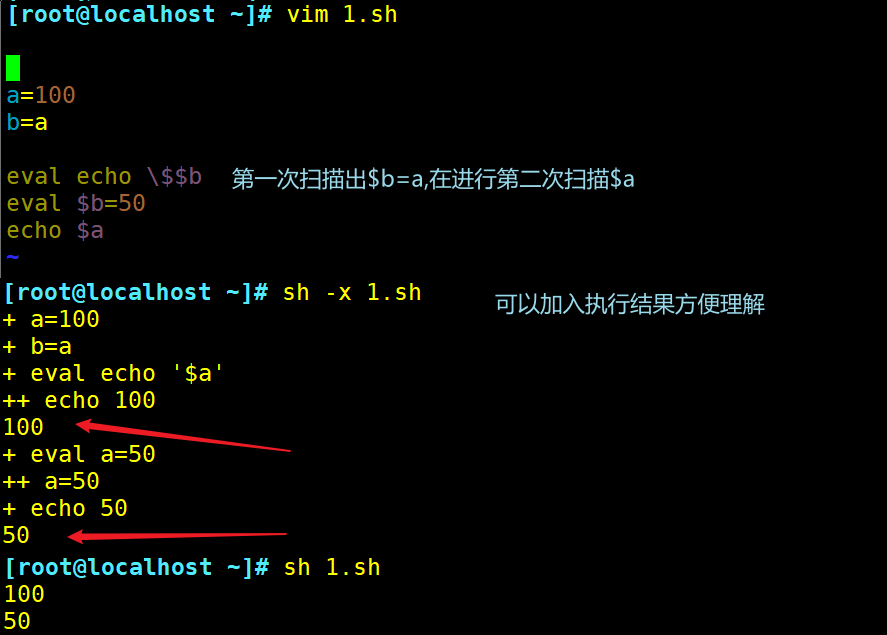
命令字前加上eval时,shell会在执行命令之前扫描它两次。eval命令将首先会先扫描命令行进行所有的置换,然后再执行该命令。该命令适用于那些一次扫描无法实现其功能的变量。该命令对变量进行两次扫描
使用eval命令创建指向变量的指针
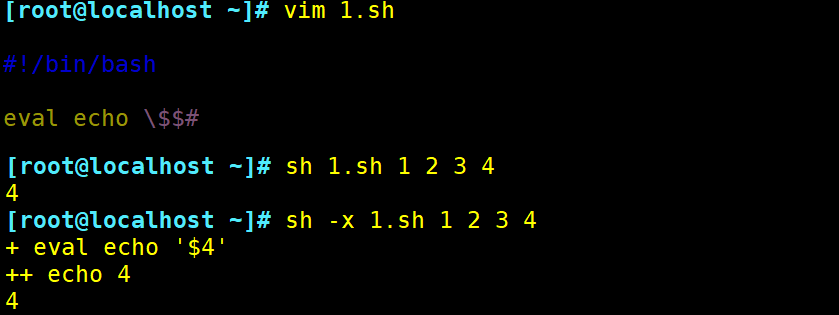
eval命令显示出传递给脚本的最后一个参数
注意:
1、eval 不能获得函数处理结果。
2、eval 嵌套无意义,在其他语言中可以通过 eval(eval(“code”)) ,来执行(执行动态生成的code的返回),而由shell中 eval 将后面的eval命令简单当作命令字符串执行,失去了嵌套作用,嵌套被命令替换取代。
正则表达式
定义
正则表达式是你所定义的模式模板(pattern template),Linux工具可以用它来过滤文本。Linux工具(sed编辑器或gawk程序)能够在处理数据时使用正则表达式对数据进行模式匹配。通常用于判断语句中,用来检查某一字符串是否满足某一格式,如果数据匹配模式,它就会被接受并进一步处理,如果数据不匹配模式,它就会被过滤掉
正则表达式是由普通字符与元字符组成
普通字符包括大小写字母、数字、标点符号及一些其他符号
元字是指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导学符 (即位于元字符前面的字符或表法式)在目标对象中的出现模式
基础正则表达式常见元字符∶(支持的工具∶ grep、egrep、sed、awk)
\∶转义字符,用于取消特殊符号的含义,例∶\!、\n、\s等
^∶匹配字符串开始的位置,例∶^a、^the、"#、^[a-z]
$∶匹配字符串结束的位置,例∶word$、^$匹配空行
.∶匹配除\n之外的任意的一个字符,例∶go.d、g..d
*∶匹配前面子表达式0次或者多次,例∶goo*d、go.*d
[list]∶匹配list列表中的一个字符,例∶go[ola]d,[abc]、[a-z]、[a-z0-9]、[0-9]匹配任意一位数字
[^list]∶匹配任意非list列表中的一个字符,例∶[^0-9]、[^A-z0-9]、[^a-z]匹配任意一位非小写字母
\{n\}∶匹配前面的子表达式n次,例∶go\{2\}d、' [0-9]\{2\}'匹配两位数字
\{n,\}∶匹配前面的子表达式不少于n次,例∶go\{2\N}d、'[0-9]\{2,\}'匹配两位及两位以上数字
\{n,m\}∶匹配前面的子表达式n到m次,例∶ go\{2,3\}d、'[0-9]\{2,3\}'匹配两位到三位数字
注∶ egrep(就是grep的增强版,功能基本一样相当于vi和vim)、awk使用 {n}、{n,}、{n,m}匹配时"{}"前不用加"\"

扩展正则表达式元字符∶(支持的工具∶ egrep、awk)
+∶匹配前面子表达式1次以上,例∶go+d,将匹配至少一个o,如god、good、goood等
?∶匹配前面子表达式0次或者1次,例∶go?d,将匹配gd或god
()∶将括号中的字符串作为一个整体,例∶g(oo)+d,将匹配oo整体1次以上,如good、gooood等
|∶以或的方式匹配字条串,例∶g(oo|la)d,将匹配good或者glad
示例:混合运用
原本1.txt文件中有这么几个邮箱,我根据需要筛选出了部分文件

注释:
^[a-zA-Z\_]:以大小写字母或者符号 _ 开头
[a-zA-Z0-9\_\.\-\#\ ]{5,}:邮箱用户名部分的字符可以是大小写字母或者是这么几个符号“\ ” 为空格,最少匹配五次以上
@:中间字符为@
[0-9a-zA-Z\_\-]+:子域名部分字符可能为大小写字母,数字或者这两个符号匹配至少一次以上
.[a-zA-Z]{2,5}$:.顶级域名字符串是大小写字母结尾并且至少匹配2到5次

 浙公网安备 33010602011771号
浙公网安备 33010602011771号