02Redis和Net8
前言
总结一下Redis。
Redis,英文全称是Remote Dictionary Server(远程字典服务),是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
与MySQL数据库不同的是,Redis的数据是存在内存中的。它的读写速度非常快,每秒可以处理超过10万次读写操作。因此redis被广泛应用于缓存,另外,Redis也经常用来做分布式锁。除此之外,Redis支持事务、持久化、LUA 脚本、LRU 驱动事件、多种集群方案。
1.环境搭建
开发环境vs2022 + net8。
这是控制台使用的Redis公共方法实现,可以跳过。
StackExchange.Redis安装包
<ItemGroup>
<PackageReference Include="Newtonsoft.Json" Version="13.0.3" />
<PackageReference Include="StackExchange.Redis" Version="2.7.4" />
</ItemGroup>
实现封装
将Redis服务注入到ServiceCollection
RedisOptions cacheOptions = new RedisOptions()
{
Enable = true,
ConnectionString = "127.0.0.1:6379",
InstanceName = ""
};
IServiceCollection services = new ServiceCollection();
services.AddLogging();
// 配置启动Redis服务,虽然可能影响项目启动速度,但是不能在运行的时候报错,所以是合理的
services.AddSingleton<IConnectionMultiplexer>(sp =>
{
//获取连接字符串
var configuration = ConfigurationOptions.Parse(cacheOptions.ConnectionString, true);
configuration.ResolveDns = true;
return ConnectionMultiplexer.Connect(configuration);
});
services.AddSingleton<ConnectionMultiplexer>(p => p.GetService<IConnectionMultiplexer>() as ConnectionMultiplexer);
services.AddTransient<IRedisBasketRepository, RedisBasketRepository>();
IServiceProvider container = services.BuildServiceProvider(new ServiceProviderOptions()
{
ValidateOnBuild = true,//构建时检查是否有依赖没有注册的服务
ValidateScopes = false,//在解析服务时检查是否通过根容器来解析Scoped类型的实列
});
2.String(字符串)
2.1基础知识
- 简介:String是Redis最基础的数据结构类型,它是二进制安全的,可以存储图片或者序列化的对象,值最大存储为512M
- 简单使用举例:
set key value、get key等 - 应用场景:共享session、分布式锁,计数器、限流。
- 内部编码有3种,
int(8字节长整型)/embstr(小于等于39字节字符串)/raw(大于39个字节字符串)
C语言的字符串是char[]实现的,而Redis使用SDS(simple dynamic string) 封装,sds源码如下:
struct sdshdr{
unsigned int len; // 标记buf的长度
unsigned int free; //标记buf中未使用的元素个数
char buf[]; // 存放元素的坑
}
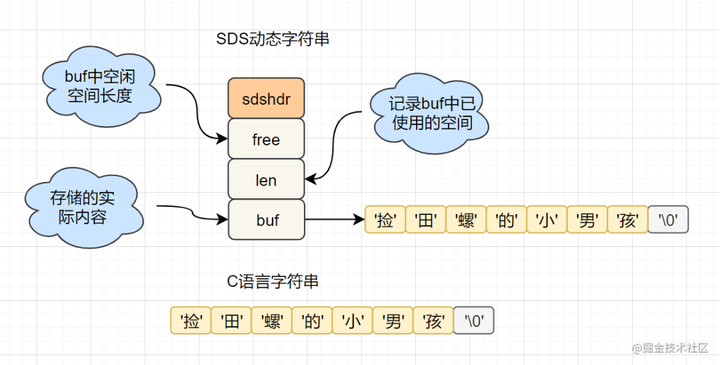
Redis为什么选择SDS结构,而不是C语言原生的char[]
SDS中,O(1)时间复杂度,就可以获取字符串长度;而C 字符串,需要遍历整个字符串,时间复杂度为O(n)
2.2Net8中使用String
添加一个值并查询
//string
var redisRes = container.GetRequiredService<IRedisBasketRepository>();
string str1 = string.Empty;
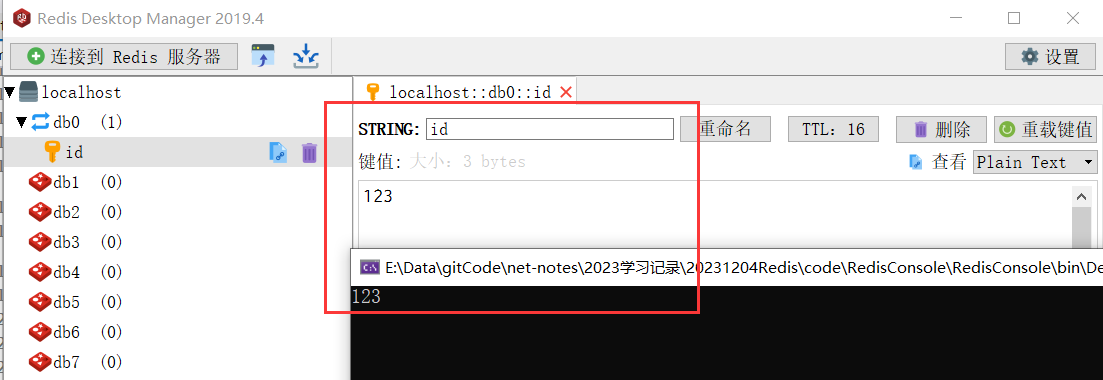
if (!await redisRes.Exist("id"))
{
await redisRes.Set("id", "123", TimeSpan.FromSeconds(20));
str1 = await redisRes.GetValue("id");
}
else
{
str1 = await redisRes.GetValue("id");
}
使用Redis Desktop查看
3.Hash(哈希)
3.1基础知识
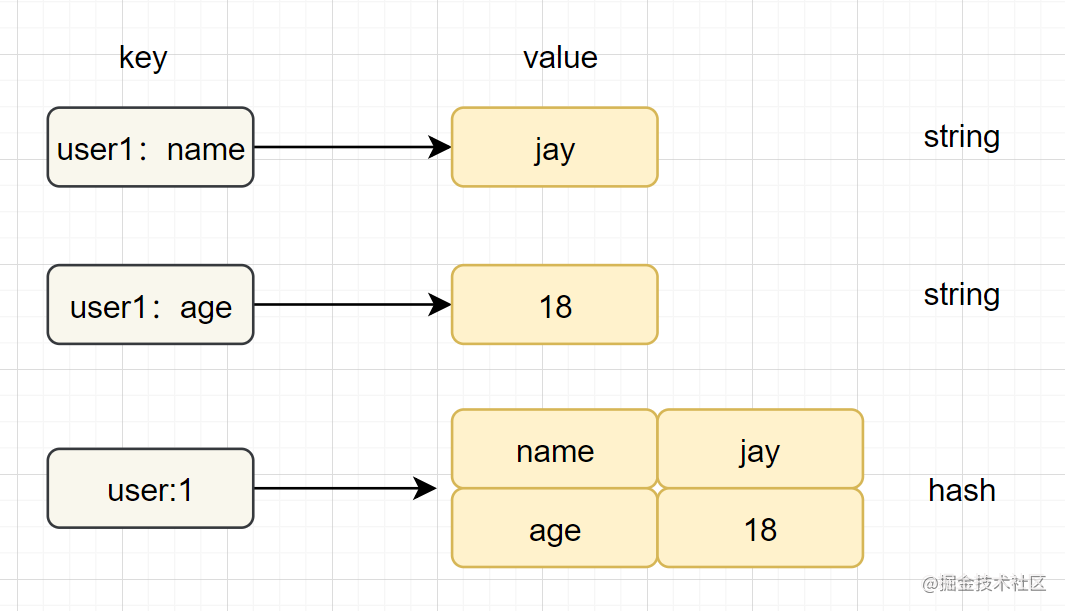
- 简介:在Redis中,哈希类型是指v(值)本身又是一个键值对(k-v)结构
- 简单使用举例:
hset key field value、hget key field - 内部编码:
ziplist(压缩列表)、hashtable(哈希表) - 应用场景:缓存用户信息等。
- 注意点:如果开发使用hgetall,哈希元素比较多的话,可能导致Redis阻塞,可以使用hscan。而如果只是获取部分field,建议使用hmget。
字符串和哈希类型对比如下图:
3.2Net8中使用Hash
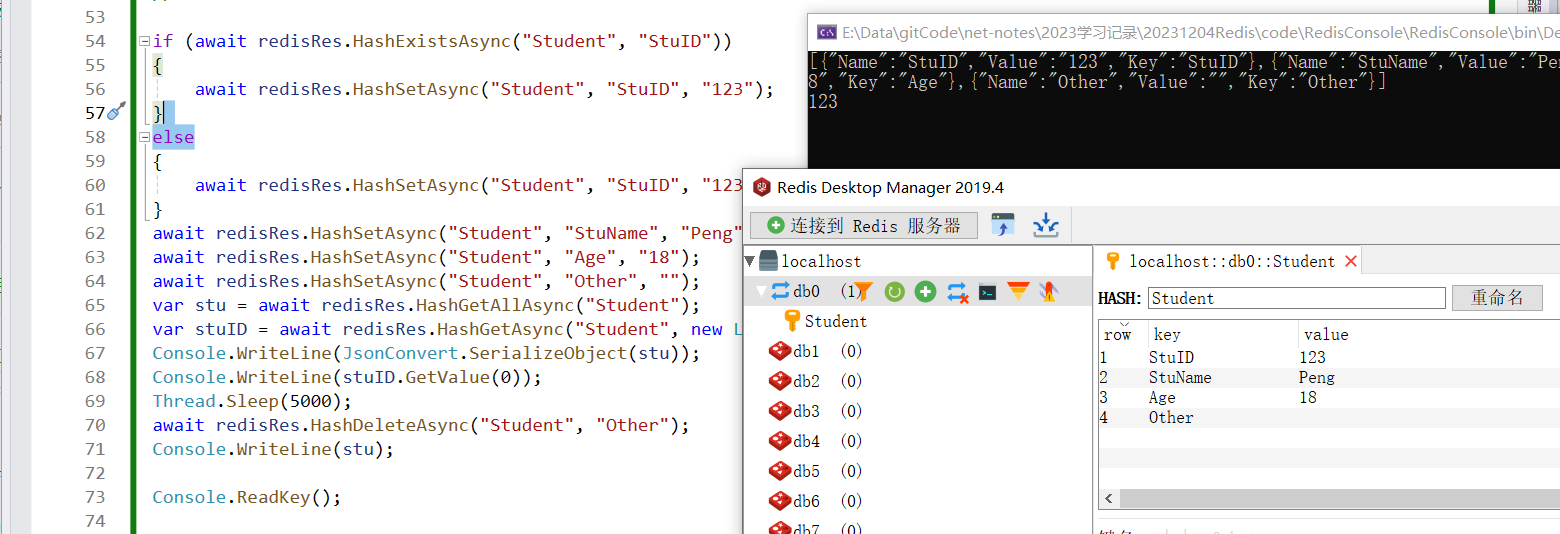
//Hash
if (await redisRes.HashExistsAsync("Student", "StuID"))
{
await redisRes.HashSetAsync("Student", "StuID", "123");
}
else
{
await redisRes.HashSetAsync("Student", "StuID", "123");
}
await redisRes.HashSetAsync("Student", "StuName", "Peng");
await redisRes.HashSetAsync("Student", "Age", "18");
await redisRes.HashSetAsync("Student", "Other", "");
Thread.Sleep(5000);
await redisRes.HashDeleteAsync("Student", "Other");
4.List(列表)
4.1基础知识
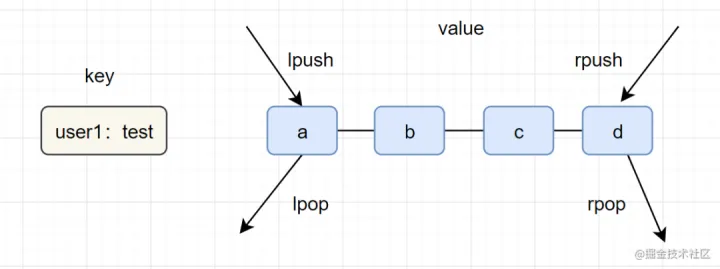
- 简介:列表(list)类型是用来存储多个有序的字符串,一个列表最多可以存储2^32-1个元素。
- 简单实用举例:
lpush key value [value ...]、lrange key start end - 内部编码:ziplist(压缩列表)、linkedlist(链表)
- 应用场景:消息队列,文章列表,
一图看懂list类型的插入与弹出:
list应用场景参考以下:
- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpsh+ltrim=Capped Collection(有限集合)
- lpush+brpop=Message Queue(消息队列)
4.2Net8中使用List
//List
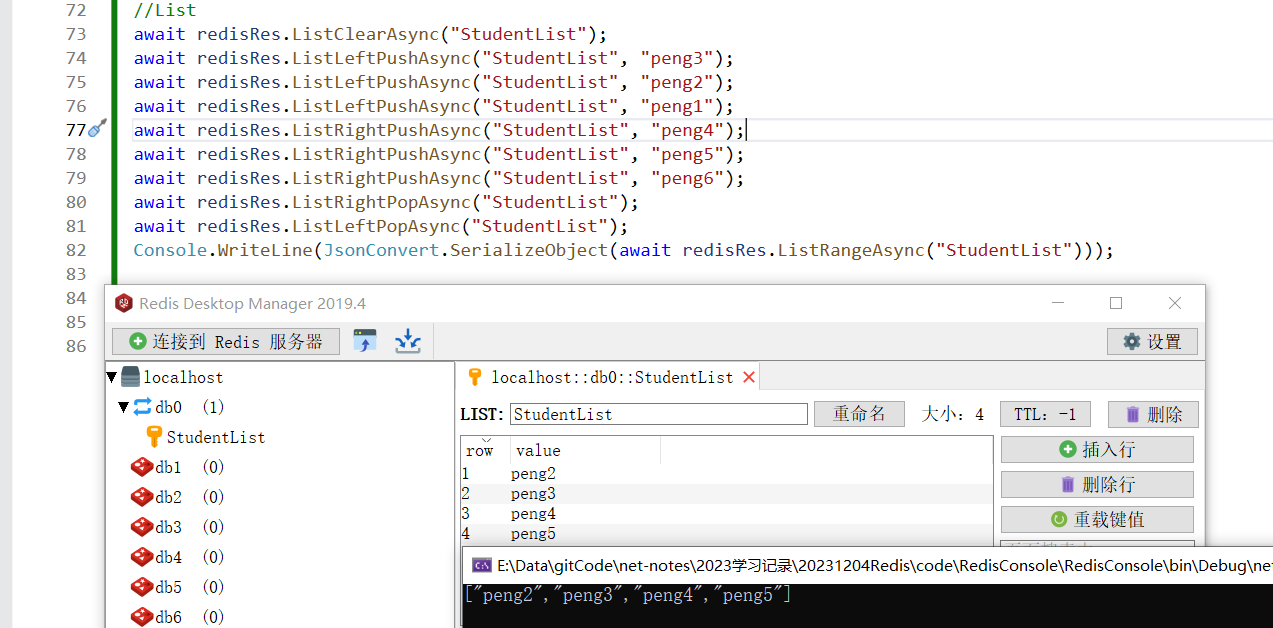
await redisRes.ListClearAsync("StudentList");
await redisRes.ListLeftPushAsync("StudentList", "peng3");
await redisRes.ListLeftPushAsync("StudentList", "peng2");
await redisRes.ListLeftPushAsync("StudentList", "peng1");
await redisRes.ListRightPushAsync("StudentList", "peng4");
await redisRes.ListRightPushAsync("StudentList", "peng5");
await redisRes.ListRightPushAsync("StudentList", "peng6");
await redisRes.ListRightPopAsync("StudentList");
await redisRes.ListLeftPopAsync("StudentList");
Console.WriteLine(JsonConvert.SerializeObject(await redisRes.ListRangeAsync("StudentList")));
5.Set(集合)
5.1基础知识
- 简介:集合(set)类型也是用来保存多个的字符串元素,但是不允许重复元素
- 简单使用举例:
sadd key element [element ...]、smembers key - 内部编码:
intset(整数集合)、hashtable(哈希表) - 注意点:smembers和lrange、hgetall都属于比较重的命令,如果元素过多存在阻塞Redis的可能性,可以使用sscan来完成。
- 应用场景:用户标签,生成随机数抽奖、社交需求。
5.2Net8中使用Set
(1)SetAdd:添加数据,可以单独1个key-1个value,也可以1个key-多个value添加
(2)SetLength:求key集合的数量
(3)SetContains:判断key集合中是否包含指定值
(4)SetRandomMember:随机获取指定key集合中的一个值或n个值
(5)SetMembers:获取key中的所有值,数据类型要一致,便于存储
(6)SetRemove:删除key集合中的指定value(1个或多个)
(7)SetPop:随机删除指定key集合中的一个值或n个值,并返回这些值。
(8)SetCombine:求多个元素的交并差
a.SetOperation.Intersect:交集
b.SetOperation.Union:并集
c.SetOperation.Difference:差集
(9)SetCombineAndStore:把多个元素的交并差,放到一个新的元素集合中
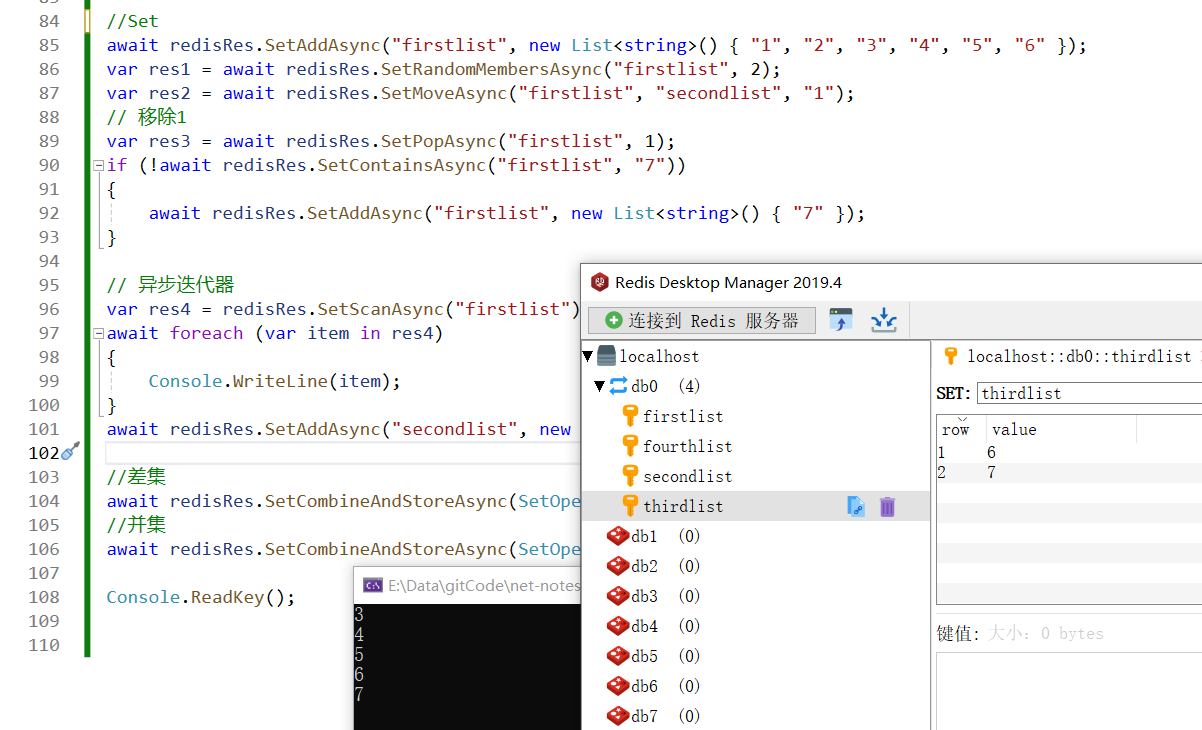
await redisRes.SetAddAsync("firstlist", new List<string>() { "1", "2", "3", "4", "5", "6" });
var res1 = await redisRes.SetRandomMembersAsync("firstlist", 2);
var res2 = await redisRes.SetMoveAsync("firstlist", "secondlist", "1");
// 移除1
var res3 = await redisRes.SetPopAsync("firstlist", 1);
if (!await redisRes.SetContainsAsync("firstlist", "7"))
{
await redisRes.SetAddAsync("firstlist", new List<string>() { "7" });
}
// 异步迭代器
var res4 = redisRes.SetScanAsync("firstlist");
await foreach (var item in res4)
{
Console.WriteLine(item);
}
await redisRes.SetAddAsync("secondlist", new List<string>() { "2", "3", "4", "5" });
//差集
await redisRes.SetCombineAndStoreAsync(SetOperation.Difference, "thirdlist", "firstlist", "secondlist");
//并集
await redisRes.SetCombineAndStoreAsync(SetOperation.Union, "fourthlist", "firstlist", "secondlist");
6.ZSet(有序集合)
6.1基础知识
- 简介:已排序的字符串集合,同时元素不能重复
- 简单格式举例:
zadd key score member [score member ...],zrank key member - 底层内部编码:
ziplist(压缩列表)、skiplist(跳跃表) - 应用场景:排行榜,社交需求(如用户点赞)。
6.2Net8中使用ZSet
(1)SortedSetAdd:增加,可以一次增加一个member,也可以一次增加多个member
(2)SortedSetIncrement 和 SortedSetDecrement:Score值自增或自减,如果不存在这member值,则执行增加操作,并返回当前Score值。
(3)排序相关
SortedSetRangeByRank:根据索引获取member值,默认是升序,可以获取指定索引内的member值
SortedSetRangeByScore:根据score获取member值,默认是升序,可以获取指定score开始和结束的member值,后面的skip和take用于分页
SortedSetRangeByValue:根据member获取member值,默认是升序,可以获取指定member开始和结束的值,后面的skip和take用于分页
SortedSetRangeByRankWithScores:获取member和score值,可以只返回 start-stop 这个索引排序内的值(默认升序),后面的skip和take用于分页
SortedSetScore:获取指定key指定member的score值
SortedSetLength:获取集合的数量
(4).删除相关
SortedSetRemove:删除指定key和指定member,member可以是1个或多个
SortedSetRemoveRangeByRank:删除指定索引开始到结束
SortedSetRemoveRangeByScore:删除指定分开始到结束 (5分-8分)
SortedSetRemoveRangeByValue:删除指定起始值和结束值(这里指定是member)
//ZSet
await redisRes.SortedSetAddAsync("sortsetlist", "a", 100);
await redisRes.SortedSetAddAsync("sortsetlist", "b", 90);
await redisRes.SortedSetAddAsync("sortsetlist", "c", 80);
await redisRes.SortedSetAddAsync("sortsetlist", "d", 70);
await redisRes.SortedSetAddAsync("sortsetlist", "e", 60);
// windows目前只能运行redis5,这个命令需要redis6环境才能运行。
// ERR unknown command `ZRANDMEMBER`, with args beginning with: `sortsetlist`, `5`
// await redisRes.SortedSetRandomMembersAsync("sortsetlist",5);
var res = redisRes.SortedSetScanAsync("sortsetlist",default);
await foreach ( var item in res)
{
Console.WriteLine(item);
}
7.Redis 的三种特殊数据类型
- Geo:Redis3.2推出的,地理位置定位,用于存储地理位置信息,并对存储的信息进行操作。
- HyperLogLog:用来做基数统计算法的数据结构,如统计网站的UV。
- Bitmaps :用一个比特位来映射某个元素的状态,在Redis中,它的底层是基于字符串类型实现的,可以把bitmaps成作一个以比特位为单位的数组
8.Redis为什么这么快
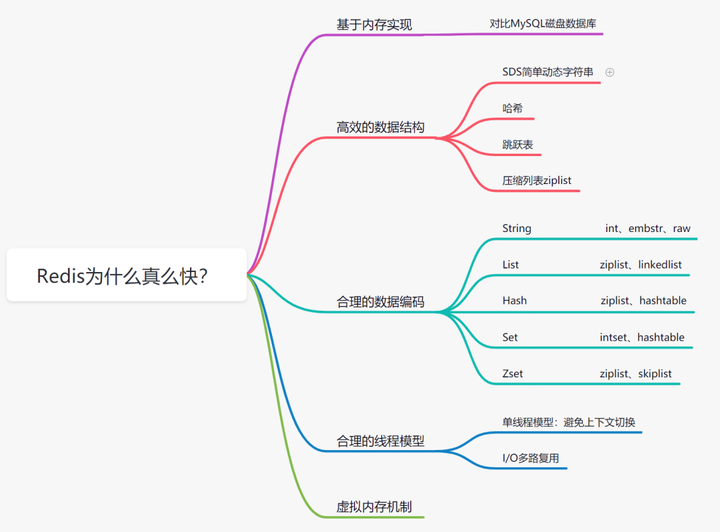
8.1基于内存存储实现
内存读写是比在磁盘快很多,Redis基于内存存储实现的数据库,相对于数据存在磁盘的MYSQL数据库,省去磁盘I/O的消耗。
8.2高效的数据结构
Mysql索引为了提高效率,选择了B+树的数据结构。
其实合理的数据结构,就是可以让你的应用/程序更快。
先看下Redis的数据结构&内部编码图:
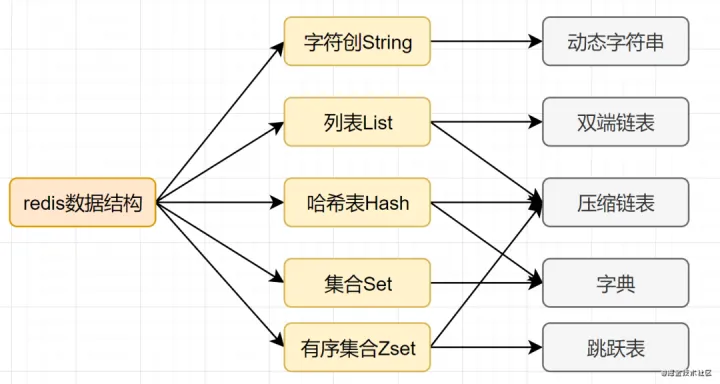
8.2.1SDS简单动态字符串
字符串长度处理:Redis获取字符串长度,时间复杂度为O(1),而C语言中,需要从头开始遍历,复杂度为O(n);
空间预分配:字符串修改越频繁的话,内存分配越频繁,就会消耗性能,而SDS修改和空间扩充,会额外分配未使用的空间,减少性能损耗。
惰性空间释放:SDS 缩短时,不是回收多余的内存空间,而是free记录下多余的空间,后续有变更,直接使用free中记录的空间,减少分配。
二进制安全:Redis可以存储一些二进制数据,在C语言中字符串遇到'\0'会结束,而 SDS中标志字符串结束的是len属性。
8.2.2字典
Redis 作为 K-V 型内存数据库,所有的键值就是用字典来存储。字典就是哈希表,比如HashMap,通过key就可以直接获取到对应的value。而哈希表的特性,在O(1)时间复杂度就可以获得对应的值。
8.2.3跳跃表
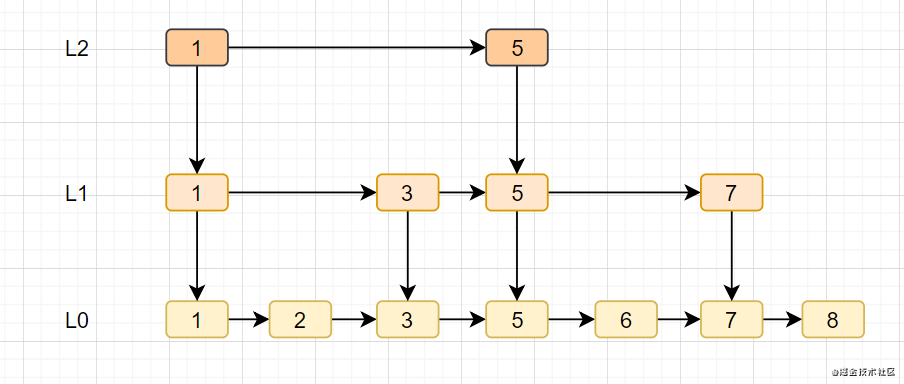
- 跳跃表是Redis特有的数据结构,就是在链表的基础上,增加多级索引提升查找效率。
- 跳跃表支持平均 O(logN),最坏 O(N)复杂度的节点查找,还可以通过顺序性操作批量处理节点。
8.3合理的数据编码
Redis 支持多种数据数据类型,每种基本类型,可能对多种数据结构。
- String:如果存储数字的话,是用int类型的编码;如果存储非数字,小于等于39字节的字符串,是embstr;大于39个字节,则是raw编码。
- List:如果列表的元素个数小于512个,列表每个元素的值都小于64字节(默认),使用ziplist编码,否则使用linkedlist编码
- Hash:哈希类型元素个数小于512个,所有值小于64字节的话,使用ziplist编码,否则使用hashtable编码。
- Set:如果集合中的元素都是整数且元素个数小于512个,使用intset编码,否则使用hashtable编码。
- Zset:当有序集合的元素个数小于128个,每个元素的值小于64字节时,使用ziplist编码,否则使用skiplist(跳跃表)编码。
8.4合理的线程模型(I/O 多路复用)
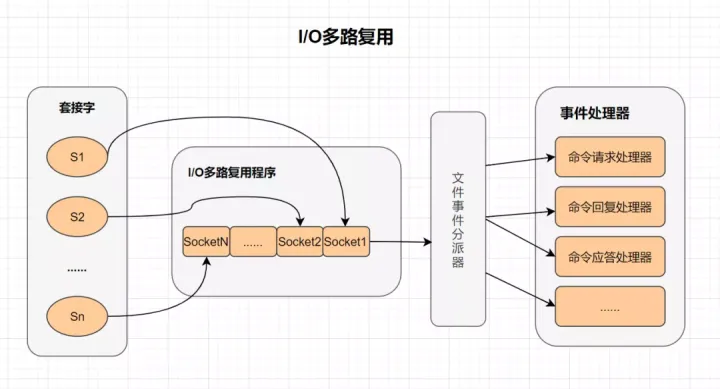
多路复用
多路I/O复用技术可以让单个线程高效的处理多个连接请求,而Redis使用epoll作为为I/O多路复用技术的实现。并且,Redis自身的事件处理模型将epoll的连接、读写、关闭都转换为事件,不在网络I/O上浪费过多的时间。
什么是I/O多路复用?
I/O:网络I/O
多路:多个网络连接。
复用:复用同一个线程。
IO多路复用其实就是一种同步I/O模型,它实现了一个线程可以监视多个文件句柄;一旦某个文件句柄就绪,就能够通知应用程序进行相应的读写操作;而没有文件句柄就绪时,就会阻塞应用程序,交出cpu。
8.5虚拟内存机制
Redis直接自己构建了VM机制 ,不会像一般的系统会调用系统函数处理,会浪费一定的时间去移动和请求。
Redis的虚拟内存机制是啥呢?
虚拟内存机制就是把暂时不经常访问的数据(冷数据)从内存交换到磁盘,从而腾出宝贵的内存空间用于其它需要访问的数据(热数据)。通过VM功能可以实现冷热数据分离,使热数据仍在内存中、冷数据保存到磁盘。这样就可以避免因为内存不足而造成访问速度下降的问题。
9.缓存击穿、穿透、雪崩
常见的缓存使用方式:读请求来了,先查下缓存,缓存有值命中,就直接返回;缓存没命中,就去查询数据库,然后把数据库的值更新到缓存,再返回。
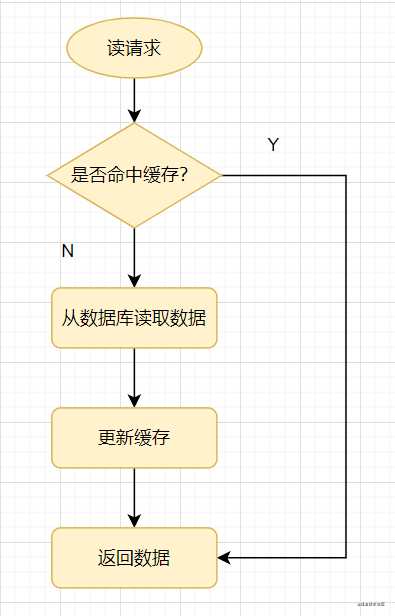
9.1缓存穿透
缓存穿透:指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库查询,进而给数据库带来压力。
通俗点说,读请求访问时,缓存和数据库都没有某个值,这样就会导致每次对这个值的查询请求都会穿透到数据库,这就是缓存穿透。
缓存穿透一般都是这几种情况产生的:
- 业务设计不合理:比如大多数用户都没开守护,但是每个请求都去缓存,查询某个userid查询有没有守护。
- 业务/运维/开发失误的操作:比如缓存和数据库的数据都被误删了。
- 黑客非法请求攻击:比如黑客故意捏造大量非法请求,以读取不存在的业务数据。
如何避免缓存穿透?
- 如果是非法请求,我们在API入口,对参数进行校验,过滤非法值。
- 如果查询数据库为空,我们可以给缓存设个空值,或者默认值。但是如果有写请求进来的话,需要更新缓存,以保证缓存一致性,同时,最后给缓存设置适当的过期时间。(业务上比较常用,简单有效)。
- 使用布隆过滤器快速判断数据是否存在。即一个查询请求过来时,先通过布隆过滤器判断值是否存在,存在才继续往下查。
布隆过滤器原理:
它由初始值为0的位图数组和N个哈希函数组成。一个对一个key进行N个hash算法获取N个值,在比特数组中将这N个值散列后设定为1,然后查的时候如果特定的这几个位置都为1,那么布隆过滤器判断该key存在。
9.2缓存雪崩
缓存雪崩:指缓存中数据大批量到过期时间,而查询数据量巨大,请求都直接访问数据库,引起数据库压力过大甚至down机。
- 缓存雪崩一般是由于大量数据同时过期造成的,对于这个原因,可通过均匀设置过期时间解决,即让过期时间相对离散一点。如采用一个较大的固定值+一个较小的随机值,5小时+0到1800秒酱紫。
- Redis故障宕机也可能引起缓存雪崩。这就需要构造Redis高可用集群啦。
9.3缓存击穿
缓存击穿:指热点key在某个时间点过期的时候,而恰好在这个时间点对这个Key有大量的并发请求过来,从而大量的请求打到db。
缓存击穿看着有点像缓存雪崩,其实它俩区别是,缓存雪崩是指数据库压力过大甚至down机,缓存击穿只是大量请求到了DB数据库层面。可认为击穿是缓存雪崩的一个子集把。有些文章认为它俩的区别,是区别在于击穿针对某一热点key缓存,雪崩则是很多key。
解决方案:
-
1.使用互斥锁方案。缓存失效时,不是立即去加载db数据,而是先使用某些带成功返回的原子操作命令,如(Redis的setnx)去操作,成功的时候,再去加载db数据库数据和设置缓存。否则就去重试获取缓存。
-
2.永不过期。是指没有设置过期时间,但是热点数据快要过期的时,异步线程去更新和设置过期时间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号