

分库分表后如何部署上线
引言
我们先来讲一个段子
面试官:“有并发的经验没?”
应聘者:“有一点。”
面试官:“那你们为了处理并发,做了哪些优化?”
应聘者:“前后端分离啊,限流啊,分库分表啊。。”
面试官:"谈谈分库分表吧?"
应聘者:“bala。bala。bala。。”
面试官心理活动:这个仁兄讲的怎么这么像网上的博客抄的,容我再问问。
面试官:“你们分库分表后,如何部署上线的?”
应聘者:“这!!!!!!”
不要惊讶,我写这篇文章前,我特意去网上看了下分库分表的文章,很神奇的是,都在讲怎么进行分库分表,却不说分完以后,怎么部署上线的。这样在面试的时候就比较尴尬了。
你们自己摸着良心想一下,如果你真的做过分库分表,你会不知道如何部署的么?因此我们来学习一下如何部署吧。
ps:我发现一个很神奇的现象。因为很多公司用的技术比较low,那么一些求职者为了提高自己的竞争力,就会将一些高大上的技术写进自己的low项目中。然后呢,他出去面试害怕碰到从这个公司出来的人,毕竟从这个公司出来的人,一定知道自己以前公司的项目情形。因此为了圆谎,他就会说:“他们从事的是这个公司的老项目改造工作,用了很多新技术进去!”
那么,请你好好思考一下,你们的老系统是如何平滑升级为新系统的!
如何部署
停机部署法
大致思路就是,挂一个公告,半夜停机升级,然后半夜把服务停了,跑数据迁移程序,进行数据迁移。
步骤如下:
(1)出一个公告,比如“今晚00:00~6:00进行停机维护,暂停服务”
(2)写一个迁移程序,读db-old数据库,通过中间件写入新库db-new1和db-new2,具体如下图所示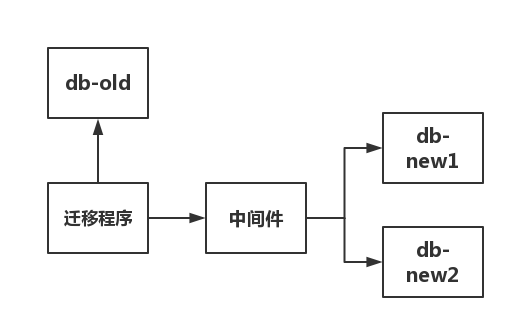
(3)校验迁移前后一致性,没问题就切该部分业务到新库。
顺便科普一下,这个中间件。现在流行的分库分表的中间件有两种,一种是proxy形式的,例如mycat,是需要额外部署一台服务器的。还有一种是client形式的,例如当当出的Sharding-JDBC,就是一个jar包,使用起来十分轻便。我个人偏向Sharding-JDBC,这种方式,无需额外部署,无其他依赖,DBA也无需改变原有的运维方式。
评价:
大家不要觉得这种方法low,我其实一直觉得这种方法可靠性很强。而且我相信各位读者所在的公司一定不是什么很牛逼的互联网公司,如果你们的产品凌晨1点的用户活跃数还有超过1000的,你们握个爪!毕竟不是所有人都在什么电商公司的,大部分产品半夜都没啥流量。所以此方案,并非没有可取之处。
但是此方案有一个缺点,累!不止身体累,心也累!你想想看,本来定六点结束,你五点把数据库迁移好,但是不知怎么滴,程序切新库就是有点问题。于是,眼瞅着天就要亮了,赶紧把数据库切回老库。第二个晚上继续这么干,简直是身心俱疲。
ps:这里教大家一些技巧啊,如果你真的没做过分库分表,又想吹一波,涨一下工资,建议答这个方案。因为这个方案比较low,low到没什么东西可以深挖的,所以答这个方案,比较靠谱。
另外,如果面试官的问题是
你们怎么进行分库分表的?
这个问题问的很泛,所以回答这个问题建议自己主动把分表的策略,以及如何部署的方法讲出来。因为这么答,显得严谨一些。
不过,很多面试官为了卖弄自己的技术,喜欢这么问
分表有哪些策略啊?你们用哪种啊?
ok。。这个问题具体指向了分库分表的某个方向了,你不要主动答如何进行部署的。等面试官问你,你再答。如果面试官没问,在面试最后一个环节,面试官会让你问让几个问题。你就问
你刚才刚好有提到分库分表的相关问题,我们当时部署的时候,先停机。然后半夜迁移数据,然后第二天将流量切到新库,这种方案太累,不知道贵公司有没有什么更好的方案?
那么这种情况下,面试官会有两种回答。第一种,面试官硬着头皮随便扯。第二种,面试官真的做过,据实回答。记住,面试官怎么回答的不重要。重点的是,你这个问题出去,会给面试官一种错觉:"这个小伙子真的做过分库分表。"
如果你担心进去了,真派你去做分库分表怎么办?OK,不要怕。我赌你试用期碰不到这个活。因为能进行分库分表,必定对业务非常熟。还在试用期的你,必定对业务不熟,如果领导给你这种活,我只能说他有一颗大心脏。
ok,指点到这里。面试本来就是一场斗智斗勇的过程,扯远了,回到我们的主题。
双写部署法(一)
这个就是不停机部署法,这里我需要先引进两个概念:历史数据和增量数据。
假设,我们是对一张叫做test_tb的表进行拆分,因为你要进行双写,系统里头和test_tb表有关的业务之前必定会加入一段双写代码,同时往老库和新库中写,然后进行部署,那么
历史数据:在该次部署前,数据库表test_tb的有关数据,我们称之为历史数据。
增量数据:在该次部署后,数据库表test_tb的新产生的数据,我们称之为增量数据。
然后迁移流程如下
(1)先计算你要迁移的那张表的max(主键)。在迁移过程中,只迁移db-old中test_tb表里,主键小等于该max(主键)的值,也就是所谓的历史数据。
这里有特殊情况,如果你的表用的是uuid,没法求出max(主键),那就以创建时间作为划分历史数据和增量数据的依据。如果你的表用的是uuid,又没有创建时间这个字段,我相信机智的你,一定有办法区分出历史数据和增量数据。
(2)在代码中,与test_tb有关的业务,多加一条往消息队列中发消息的代码,将操作的sql发送到消息队列中,至于消息体如何组装,大家自行考虑。需要注意的是,只发写请求的sql,只发写请求的sql,只发写请求的sql。重要的事情说三遍!
原因有二:
- (1)只有写请求的sql对恢复数据才有用。
- (2)系统中,绝大部分的业务需求是读请求,写请求比较少。
注意了,在这个阶段,我们不消费消息队列里的数据。我们只发写请求,消息队列的消息堆积情况不会太严重!
(3)系统上线。另外,写一段迁移程序,迁移db-old中test_tb表里,主键小于该max(主键)的数据,也就是所谓的历史数据。
上面步骤(1)~步骤(3)的过程如下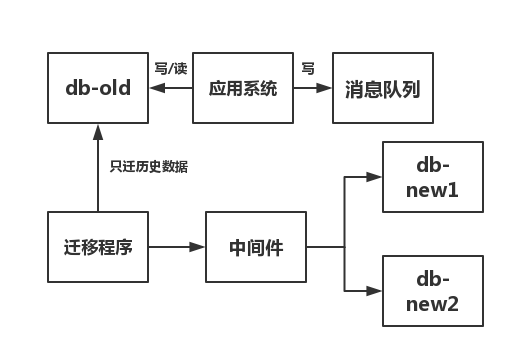
等到db-old中的历史数据迁移完毕,则开始迁移增量数据,也就是在消息队列里的数据。
(4)将迁移程序下线,写一段订阅程序订阅消息队列中的数据
(5)订阅程序将订阅到到数据,通过中间件写入新库
(6)新老库一致性验证,去除代码中的双写代码,将涉及到test_tb表的读写操作,指向新库。
上面步骤(4)~步骤(6)的过程如下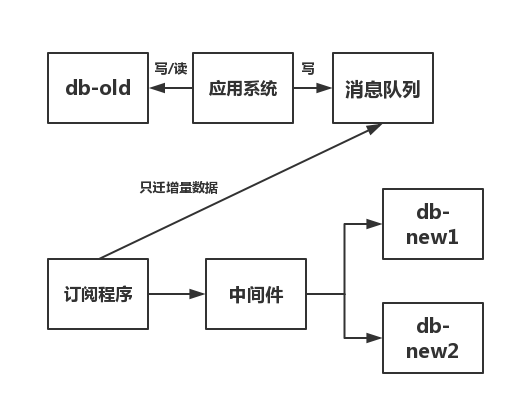
这里大家可能会有一个问题,在步骤(1)~步骤(3),系统对历史数据进行操作,会造成不一致的问题么?
OK,不会。这里我们对delete操作和update操作做分析,因为只有这两个操作才会造成历史数据变动,insert进去的数据都是属于增量数据。
(1)对db-old的test_tb表的历史数据发出delete操作,数据还未删除,就被迁移程序给迁走了。此时delete操作在消息队列里还有记录,后期订阅程序订阅到该delete操作,可以进行删除。
(2)对db-old的test_tb表的历史数据发出delete操作,数据已经删除,迁移程序迁不走该行数据。此时delete操作在消息队列里还有记录,后期订阅程序订阅到该delete操作,再执行一次delete,并不会对一致性有影响。
对update的操作类似,不赘述。
双写部署法(二)
上面的方法有一个硬伤,注意我有一句话
(2)在代码中,与test_tb有关的业务,多加一条往消息队列中发消息的代码,将操作的sql发送到消息队列中,至于消息体如何组装,大家自行考虑。
大家想一下,这么做,是不是造成了严重的代码入侵。将非业务代码嵌入业务代码,这么做,后期删代码的时候特别累。
有没什么方法,可以避免这个问题的?
有的,订阅binlog日志。关于binlog日志,我尽量下周写一篇《研发应该掌握的binlog知识》,这边我就介绍一下作用
记录所有数据库表结构变更(例如CREATE、ALTER TABLE…)以及表数据修改(INSERT、UPDATE、DELETE…)的二进制日志。binlog不会记录SELECT和SHOW这类操作,因为这类操作对据本身并没有修改。
还记得我们在双写部署法(一)里介绍的,往消息队列里发的消息,都是写操作的消息。而binlog日志记录的也是写操作。所以订阅该日志,也能满足我们的需求。
于是步骤如下
(1)打开binlog日志,系统正常上线就好
(2)还是写一个迁移程序,迁移历史数据。步骤和上面类似,不啰嗦了。
步骤(1)~步骤(2)流程图如下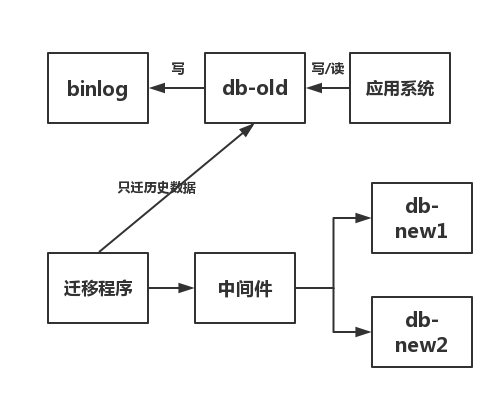
(3)写一个订阅程序,订阅binlog(mysql中有canal。至于oracle中,大家就随缘自己写吧)。然后将订阅到到数据通过中间件,写入新库。
(4)检验一致性,没问题就切库。
步骤(3)~步骤(4)流程图如下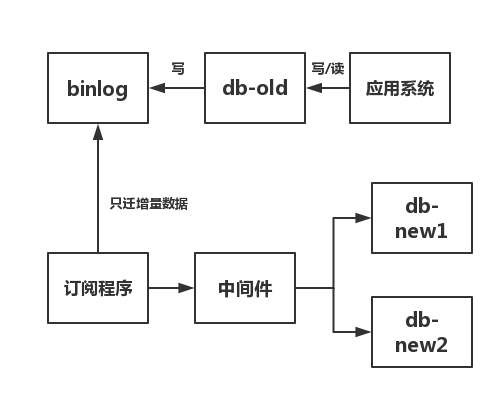
怎么验数据一致性
这里大概介绍一下吧,这篇的篇幅太长了,大家心里有底就行。
(1)先验数量是否一致,因为验数量比较快。
至于验具体的字段,有两种方法:
(2.1)有一种方法是,只验关键性的几个字段是否一致。
(2.2)还有一种是 ,一次取50条(不一定50条,具体自己定,我只是举例),然后像拼字符串一样,拼在一起。用md5进行加密,得到一串数值。新库一样如法炮制,也得到一串数值,比较两串数值是否一致。如果一致,继续比较下50条数据。如果发现不一致,用二分法确定不一致的数据在0-25条,还是26条-50条。以此类推,找出不一致的数据,进行记录即可。
ok,啰嗦完毕。

