Python多线程爬取亚马逊商品数据
前言
新年快乐
⚠️声明:本文所涉及的爬虫技术及代码仅用于学习、交流与技术研究目的,禁止用于任何商业用途或违反相关法律法规的行为。若因不当使用造成法律责任,概与作者无关。请尊重目标网站的
robots.txt协议及相关服务条款,共同维护良好的网络环境。
1.环境准备
使用miniconda为亚马逊创建一个新环境,防止feapder和其他包冲突(比如scrapy)。
# 创建一个新的 Conda 环境:
conda create -n python_feapder python=3.12
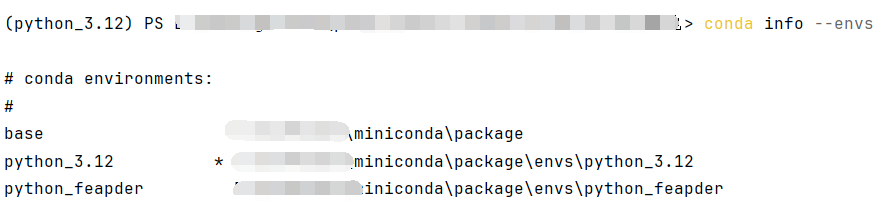
# 查看已创建的环境
conda info --envs
# 激活环境
conda activate python_feapder
# 安装所需要的包
pip install pymysql requests retrying lxml loguru feapder
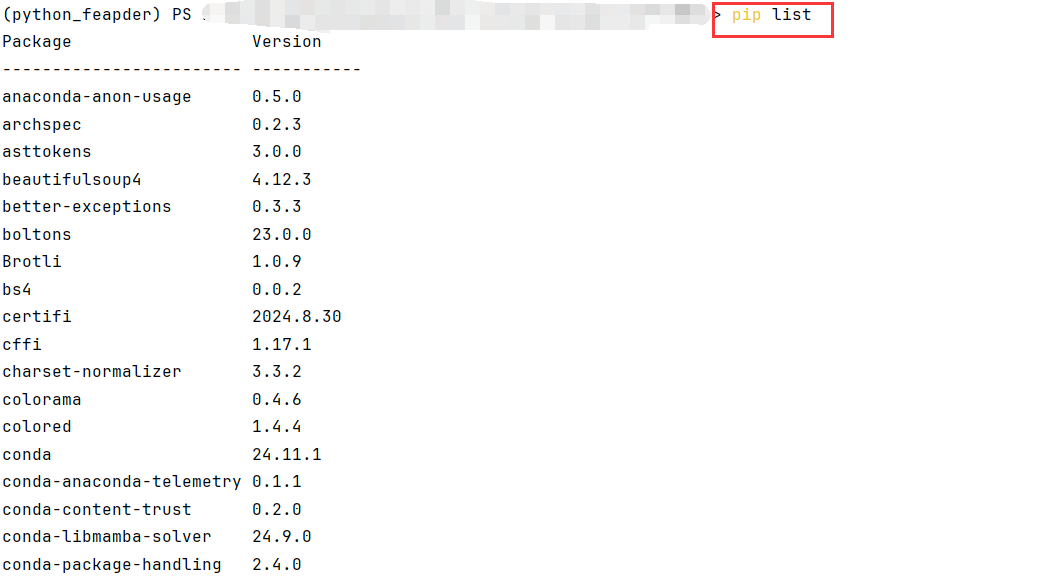
# 使用pip install安装包,要使用 pip list 来查看当前环境中通过 pip 安装的包
# 使用conda install安装包,要使用 conda list 来查看当前环境中通过 pip 安装的包
pip list
# 退出当前环境
conda deactivate
# 删除可以删除环境,可能不需要,如果创建失败或者需要重新创建,可以删除重建
conda remove -n python_feapder --all
以下是创建过程>
创建python_feapder
如果创建时不指定python版本,会默认使用你的安装目录\miniconda\package\python.exe
也就是你的miniconda安装目录下的python.exe的解释器

查看当前所有环境
激活python_feapder

安装环境所需要的包

查看已安装的包
2.conda解释器设置
添加本地解释器
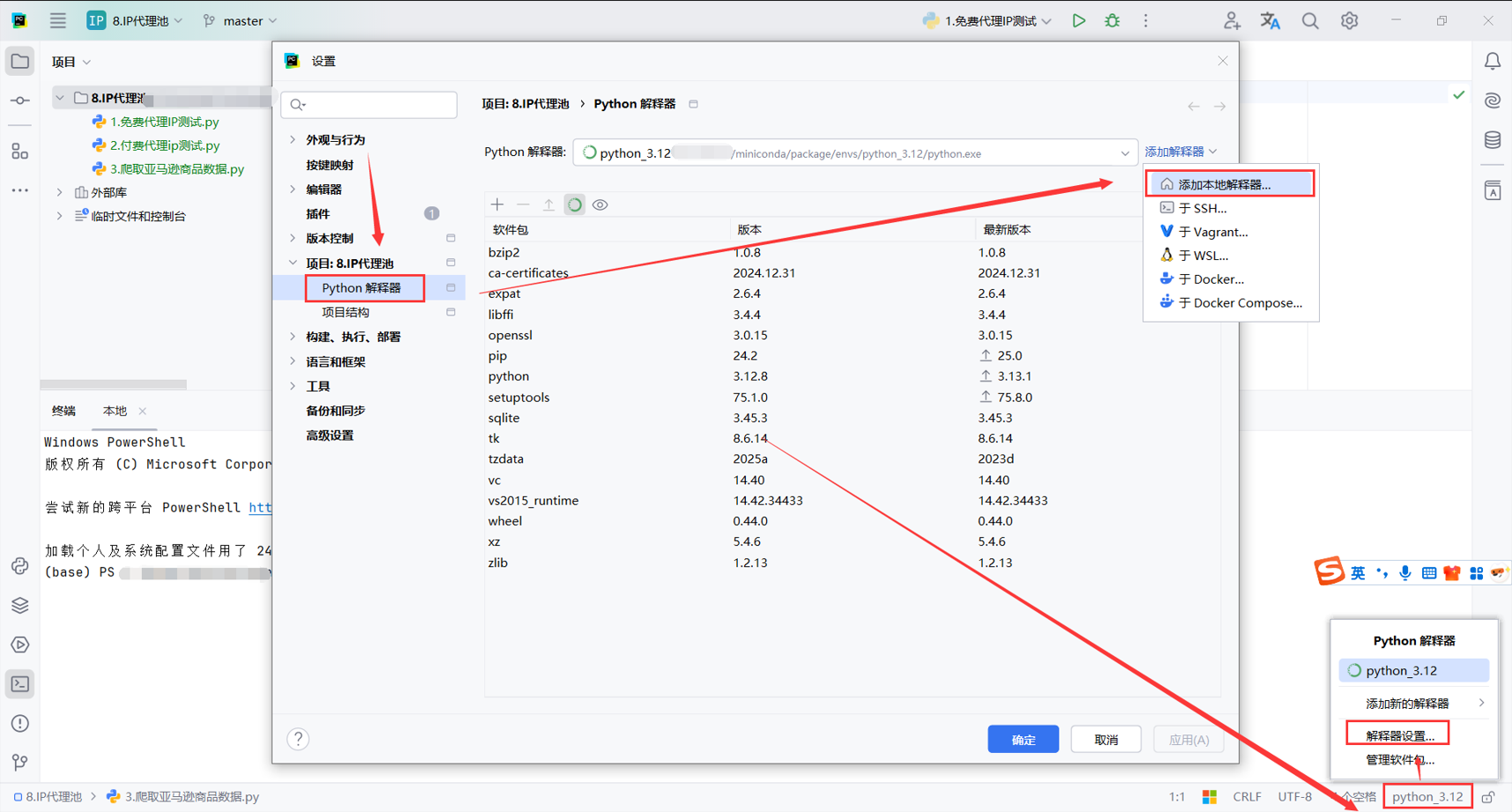
选择新创建的环境
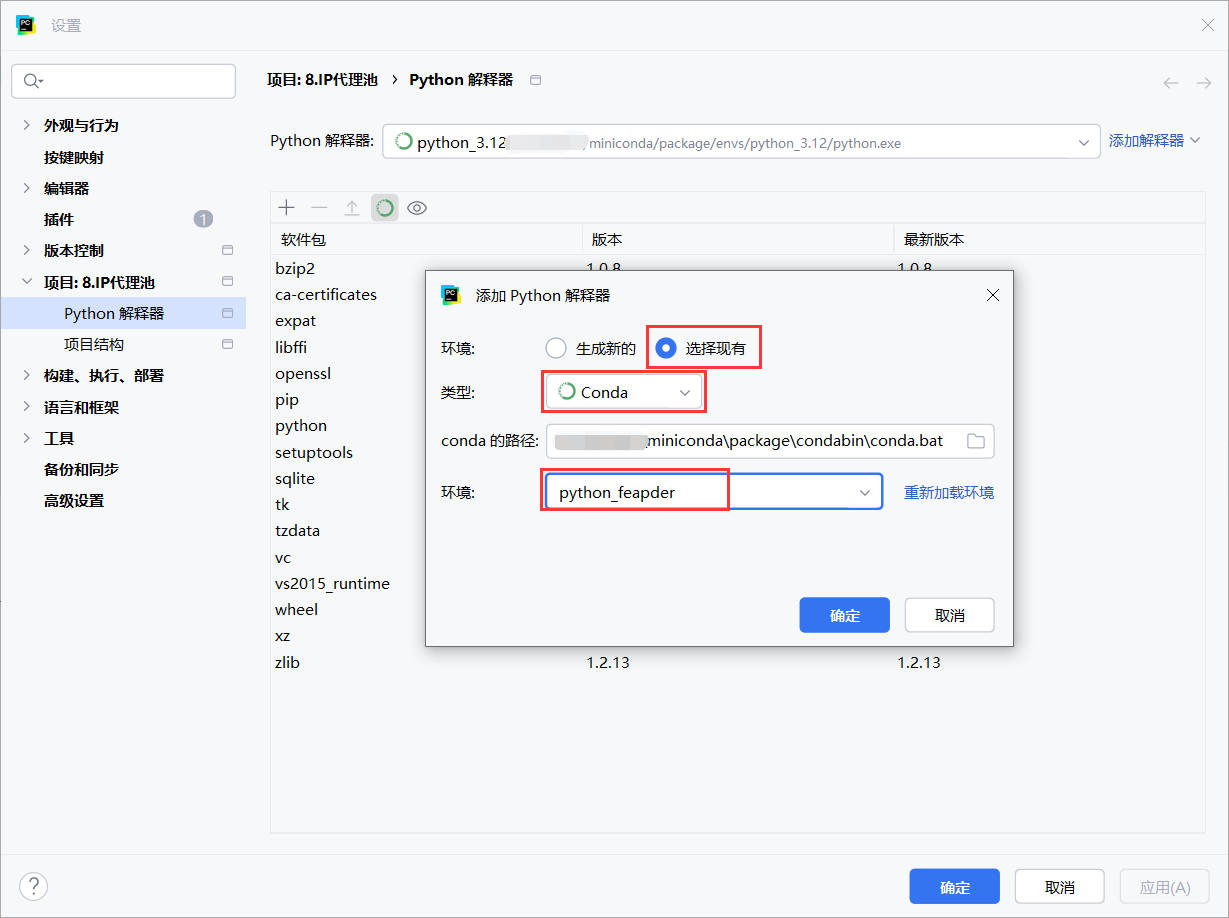
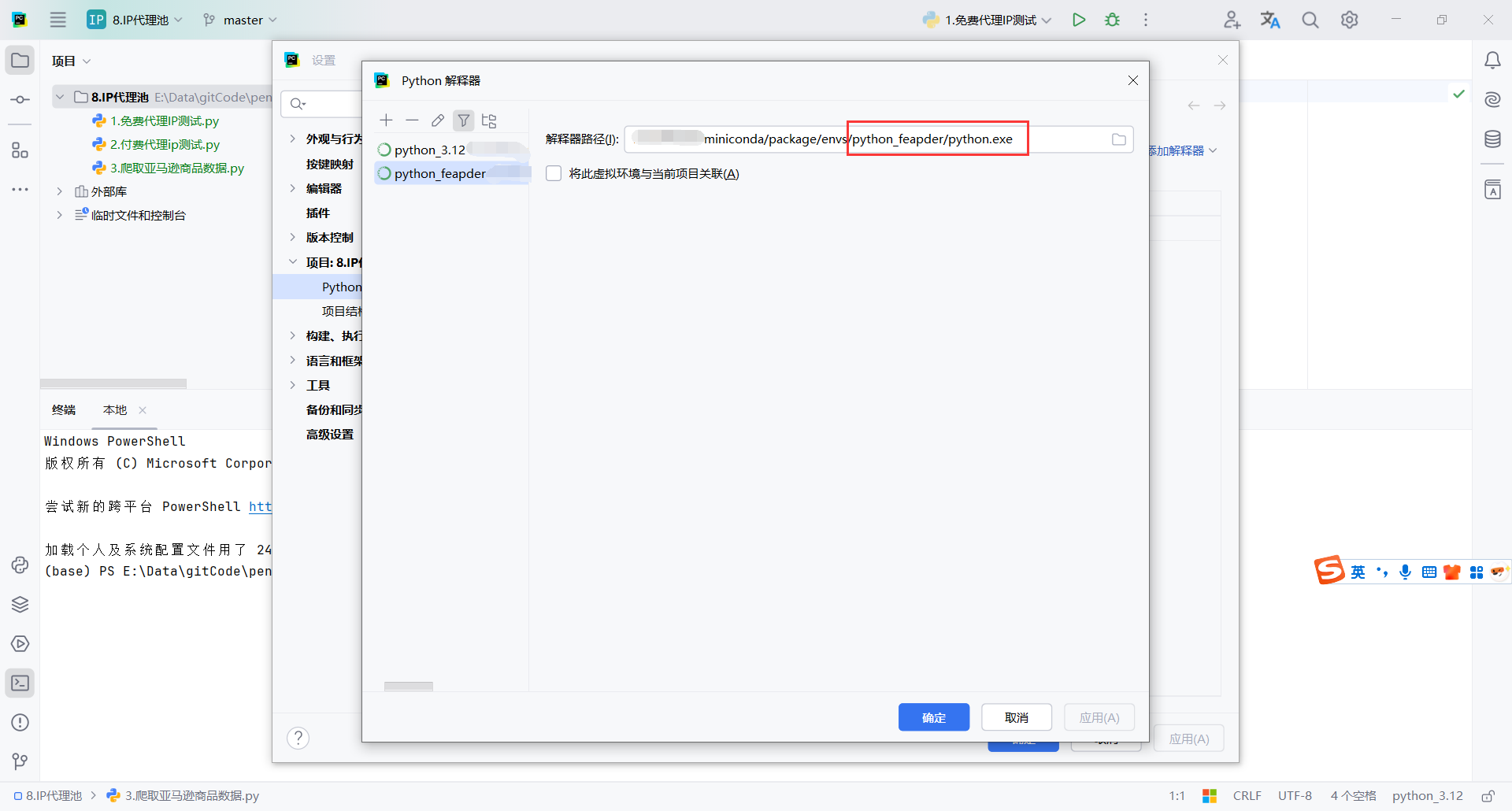
如果新创建的环境的解释器位置对不上,可以重新设置
创建环境的时候设置python版本,应该不会有这个问题
conda create -n python_feapder python=3.12
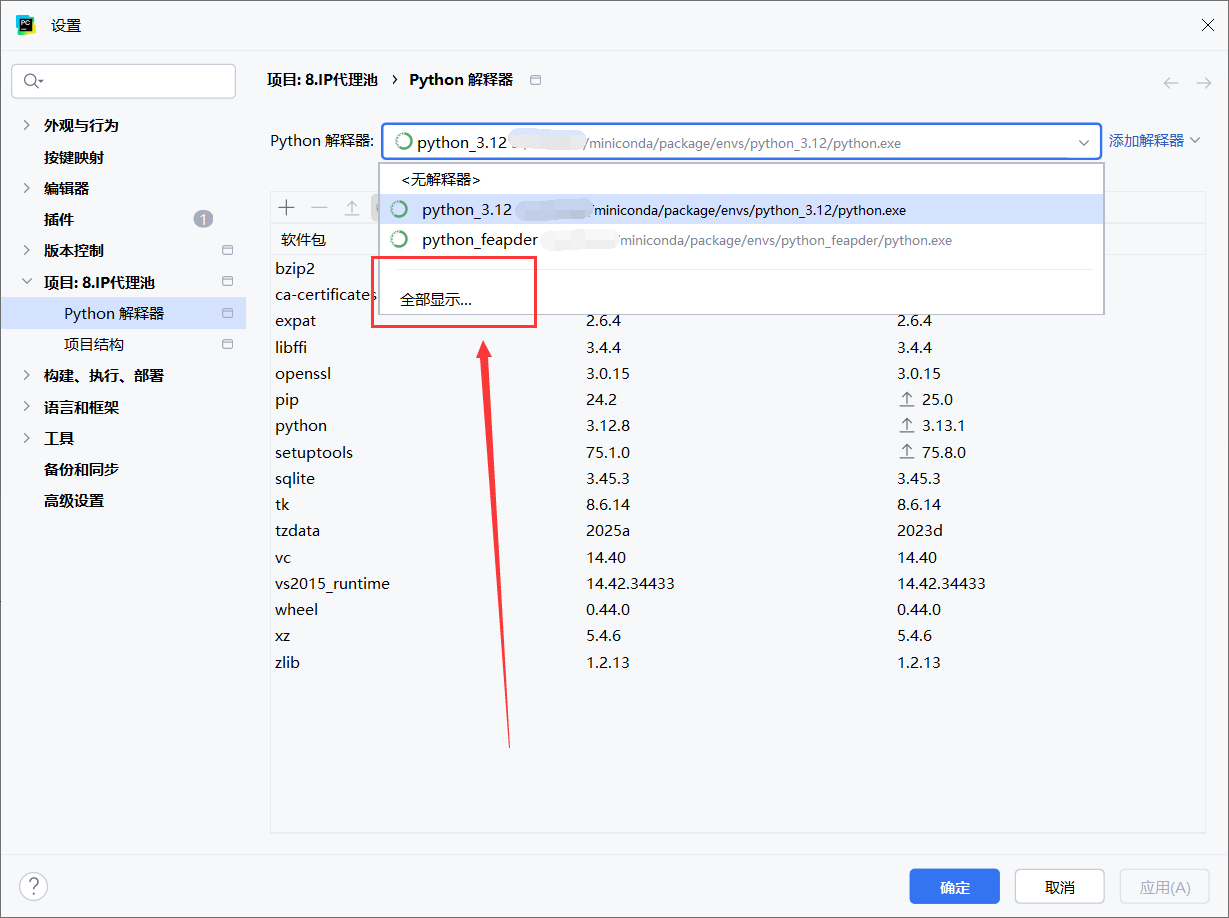
重新指定新环境的python解释器地址
3.一级菜单
查找一级菜单
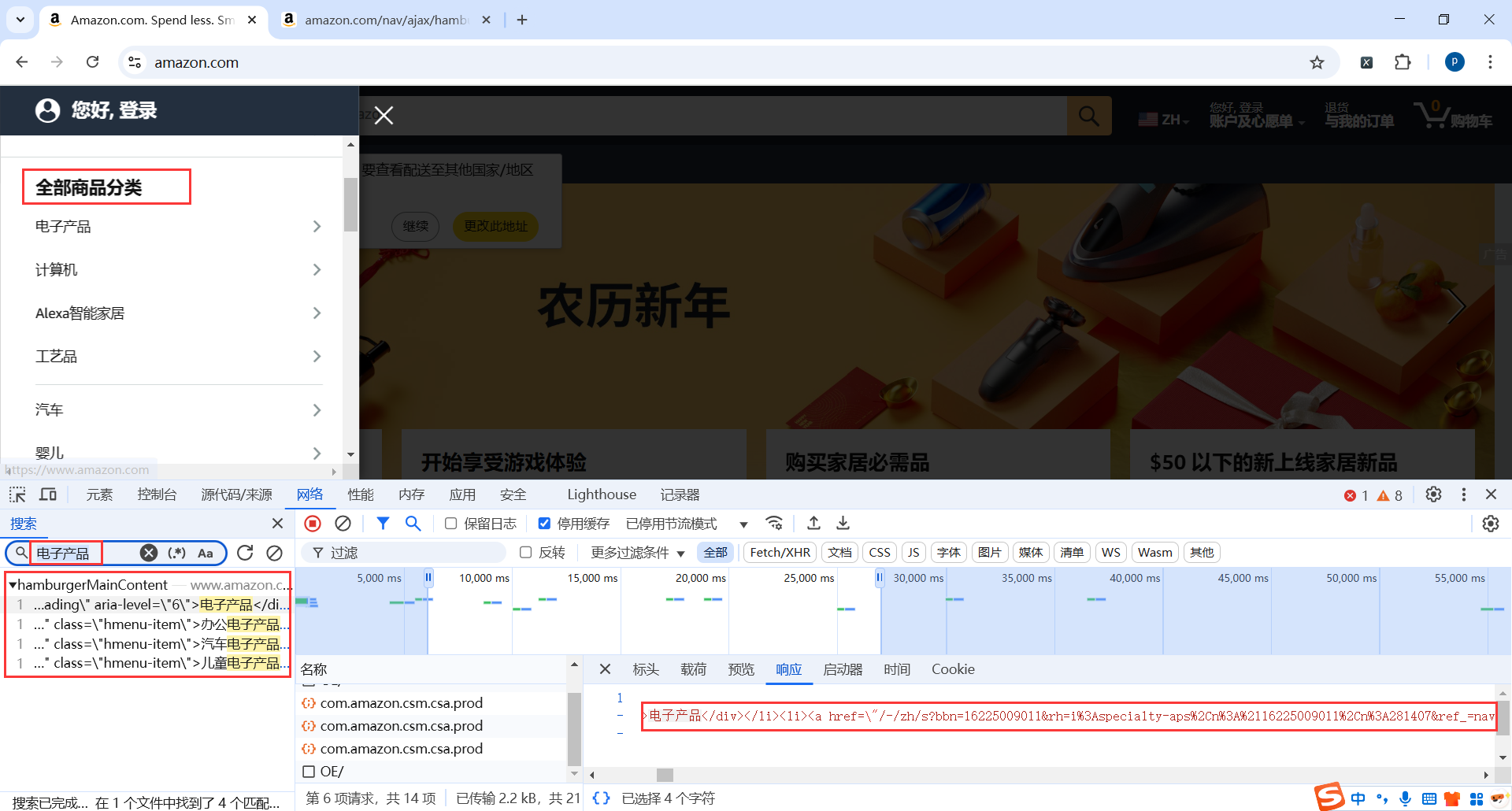
一级菜单地址
https://www.amazon.com/nav/ajax/hamburgerMainContent?ajaxTemplate=hamburgerMainContent&pageType=Gateway&hmDataAjaxHint=1&navDeviceType=desktop&isSmile=0&isPrime=0&isBackup=false&hashCustomerAndSessionId=c29600d243c8a5975548ed30d33b8f18925a7d23&languageCode=zh_CN&environmentVFI=AmazonNavigationCards%2Fdevelopment%40B6289328400-AL2_aarch64&secondLayerTreeName=prm_digital_music_hawkfire%2Bkindle%2Bandroid_appstore%2Belectronics_exports%2Bcomputers_exports%2Bsbd_alexa_smart_home%2Barts_and_crafts_exports%2Bautomotive_exports%2Bbaby_exports%2Bbeauty_and_personal_care_exports%2Bwomens_fashion_exports%2Bmens_fashion_exports%2Bgirls_fashion_exports%2Bboys_fashion_exports%2Bhealth_and_household_exports%2Bhome_and_kitchen_exports%2Bindustrial_and_scientific_exports%2Bluggage_exports%2Bmovies_and_television_exports%2Bpet_supplies_exports%2Bsoftware_exports%2Bsports_and_outdoors_exports%2Btools_home_improvement_exports%2Btoys_games_exports%2Bvideo_games_exports%2Bgiftcards%2Bamazon_live%2BAmazon_Global&customerCountryCode=VN
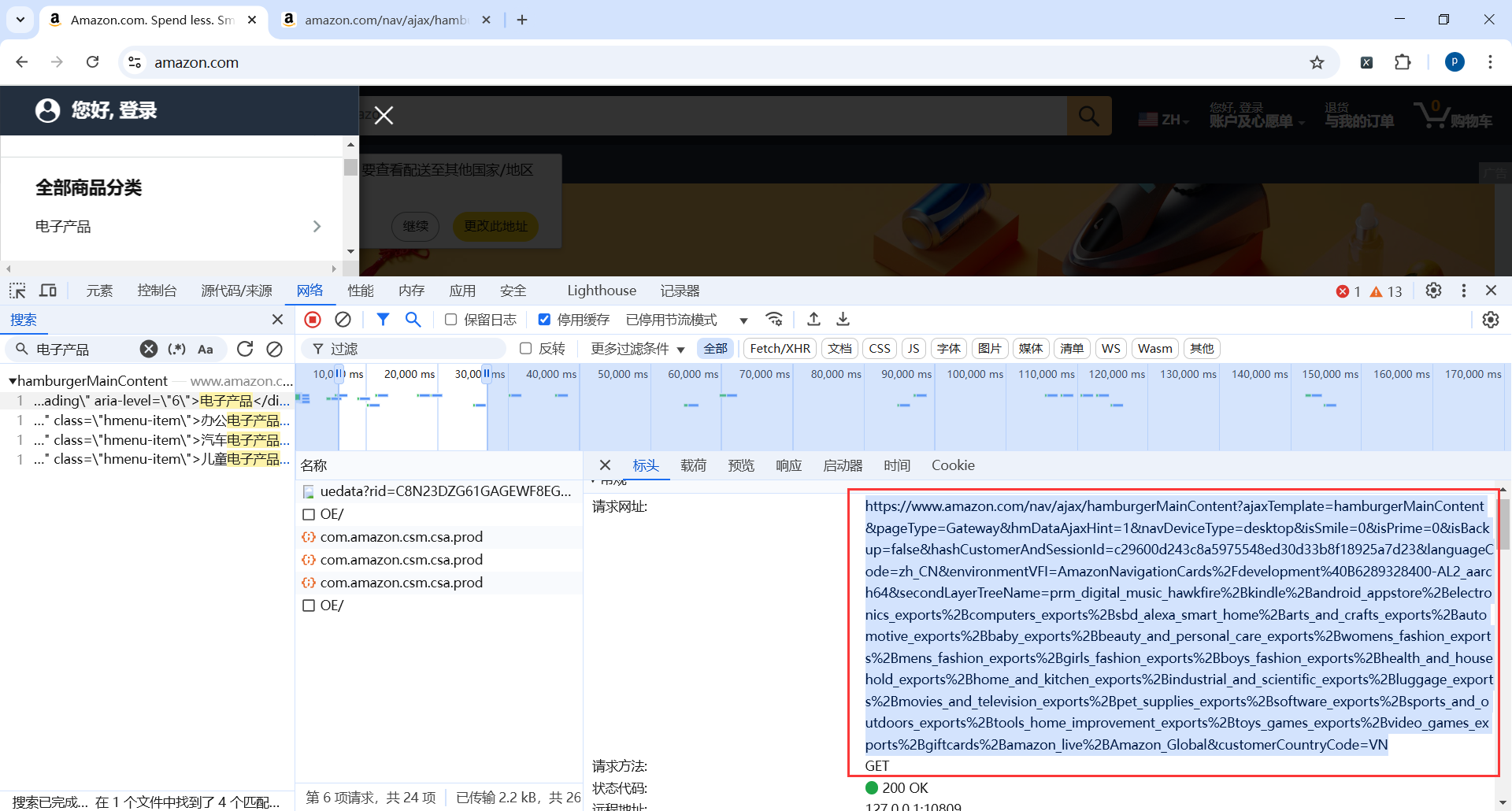
我们发现这个链接返回了所有的菜单列表,一级菜单和二级菜单,但是返回的是html
我们使用PyCharm创建一个新的html页,并把代码拷贝进去

整理一下代码,Ctrl + shift + L格式化代码
然后替换一些格式化的字符,代码就整洁多了
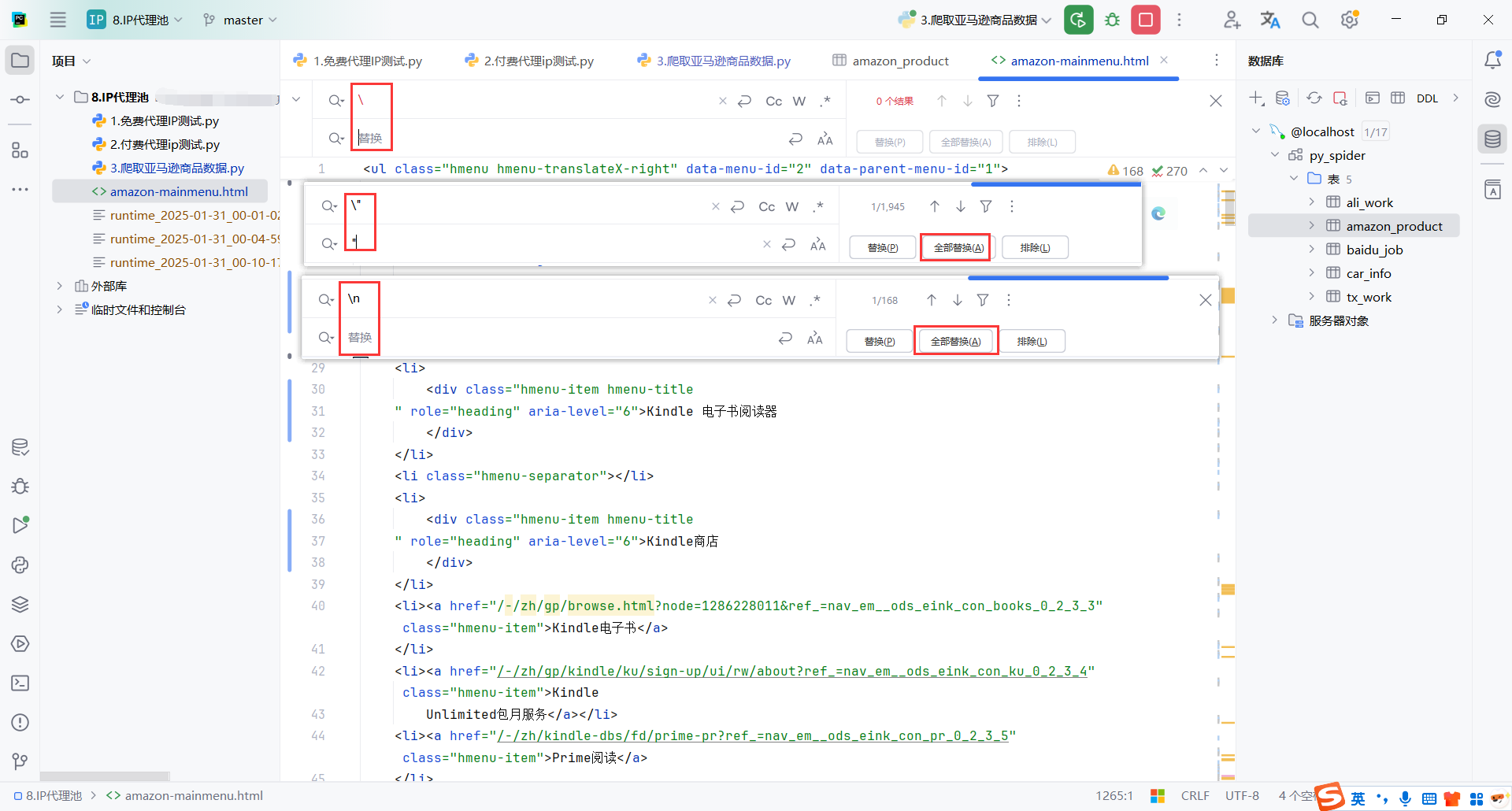
在页面开始加一行配置,要不然使用PyCharm打开时会乱码
<meta http-equiv="Content-Type" content="text/html;charset=utf-8">
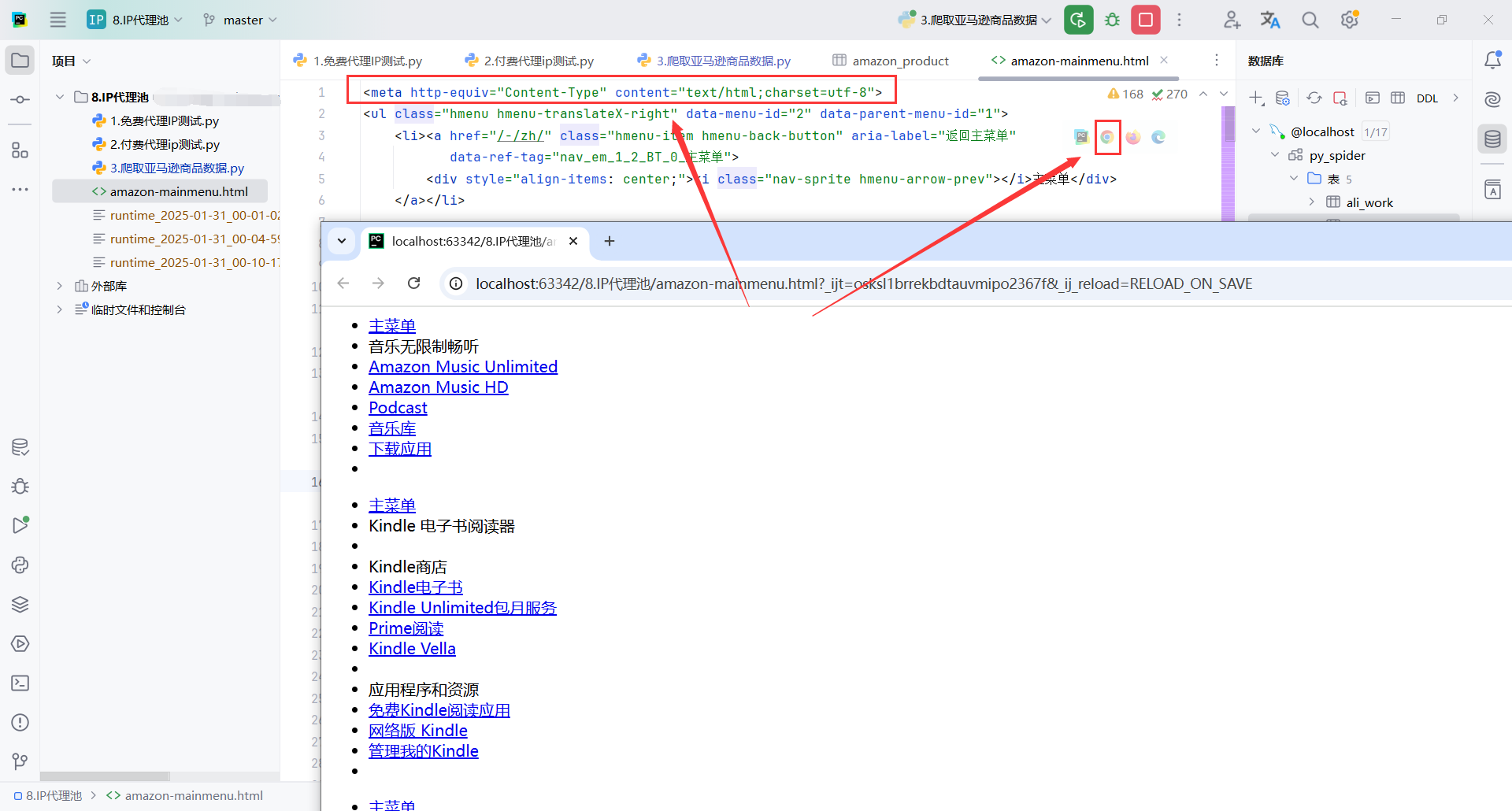
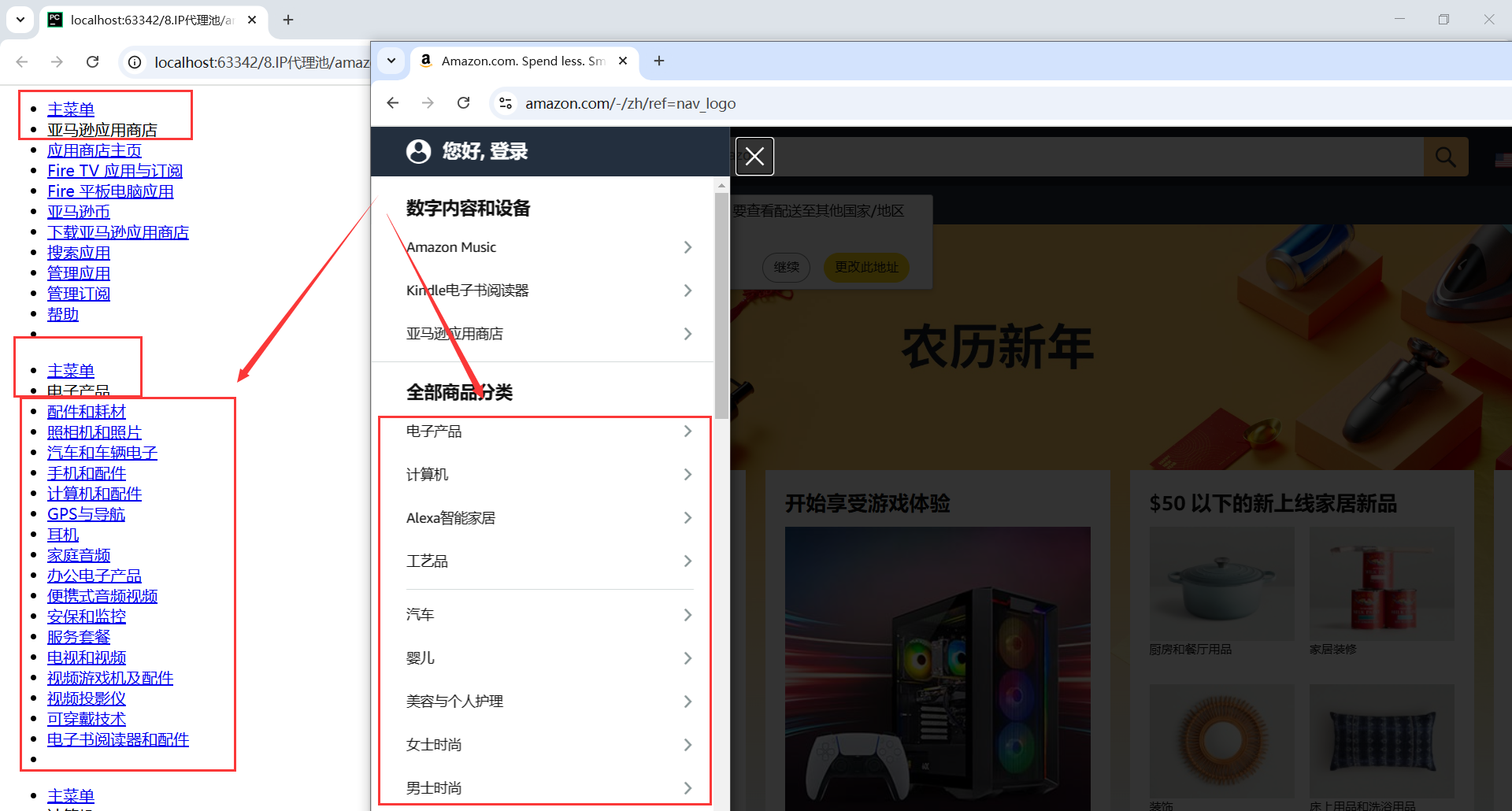
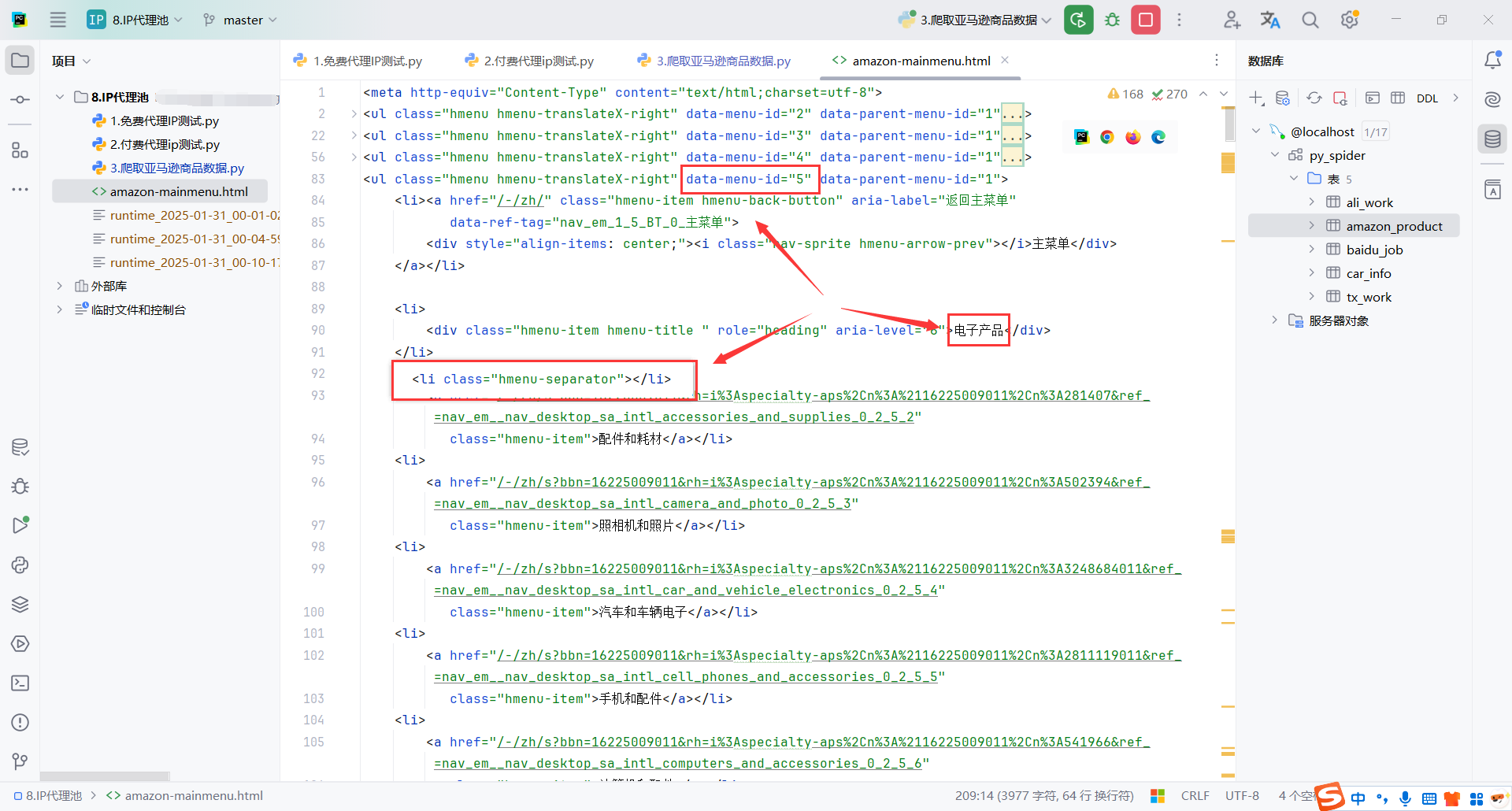
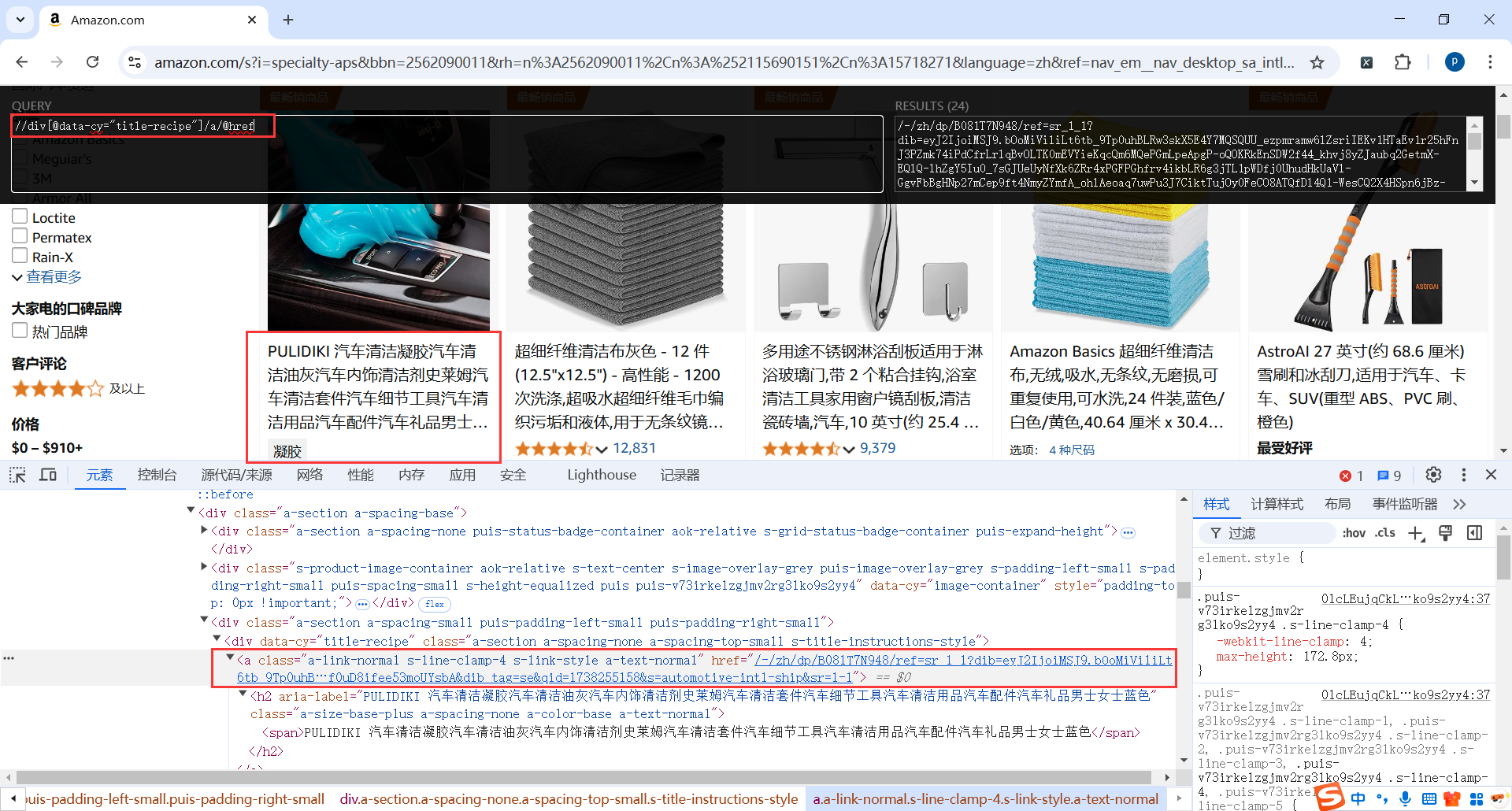
我们只需要商品分类下的菜单地址,而且每个菜单的前2个是没有链接的
所以我们提取数据的xpath是:
从 <ul> 元素中,选取 data-menu-id 在 5 到 26 之间的 ul,并筛选其中符合以下条件的 <li> 元素:
- 位置 (
position()) 大于 2(即排除前两个<li>)。 - 不包含
class="hmenu-separator"(即排除分隔符)。这个是我后期测试发现的,这个li没有链接,可以忽略掉
//ul[number(@data-menu-id) >= 5 and number(@data-menu-id) <= 26]/li[position() > 2 and not(contains(@class, "hmenu-separator"))]
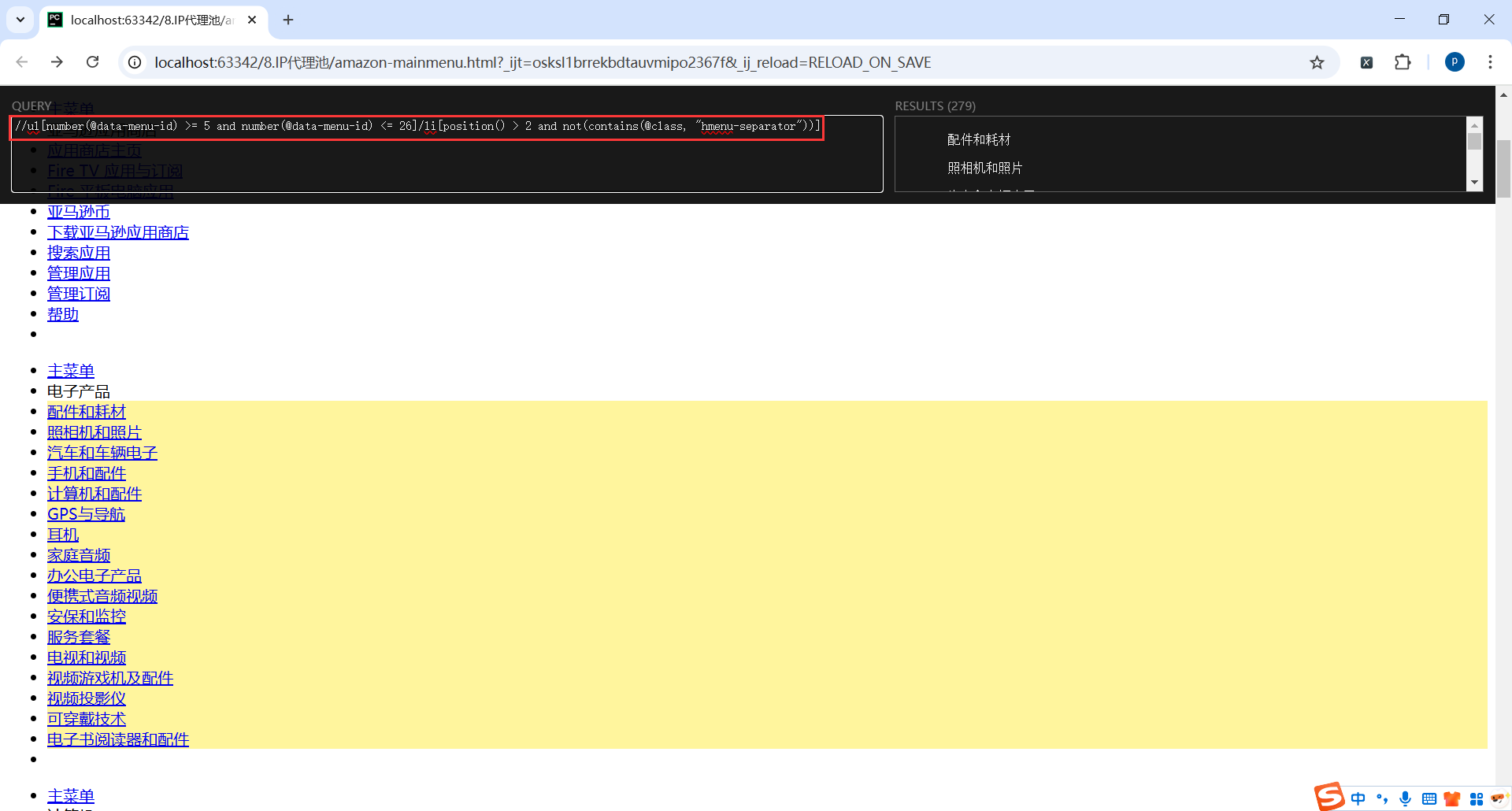
看看返回的html,基本就明白了
当然,看着简单,我调的时候也费了点事
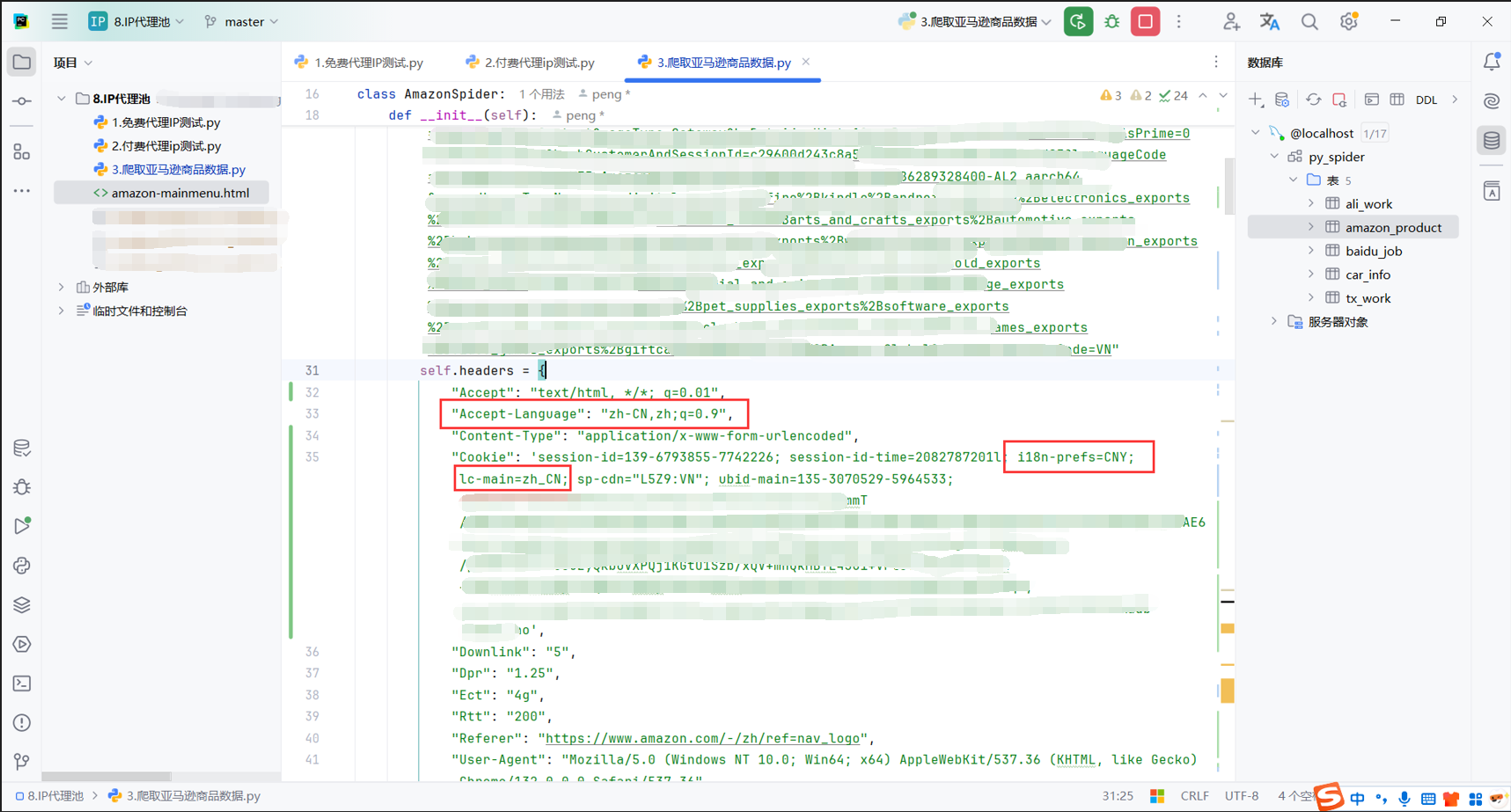
然后就是我请求的时候一直返回的是英文的数据,需要在请求头加点配置
"Cookie": " i18n-prefs=CNY; lc-main=zh_CN;"
"Accept-Language": "zh-CN,zh;q=0.9",
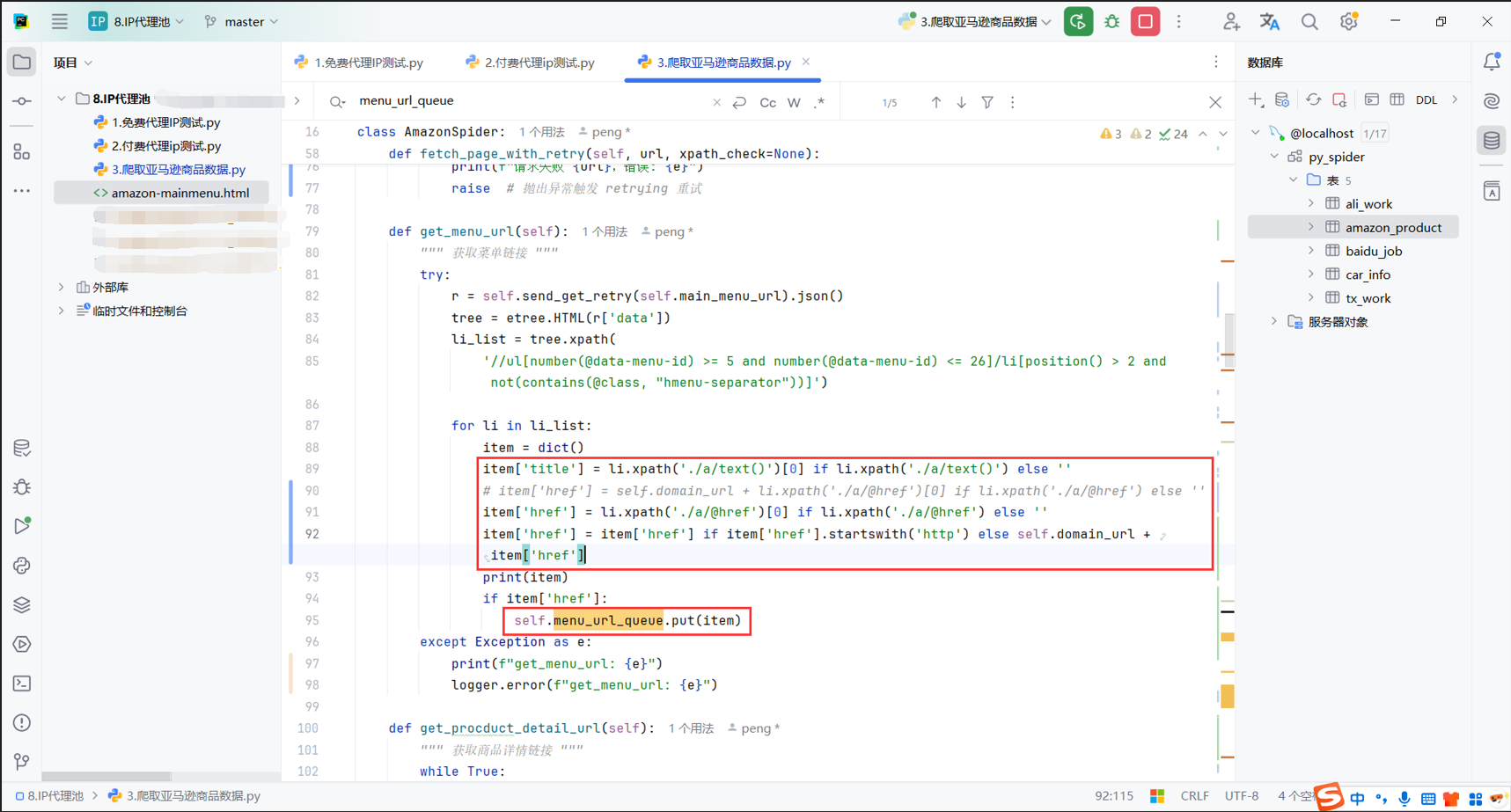
多线程其实就是把数据放到队列,交给其他有资源的线程从队列中获取后进行处理
获取一级菜单也不是多线程,我只开启了一个线程,其实也不需要多线程处理这个html
然后爬取到的链接,其实就是li下的a标签的href属性,这个链接是没有域名的,需要加上域名
4.商品列表页
这里只爬取二级菜单返回的链接中带有分页的,其他的页面也要好多种,这里不展开学习了

这里获取到商品列表后,获取分页最大的页码,给商品列表的链接拼接分页参数,就是&page=
拼接完所有的分页链接后,解析获取每页的商品详情链接
记得开始get(),代码最后要task_done()
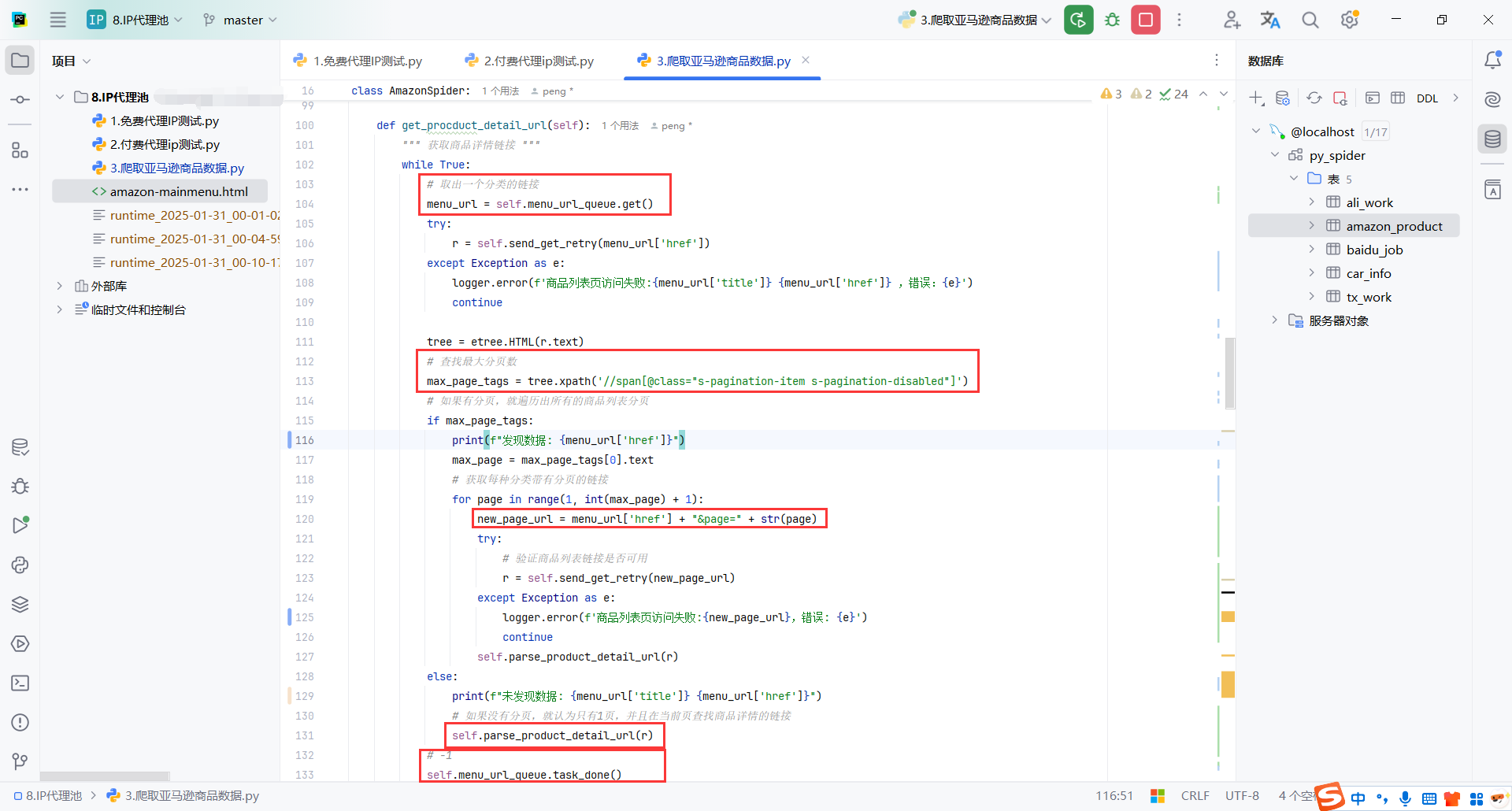
其实就是获取<a>标签的<href>的链接
获取到商品详情的链接就放入到获取商品详情数据的队列product_url_queue
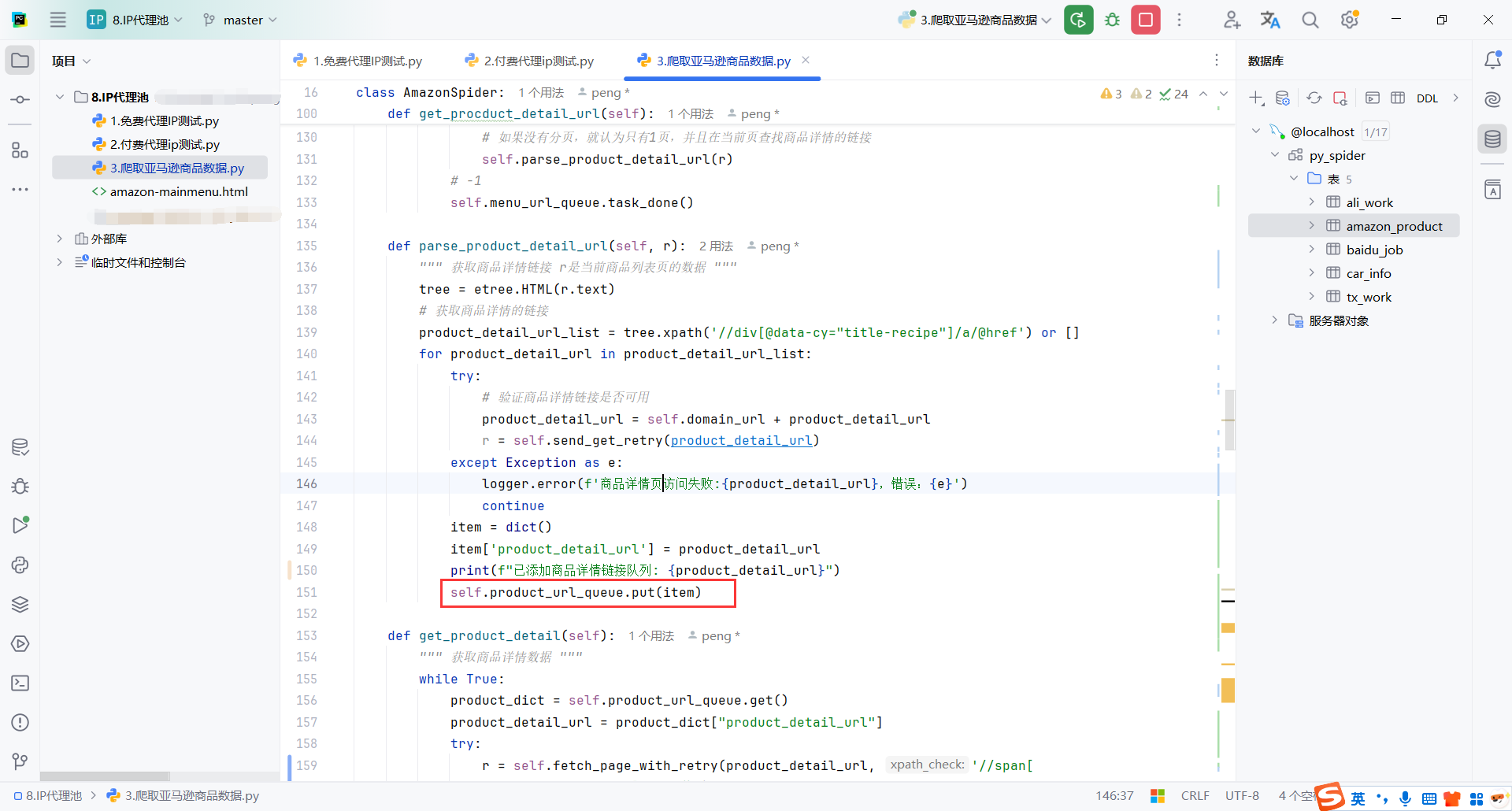
5.商品详情
这里获取到商品详情链接后,就需要分析商品详情的页面,获取到自己需要的数据
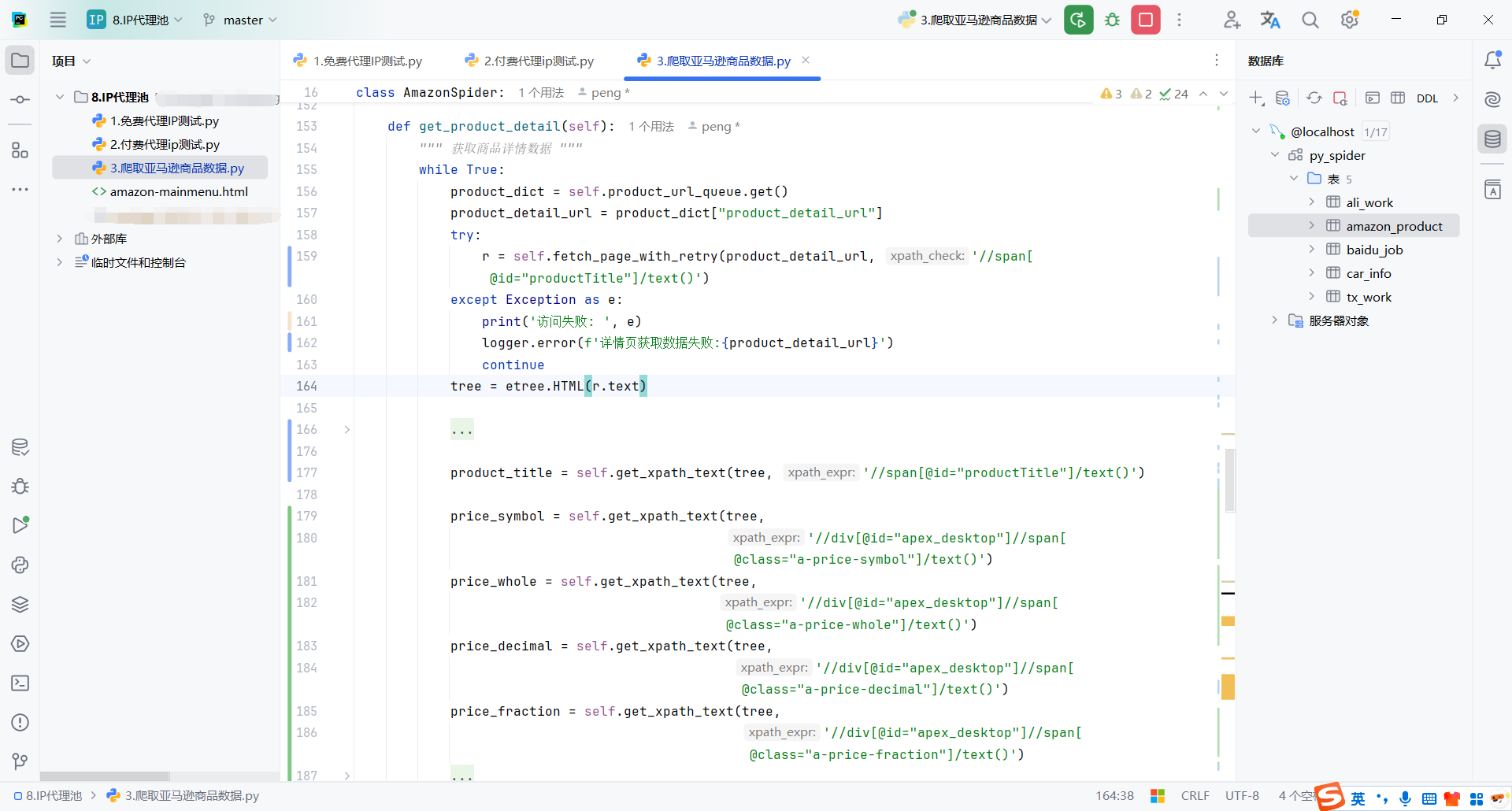
这里就以商品标题为例,商品标题的xpath
//span[@id="productTitle"]/text()
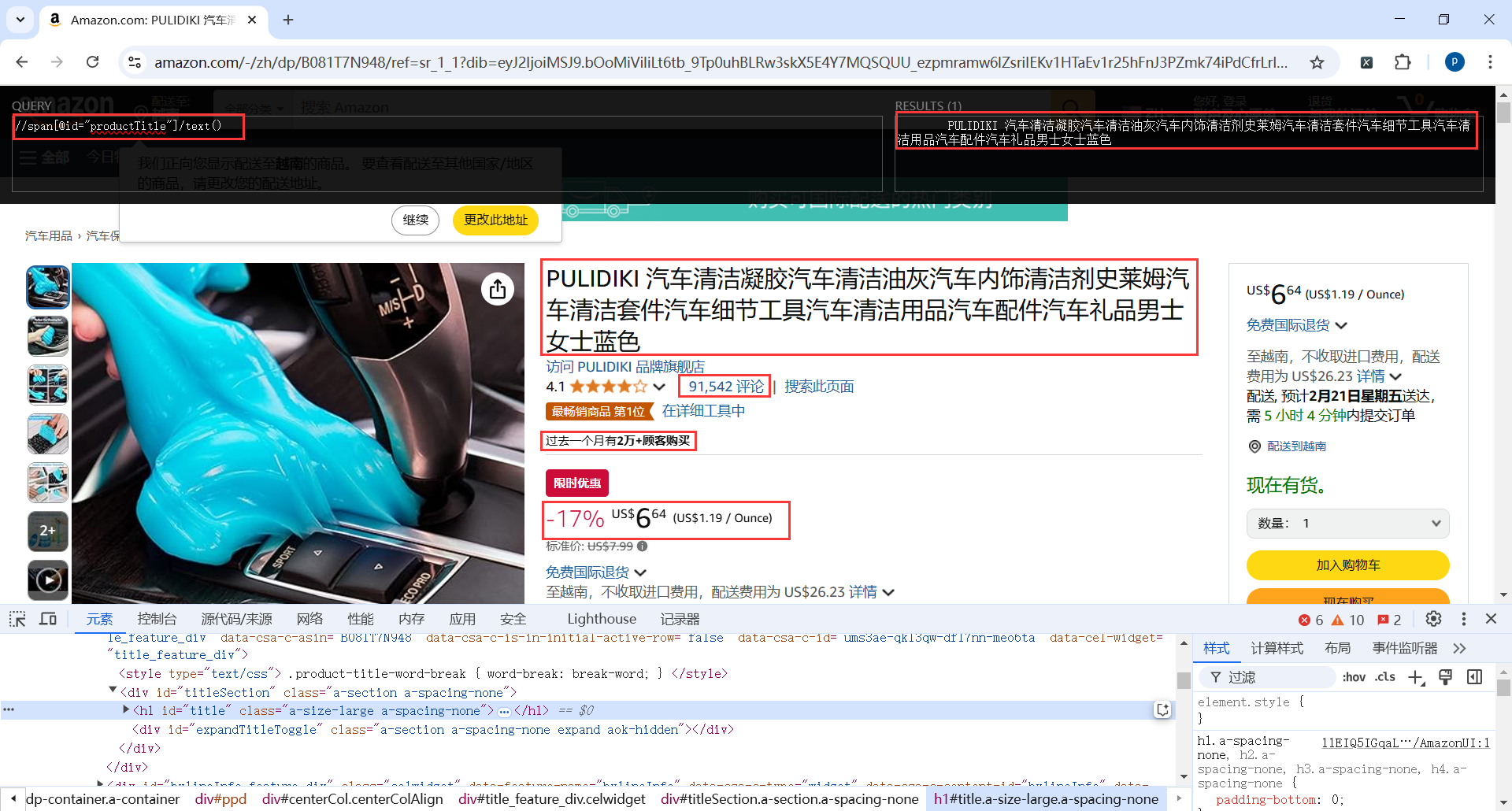
xpath匹配数据的时候记得做非空判断,提高代码容错率,我这里封装了一个方法

其实每种类别的商品详情页还是有一些差别的
我这里主要是获取了名称、图片、价格、销量、评论等
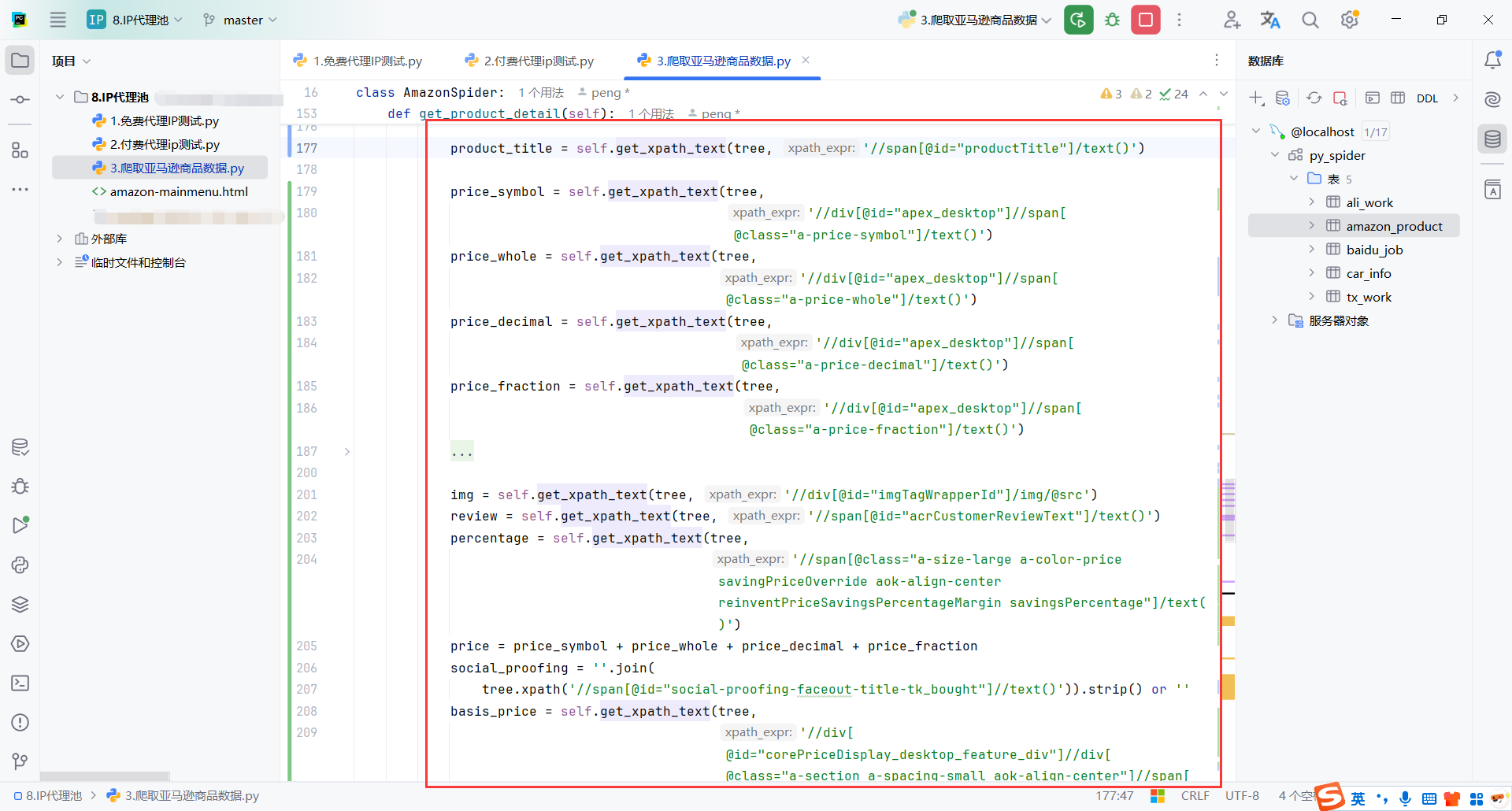
实际爬取的过程中,获取到商品详情的链接,我打开页面发现对应的xpath也能获取信息,但是代码获取的就是空
具体原因可能是返回的页面不完整或者其他的反爬措施
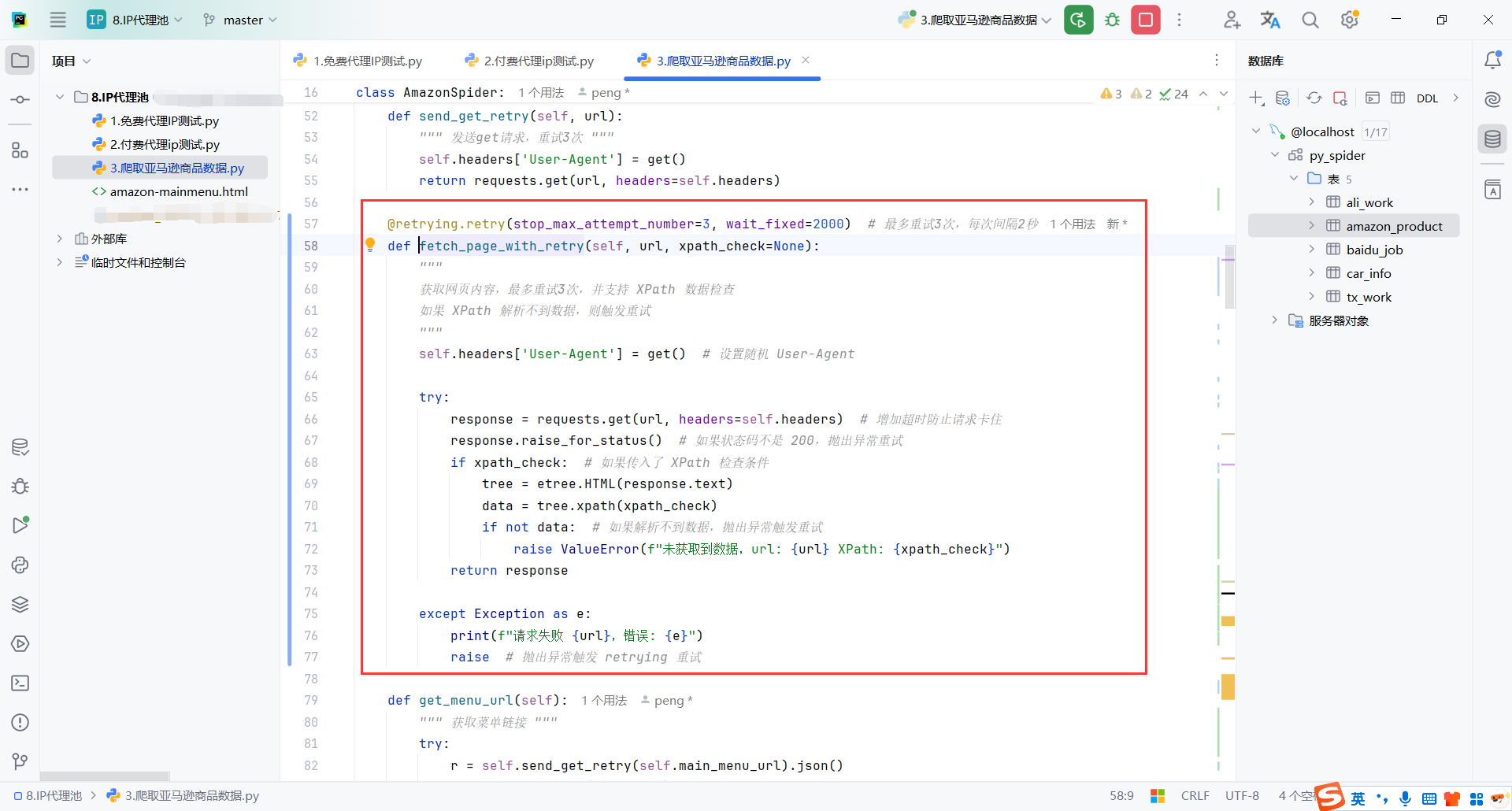
我这里就在请求的时候带上xpath,主要是商品标题的xpath,这个肯定是有的
如果没有我要的数据就重试3次,每次间隔2s,算是一个小的优化,实际爬取过程确实好了不少
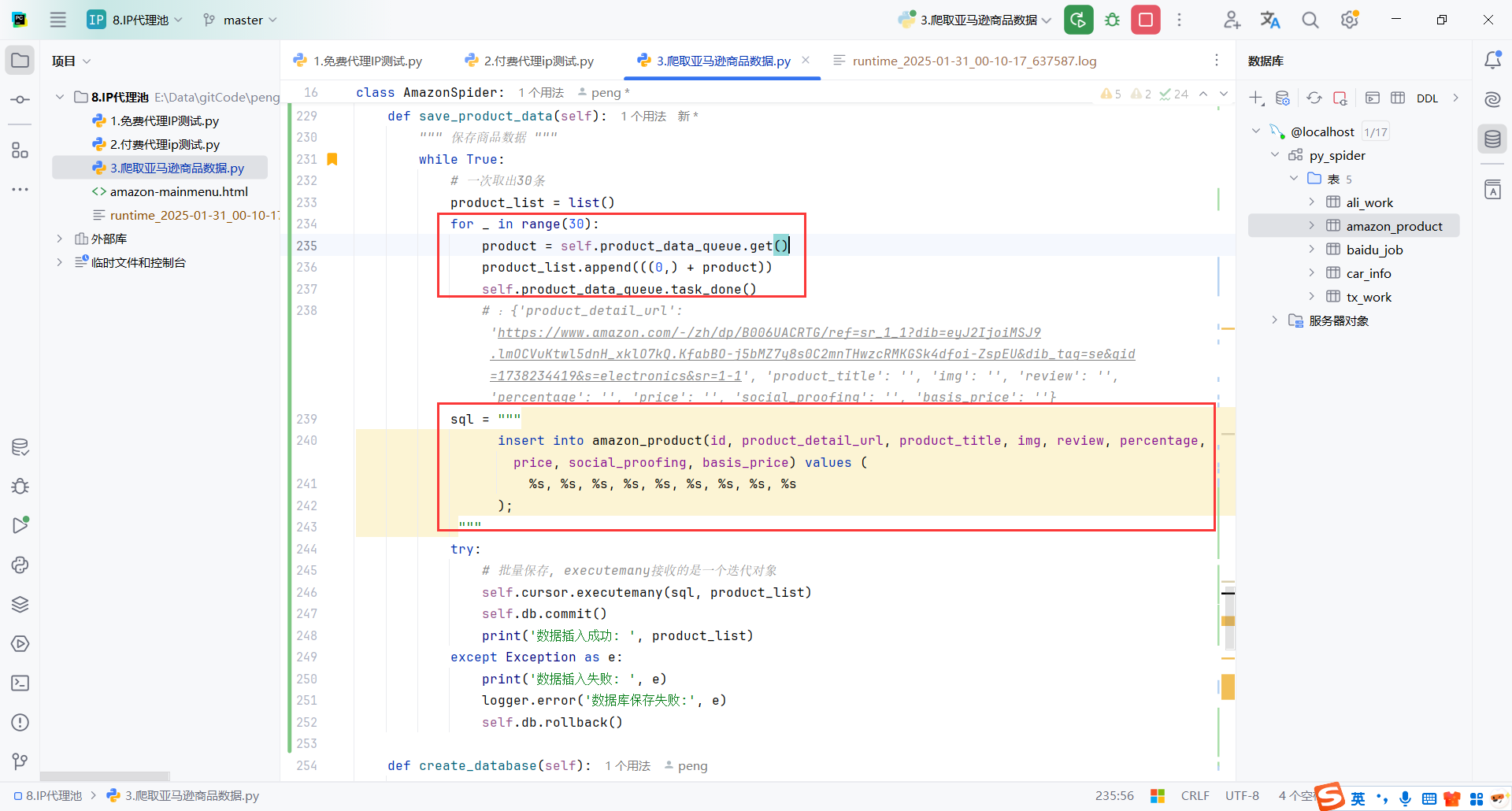
6.保存数据
保存mysql基本操作,这里做了优化就是30条数据插入一次,算是优化
但是风险就是插入失败了会损失30条
还有需要注意的是代码的缩进,我这里sql一开始缩进不对,程序就一直卡着,不好调试
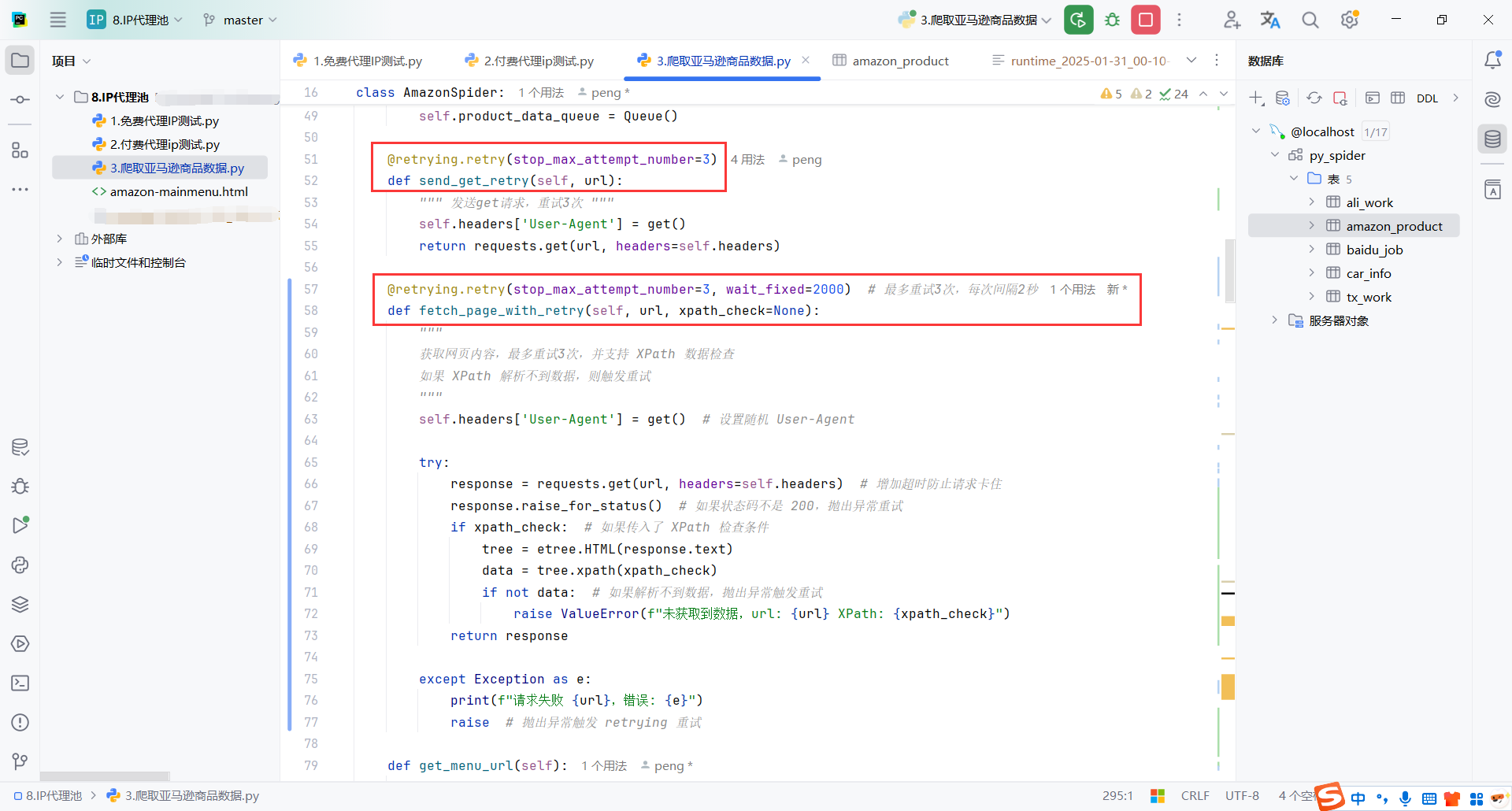
7.请求重试
这里对发送请求进行了优化
- 一个是普通请求失败了,可以重试3次
- 另一个是没有返回指定内容的页面也进行了重试,重试3次,间隔2s
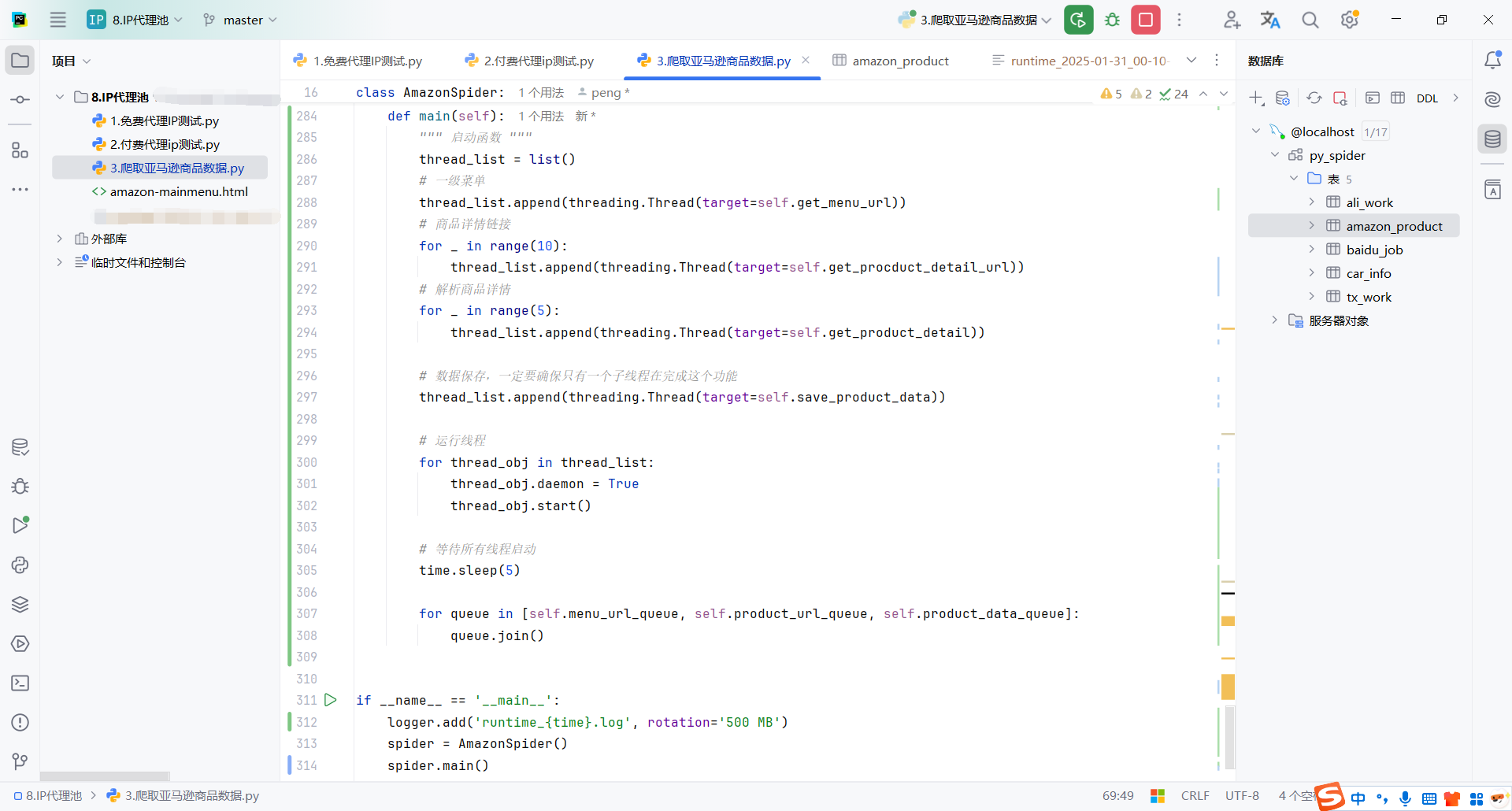
8.多线程启动任务
创建线程(不同任务分配不同数量的线程):
- 1个线程 处理获取菜单链接 (
get_menu_url)。 - 10个线程 处理获取商品详情链接 (
get_procduct_detail_url)。 - 5个线程 处理解析商品详情 (
get_product_detail)。 - 1个线程 负责数据保存 (
save_product_data)。
然后遍历thread_list启动所有线程,并设置置守护线程,保证主线程退出时所有子线程自动终止。
time.sleep(5):等待5秒,确保所有线程都真正运行起来,防止主线程提前执行 queue.join() 导致阻塞。
queue.join():阻塞主线程,直到队列中的所有任务都被消费。
9.代理IP池
如果长时间对https://www.amazon.com进行请求,自己的IP可能被封禁,所以建议使用代理IP池,当然需要付费,我这里只是记录一下实现方式
首先在__init__(self)中声明代理IP池的请求地址和队列,因为我们获取到IP池的IP放到队列,需要的时候从队列里取

从代理池队列里取出IP后,请求的时候带上proxies,如果IP可用,再放回代理IP池队列中,做到重用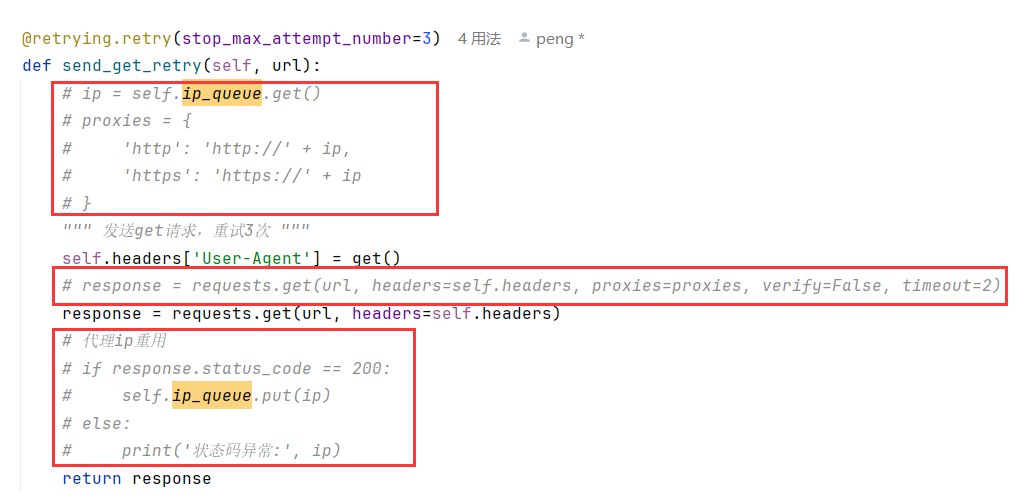
开启一个线程从代理IP池的服务器获取代理IP

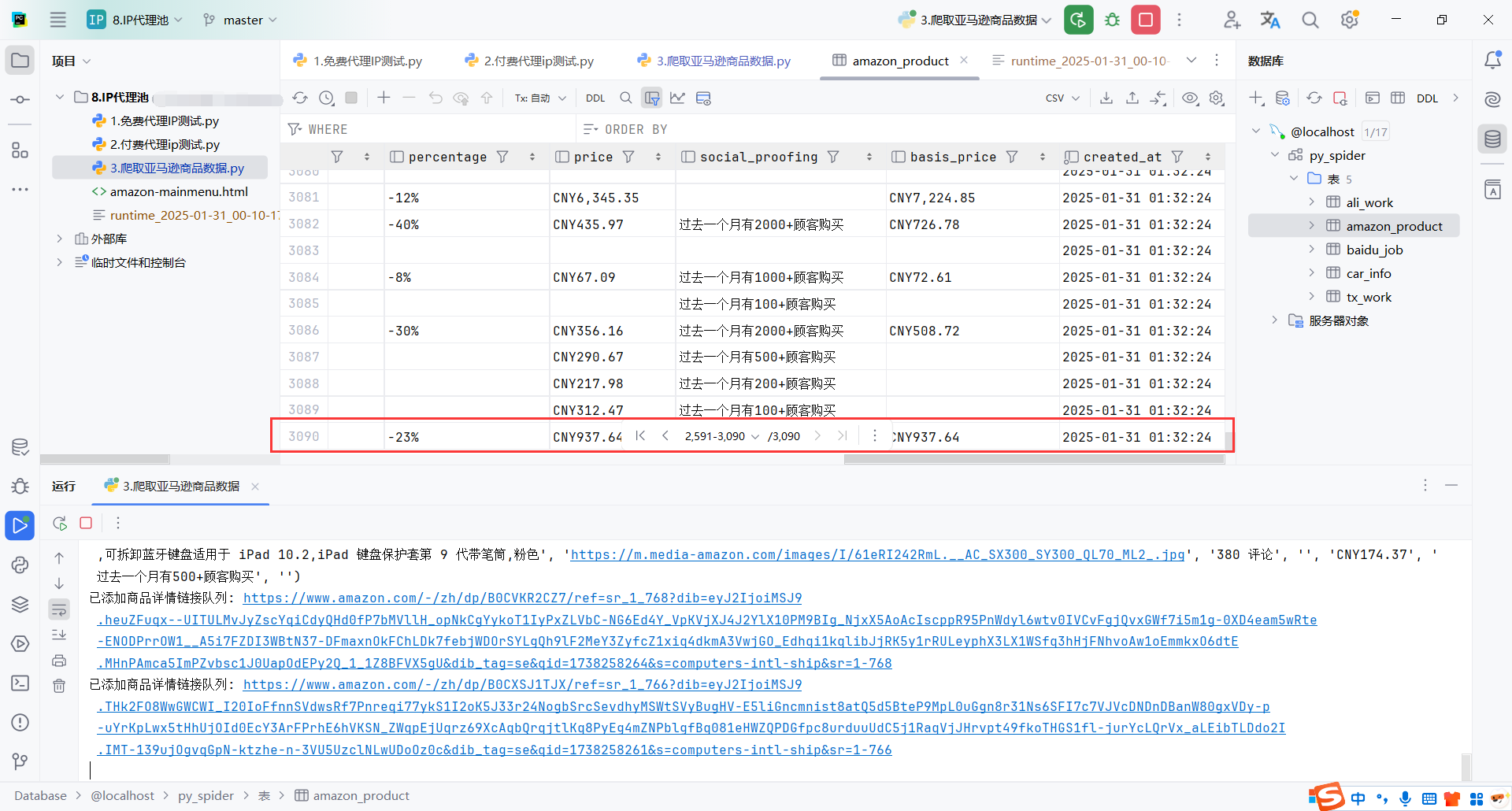
10.结尾
没有使用代理IP池,个人电脑爬取,不到30分钟,爬取了3000条数据,效率还凑合
📌 创作不易,感谢支持!
每一篇内容都凝聚了心血与热情,如果我的内容对您有帮助,欢迎请我喝杯咖啡☕,您的支持是我持续分享的最大动力!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号